论文阅读笔记--Clustered Federated Learning:Model-Agnostic Distributed Multitask Optimization Under Privacy
Introduction传统的Parameter Server(P-S)架构的联邦学习系统尝试训练出一个模型,让它能适用于每一个client的数据分布,这暗含了一个假设,模型的最优解θ∗\theta^*θ∗同时是所有client的最优解,各个client的模型是全等的(congruent)。也就是作者提到的Assumption 1:显然这个条件不是任何时候都可以得到满足的,作者列举了两种例子:1)
Introduction
传统的Parameter Server(P-S)架构的联邦学习系统尝试训练出一个模型,让它能适用于每一个client的数据分布,这暗含了一个假设,模型的最优解θ∗\theta^*θ∗同时是所有client的最优解,各个client的模型是全等的(congruent)。也就是作者提到的Assumption 1:
显然这个条件不是任何时候都可以得到满足的,作者列举了两种例子:
1)模型fθf_{\theta}fθ表达能力不够强,无法同时拟合所有client的数据集;
2)各个客户端的数据集的条件分布有差异,φi(y∣x)≠φj(y∣x)\varphi_i(y|x)\neq\varphi_j(y|x)φi(y∣x)=φj(y∣x)。
Figure 1里面的前两张图就是受限于模型的表达能力,第3张图无论模型表达能力再强也无法同时fit两个client的数据。
考虑到这些问题,文章使用了一种称为clustered FL的方法,主要方法就是将任务相似度吻合度较高的客户端构成小的集群,使他们能够更好的协作,同时减少其他客户端带来的负面影响。
Clustered FL
在FL中,Server是无法得到client的数据的,那么应该怎样比较各个client之间的任务相似度呢,这里用到了余弦距离来表示。
假设我们将所有的client划分为两个cluster,我们要学习的目标函数可以定义为
用RRR表示期望风险,rrr表示经验风险,在数据量足够大的情况下,r≈Rr{\approx}Rr≈R。在训练中我们优化F(θ)F(\theta)F(θ)直到∇F(θ)=0\nabla F(\theta)=0∇F(θ)=0。此时,∇a1R1(θ)+a2R2(θ)=0\nabla a_{1}R_{1}(\theta) + a_{2}R_{2}(\theta)=0∇a1R1(θ)+a2R2(θ)=0。如果θ∗\theta^*θ∗同时是两种期望风险的最优解,那么应该有R1(θ∗)=R2(θ∗)=0R_1({\theta}^{*})=R_2({\theta^*})=0R1(θ∗)=R2(θ∗)=0,那么R1R_1R1和R2R_2R2是congruent的;抑或是R1(θ∗)≠R2(θ∗)R_1({\theta}^{*}){\neq}R_2({\theta^*})R1(θ∗)=R2(θ∗),也就是Figure 2左图所示的情况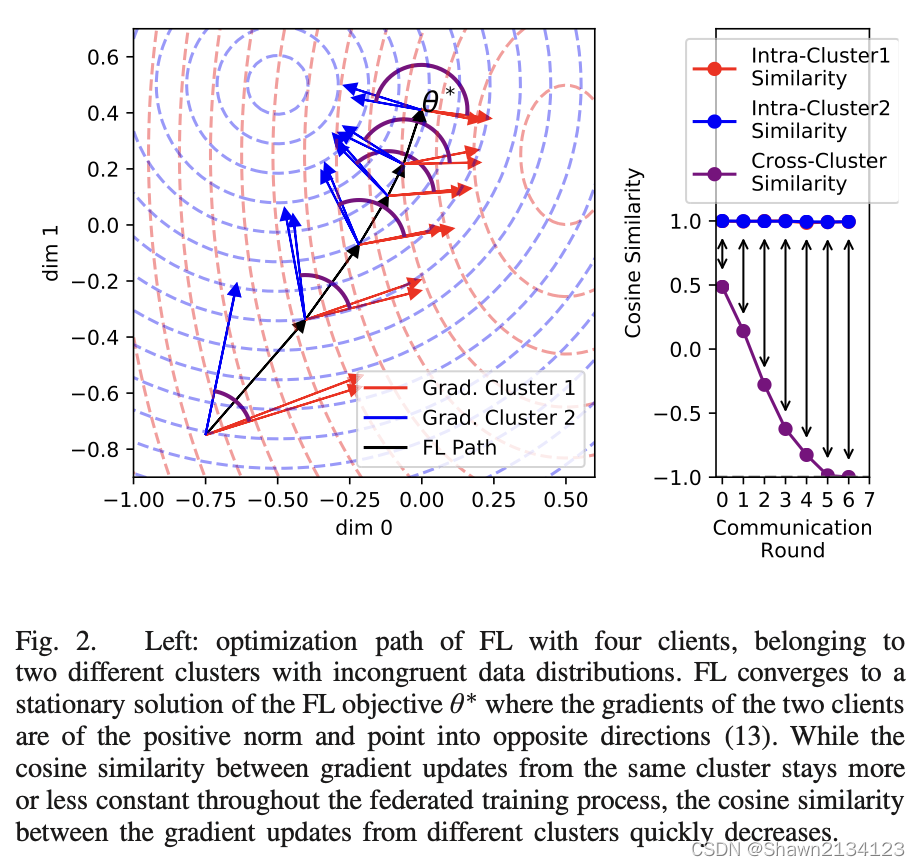
这个时候我们就需要将client进行划分。以上是将client划分为两个cluster的方法,将其扩展为划分为多个cluster,由于实际情况中即使数据分布相同的两个client,在θ∗\theta^*θ∗处的梯度也很难同时为0,为此我们可以分别设置cluster内的余弦距离下界和cluster间的余弦距离上界来将client划分为若干个cluster(越相似,余弦距离越大)。
于是Clustered FL的算法框架也有了: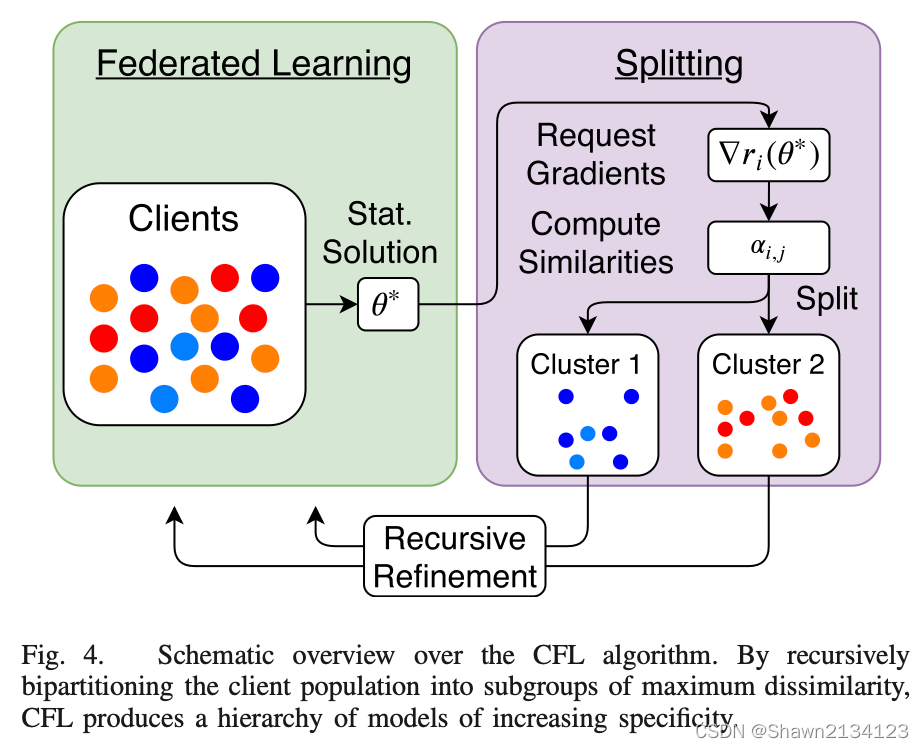
所有client共同训练得到全局的最优解θ∗\theta^*θ∗,然后将θ∗\theta^*θ∗用于各自的数据计算出此时的梯度,根据梯度将client划分为若干个cluster,每个cluster再循环执行上述算法。算法的描述如下图所示
具体实现上,可以使用Parameter Trees这种树形结构来实现: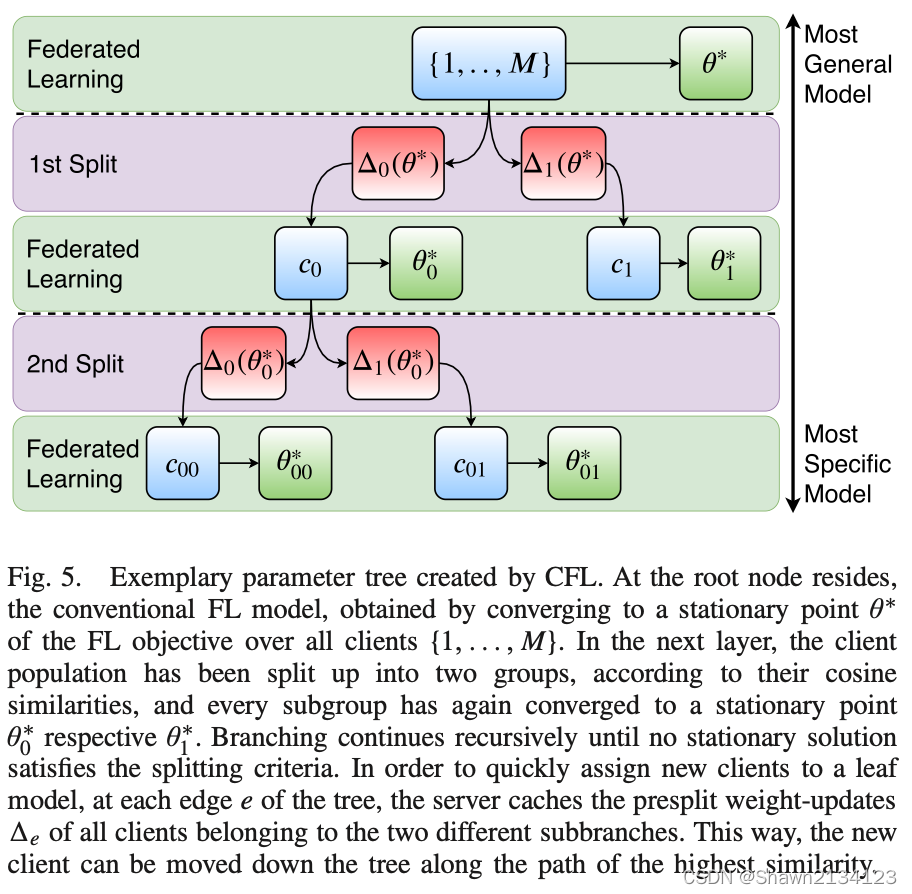
这种数据结构的好处是,当有一个新节点加入的时候,可以通过树的分支搜索很快的找到新节点归属于哪一个cluster。
(转载请注明出处)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)