深度学习 | 优化算法
优化算法有哪些?1 什么是优化算法?1.1 原理1.2 图解2 有哪些优化算法?2.1 SGD2.1.1 思想2.1.2 公式2.2 SGDM2.2.1 原理2.2.2 图解2.2.3 公式2.3 NAG2.3.1 思想2.3.2 公式2.4 AdaGrad2.4.1 思想2.4.2 公式2.5 AdaDelta // RMSProp2.5.1 思想2.5.2 公式2.6 Adam2.6.1 ..
优化算法有哪些?
1 什么是优化算法?
深度学习优化算法经历了 SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam 这样的发展历程。
那什么是优化算法呢?
无论是机器学习还是深度学习,训练的目的在于不断更新参数,优化目标函数(比如最小化损失函数),而这个优化的方法可以有很多不同的方式,最经典的就是梯度下降了,之后还衍生出了上述很多种方法!
小结:优化算法就是在优化目标函数的时候采用的不同算法,不同算法在更新参数的时候用到的方法不同,最经典的算法就是SGD,随机梯度下降。
2 有哪些优化算法?
首先引用一个贼牛逼的框架,可以将下述所有的优化算法囊括到:
- 其中第3和第4步均是一致的,主要区别在于1和2上!
2.1 SGD
2.1.1 思想
即随机梯度下降。传统的梯度下降的时候,每次更新参数用到了所有的样本,而随机梯度下降则是每次随机抽取一个样本来更新参数!所以速度会更快!
其实梯度下降整体来说有三种具体分类:
- GD。每次全部样本更新参数
- SGD。每次随机抽取一个样本更新参数
- MBGD。每次抽取m个样本进行更新参数。
2.1.2 公式

- SGD最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,陷入局部最优,停留在一个局部最优点。
2.2 SGDM
2.2.1 原理
即SGD with Momentum。在随机梯度中引入了动量 Momentum 的概念。
- SGD+一阶动量
- SGD的时候每次前进的方向都是负梯度的方向
- SGDM就是不仅仅考虑负梯度方向,还考虑此时动量的方向(上一步的前进方向的惯性方向),然后将两个方向进行合并,即下一步更新参数的方向!
- SGDM可以抑制SGD的震荡。下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。SGDM全称是SGD with momentum,在SGD基础上引入了一阶动量。
2.2.2 图解
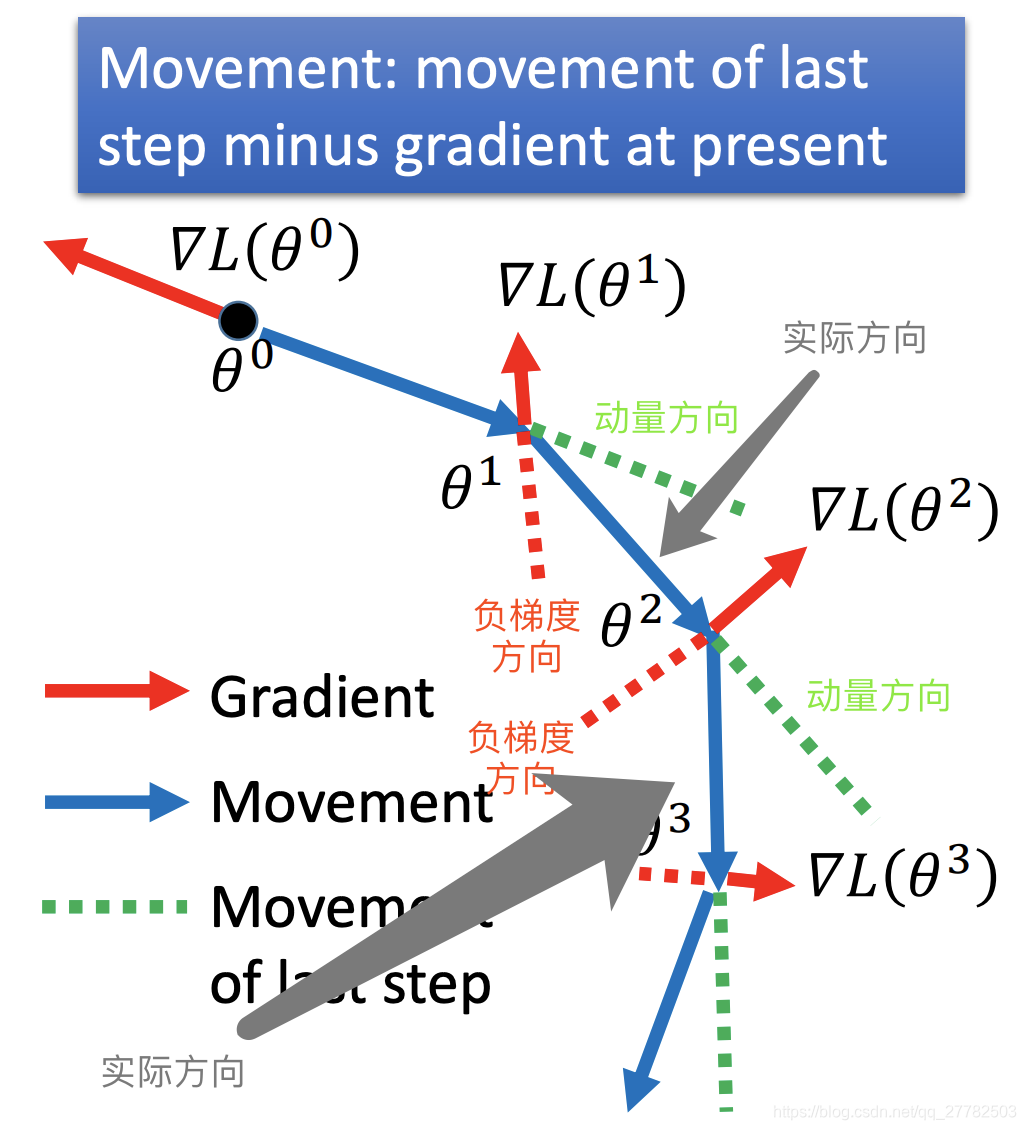
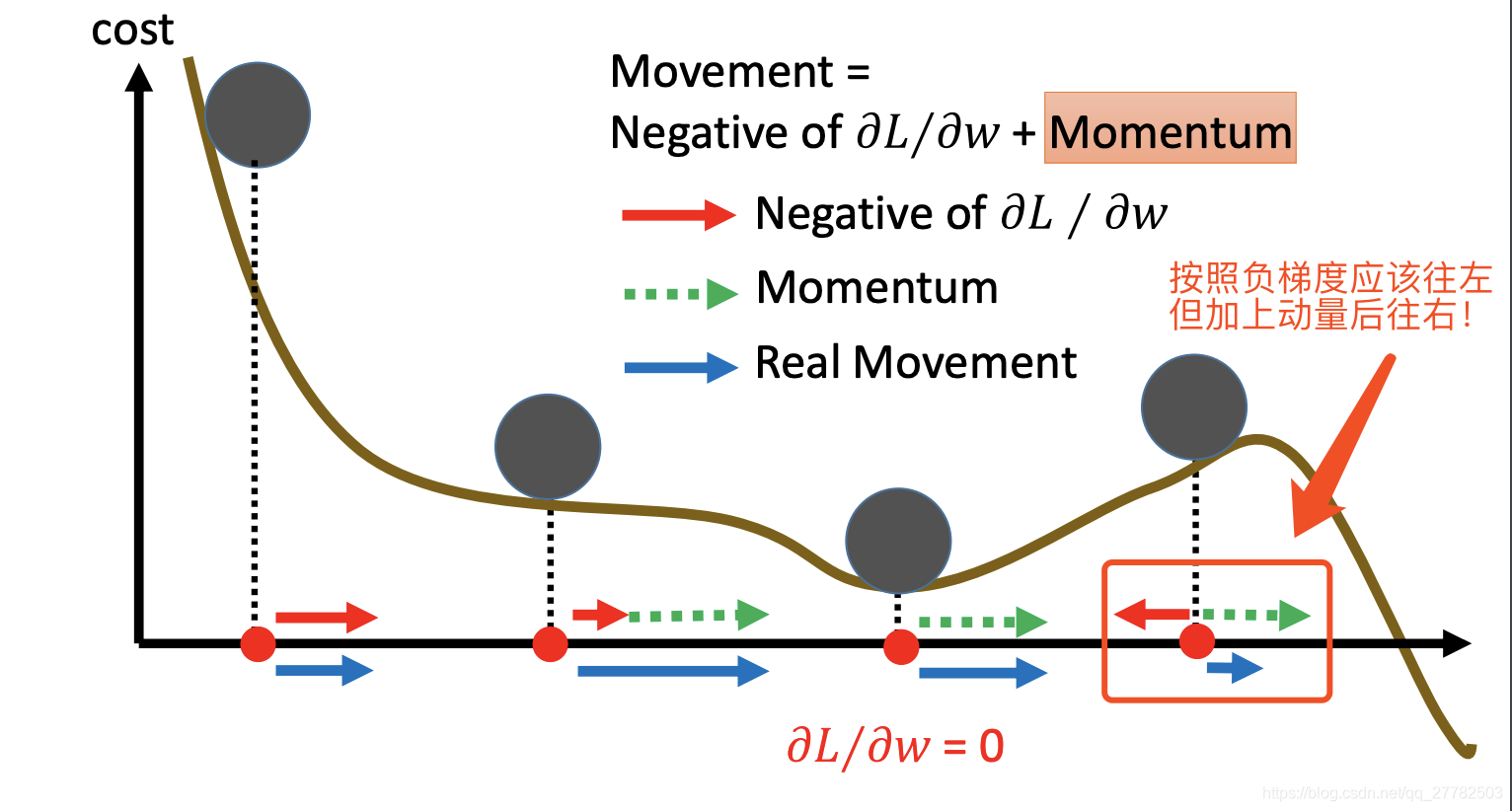
2.2.3 公式
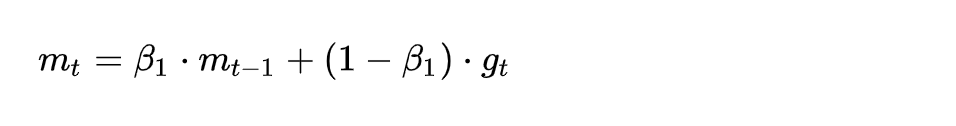
此时没有引入二阶动量的概念,故 V t = I 2 V_t=I^2 Vt=I2
2.3 NAG
2.3.1 思想
- NAG全称Nesterov Accelerated Gradient,在步骤1进行了改进,即求梯度的时候!
- 我们知道在时刻t的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再怎么走。
2.3.2 公式
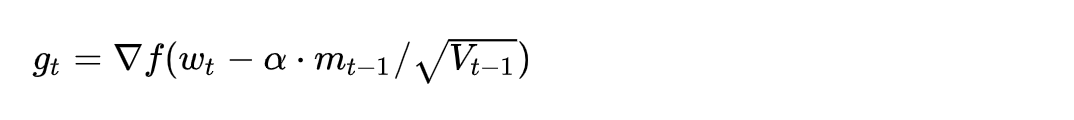
2.4 AdaGrad
2.4.1 思想
- SGD+二阶动量
- 对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。引入二阶动量的概念!即所有梯度的平方和
- 这一方法在稀疏数据场景下表现非常好。但也存在一些问题,学习率单调递减至0,可能会使得训练过程提前结束,即便后续还有数据也无法学到必要的知识。
2.4.2 公式

- 即二阶动量的概念引入了,一阶动量=梯度。
2.5 AdaDelta / / RMSProp
2.5.1 思想
- SGD+二阶动量
- 引入二阶动量的概念,一阶动量=梯度
- 但RMSProp和AdaGrad的区别在于,它在二阶动量之间加入了Delta系数,所以被称为AdaDelta!
2.5.2 公式


- 可以解决二阶动量持续累积、导致训练过程提前结束的问题了。
2.6 Adam
2.6.1 思想
- Adam = Adaptive + Momentum
- 引入了SGDM一阶动量+AdaDelta的二阶动量
- 两个参数 β 1 、 β 2 \beta_1 、\beta_2 β1、β2分别控制一阶动量和二阶动量。
2.6.2 公式


2.6.3 评价
缺点:
- 可能不收敛
- 可能错过全局最优解
2.7 Nadam
2.7.1 思想
- Nesterov(修改梯度计算方式) + Adam = Nadam
- 集成了Nesterov和Adam两种方法
2.7.2 公式
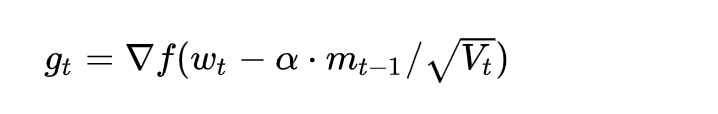
3 其余tips
3.1 到底该用Adam还是SGD?
-
理解数据对于设计算法的必要性。优化算法的演变历史,都是基于对数据的某种假设而进行的优化,那么某种算法是否有效,就要看你的数据是否符合该算法的胃口了。
-
算法固然美好,数据才是根本。
-
在充分理解数据的基础上,依然需要根据数据特性、算法特性进行充分的调参实验,找到自己炼丹的最优解。而这个时候,不论是Adam,还是SGD,于你都不重要了。
3.2 组合策略:Adam+SGD
- 先用Adam快速下降,再用SGD调优
实现问题有两个问题:
- Q1:什么时候切换?
- Q2:学习率如何设置?(因为Adam是二阶动量的学习率,而SGD没有二阶动量的概念)
Q1:当 SGD的相应学习率的移动平均值基本不变的时候。即每次迭代的时候(Adam作为优化器)都计算一下SGD接班人的相应学习率,如果发现基本稳定了,换用SGD。
Q2:SGD在Adam下降方向上的正交投影,应该正好等于Adam的下降方向(含步长)
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)