这也泰裤辣!小样本学习+多模态,拿下Nature!不信你不心动!
最近在Nature看到了一篇效果拔群的文章,作者通过实际上,小样本学习+多模态是近来新兴且热门的方向,在其在CVPR、ECCV、ICLR等顶会都是常客!主要在于,这两者结合,能够发挥各自的优势,帮助我们大幅度提升模型性能和计算效率!尤其是在医疗诊断、自动驾驶、机器人交互等等数据稀缺、标注成本高的领域,更是举足轻重!为了让大家能够掌握领域的主流研究方法,早点发出自己的顶会,我给大家论文原文+开源代码
最近在Nature看到了一篇效果拔群的文章,作者通过把小样本学习与多模态结合,不仅训练数据需求狂降,模型性能也远超SOTA!
实际上,小样本学习+多模态是近来新兴且热门的方向,在其在CVPR、ECCV、ICLR等顶会都是常客!
主要在于,这两者结合,能够发挥各自的优势,帮助我们大幅度提升模型性能和计算效率!尤其是在医疗诊断、自动驾驶、机器人交互等等数据稀缺、标注成本高的领域,更是举足轻重!
为了让大家能够掌握领域的主流研究方法,早点发出自己的顶会,我给大家准备了12种创新思路,原文和源码都有!
论文原文+开源代码需要的同学看文末
论文:Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models
内容
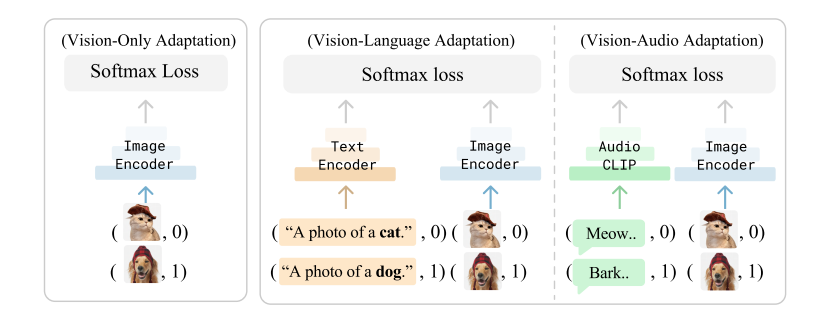
该论文探讨了如何利用多模态信息来提高单一模态任务的学习效率,提出了一种简单的跨模态适应方法,通过将不同模态的样本视为额外的少量样本来提高分类器的性能,利用了CLIP等多模态基础模型的能力,将不同模态映射到同一表示空间,
论文:Active Exploration of Multimodal Complementarity for Few-Shot Action Recognition
内容
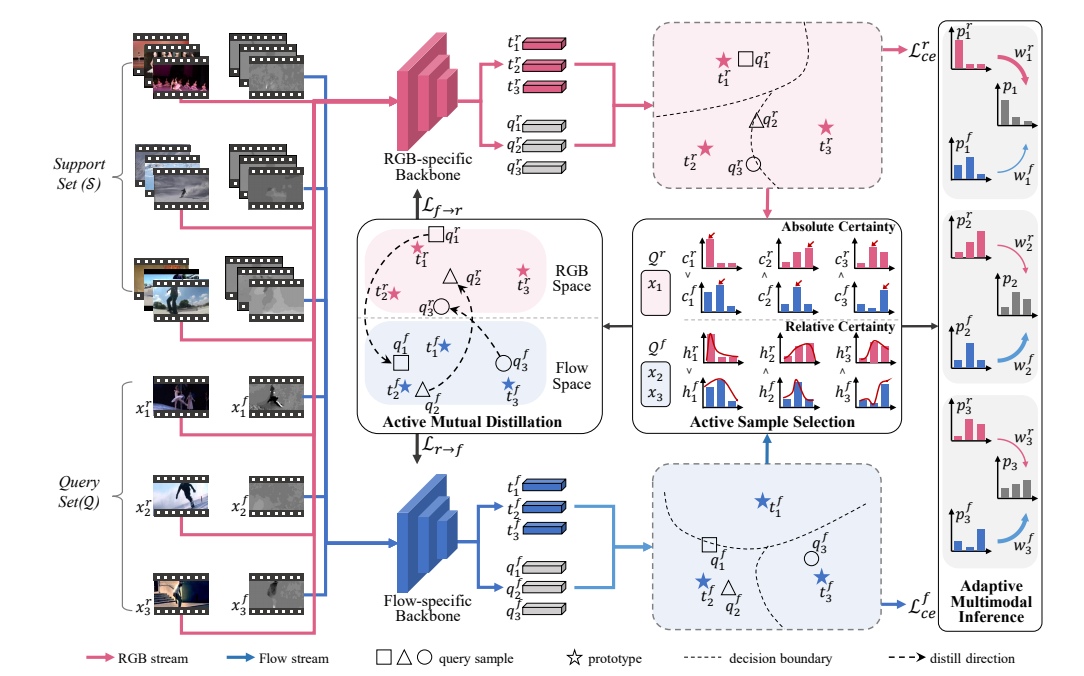
该论文提出了一个新颖的框架AMFAR,用于探索多模态信息在少量镜头动作识别任务中的互补性。AMFAR框架通过主动学习的方法,根据任务特定的上下文信息为每个样本找到更可靠的模态,以改善少量镜头推理过程,旨在通过双向知识蒸馏和适应性融合不同模态的后验分布来提高识别性能。
论文:Multimodal Task Vectors Enable Many-Shot Multimodal In-Context Learning
内容
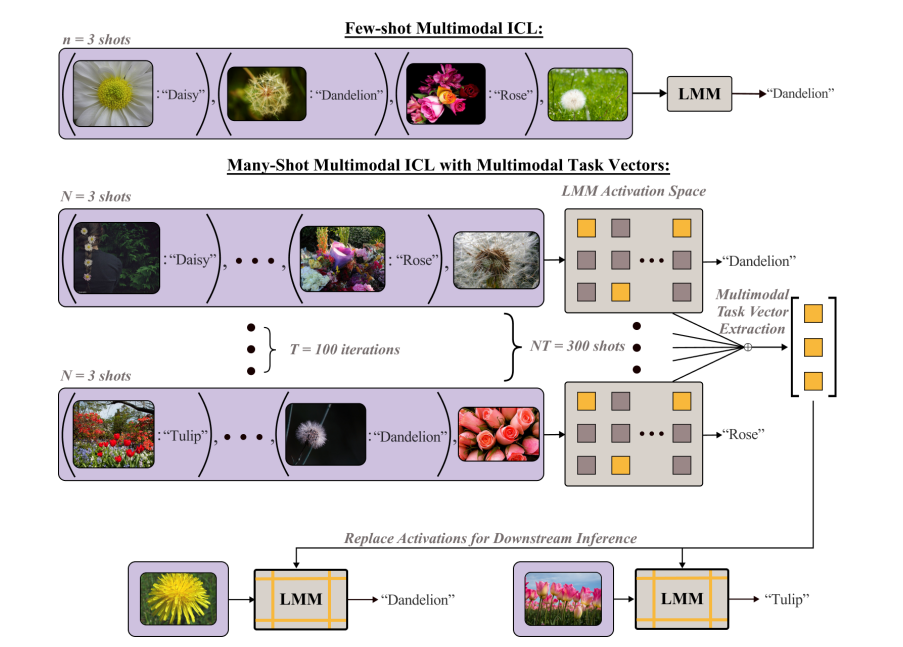
该论文介绍了一种名为多模态任务向量(MTV)的方法,它通过在大型多模态模型(LMMs)的注意力头部中压缩多模态上下文示例的紧凑隐式表示,使得模型能够在多模态、多示例的上下文中进行学习,不仅提高了模型在视觉和语言任务上的性能,而且能够扩展到更多的示例,并且不需要额外的上下文长度即可进行推理,从而有效地解决了多模态领域中上下文长度限制的问题。
论文:Zero-shot learning enables instant denoising and super-resolution in optical fluorescence microscopy
内容
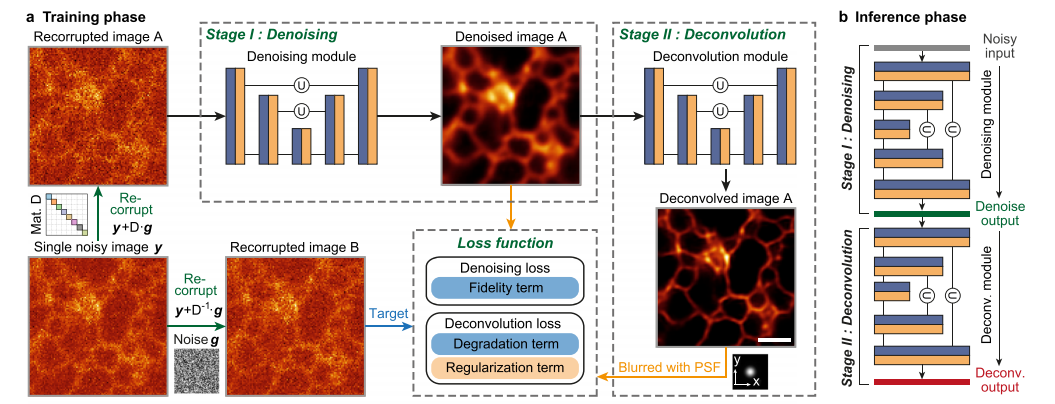
该论文介绍了一种名为零样本去卷积网络(ZS-DeconvNet)的新方法,它能够在无需监督的情况下,通过不到1.5倍的衍射极限和10倍低荧光条件下,即时增强显微镜图像的分辨率,通过利用计算超分辨率技术,包括传统的分析算法和深度学习模型,显著提升了光学显微镜的性能,并且可以广泛应用于多种成像模式,包括全内反射荧光显微镜、三维广视场显微镜、共聚焦显微镜、双光子显微镜、光格光片显微镜和多模态结构光显微镜,实现了从单细胞到多细胞胚胎的亚细胞生物过程的多色、长期、超分辨率2D/3D成像。
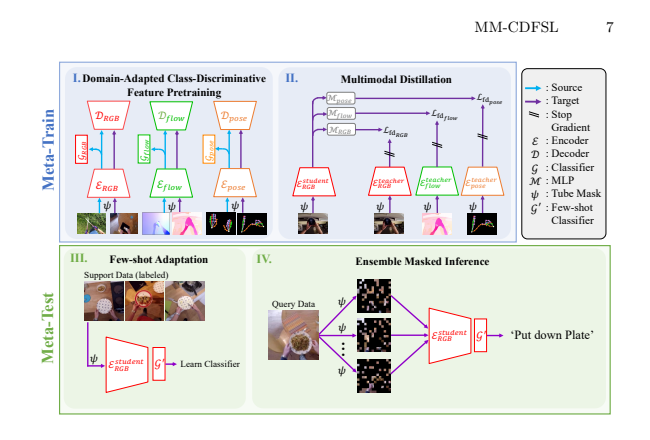
论文:Multimodal Cross-Domain Few-Shot Learning for Egocentric Action Recognition
内容
该论文提出了一种名为MM-CDFSL的方法,旨在解决以第一人称视角(egocentric)动作识别任务中的跨域少样本学习(cross-domain few-shot learning, CD-FSL)问题,通过多模态输入和未标记的目标数据来增强模型对目标域的适应性,并减少实际应用中的计算成本,MM-CDFSL通过在学生RGB模型中引入多模态蒸馏,利用教师模型独立训练源数据和目标数据的各自模态,以及通过集成掩码推理技术减少输入标记的数量,从而在保持动作识别准确性的同时提高推理速度。
关注下方《人工智能学起来》
回复“FLM”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)