食物声音识别:CNN
1、数据集来自Eating Sound Collection,数据集中包含20种不同食物的咀嚼声音,赛题任务是给这些声音数据建模,准确分类。https://tianchi.aliyun.com/competition/entrance/531887/information
1、DataSet
数据集来自Eating Sound Collection,数据集中包含20种不同食物的咀嚼声音,赛题任务是给这些声音数据建模,准确分类。
https://tianchi.aliyun.com/competition/entrance/531887/information
2、查看音频
使用librosa模块加载音频文件,librosa.load()加载的音频文件,默认采样率(sr)为22050HZ mono。我们可以通过librosa.load(path,sr=44100)来更改采样频率
data1, sampling_rate1 = librosa.load('./train_sample/aloe/24EJ22XBZ5.wav')
plt.figure(figsize=(14, 5))
librosa.display.waveplot(data1,sr=sampling_rate1)查看声谱图
- 声谱图(spectrogram)是声音或其他信号的频率随时间变化时的频谱(spectrum)的一种直观表示。
- 声谱图有时也称sonographs,voiceprints,或者voicegrams。当数据以三维图形表示时,可称其为瀑布图(waterfalls)。
- 在二维数组中,第一个轴是频率,第二个轴是时间。使用librosa.display.specshow来显示声谱图。
plt.figure(figsize=(20, 10))
D = librosa.amplitude_to_db(np.abs(librosa.stft(data1)), ref=np.max)
plt.subplot(4, 2, 1)
librosa.display.specshow(D, y_axis='linear')
plt.colorbar(format='%+2.0f dB')
plt.title('Linear-frequency power spectrogram of aloe')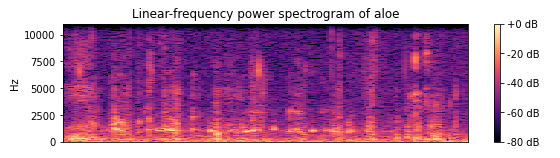
3、音频数据特征提取
人耳接收信号时,不同的频率会引起耳蜗不同部位的震动。耳蜗就像一个频谱仪,自动在做特征提取并进行语音信号的处理。
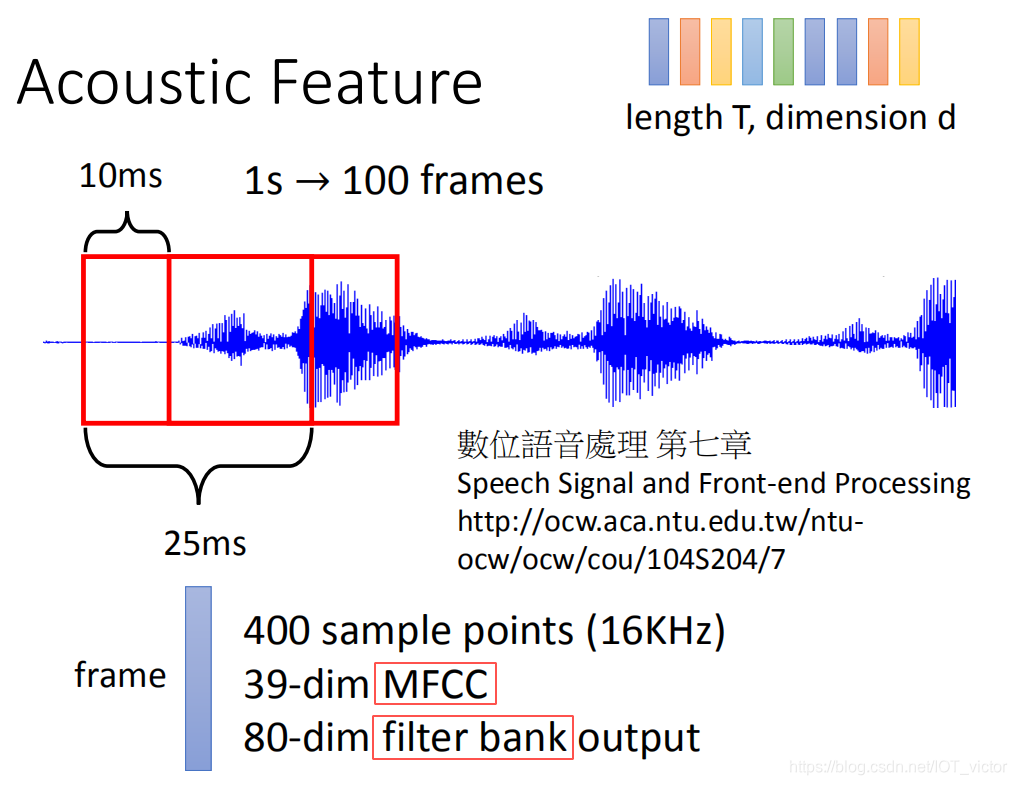
MFCC
https://www.cnblogs.com/LXP-Never/p/10918590.html
MFCC(Mel Frequency Cepstral Coefficents)是本次音频分类任务中涉及到的特征提取方法。
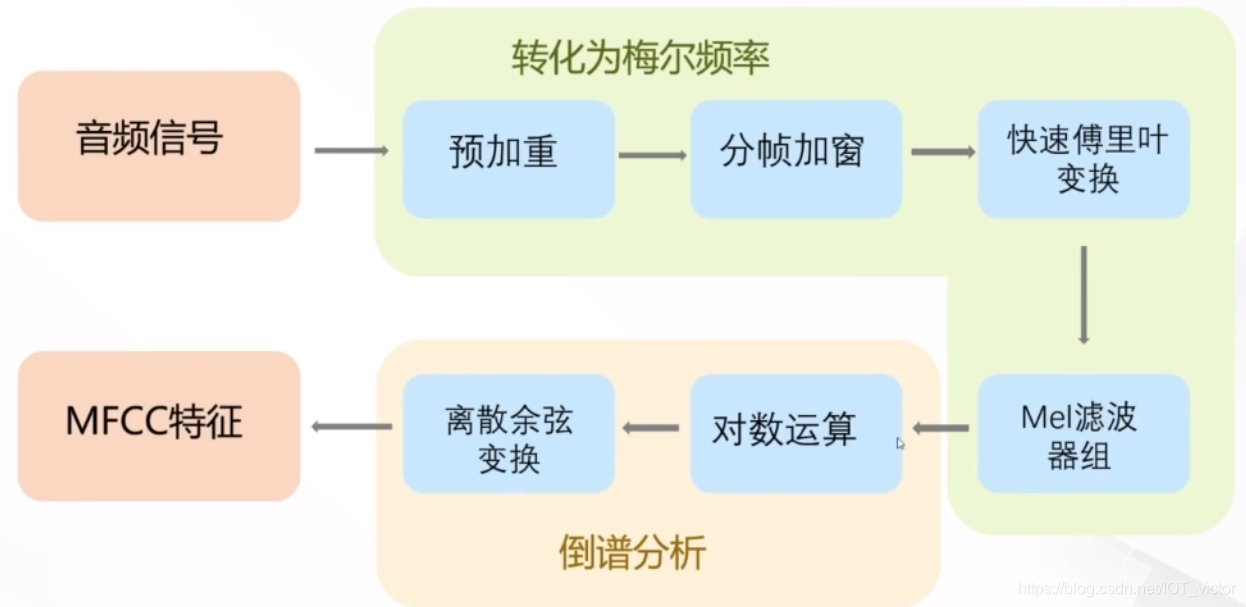
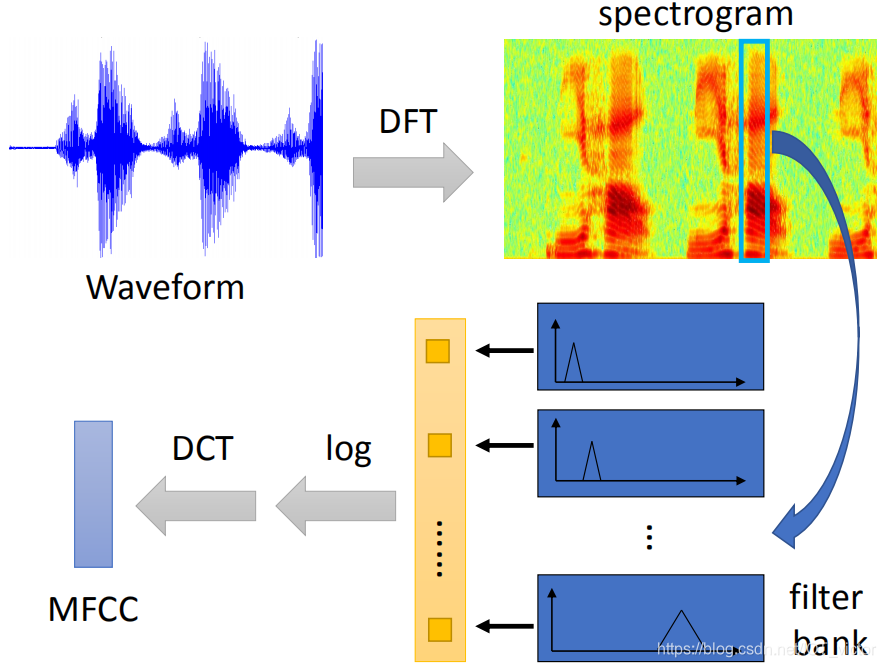
具体来说,MFCC特征提取的步骤如下:
- 对语音信号进行分帧处理
- 用周期图(periodogram)法来进行功率谱(power spectrum)估计
- 对功率谱用Mel滤波器组进行滤波,计算每个滤波器里的能量
- 对每个滤波器的能量取log
- 进行离散余弦变换(DCT)变换
- 保留DCT的第2-13个系数,去掉其它
其中,前面两步是短时傅里叶变换,后面几步主要涉及梅尔频谱。
3.1 短时傅里叶分析
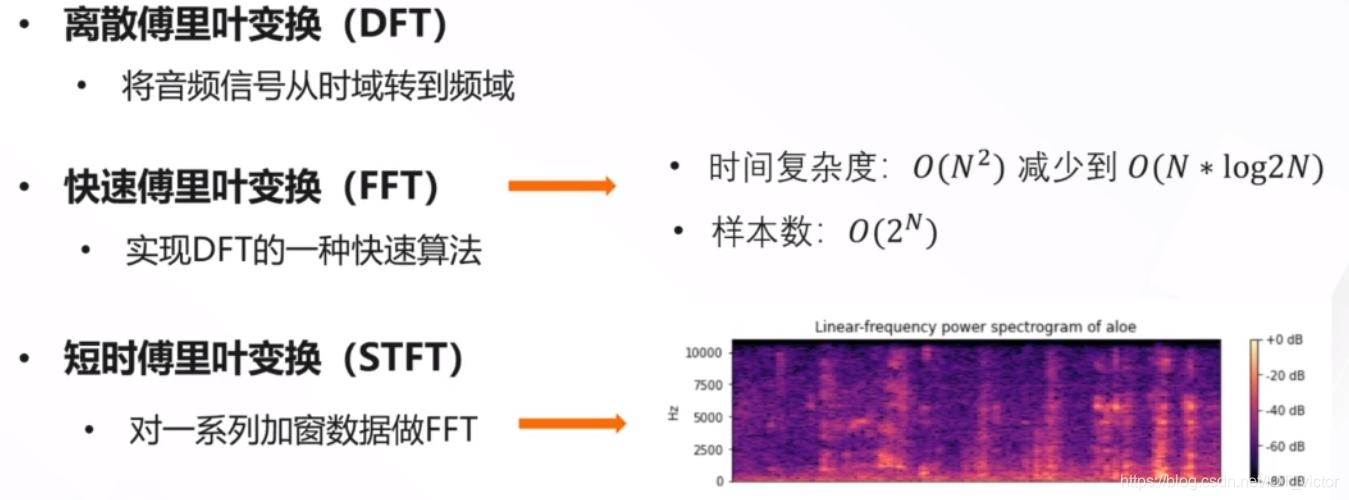
声音信号本是一维时域信号(声音信号随时间变化),可以通过傅里叶变换将其转换到频域上,但这样又失去了时域信息,无法看出频率分布随时间的变化。短时傅里叶(STFT)就是为了解决这个问题而发明的常用手段。
所谓的短时傅里叶变换,
- 即把一段长信号分帧、加窗,再对每一帧做快速傅里叶变换(FFT),
- 最后把每一帧的结果沿另一个维度堆叠起来,得到类似于一幅图的二维信号形式,也就是在第2部分中得到的声谱图。
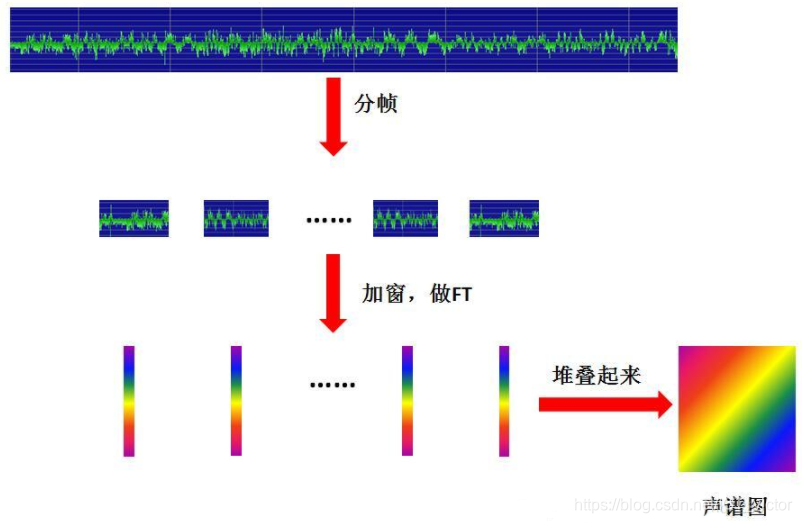
3.2 梅尔频谱和梅尔倒谱
声谱图往往是很大的一张图,且依旧包含了大量无用的信息,所以我们需要通过梅尔标度滤波器组(mel-scale filter banks)将其变为梅尔频谱。
在梅尔频谱上做倒谱分析(取对数log,做离散余弦变换(DCT)变换)就得到了梅尔倒谱。
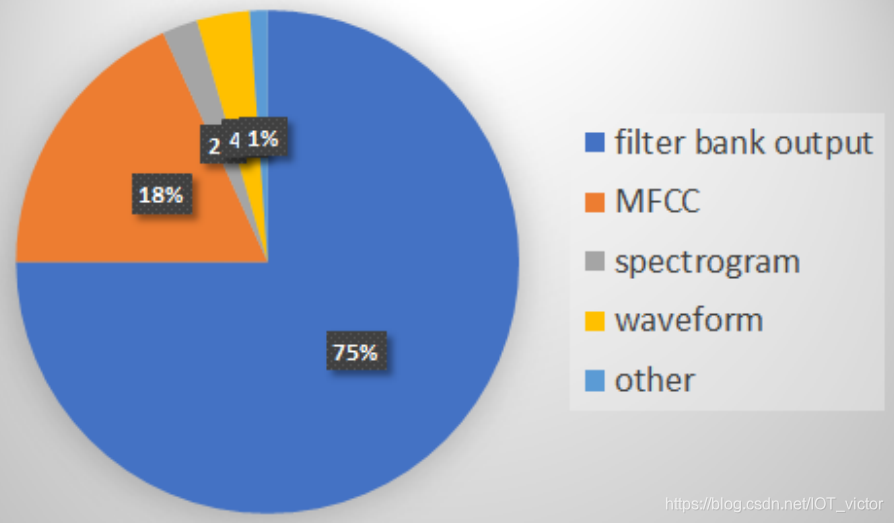
各类音频特征在100 papers in INTERSPEECH’19,ICASSP’19, ASRU’19上的使用统计。
4、CNN
提取音频特征
def extract_features(parent_dir, sub_dirs, max_file=10, file_ext="*.wav"):
c = 0
label, feature = [], []
for sub_dir in sub_dirs:
for fn in tqdm(glob.glob(os.path.join(parent_dir, sub_dir, file_ext))[:max_file]): # 遍历数据集的所有文件
# segment_log_specgrams, segment_labels = [], []
#sound_clip,sr = librosa.load(fn)
#print(fn)
label_name = fn.split('/')[-2]
label.extend([label_dict[label_name]])
X, sample_rate = librosa.load(fn,res_type='kaiser_fast')
mels = np.mean(librosa.feature.melspectrogram(y=X,sr=sample_rate).T,axis=0) # 计算梅尔频谱(mel spectrogram),并把它作为特征
feature.extend([mels])
return [feature, label]CNN网络结构
model = Sequential()
# 输入的大小
input_dim = (16, 8, 1)
model.add(Conv2D(64, (3, 3), padding = "same", activation = "tanh", input_shape = input_dim))# 卷积层
model.add(MaxPool2D(pool_size=(2, 2)))# 最大池化
model.add(Conv2D(128, (3, 3), padding = "same", activation = "tanh")) #卷积层
model.add(MaxPool2D(pool_size=(2, 2))) # 最大池化层
model.add(Dropout(0.1))
model.add(Flatten()) # 展开
model.add(Dense(1024, activation = "tanh"))
model.add(Dense(20, activation = "softmax")) # 输出层:20个units输出20个类的概率
# 编译模型,设置损失函数,优化方法以及评价标准
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])https://github.com/datawhalechina/team-learning-nlp/tree/master/FoodVoiceRecognition

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)