具身系统中的生成式AI:性能、效率和可扩展性的系统级分析(下)
25年4 月来自Georgia Tech、明尼苏达大学和哈佛大学的论文“Generative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability”。具身系统利用大语言模型(LLM)驱动的集成感知、认知、行动和高级推理能力,使生成式自主智体能够与物理世界互动,从而在现实世界环
25年4 月来自Georgia Tech、明尼苏达大学和哈佛大学的论文“Generative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability”。
具身系统利用大语言模型(LLM)驱动的集成感知、认知、行动和高级推理能力,使生成式自主智体能够与物理世界互动,从而在现实世界环境中处理复杂、长周期、多目标任务方面具有巨大潜力。然而,由于运行时延迟过长、可扩展性有限以及系统对环境因素高度敏感,导致系统效率显著降低,因此部署这些系统仍然面临挑战。本文旨在理解具身智体系统的工作负载特征并探索优化方案。这些系统系统地分为四种范式,并通过基准测试研究评估其在不同模块、智能体规模和具身任务下的任务性能和系统效率。基准测试研究揭示一些关键挑战,例如规划和通信延迟过长、智体交互冗余、底层控制机制复杂、内存不一致、提示长度爆炸、对自我纠正和执行的敏感性、成功率急剧下降以及随着智体数量的增加协作效率降低等。利用这些分析结果,其提出系统优化策略,以提升不同范式下具身智体的性能、效率和可扩展性。
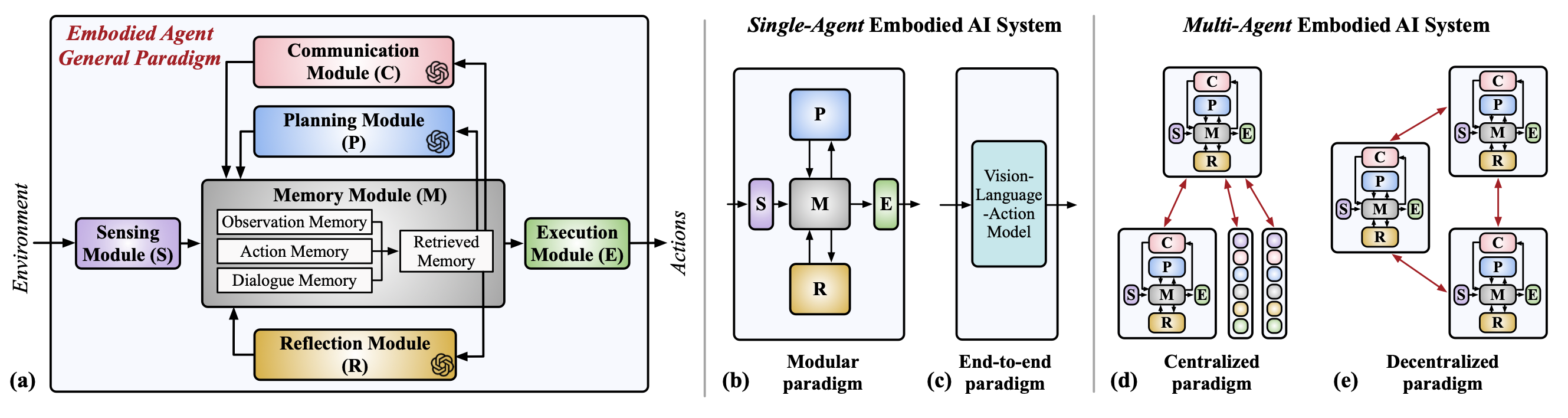
。。。。。。继续。。。。。。
运行时延迟分析
端到端延迟。图 a 展示各种长时程具身任务中每个模块在每个时间步长内贡献的平均延迟。具身工作负载的延迟步长显著,帧率较低。执行长时程任务的一步平均耗时 10-30 秒,导致帧率低,通常无法满足人机交互应用的实时性要求。此外,如图 b 所示,每个工作负载需要数十到数百步才能完成任务,导致端到端长时程具身任务延迟较长,不同任务的延迟时间在 10-40 分钟之间。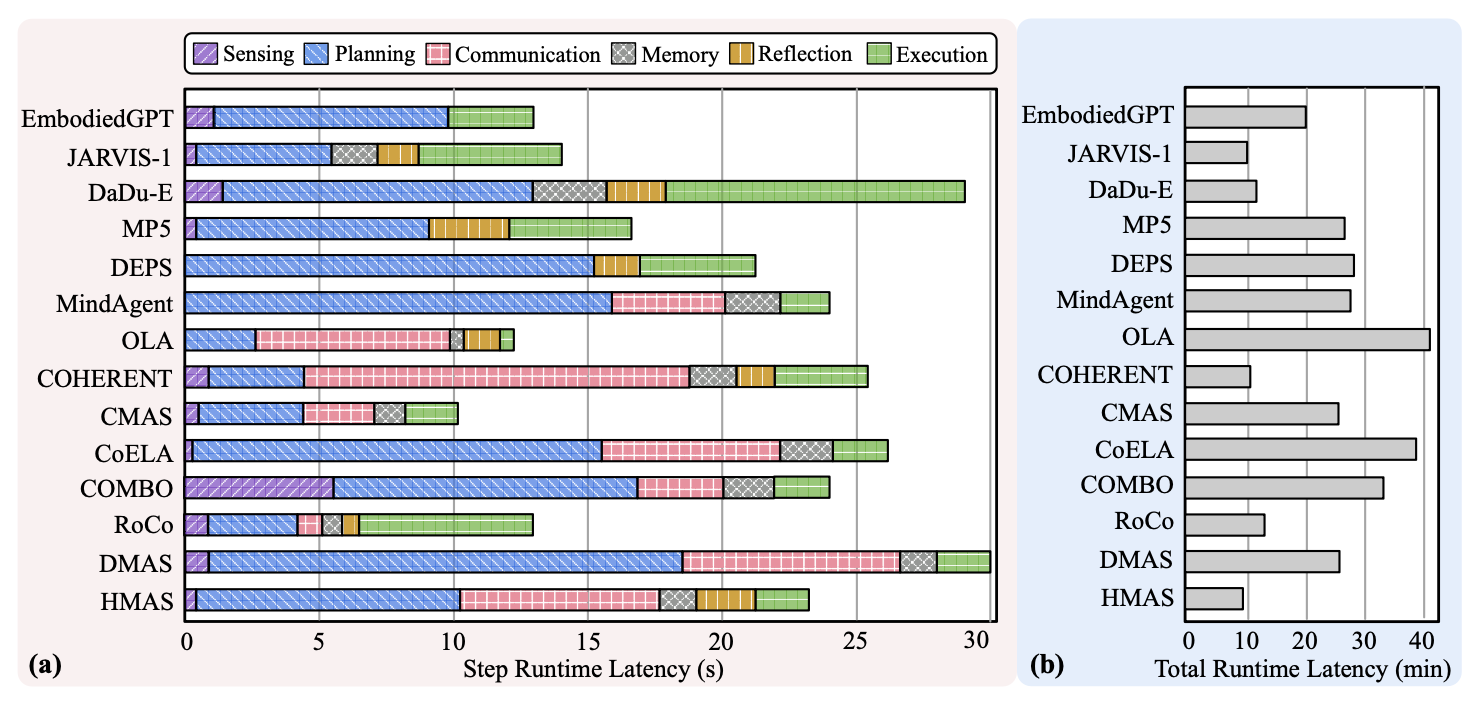
基于 LLM 的模块延迟。基于 LLM 的规划和通信模块对延迟的贡献最大。如上图 a 所示,基于 LLM 的模块,无论是通过 GPT-4 API 调用还是本地模型处理(例如 Llama、LLaVA),在 14 个工作负载中平均占总延迟的 70.2%。由于消息生成和提取过程的重复,通信模块显著地成为某些工作负载(例如 COHERENT、CoELA)的瓶颈。此外,每个执行步骤通常涉及多次 LLM 推理运行。例如,在 CoELA 中,每个步骤都涉及三次 LLM 运行,分别用于消息生成(16.1%)、规划(36.5%)和动作选择(10.3%),这导致效率低下,尤其是在智体数量更多、任务周期更长的情况下。
非 LLM 模块的延迟。执行模块可能成为具身系统的瓶颈。上图 a 显示,与基于 LLM 的模块相比,底层规划和动作模块的延迟不可忽略,分别占 RoCo、DaDu-E 和 EmbodiedGPT 总延迟的 49.4%、38.1% 和 24.1%。这主要是由于完成单个规划步骤通常需要多次执行,以及底层路径规划和操作功能(例如 RRT [78]、A* [79])的计算复杂度较高。值得注意的是,底层执行对于成功完成具身任务至关重要 [33]、[34]。
结论 1:长时程具身任务的端到端延迟显著。基于 LLM 的规划和通信由于重复的推理运行而占据了大部分延迟。底层规划和执行也由于多次执行和计算复杂度而造成明显的延迟。
建议 1:规划和通信的长延迟可以通过高效的 LLM 部署来优化,例如批处理(例如,将多个查询聚合到单个批次中)、量化(例如,AWQ [80])、硬件友好格式(例如,MLC-LLM [81])和轻量级模型。
建议 2:低级操作和执行的低效可以通过优化数据结构、内存访问模式、并行性以及与高级规划基础架构集成的领域特定架构来优化。
模块敏感性分析
为了分析具身系统中每个构建模块对长周期多目标任务的敏感性,对完成任务所需的平均步骤数和跨工作负载的平均成功率进行基准测试(如图所示)。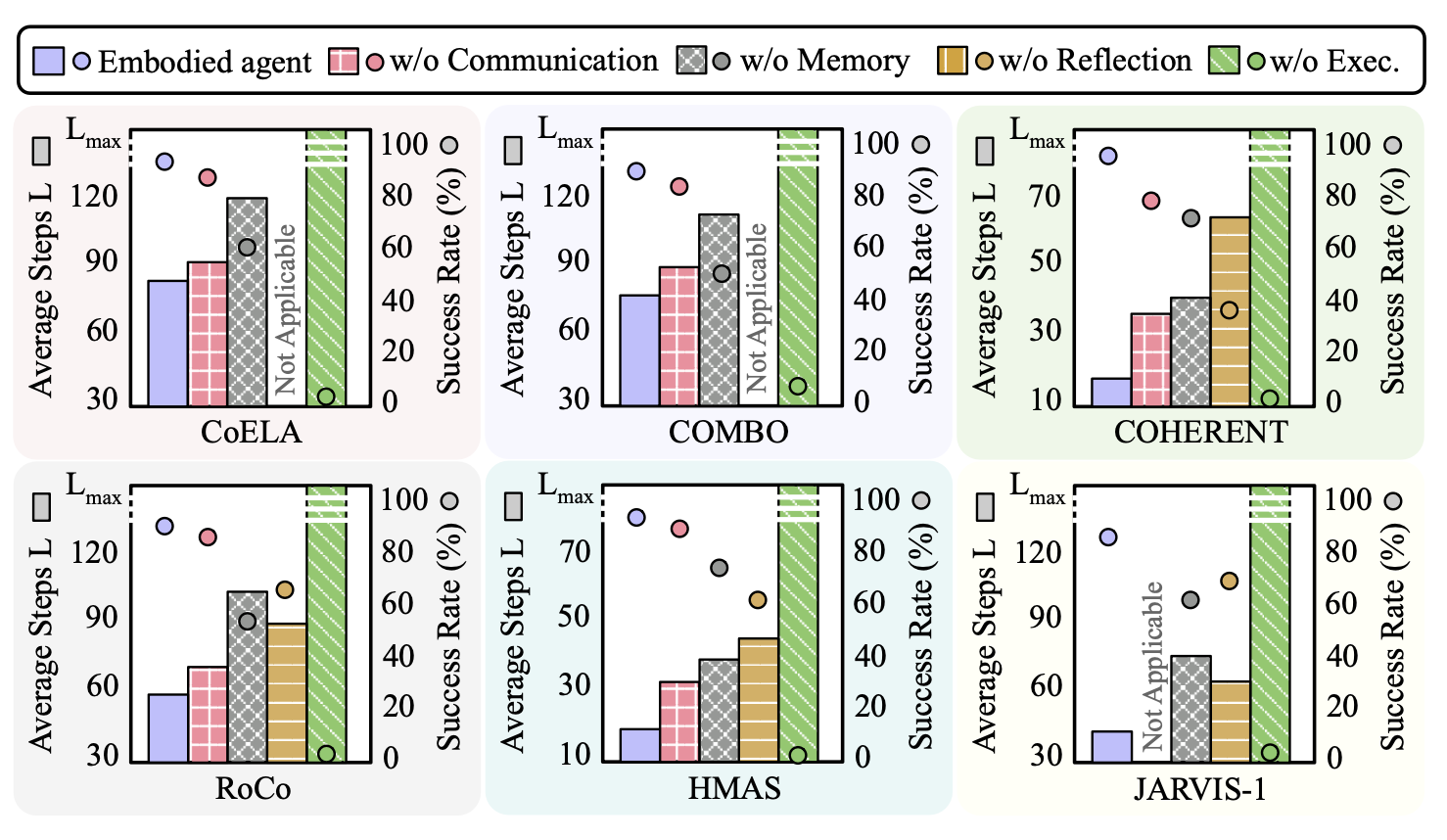
通信模块的敏感性。通信模块负责信息共享和请求处理。有趣的是,与其他模块相比,禁用智体之间的通信对性能没有显著影响。假设存在两种可能的原因:在系统层面,许多对话轮次是冗余且低效的,只有一小部分生成的消息被交换,表明通信利用率低。在模型层面,有效的通信依赖于准确地对其他智体的意图进行建模并解决自然语言歧义。目前的模型(例如 GPT-4)仍然难以始终如一地处理这些推理的复杂性。
记忆模块的敏感性。记忆模块存储观察、对话和动作信息,其他模块会检索这些信息用于规划和通信。如上图所示,记忆模块在具身人工智能体系统中扮演着至关重要的角色。禁用记忆模块会使完成任务所需的步骤平均增加 1.61 倍,并在六个系统中使成功率降低 27.7%。这凸显记忆模块在存储和更新有关环境和智体动作的知识方面的重要性,从而显著提高任务效率和性能。
反思模块的敏感性。反射模块对于纠正错误操作至关重要,它可以防止智体执行错误的计划或陷入无效操作的循环。如上图所示,禁用反思模块会导致六个系统中平均步骤数增加 1.88 倍,成功率下降 33.3%。这凸显了反思机制的重要性,尽管它平均仅占总延迟的 8.61%。
执行模块敏感性。如上图所示,底层执行和控制模块对于系统功能至关重要。禁用该模块会导致任务失败并达到最大步数限制。这可能是因为,如果没有该模块,基于 LLM 的规划系统将被迫处理底层控制决策,从而极大地扩展了决策空间并减慢推理过程。这一发现强调使用 LLM 进行高层规划,同时依靠底层控制来实现精确的机器人智体动作的必要性。开发能够高效管理底层控制的代理对于复杂的具身系统至关重要。
结论 2:记忆模块和反思模块对于任务效率至关重要,而执行模块对于底层控制以防止任务失败必不可少。由于冗余对话和有限的有效利用,通信模块对任务成功率没有显著影响。
建议 3:可以通过提高通信效率、通过上下文摘要增强记忆以及通过自适应纠错强化反思来优化系统性能。将底层执行卸载到专用控制器并采用混合规划框架可以进一步提高任务效率。
规划模块:各种 LLM 模型分析
本地模型处理比较。下图比较本地 LLM 处理(Llama-3.1-8B)和 GPT-4 API 调用在任务性能和系统效率方面的差异。较小的 LLM 模型会降低任务成功率并增加端到端运行时延迟。这主要是由于较小的 LLM 模型推理能力较弱,导致计划不最优、执行错误操作或需要更多步骤才能完成任务。虽然本地模型通常可以减少每次推理的时间,但性能下降和额外的操作最终会导致整体任务运行时延迟更长。
结论 3:尽管每次推理的时间更短,但较小的本地 LLM 会由于规划不最优而增加端到端具身任务运行时延迟并降低成功率。
建议 4:使用 LoRA 进行参数高效的微调,并用外部知识(例如符号推理)增强较小的 LLM,可以提高性能并改进特定任务的推理能力。此外,将规划任务转换为多项选择题可以大大降低生成符合格式要求的输出的复杂性,从而缩小小型本地部署模型与闭源商业模型之间的性能差距。
内存模块:不同内存容量分析
内存模块容量的影响。如图展示内存容量(定义为存储的过去步骤信息量)对任务成功率和完成步骤数的影响。增加内存容量通常会提高任务性能。随着内存容量的增加,成功率提高,而步骤数减少。简单的任务使用较小的内存容量即可获得较高的成功率,而更复杂的任务则受益于更大的内存模块。然而,增加内存容量也会导致每个步骤的信息检索时间延长。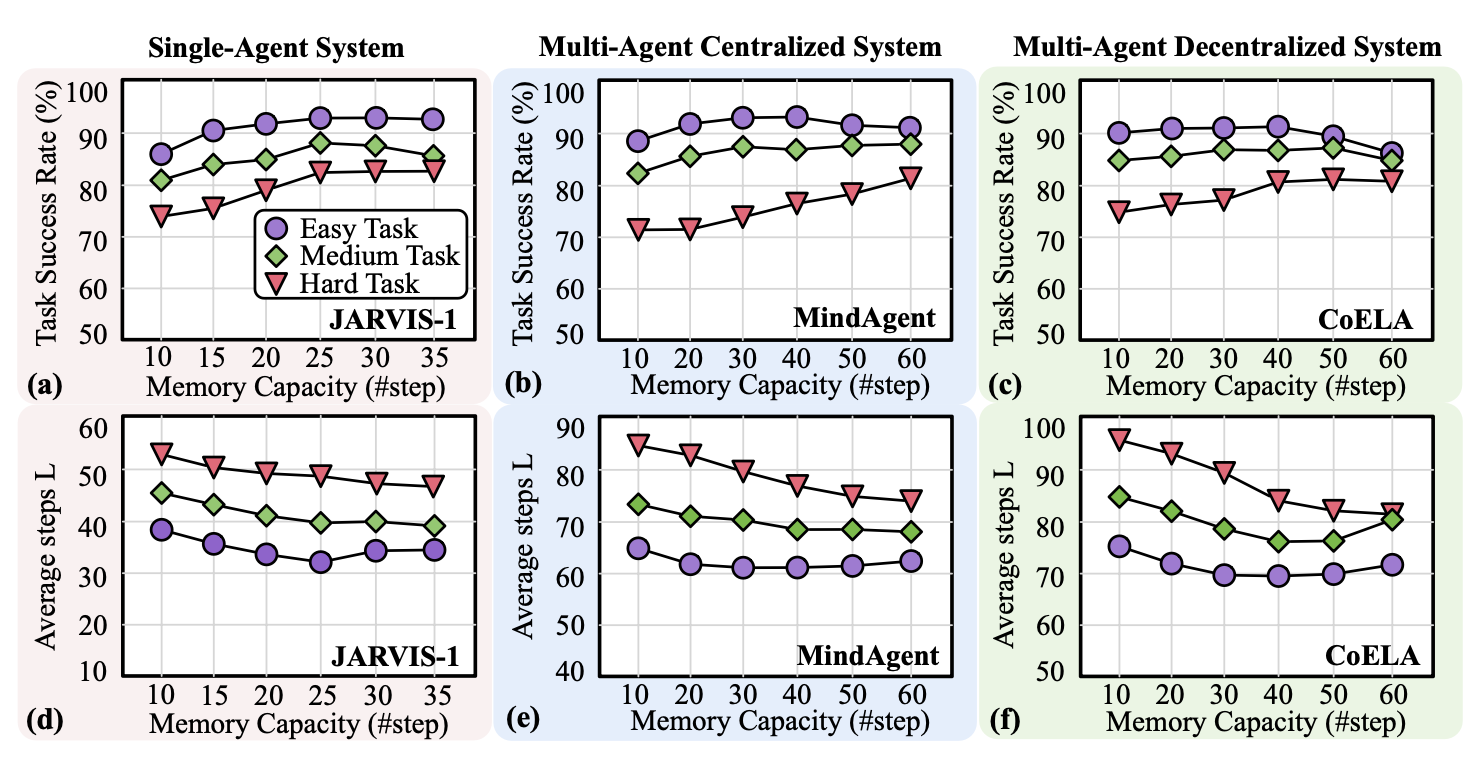
记忆不一致性。上图还强调,过大的记忆容量会导致记忆不一致性问题。当记忆容量非常大时(例如,完整的状态-动作历史记录),性能会略有下降。这是因为随着上下文示例数量的增加,LLM 难以保留关键细节,例如先前的动作和物体位置,从而导致不一致性。此外,基于多模态状态(视觉观察、符号信息、动作历史记录)的检索方法优于仅依赖文本嵌入的方法。
结论 4:增加记忆模块容量可以提高成功率并减少步骤,尤其对于复杂任务而言。然而,过大的记忆容量会引入不一致性并增加每步的检索时间。
建议 5:采用双内存结构可以优化内存模块开销和不一致性:长期内存存储静态环境信息,而短期内存捕获智体状态、任务进度和最近交互的实时更新。
通信模块:token长度分析
提示token长度。如图展示提示token长度如何随工作负载的变化而变化。token长度随着任务的推进而增加,这主要是由于输入token的增加。随着任务的推进,基于 LLM 的规划和通信模块会检索更多信息,并且经常重复相关事件,这会导致提示过长,有时甚至超过 LLM 的token限制。这不仅增加计算成本,还降低 LLM 关注关键细节的能力,从而导致响应并非最优。在多智体系统中,先前智体的对话会被拼接成后续智体的提示,导致token长度在每次迭代中以及随着任务的推进而增长。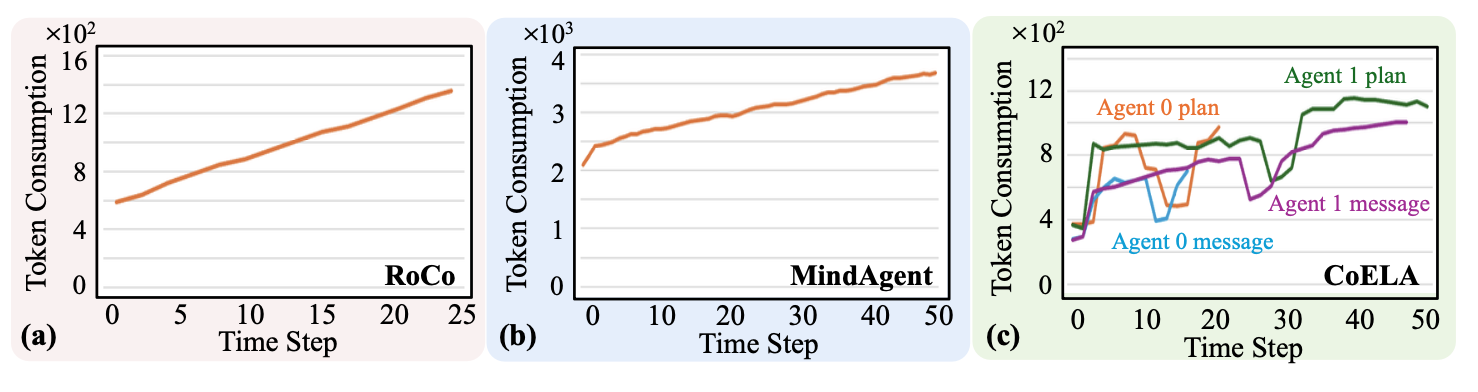
结论 5:提示token长度随着任务的推进而增加,这是由于重复的信息检索和多智体对话的拼接所致,从而导致更高的计算成本,进而降低系统效率。
建议 6:提示长度效率低下的问题可以通过上下文感知管理和压缩技术进行优化,例如总结对话历史、移除冗余信息等。
模块化具身系统:流水线效率分析
系统效率低下。通过延迟分析,还观察到系统级效率低下的几个原因。顺序处理导致系统延迟较高。具体而言,感知-规划-通信-执行流水线在每个步骤都会引入累积延迟,并且高层规划计算中可能存在冗余。此外,低效的通信和规划机制会导致不必要的对话。智体经常发送冗余、重复的消息,并且彼此干扰。例如,在 CoELA 中,通信在规划之前执行,每个智体在每个步骤中都会预先生成消息。然而,在智体最终确定其规划后,只有 20% 的步骤最终导致实际的通信。大多数消息都是不必要的,对任务成功没有贡献,却会增加任务延迟。
要点 6:模块化流水线内部以及跨操作步骤的顺序处理会导致累积延迟和冗余的高级规划计算。低效的通信机制,例如预先生成不必要的消息,会阻碍有效协作并增加延迟。
建议 7:可以通过规划引导的多步骤执行来优化顺序处理。规划模块可以生成一个高级规划,指导在特定时间段内执行多个连续的低级操作,而不是为每个低级操作生成一个新的高级规划。
建议 8:可以通过“先规划后通信”策略来优化冗余通信。在该策略中,规划模块首先确定通信是否必要,只有在认为通信必不可少时,系统才会通过 LLM 启动消息生成。此外,对智体之间的通信进行分层结构化可以进一步提高效率并提升系统整体性能。
可扩展性挑战。多智体系统中三个关键可扩展性挑战:首先,可能的协同动作及其相互依赖性的数量随智体数量的增加呈指数级增长,使得LLM推理变得越来越复杂;其次,LLM上下文不仅包含其他智体当前回合的响应,还包含对话历史、动作以及先前回合的状态;随着智体数量的增加,上下文长度也随之增加,接近LLM token限制,从而增加推理延迟和API成本;第三,更长的提示往往会稀释相关信息,进一步降低任务性能。
下图展示集中式(MindAgent)和分布式(CoELA和COMBO)具身系统在不同智体数量和任务难度级别下的平均任务成功率和端到端延迟。这两种范式在任务性能和系统效率方面具有截然不同的可扩展性特征。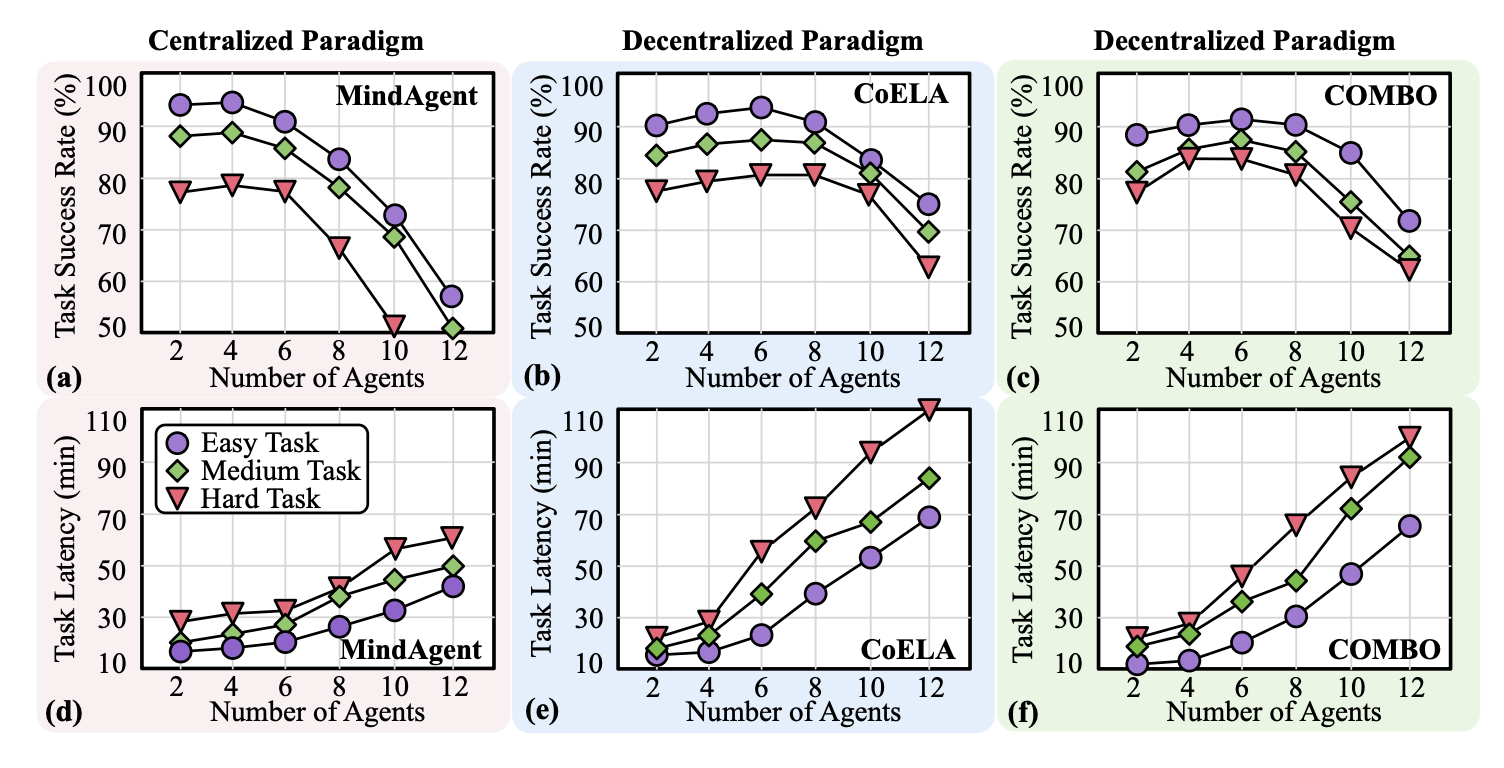
集中式系统可扩展性分析。集中式系统中的任务性能会随着智体数量的增加而急剧下降。如图 a 所示,随着智体数量的增加,任务成功率显著下降,表明单个中央 LLM 规划器难以生成针对复杂推理任务的有效规划,导致在复杂场景下性能欠佳。另一方面,如图 d 所示,集中式系统在系统效率方面展现出更好的可扩展性。这主要是因为它们所需的 LLM 运行次数(API 调用)和数量更少,而这些计算需求会随着智体数量的增加呈线性增长。
去中心化系统可扩展性分析。去中心化具身系统存在可扩展性有限和延迟爆炸的问题。如图 e-f 所示,随着智体数量的增加,每个规划步骤的通信轮次也随之增加,这通常会导致重复且低效的对话,从而造成显著的延迟。智体经常重复之前的建议或提出相同的操作,这会削弱上下文信息,阻碍协作。此外,去中心化系统需要更多的LLM运行(API调用)和token,计算需求随智体数量的平方呈平方级增长。就任务性能而言,随着智体数量的增加,任务成功率最初会提高,但由于大型智体群体中协作效率的降低而下降(如图b-c)。
要点7:随着智体数量的增加,多智体具身系统在执行长期任务时面临可扩展性挑战。集中式系统由于中央规划器难以管理复杂的推理而导致性能下降,而去中心化系统则面临冗余和低效对话以及大型团队协作效率降低带来的效率低下问题。
建议9:多智体具身系统的可扩展性挑战可以通过分层协作范式进行优化。当智体足够接近可以交互时,它们会被分组到集群中,在集群内部进行集中协作,并在集群之间进行分散协作。
建议10:优化通信协议(例如,消息过滤、优先级排序、按需生成)可以最大限度地减少无效通信和延迟。将复杂任务分解为更小的模块化子任务可以实现并行执行并降低计算负担。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)