moe原理和优化
可以发现这三个矩阵的A矩阵尺寸不一样,不能用batched gemm,所以这里需要用grouped gemm来做,接下来可以看看为什么grouped gemm比batch gemm效果好。最近deepseek比较火,导致moe也比较热门,这里简单看看原理以及如何优化。1、首先每个token经过线性层和softmax选择自己的专家id。3、最后再根据不同专家的权重做一个合并。2、然后根据id选择不同
·
背景
最近deepseek比较火,导致moe也比较热门,这里简单看看原理以及如何优化。
算法
整体思路比较简单,以前attention后面接的是一个FFN网络,现在是的原理如下: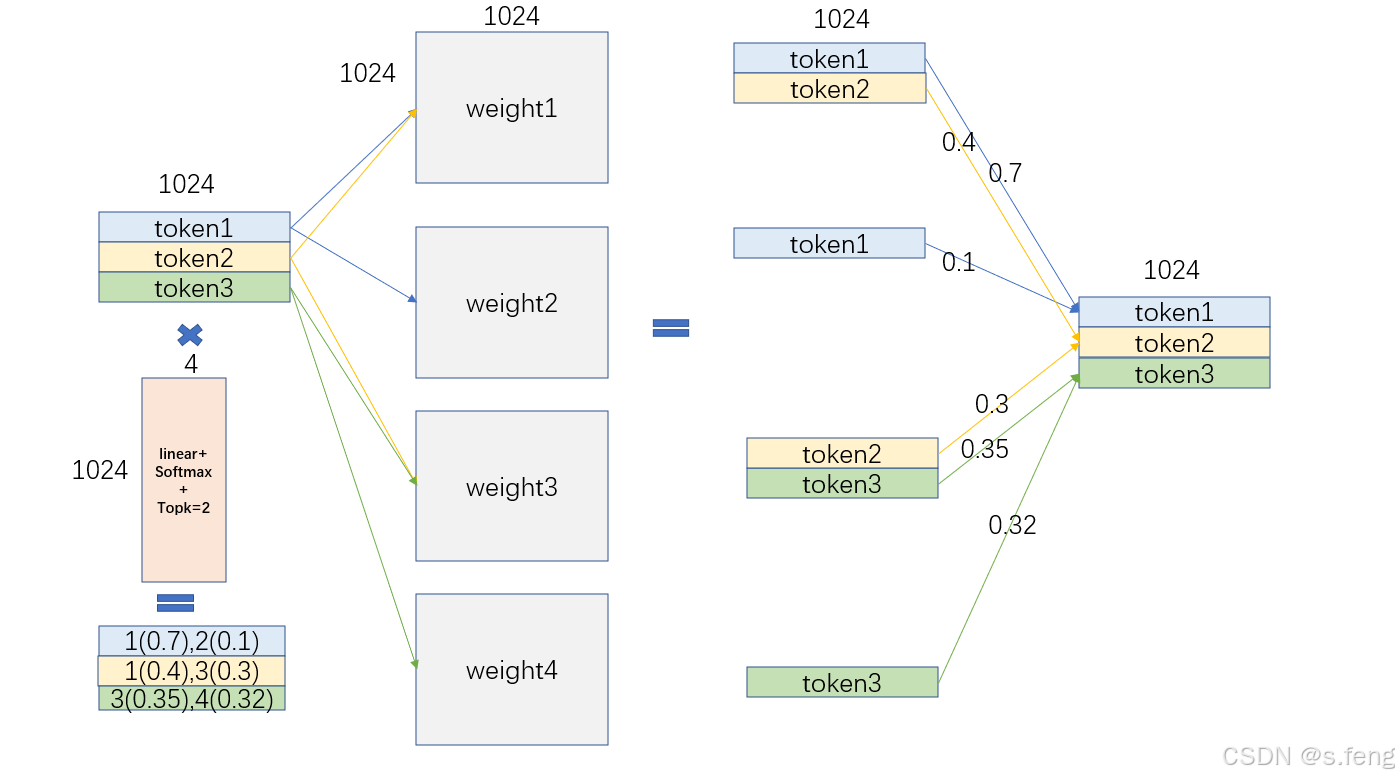
1、首先每个token经过线性层和softmax选择自己的专家id
2、然后根据id选择不同的矩阵参数乘
3、最后再根据不同专家的权重做一个合并
优化
实际推理的时候可能会出现如下状况: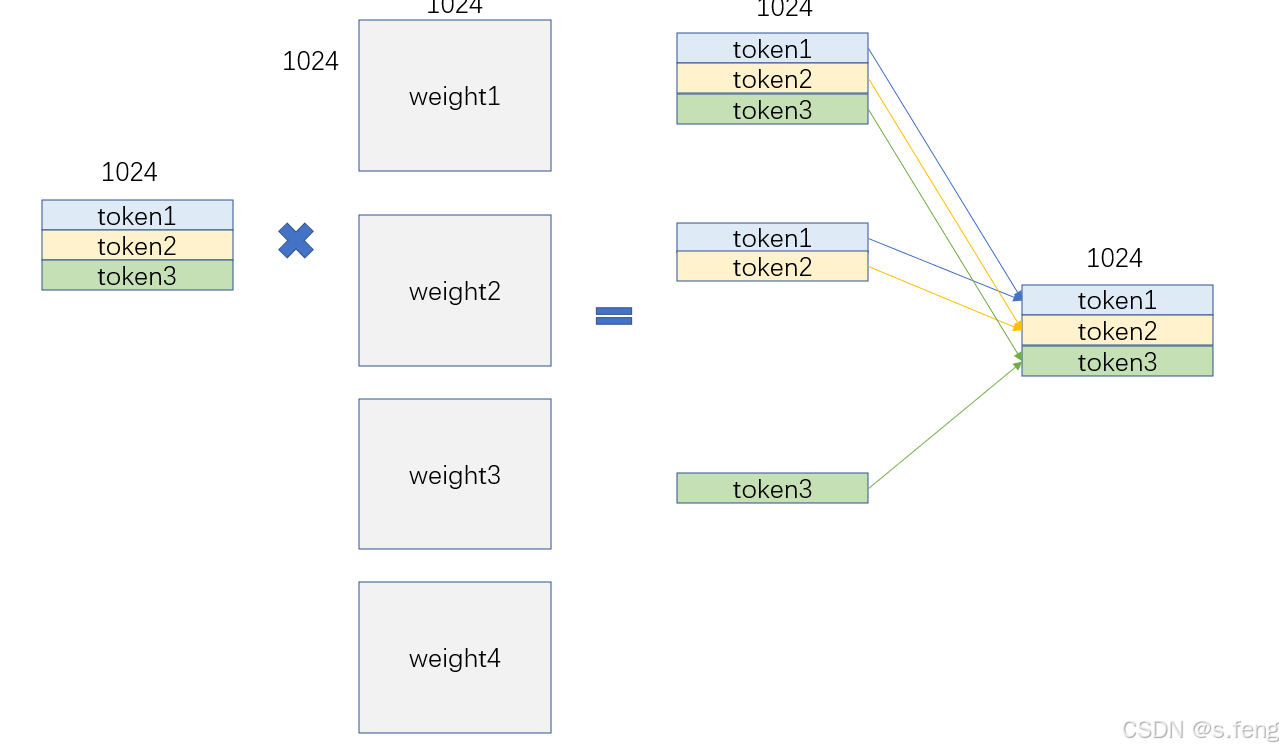
在前向传播的时候,需要做如下三个矩阵乘法: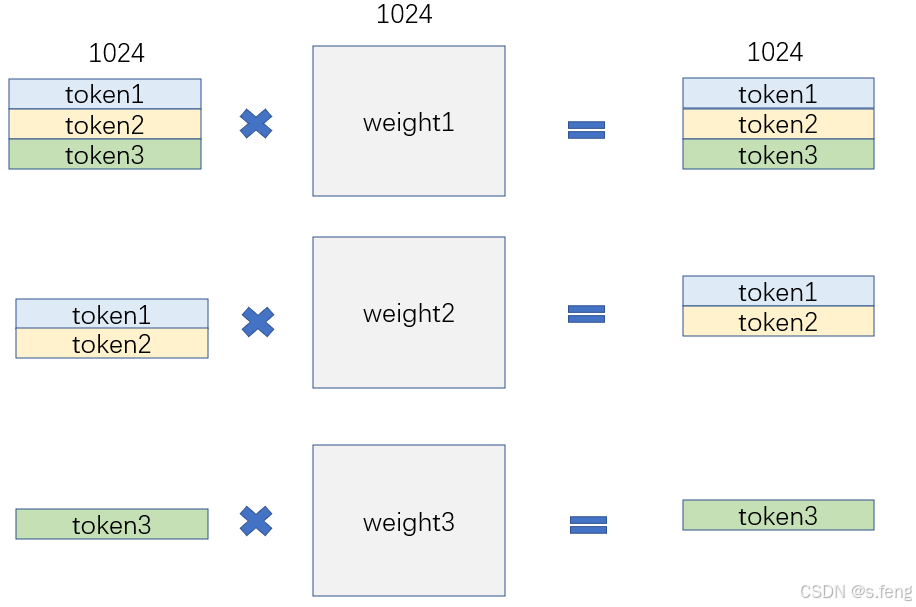
可以发现这三个矩阵的A矩阵尺寸不一样,不能用batched gemm,所以这里需要用grouped gemm来做,接下来可以看看为什么grouped gemm比batch gemm效果好。
未完待续

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)