论文分享➲ Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning
本文认为任务数据集与大型语言模型之间的分布差距是主要的根本原因。为解决这一问题,引入了自蒸馏微调(SDFT)这一新颖的方法,该方法通过利用模型自身生成的经过蒸馏的数据集来引导微调,使其与原始分布相匹配,从而弥合分布差距。
Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning
自蒸馏弥合语言模型微调中的分布差距

📖导读:本篇博客有
🦥精读版、🐇速读版及🤔思考三部分;精读版是全文的翻译,篇幅较长;如果你想快速了解论文方法,可以直接阅读速读版部分,它是对文章的通俗解读;思考部分是个人关于论文的一些拙见,欢迎留言指正、探讨。
目录
🦥精读版
Abstrct
大型语言模型(LLMs)的蓬勃发展已经彻底改变了自然语言处理领域,但针对特定任务对其进行微调时,往往在平衡性能以及保留通用的指令遵循能力方面遇到挑战。在本文中,我们认为任务数据集与大型语言模型之间的分布差距是主要的根本原因。为解决这一问题,我们引入了自蒸馏微调(SDFT)这一新颖的方法,该方法通过利用模型自身生成的经过蒸馏的数据集来引导微调,使其与原始分布相匹配,从而弥合分布差距。在多个基准测试中对 Llama-2-chat 模型进行的实验结果表明,与常规微调相比,SDFT 能有效减轻灾难性遗忘问题,同时在下游任务上可实现相当甚至更优的性能。此外,SDFT 还展现出了维持大型语言模型的有用性及安全性对齐的潜力。我们的代码可在https://github.com/sail-sg/sdft获取。
1. Introduction
近年来,大型语言模型(LLMs)的发展已成为自然语言处理(NLP)领域最具开创性的进展之一。像 GPT-3(Brown et al, 2023)和 PaLM(Chowdhery et al, 2023)这样的大型语言模型在预训练期间利用大量文本语料库,彻底改变了该领域,使其能够在众多任务中实现出色的少样本性能。监督微调(SFT)(Ouyang et al, 2022b; Chung et al, 2022)的引入进一步提升了大型语言模型的能力,尤其在增强其指令遵循能力方面。
有趣的是,即便从相同的基础大型语言模型(Touvron et al, 2023; Bai et al, 2023)开始,监督数据集的微小差异也会导致模型性能出现显著不同(Zhou et al, 2023; Wang et al, 2023)。因此,开源社区见证了大型语言模型变体多样性的快速增长,这些变体融入了各种监督微调数据集和技术,从而提高了它们的实用性和可获取性。
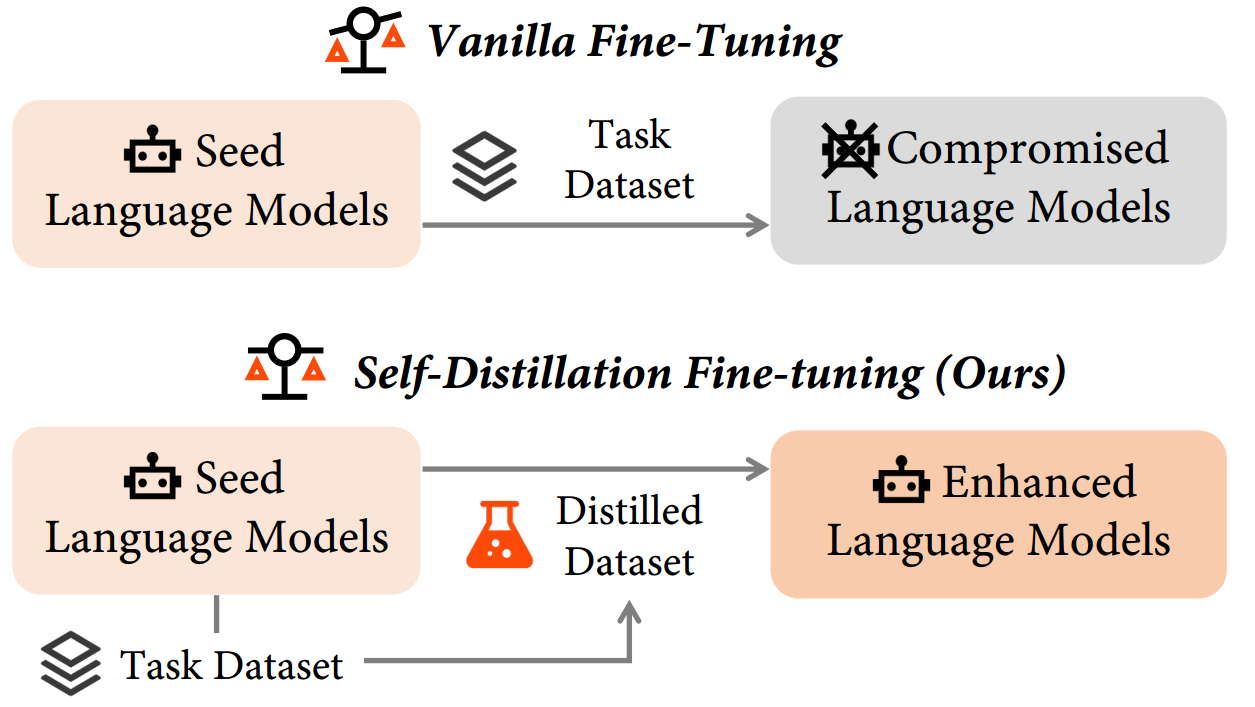
然而,监督微调(SFT)通常侧重于提升通用的指令遵循能力,这意味着经过监督微调的大型语言模型(LLMs)在特定的下游任务中可能会面临挑战。因此,将这些模型重新用作种子语言模型(seed LMs)以便针对特定下游任务进行后续微调,已成为一种颇具吸引力的方法。虽然这种方法看似很有前景,但我们的初步研究表明,通过常规微调同时提升特定任务的性能并保留通用的指令遵循能力是一项挑战,主要原因在于灾难性遗忘问题。与我们的发现相呼应,近期的研究也强调,即便使用无害数据集进行微调,也可能会损害种子语言模型的安全性(Qi et al, 2024; Yang et al, 2023; Zhan et al, 2023; Pelrine et al, 2023)。正如所证实的那样,旨在减轻灾难性遗忘的微调方法目前仍然缺失。
在本文中,我们提出了一种新颖的微调方法 —— 自蒸馏微调(SDFT),以减轻微调过程中的灾难性遗忘问题。我们假设灾难性遗忘源于任务数据集与种子语言模型(seed LMs)之间的分布差距。为解决这一问题,如图 1 所示,SDFT 首先促使种子语言模型生成与任务数据集中原有响应在语义上等同的响应,从而得到经过蒸馏的数据集。改写的一个代表性示例在图 2 中有所展示。在改写之后,这些自行生成的响应在后续微调过程中可作为替代目标。通过这种方法,SDFT 从本质上维持了原始分布,避免了分布偏移,进而保留了相关能力。
我们通过将自蒸馏微调(SDFT)的性能与常规微调以及种子语言模型在各种基准测试中的性能进行比较,对 SDFT 进行了系统评估。这些基准测试包括:(1)多种下游任务,如数学推理、工具使用和代码生成;(2)对通用有用性和安全性对齐的评估。所有基准测试的结果都表明了 SDFT 相较于常规微调的优越性。例如,在 OpenFunctions 数据集(Patil et al, 2023)上进行常规微调,会导致在 HumanEval 基准测试(Chen et al, 2021)中的通过率(pass@1)从 13.4 大幅下降到 9.8,降幅达 27%。相比之下,SDFT 不仅减轻了这种下降趋势,还将准确率略微提高到了 15.2。对我们所提方法的深入分析表明,增加用于微调的蒸馏数据集的比例会使灾难性遗忘现象减少,从而证实了 SDFT 是通过弥合分布差距来减轻灾难性遗忘的。
2. 相关工作
微调 微调是一种在提升模型于下游任务性能方面较为常用的策略,在包括编码(Roziere et al,2023;Luo et al,2024)、算术(Luo et al,2023a)、医疗保健(Jin et al,2023)以及金融(Wu et al,2023)等诸多领域都有所体现。常规微调直接将目标响应的对数似然最大化。与我们的工作类似,自博弈微调(Chen et al,2024)使用同一个大型语言模型既作为生成器又作为判别器,引导模型更倾向于标注响应而非生成输出。由于大型语言模型的分布最终会与训练数据的分布趋同,所以该方法在微调过程中并不能减轻遗忘现象。
持续学习 微调能使模型适应新的数据分布,从而提高它们在下游任务上的效能。然而,这一过程可能会导致先前习得的知识丢失,这一问题被称为灾难性遗忘(French,1999)。一个相关领域是持续学习(Kirkpatrick et al,2017;Lopez-Paz and Ranzato,2017),其旨在让模型在获取新知识的同时减轻此类遗忘现象。传统方法通常依赖于保留历史数据以便重放(Scialom et al,2022;Luo et al,2023b)、计算参数重要性(Kirkpatrick et al,2017;Aljundi et al,2018),或者为不同任务分配不同的神经元(Mallya and Lazebnik,2018)。然而,由于大型语言模型(LLMs)具有庞大的参数和任务空间,再加上原始训练数据集常常无法获取,这就降低了这些既有技术的可行性,因此对大型语言模型进行微调尤其具有挑战性(Kirkpatrick et al,2017;Lopez-Paz and Ranzato,2017;Scialom et al,2022)。尽管近期的研究(Luo et al,2023b;Scialom et al,2022)强调了持续学习对语言模型(LMs)的重要性,但针对大型语言模型却鲜有可行的解决方案。在本文中,我们对大型语言模型微调过程中的灾难性遗忘问题进行了全面评估,并提出了一个专门为大型语言模型设计的简单而有效的策略。
对齐 随着大型语言模型(LLMs)能力的不断扩展,其生成有害内容的潜在可能性也在增加,从而引发了重大的安全担忧(Perez et al, 2022; Ganguli et al, 2023)。作为回应,人们已经提出了各种各样的策略来使大型语言模型与人类的道德标准保持一致,并防止生成有害内容。常见的方法包括指令微调(Ouyang et al, 2022a; Touvron et al, 2023)、基于人类反馈的强化学习(Ouyang et al, 2022a; Bai et al, 2023)以及自对齐技术(Sun et al, 2023)。通过采用这些对齐技术,大型语言模型在实用性和安全性之间达成了一种微妙的平衡(Bianchi et al, 2023; Qi et al, 2024)。虽然这些方法在安全对齐方面已经显示出了成效,但它们并没有涵盖因微调而产生的其他风险。近期的研究表明,即使用无害数据进行微调也可能导致安全性受损(Qi et al, 2024; Yang et al, 2023; Zhan et al, 2023; Pelrine et al, 2023)。我们所提出的策略能够有效地减轻这种安全性下降的情况。
基于提示的学习 近来,在大型语言模型(LLMs)中使用提示来生成用于模型训练的响应这一做法引起了广泛关注。像 self-instruct(Wang et al, 2022)和 WizardLM(Xu et al, 2024)等方法利用生成的响应进行监督微调,其中 WizardLM 采用 GPT-4 作为生成器。其他方法,如 Self-Refine(Madaan et al, 2024)和 Self-Reward(Yuan et al, 2024),则将这些响应作为反馈来迭代地精炼模型的输出。与之不同的是,我们的工作引入了一个全新的视角,即利用这些响应来弥合分布差距并解决微调过程中的灾难性遗忘问题。
3. 方法
在本节中,我们首先概述微调的过程,随后介绍我们所提出的自蒸馏微调方法及其实施细节。
3.1 微调LLMs
虽然大型语言模型在各种任务中表现出卓越的能力,但在需要微调的下游任务中,它们经常会遇到限制。具体来说,我们将需要进一步微调的语言模型称为种子语言模型,记为 f f f,由参数 θ θ θ 参数化。种子语言模型通常经过通用的监督微调,这表明它能够将由任务描述 c ∈ C c ∈ C c∈C 上下文化的任何自然语言指令 x ∈ X x ∈ X x∈X 映射到其相应的输出 y ∈ Y y ∈ Y y∈Y。

种子语言模型的微调过程可以概述如下:对于具有上下文 c t c^t ct 的目标任务 t t t,每个任务示例 ( x t , y t ) (x^t, y^t) (xt,yt) 被用于更新模型参数。此更新旨在最小化数据分布与语言模型分布之间的差异,如下所示:

它试图最小化在给定上下文 c t c^t ct 和输入 x t x^t xt 的情况下目标输出 y t y^t yt 的负对数似然,相对于模型参数 θ θ θ。当生成的响应 y ^ \hat{y} y^ 与 y t y^t yt 匹配时,即微调后的语言模型的分布与任务数据集分布一致时,LFT 收敛。
3.2 自蒸馏微调
随着种子语言模型的分布趋向于任务数据集的分布,它自然会提高在目标任务上的性能。然而,普通的微调通常容易在通用指令遵循能力和安全对齐方面遭受灾难性遗忘。
为了解决这个问题,我们提出自蒸馏微调(SDFT),以更好地使任务数据集的分布与种子语言模型的分布对齐。
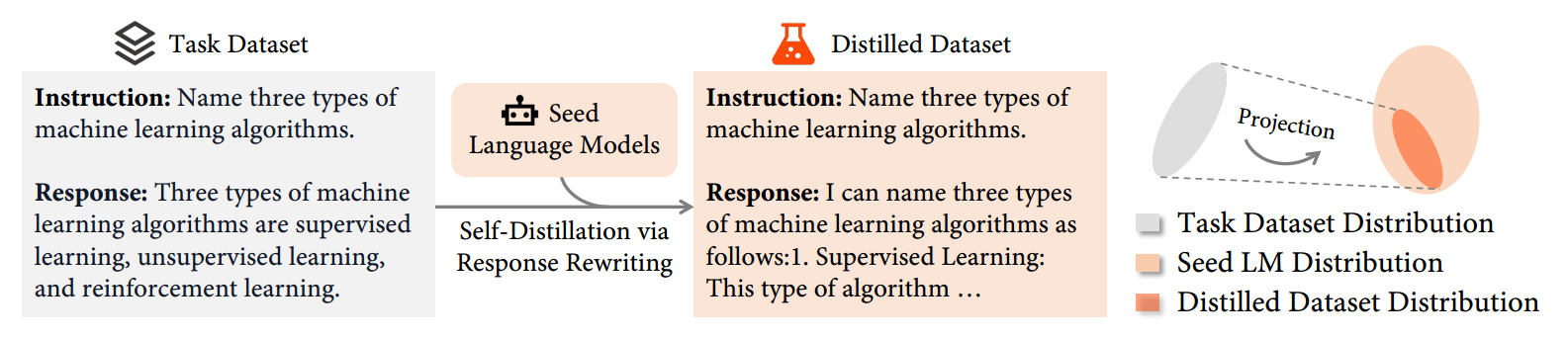
如图 2 所示,SDFT 的初始步骤涉及提示种子语言模型将原始响应 y t y^t yt 重写为 y ~ \tilde{y} y~:

这一步标志着我们的方法与普通微调的主要区别,因为它涉及将原始响应映射到种子语言模型分布内的响应。为了完成重写,我们使用自蒸馏模板,这对种子语言模型的要求最小,只需要它遵循我们的指令进行响应重写。这个提示的具体说明将在后面详细阐述。
接下来,为了确保蒸馏后响应的质量,我们使用简单的启发式方法来评估蒸馏后的响应。例如,在数学推理问题中,我们从蒸馏后的响应 y ~ \tilde{y} y~ 中提取最终答案,并与原始响应 y t y^t yt 中的答案进行比较。否则,我们保留原始响应。我们将这个有条件的选择过程形式化为:

最后,蒸馏后的响应被用作原始响应 y t y^t yt 的替代进行微调,即损失变为:

因此,通过使用蒸馏后的数据集而不是任务数据集,分布差距得以减小,如图 2 的右侧所示。

3.3 蒸馏模板
在我们的工作中,蒸馏模板起着至关重要的作用。它被设计为与任务无关,能够无缝应用于各类任务而无需修改。在此框架内,该模板将任务数据集中的原始响应指定为 “参考答案”,并引导模型相应地生成响应。我们大多数实验中所采用的模板如图 3 所示。在处理涉及数学推理的数据集时,我们会对模板稍作调整,以更好地适应推理过程。有关这些模板的更多详细信息可在附录 B 中找到。
4. 实验
在本节中,我们首先介绍用于微调及评估目的的数据集。随后,我们对普通微调方法以及我们提出的自监督蒸馏微调(SDFT)方法在各类任务(包括数学推理、代码生成以及工具使用)中所获得的实验结果进行对比分析。最后,我们评估这两种方法对安全性、通用知识以及实用性方面的影响。
4.1 实验设置
我们在大多数实验中都将 Llama-2-7b-chat 模型(Touvron 等,2023)用作种子语言模型(LM),除非另有明确说明。由于计算资源有限,我们在进行常规微调以及我们所提出的自监督蒸馏微调(SDFT)时均运用了低秩自适应(LoRA)技术(Hu 等,2022)。
为确保公平比较,我们对这两种方法的几乎所有超参数都保持一致。对于包含超过 10,000 个示例的数据集,我们随机选取 2,000 个示例用于微调,以保证大多数数据集在规模上具有可比性。对于 OpenHermes 数据集,我们随机选取 20,000 个示例,来验证自监督蒸馏微调(SDFT)方法在更大的混合数据集上的效果。更多实验细节可在附录 A 中找到。
4.2 用于微调和评估的数据集
我们在多种数据集上对种子语言模型(LM)进行微调,这些数据集涵盖了单任务和多任务场景。然后,我们会评估种子模型以及经过微调的模型在各类不同任务中的性能表现。用于微调与评估的数据集分类如下:
单任务数据集。 对于单任务数据集,我们探索在微调过程中提升语言模型的数学推理、工具使用以及代码生成能力。利用 GSM8K 数据集(Cobbe 等,2021)来提升数学推理能力,该数据集包含 8800 个按照小学水平设计的高质量算术应用题。通过利用诸如 Gorilla OpenFunctions 数据集(Patil 等,2023)这类函数调用数据集来评估工具使用熟练程度。此外,使用 MagiCoder 数据集(Wei 等,2023)来提升代码生成技能,而使用 HumanEval 数据集(Chen 等,2021)进行评估。
多任务数据集。 我们使用四个高质量数据集来评估我们的方法在多任务微调场景中的有效性:Alpaca(Taori 等,2023)、Dolly(Conover 等,2023)以及 LIMA(Zhou 等,2023)。Alpaca 数据集涵盖了多种任务,包括算术、编码以及问答等。它是通过 text-davinci-003 模型利用 Self-Instruct 方法(Wang 等,2022)生成的。Dolly 数据集由七种不同的任务组成,像开放式问答、信息提取以及摘要等任务。LIMA 数据集涵盖了广泛的主题,并且是从多个来源精心整理而来的。OpenHermes 数据集主要由来自各种公开数据集的 GPT-4 生成的数据组成,且经过了筛选以去除拒答内容。
安全性评估。 我们利用 Advbench 数据集(Zou et al,2023)中的有害行为指令来进行评估,按照 Qi et al(2024)的做法,通过关键词匹配来评估模型输出的安全性。我们将安全响应的比例定义为原始安全率。此外,我们会按照 Zou et al(2023)所述的方式,通过在指令后附加对抗性后缀来模拟越狱尝试。在此条件下的安全率被称作越狱安全率。
实用性评估。 我们采用 AlpacaEval(Li et al,2023)来评估各类模型的实用性。该工具包含一个数据集以及相关的评估指标,便于将生成的输出与 Text-Davinci-003 的响应进行比较,比较是基于源自多个数据集的 805 条详细指令所构成的多样化集合开展的。我们会报告胜率,即根据 GPT-4 的评判,响应优于 Text-Davinci-003 所生成响应的实例所占的比例。
知识评估。 语言模型(LMs)的通用知识是通过使用 OpenLLM 排行榜中的基准进行评估的,具体包括 MMLU(Hendrycks et al,2021)、TruthfulQA(Lin et al,2021)、ARC(Clark et al,2018)、HellaSwag(Zellers et al,2019)以及 Winogrande(Sakaguchi et al,2021)。这些数据集能够衡量模型在多个领域内的事实性知识和常识性知识。
4.3 SDFT在下游任务中取得更好的结果
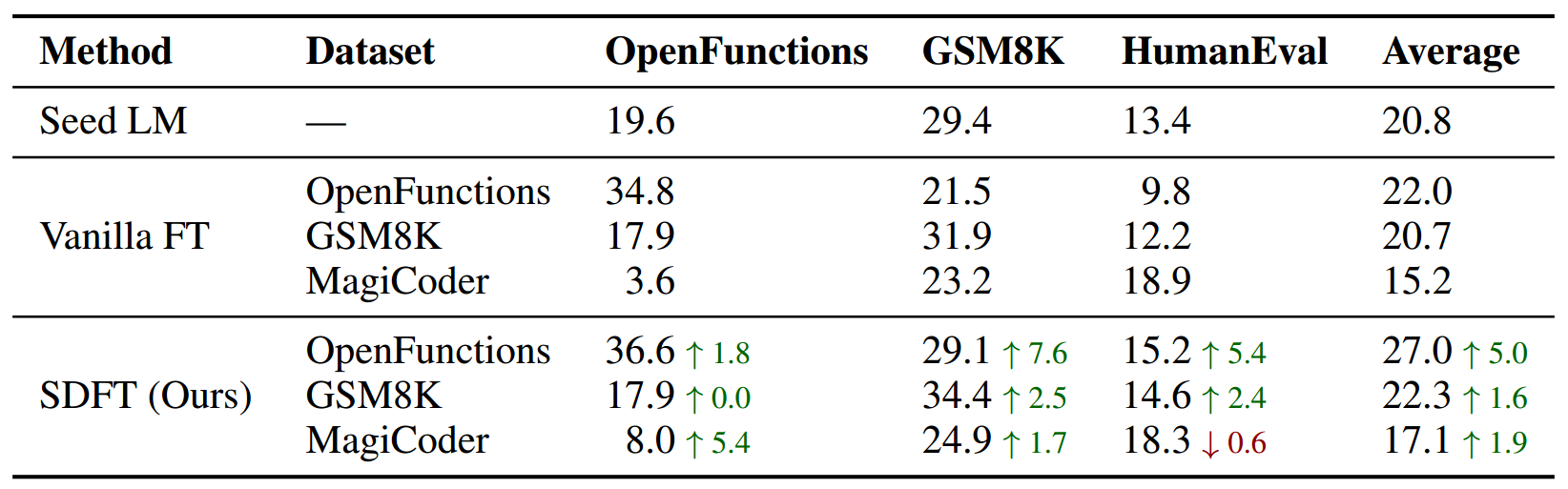
表 1 展示了在三个下游任务上进行微调的结果。结果表明,虽然常规微调能够提升模型在目标任务上的效能,但也会导致其在其他任务上的性能显著下降。例如,如表中第一行所示,使用 OpenFunctions 数据集进行微调会使模型的编码能力降低,从 13.41 降至 9.76。在数学推理能力方面也观察到了类似的下降情况,在 GSM8K 数据集上的准确率从 29.42 下降到了 21.53。
此外,所提出的自监督蒸馏微调(SDFT)能够有效缓解这种性能下降的情况。在上述实例中,该模型保留了其数学推理能力,达到了 29.11 的准确率,与种子模型的性能(29.42)十分接近。对于在 HumanEval 上评估的编码性能,还有些许提升,性能从种子模型的 13.41 提高到了 15.24。当聚焦于目标任务时,自监督蒸馏微调(SDFT)的表现也优于常规微调,其准确率达到了 36.61,而常规微调的准确率为 34.82。

4.4 SDFT保持对齐性
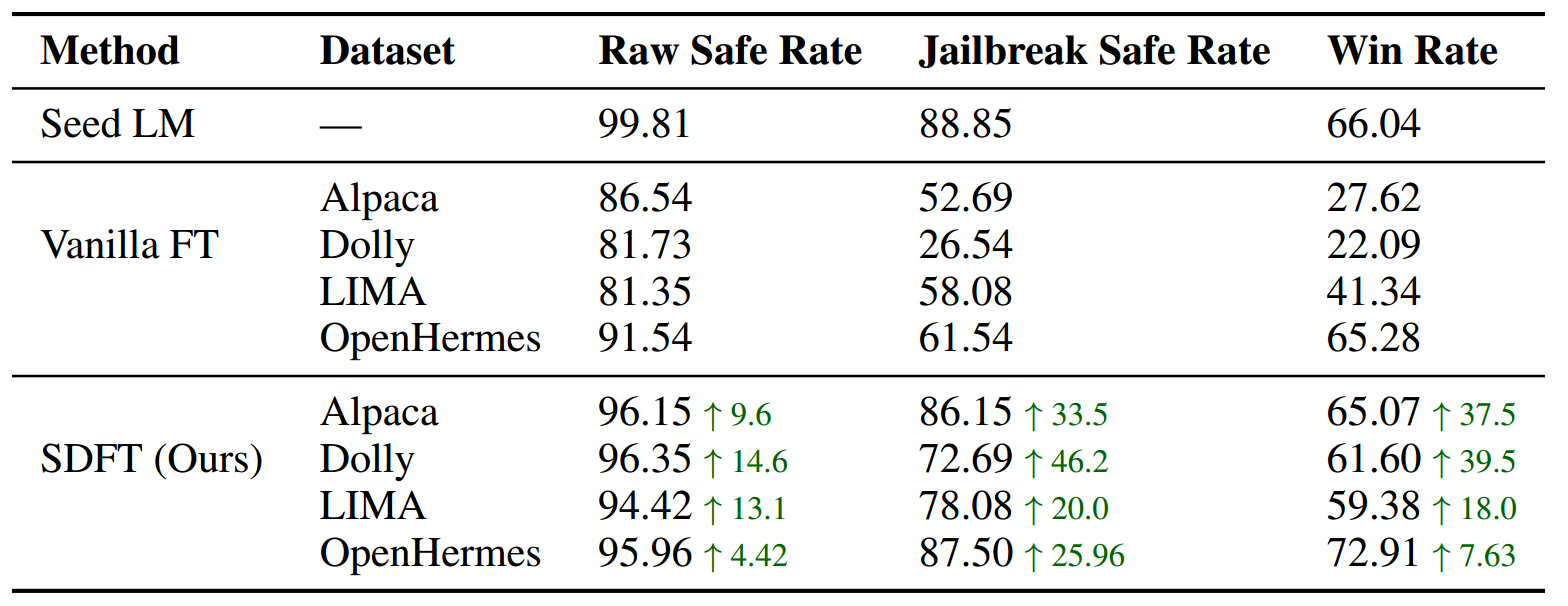
如表2中的研究结果所强调的那样,在大多数数据集上进行微调已被证明会导致安全对齐性和整体实用性方面出现显著下降。例如,在GSM8K数据集上进行微调后,安全率从99.81降至82.12,越狱安全率从88.85降到54.81,在AlpacaEval上的胜率也从66.04减少至23.38。相比之下,我们提出的自监督蒸馏微调(SDFT)方法有效地缓解了这种下降情况,使原始安全率和越狱安全率分别提高了5和11。值得注意的是,与种子模型相比,胜率还有些许提升,分数从66.03提升至66.73。
表3展示了在包含多个任务的指令遵循数据集上进行微调后的评估结果。由于这些数据集的目标任务未明确指定,我们在微调后将评估重点放在安全性和整体实用性上。与表2中指出的模式一致,在Alpaca、Dolly和LIMA数据集上进行微调通常会导致安全性和实用性指标出现显著下降。我们观察到这三项指标均出现了明显的下降,每项指标大致下降了20。相比之下,我们提出的自监督蒸馏微调(SDFT)方法有效地缓解了这种下降情况,将下降幅度限制在10以内。同样地,在OpenHermes(Teknium,2023)数据集上进行常规微调会导致安全对齐性降低。与之相反,自监督蒸馏微调(SDFT)有效地缓解了这种性能下降情况,将越狱安全率从61.54提高到了87.50。
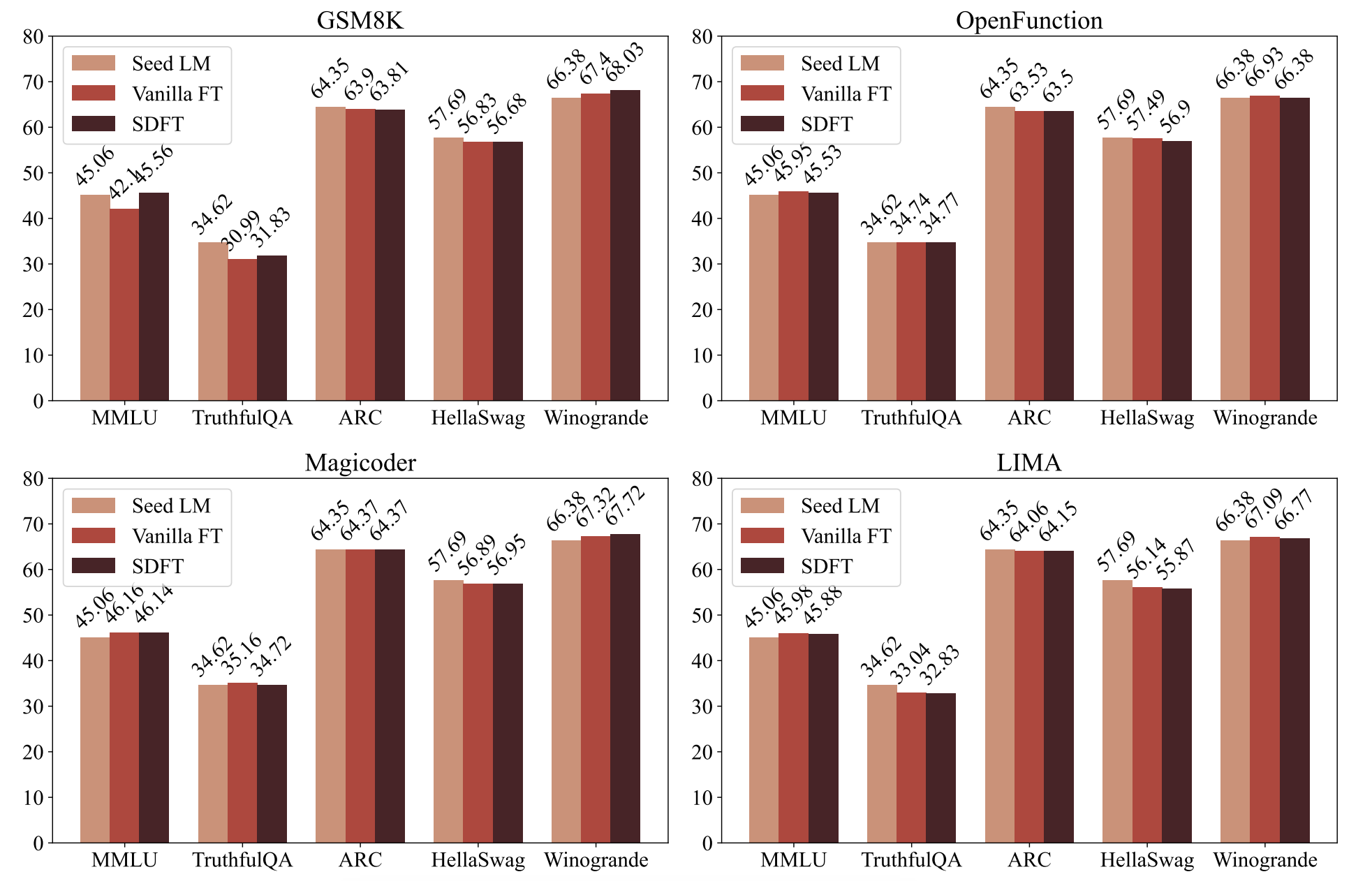
4.5 通用知识保持完整
图 4 展示了关于通用知识的结果。尽管常规微调会损害下游任务性能以及对齐性,但模型的通用知识能力相对未受影响。例如,在 OpenFunctions 数据集上进行微调后,经过微调的模型与种子语言模型(LM)之间的性能差异小于 1。在使用自监督蒸馏微调(SDFT)进行微调后,也能观察到同样的情况。
5. 分析
在本节中,我们进行了详细分析,以了解分布偏移对灾难性遗忘的影响。除了第 4 节中概述的评估指标外,我们还引入了四个补充指标来评估分布偏移的程度。我们利用种子模型和经过微调的模型在 Advbench(Zou 等,2023)数据集上生成响应,并对这些响应进行对比分析。
具体而言,我们计算经过微调的模型的 BLEU-4 和 ROUGE-L 分数,以种子模型的输出作为参考,来评估分布偏移的程度。我们还利用 Sentence-BERT(Reimers and Gurevych,2019)来获取句子嵌入向量,并按照 Zhang 等(2023)的做法,利用这些嵌入向量之间的余弦相似度进行分析。最后,我们通过将更新后的参数与种子模型的参数进行比较来量化参数偏移的程度,将它们之间的距离作为参数偏移幅度的衡量指标。BLEU-4、ROUGE-L 以及嵌入向量相似度得分越低,分布偏移就越大。相反,参数偏移与参数变化的范数成正比。
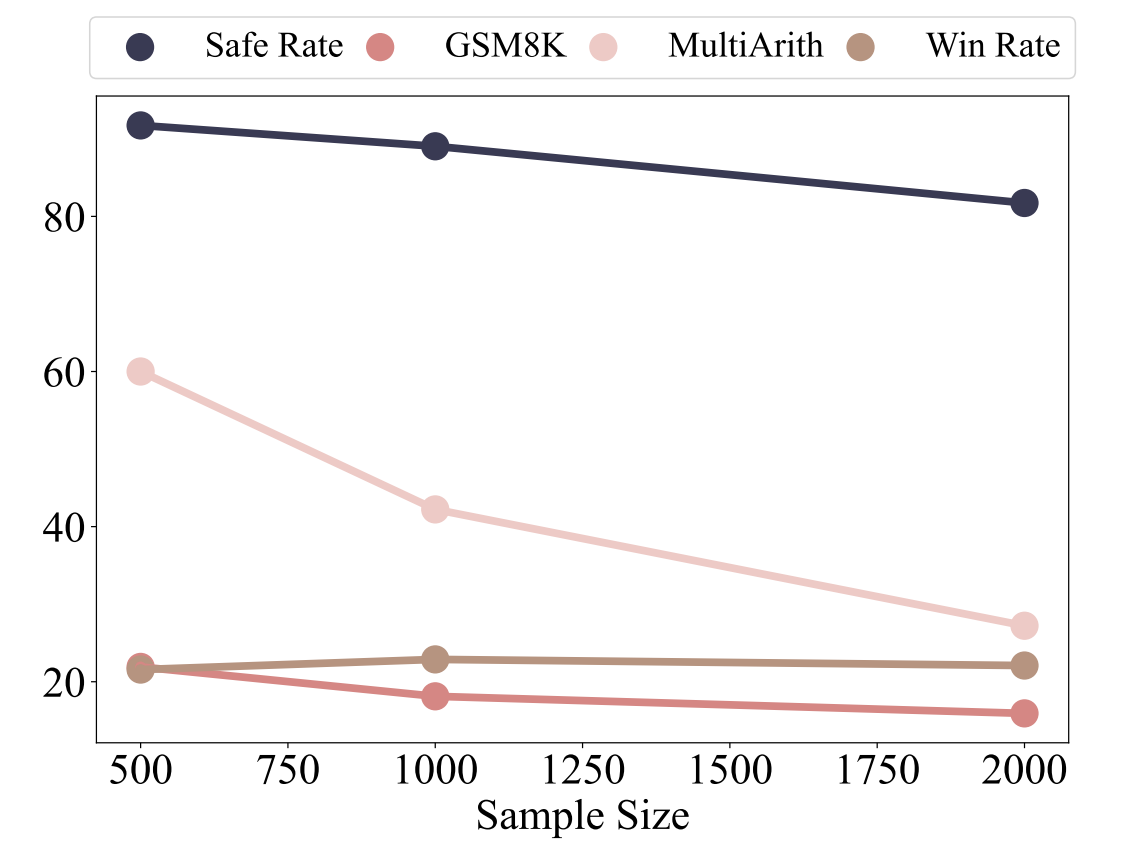
图 5:随着用于微调的数据增多,模型在包括数学、安全对齐性以及指令遵循能力等各类基准测试中的性能有所下降。
|
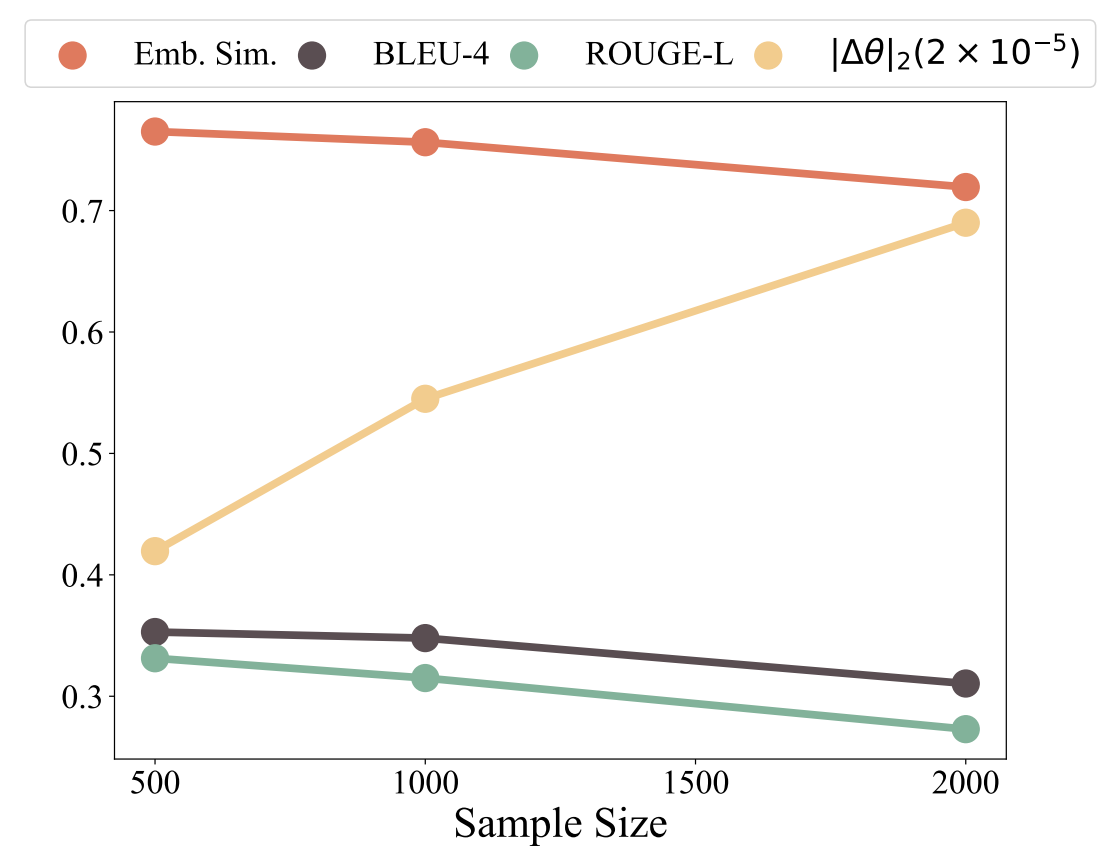
图 6:随着样本量的增加,BLEU-4、ROUGE-L 以及嵌入相似度全都下降,而参数偏移幅度增大,这表明分布偏移的程度加剧了。
|
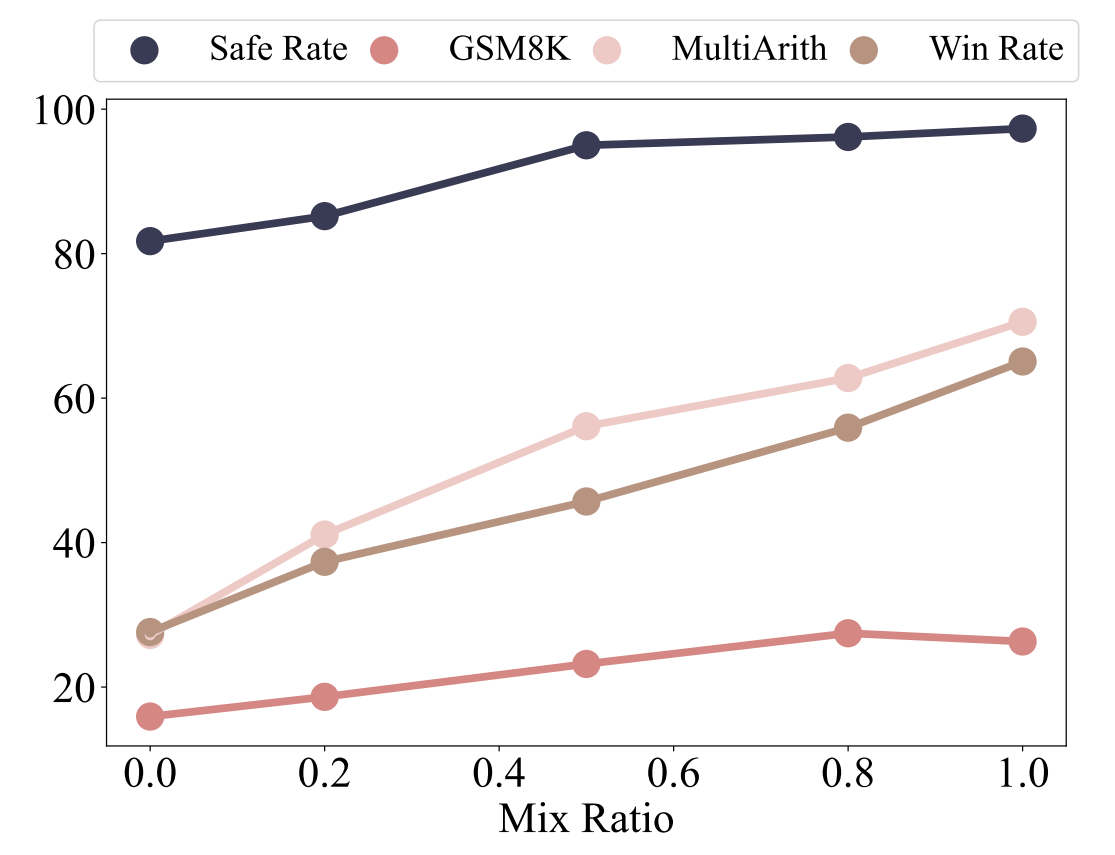
图 7:随着混合比例的增加,模型在各类基准测试中的性能有所提升。
|
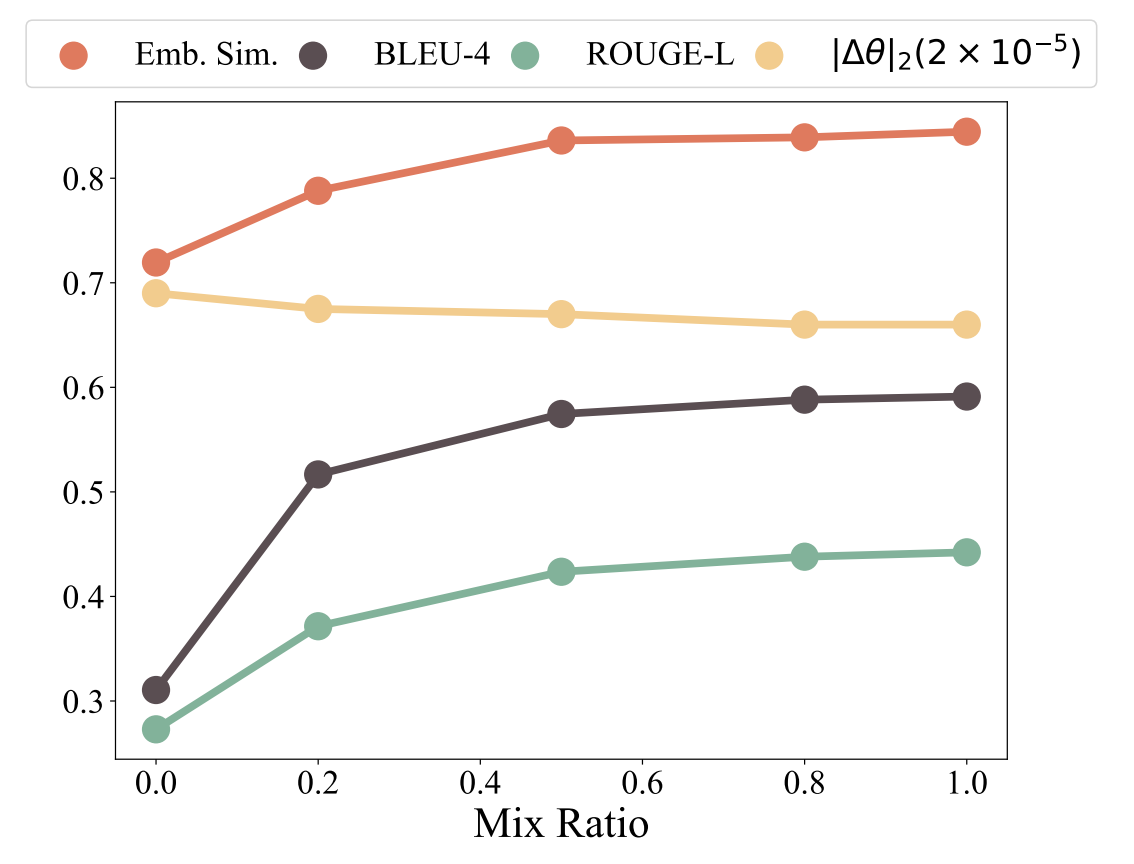
图 8:随着混合比例的增加,BLEU-4、ROUGE-L 以及嵌入相似度会升高,而参数偏移量会降低,这表明分布偏移有所减少。
|
5.1 分布偏移与灾难性遗忘相关
我们通过两种方法诱导不同程度的分布偏移,以研究其影响:(1) 通过对不同数量的示例进行采样来进行微调,用于微调的数据点数量增加意味着更大的分布偏移。(2) 通过将常规微调与自监督蒸馏微调(SDFT)混合,这涉及用原始样本替换蒸馏样本。我们定义混合比例来表示所采用的蒸馏样本的占比。混合比例为1表示仅使用我们的自监督蒸馏微调(SDFT),而0表示常规微调。
图5和图6展示了不同样本量下的结果。随着样本量的增加,我们观察到BLEU-4、ROUGE-L以及嵌入相似度得分显著下降,同时参数偏移幅度升高。这种趋势意味着分布偏移程度加剧。因此,在诸如GSM8K、多算术(MultiArith)、Advbench以及AlpacaEval等基准测试中,模型性能出现了明显的下降,这表明灾难性遗忘加剧了。
同样地,图7和图8呈现了与混合比例上升相对应的结果。随着该比例的增加,BLEU-4、ROUGE-L以及嵌入相似度得分呈现上升趋势,而参数偏移的规模减小,这意味着分布偏移得到了缓解。相应地,各基准测试的性能全面提升,这标志着灾难性遗忘的严重程度有所降低。
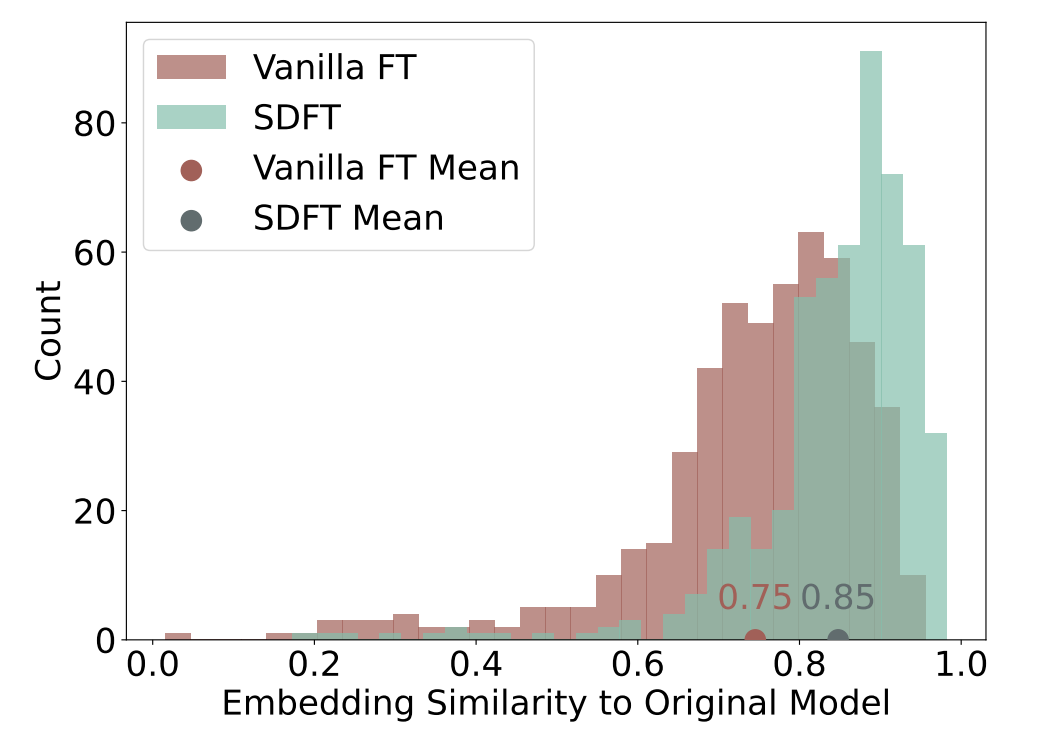
图9展示了通过常规微调以及我们的自监督蒸馏微调(SDFT)所获得的相似度分布情况。值得注意的是,采用自监督蒸馏微调(SDFT)时,微调后的模型与种子模型之间具有更高的相似度,这意味着分布偏移有所减少。
5.2 蒸馏模板间的稳健性
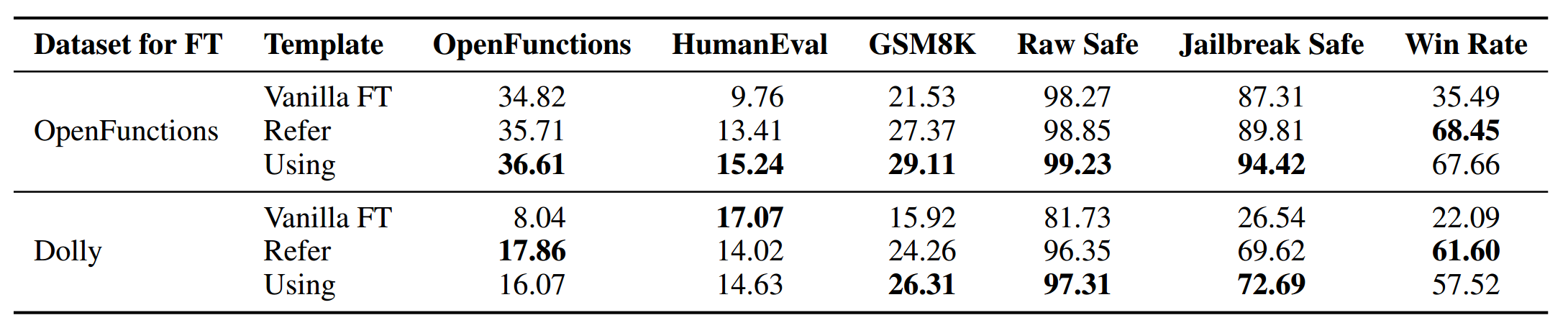
我们构建了两个模板来研究自监督蒸馏微调(SDFT)的稳健性。图3所示的模板被标记为“Using”,在这个模板中,短语“Using the reference answer as a guide”被替换为“Refer to the reference answer”,后一个模板被称作“Refer”。使用这两个模板进行微调后的结果详见表4。在不同基准测试中的性能在各个模板间保持一致,这体现了自监督蒸馏微调(SDFT)的稳健性。
5.3 SDFT在不同模型规模和架构中的有效性
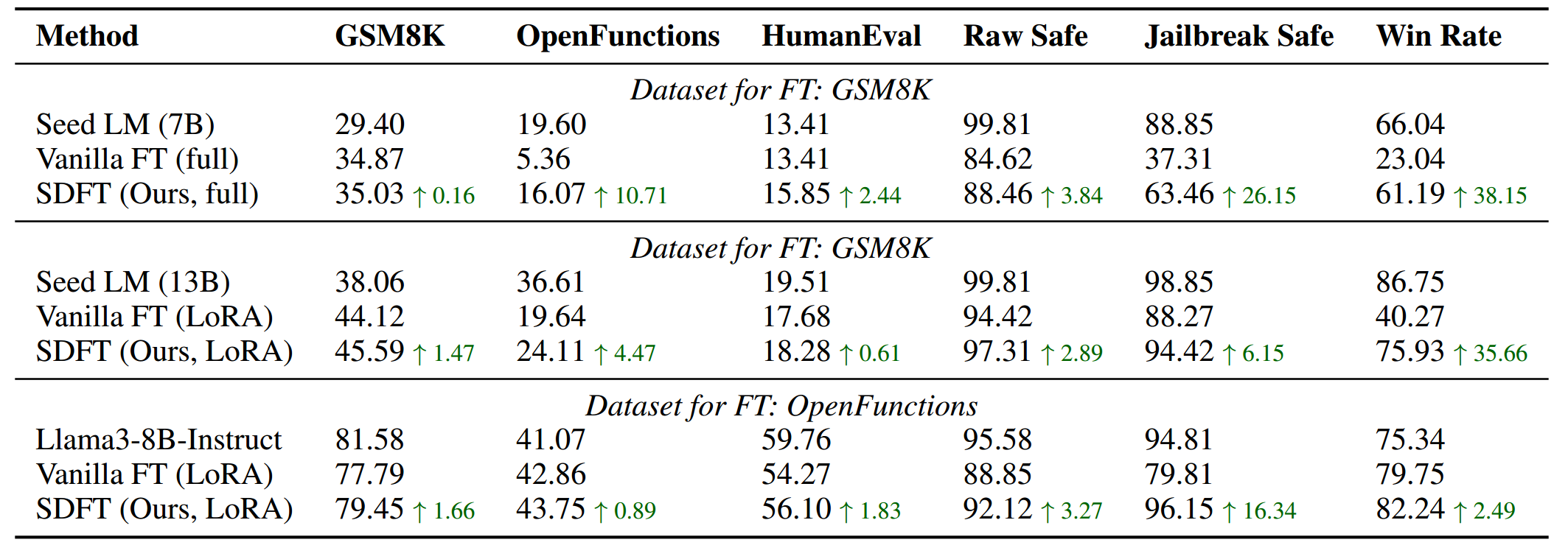
SDFT方法不受任何特定微调技术(如LoRA)或模型架构的限制,使其能够应用于全面微调流程以及其他模型架构当中。为证实这一说法,我们开展了补充实验,其中包括对 Llama-2-7b-chat 进行全量微调以及对 Llama-2-7b-chat 使用LoRA微调。此外,我们还探索了对近期发布的最先进(SOTA)模型 Llama3(Meta AI,2024)在 OpenFunctions 数据集上进行微调的情况。表 5 中的结果显示,在所有场景下,SDFT不仅在目标任务中始终优于常规微调,而且还减少了在所有其他任务上出现的遗忘问题,这体现了它的有效性。
6. 结论与局限性
在本文中,我们对语言模型针对下游任务进行微调时出现的灾难性遗忘现象开展了系统性评估。我们的研究结果表明,微调过程中的分布偏移会导致通用任务能力以及模型的安全对齐性和实用性方面的性能下降。为了在提升目标任务性能的同时保持语言模型(LMs)的广泛能力,我们提出了一种即插即用的策略——自监督蒸馏微调(SDFT),用以减少分布偏移并缓解灾难性遗忘。大量实验表明,SDFT能有效减少遗忘情况,并且在目标任务上可实现与常规微调相当甚至更优的性能表现。
我们的研究存在一定的局限性。由于计算资源的限制,我们的大多数实验都是基于采用LoRA的Llama-2-7b-chat模型开展的。涉及更大规模模型以及全量微调的进一步研究仍有待探索。此外,我们的安全性评估仅限于Advbench数据集以及固定的对抗性后缀,针对其他越狱策略的鲁棒性研究留待未来开展。
伦理声明
我们所提出的SDFT方法有效地缓解了语言模型微调过程中灾难性遗忘的问题,包括安全对齐性下降这一问题。因此,该过程不会带来额外的风险。
我们使用了多种开源的英语数据集进行训练,这些数据集包括Alpaca、Dolly、LIMA、OpenHermes、GSM8K、OpenFunctions以及MagiCoder。我们将Llama-2-chat模型作为训练的种子模型。我们承认在这些数据集以及模型中可能存在固有的偏差。
🐇速读版
1. 论文要解决什么问题?
背景介绍: 大语言模型在预训练阶段,会借助大量的文本语料库展开训练,再加上进一步监督微调(SFT),让模型具备了强大的通用指令遵循能力,这种模型被称为种子语言模型(seed LMs)。不过,当面对一些特定的下游任务时,像医疗信息抽取、金融领域问答等,种子语言模型的表现可能就没那么出色了。换句话说,种子语言模型就好像是 “广而不精” 的状态,虽然知识面覆盖得比较宽泛,但在具体的专项任务上却不够精通。倘若想要让种子语言模型在特定任务上能够有良好的表现,那就需要针对这些特定任务对其进行微调。
微调其实就是一个让模型去适应特定任务的过程。然而,常规的微调方式是存在不足之处的:它难以在特定任务性能和保留通用指令遵循能力之间取得平衡。通俗来讲就是:要么在特定任务上的表现确实变好了,可通用指令遵循能力却随之下降了;要么就是通用能力得以保留,但在特定任务上的表现又不尽如人意,很难做到两者兼顾。
作者认为造成这一不足的主要原因在于灾难性遗忘问题。常规微调是让模型去适应数据的分布,这不得不使得模型妥协,被迫改变一些关键参数,从而使得通用性能下降。因此论文要解决的问题就是如何减轻常规微调过程中的灾难性遗忘问题,使得微调后的模型即广又精,两者兼顾。
2. 如何解决的?
思路: 首先分析导致灾难性遗忘的本质原因:作者通过提出假设,认为灾难性遗忘源于任务数据集与种子语言模型之间的分布差距。常规微调是让模型适应数据分布,而这篇论文反其道而行,让数据适应模型分布,从而缩小分布差距。
论文方法: 提出了一种新颖的微调方法 —— 自蒸馏微调(SDFT),实际上就是通过让种子语言模型自身重写任务数据,让数据分布与自身的分布更接近。用论文两张原图举例说明:
这两幅图可以清晰的体现论文的方法:让种子语言模型通过一个设计的自蒸馏模板,对任务数据的原始响应进行重写,得到与模型分布更为贴合的数据,从而在不需要过度改变原本参数的同时,也能学到特定任务知识,两者兼顾。
最后,文章用了大量篇幅设计了完备的实验以及对实验结果的合理分析,从而强有力地证明了提出的假设:灾难性遗忘源于任务数据集与种子语言模型之间的分布差距。除此之外,也证明了所提出的方法在维持大语言模型的有用性及安全性对齐的潜力。实验与分析详见🦥精读版对应章节。
3. 方法优点
- 有效缓解了灾难性遗忘,在下游任务上能够表现出色,同时保持原有的通用指令遵循能力
- 通过本文所提出的微调方法后,模型仍能够在安全对齐性和整体实用性方面表现良好
🤔思考
-
这篇论文与之前分享的另一篇论文出发点很相似,都是研究如何缓解模型灾难性遗忘问题,让模型能够持续学习,寻求可塑性与稳定性之间的平衡。并且两篇论文基于相似的思想:通过模型自身来得到想要的数据。只不过两篇论文侧重点不同:这篇论文主要研究 “有数据,但数据(分布)不够好,如何得到好的数据” ;而另一篇主要研究 “没数据,或数据较少,如何得到可用数据” 。
-
在
🐇速读版中,我提到论文的思想是让数据适应模型,其实这一思想并不新鲜,最早提示学习(Prompt Learning)被提出的时候,正式基于这一思想,通过提示词或者特定的模板将各种下游任务转化为自然语言形式,使其适应预训练模型,减小下游任务与预训练任务之间的Gap,从而充分发挥预训练模型潜力,即使少样本或零样本情况下,模型仍能很好的学习下游任务。这篇文章借助类似的思想,引入了一个全新的视角,即通过模型自身重写任务数据来弥合分布差距并缓解微调过程中的灾难性遗忘问题。 -
另外,这篇顶会文章的写作真的很值得学习。首先通过提出假设,然后展开方法论,可以看到本文的公式并不多,所提出的方法也很简单直观,但我个人认为这篇论文的精华在于实验、分析部分,针对提出的假设,有条不紊地开展了全面且系统的评估验证工作。整个实验设计不仅逻辑严谨、条理清晰,而且涵盖了多方面的考量因素,显得十分完备、合理,充分满足了科学验证的要求。对实验结果的分析也极具说服力,最终证明假设为真。整篇论文逻辑清晰,表达精炼,没有冗余的内容和晦涩的辞藻,也不需要借助深奥的公式,清晰的为读者讲述了所研究的内容。
-
我一直认为,一篇好的文章,不仅让人能够对所探究的问题有清晰的认识,更重要的是要能带给人深刻的思考和新的启发,为后续的探索、学习提供新的方向和契机,这才是研究的价值所在。
参考文献
Zhaorui Yang, Tianyu Pang, Haozhe Feng, Han Wang, Wei Chen, Minfeng Zhu, and Qian Liu. 2024. Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1028–1043, Bangkok, Thailand. Association for Computational Linguistics.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)