学习笔记 Comprehensive and Delicate: An Efficient Transformer for Image Restoration(CVPR2023)
图 1. 上半部分是现有 Transformers ,下半部分我们的愿景中的依赖关系捕获图示(这里我们不需要重点关注,只需要看到两个的不同,后面将详细叙述这是如何实现的)。在本文中,我们提出了一种新颖的Vision Transformers,它首先捕获超像素级的全局依赖性,然后将其转移到每个像素中。我们的目的是在注意力计算后恢复通道和空间域中的特征分布同时筛选特征,CA以自适应方式执行特征聚合和恢
代码和参考:
1.摘要:
通常的Vision Transformers 一般是基于窗口或通道的。尽管已经取得了不错的性能,但它们通过捕获像素之间的局部而不是全局依赖性。在本文中,我们提出了一种新颖的Vision Transformers,它首先捕获超像素级的全局依赖性,然后将其转移到每个像素中。这由本文提出的两个创新的网络模块,即凝聚注意力神经块(CA)和对偶自适应神经块(DA)。下面将介绍这两个模块和本文的网络结构。
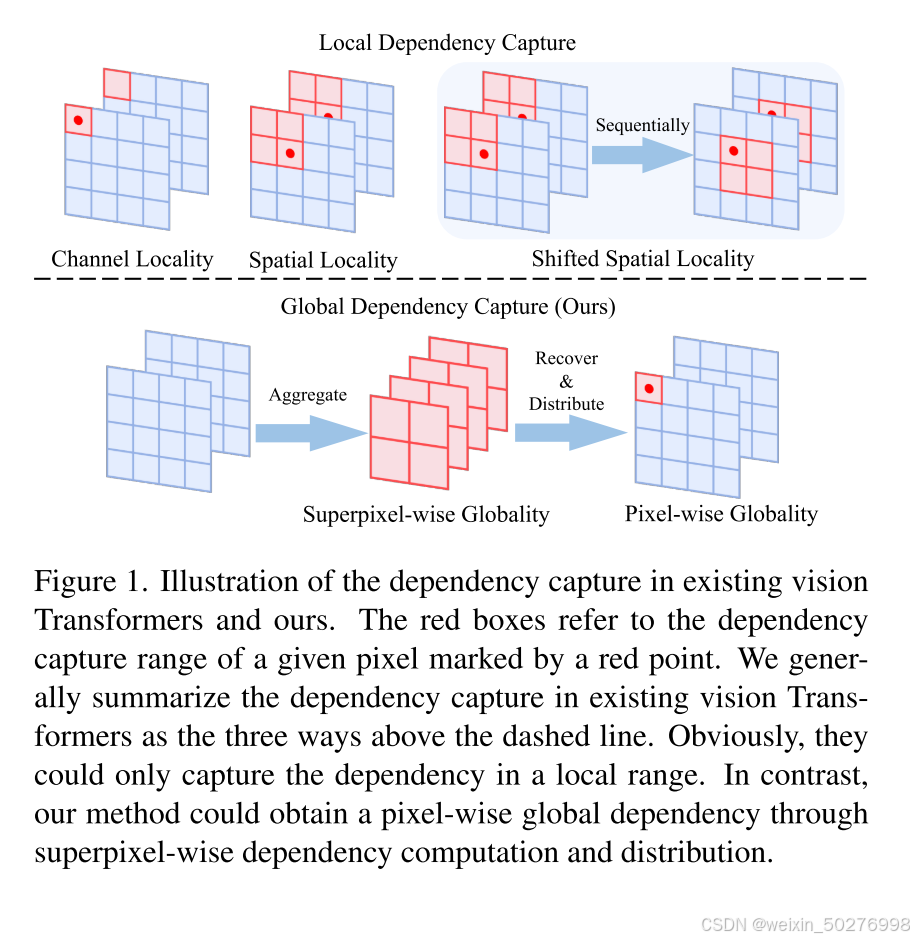
图 1. 上半部分是现有 Transformers ,下半部分我们的愿景中的依赖关系捕获图示(这里我们不需要重点关注,只需要看到两个的不同,后面将详细叙述这是如何实现的)。红色框指的是由红点标记的给定像素的依赖性捕获范围。我们一般将现有视觉 Transformer 中的依赖捕获总结为虚线上方的三种方式。显然,他们只能捕获局部范围内的依赖关系。我们的方法可以通过超像素依赖性计算和分布获得像素全局依赖性。
2.本文方法。
在本节中,我们首先介绍整体架构,然后详细说明两个神经块,即凝聚注意力(CA)和对偶自适应神经块(DA)。
2.1整体架构
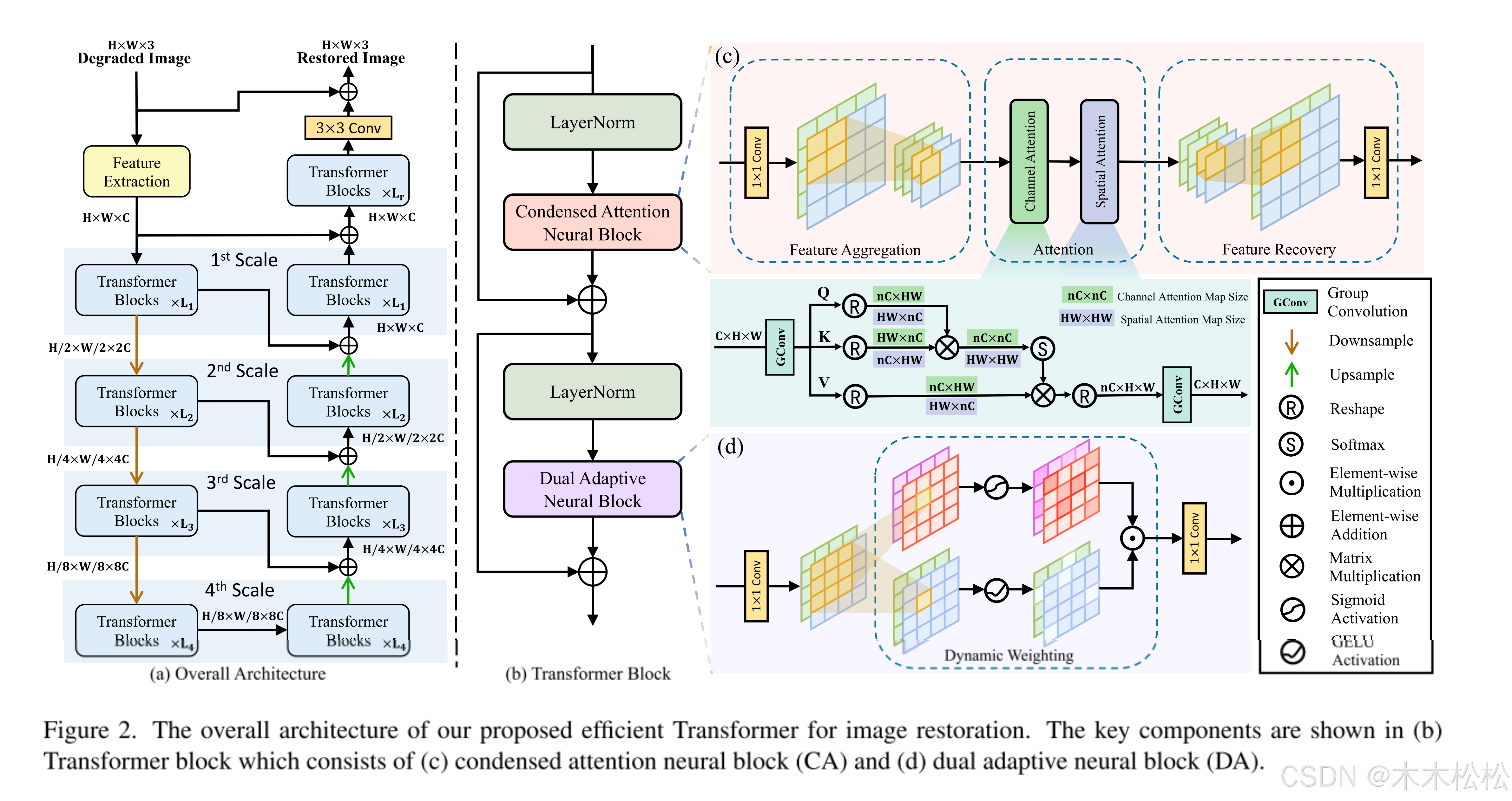
图2中的(a)就是本文的主要结构。网络是分层多尺度架构。对于给定的退化图像,我们首先使用 3×3 卷积来提取浅层特征 ,然后使用具有四个尺度的编码器-解码器来提取深层特征
。图2(b)为Transformer的结构。
在编码器中每个尺度的开始(除了第一个尺度),我们将特征分辨率降低一半,同时将特征通道扩展为两倍,然后通过多个 Transformer 块 提取深层特征。
其中 和
是编码器中第 i 个尺度的输入和输出特征。对于解码器,
我们在每个尺度开始时将特征分辨率加倍,同时将特征通道(表示为)减半(最后一个尺度除外)。同时,引入编码器相应尺度的跳跃连接来融合分层多尺度特征,即
其中 和
是解码器中第 i 个尺度的输入和输出特征,
是来自编码器的特征,与
具有相同的尺度。
经过编码器-解码器之后,我们将深层特征 与浅层特征
融合,并通过几个 Transformer 块
对其进行细化,以获得最终特征
,即
最后,我们使用3×3卷积将融合为残差图像,从而获得恢复图像。
2.2 Condensed Attention Neural Block(浓缩注意力神经块CA)
CA的三步分别为特征聚合、注意力计算和特征恢复。如图2所示,这里的特征涉及通道和空间两个维度,CA依次对它们进行通道和空间注意力,从而可以沿两个维度充分捕获全局依赖性。最后,CA恢复空间和通道维度,使得输出超像素特征的分辨率和通道与输入像素特征一致。
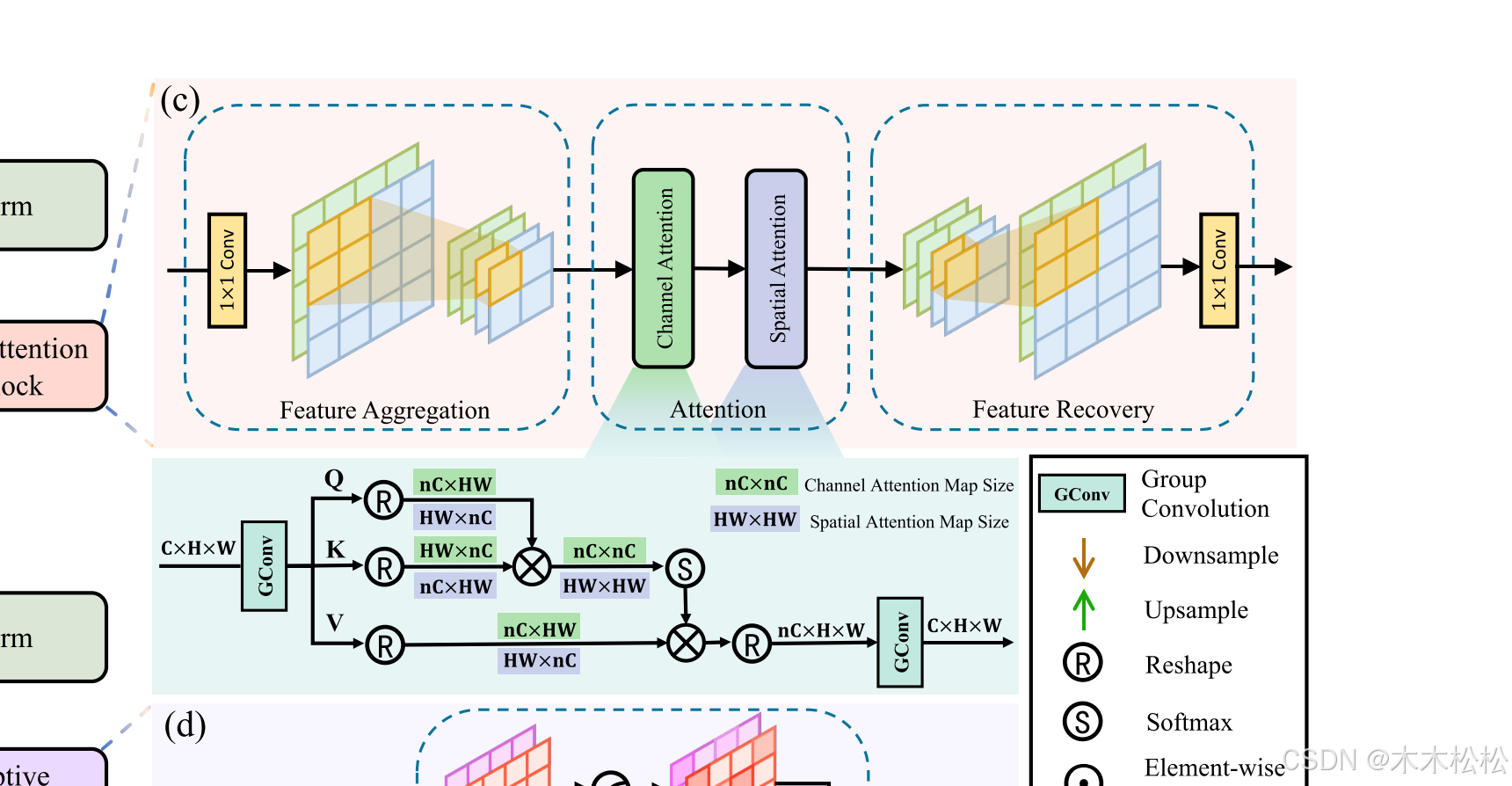
2.2.1 特征聚合和恢复
1.聚合
由于观察到通道域和空间域中都存在大量多余的特征,所以需要减少多余的特征。我们的目的是在注意力计算后恢复通道和空间域中的特征分布同时筛选特征,CA以自适应方式执行特征聚合和恢复,并通过网络恢复特征分布。
给定输入特征 ,其中
表示空间分辨率,
是通道数,CA 沿通道维度聚合特征以获得通道压缩特征
;
其中 ,
是聚合因子。出于一般性,CA 引入了逐点卷积
来自适应聚合通道域中的信息特征。
然后,CA沿空间维度聚合特征,得到空间压缩特征 ,即
其中 ,简而言之,
将块大小为
的空间特征聚合为
的压缩特征,从而获得
。通过这种方式,空间特征可以被聚合,同时被充分保留在扩展的通道中。因此,可以获得通道域和空间域中的超像素特征,并用于捕获较低维空间中的超像素依赖性。
2.恢复
为了恢复注意力后通道域和空间域的特征分布,CA 采用了聚合的逆过程。具体来说,它首先恢复空间特征,然后恢复通道特征,即
其中 是注意力计算后的特征,
和
分别是空间和通道特征的恢复函数。
为了将空间特征从大小恢复到
,采用
通道组卷积,其输入和输出通道为
和
,然后进行pixel-shuffle(这个可以参考PixelShuffle上采样原理讲解及程序实现-CSDN博客)以恢复
的空间分辨率。
为了恢复特征通道,使用与
和
的输入和输出通道进行逐点卷积。因此,可以在保持空间分辨率和通道数相同的情况下获得最终特征
。
2.2.2 通道和空间注意力
这一小节需要对transformer有基本的了解。
为了充分捕获沿二维的全局依赖性,我们依次对特征 执行通道和空间注意。简而言之,通道注意力捕获沿通道维度的依赖性,随后是空间注意力捕获沿空间维度的依赖性。因此,可以在通道和空间域中充分捕获全局依赖性。
下面介绍本文的重点!!
为了提高注意力模块的效率,我们分别在多头注意力计算之前和之后引入了一种新颖的通道切片和合并机制,可以表示为:
其中 将第 i 个通道特征
投影到 3n 个通道切片
中,从而得到所有通道特征
,其中通道数为
。
在注意力计算后将通道切片合并为一个通道。
和
都是通过群卷积(group convolutions)实现的。
为多头注意力计算,首先将切片通道统一划分为查询(Q)、键(K)、值(V),即
然后分别对它们进行洗牌,从而将同一频道的切片频道分成不同的注意头,即
接下来,我们计算头部数大于等于n的注意力。在每个头部,我们通过以下公式计算注意力
其中是可学习的比例因子,为了简单起见,我们忽略上标和下标。最后,我们将多个正面的结果连接起来,并将它们拆散,以获得注意力特征
。
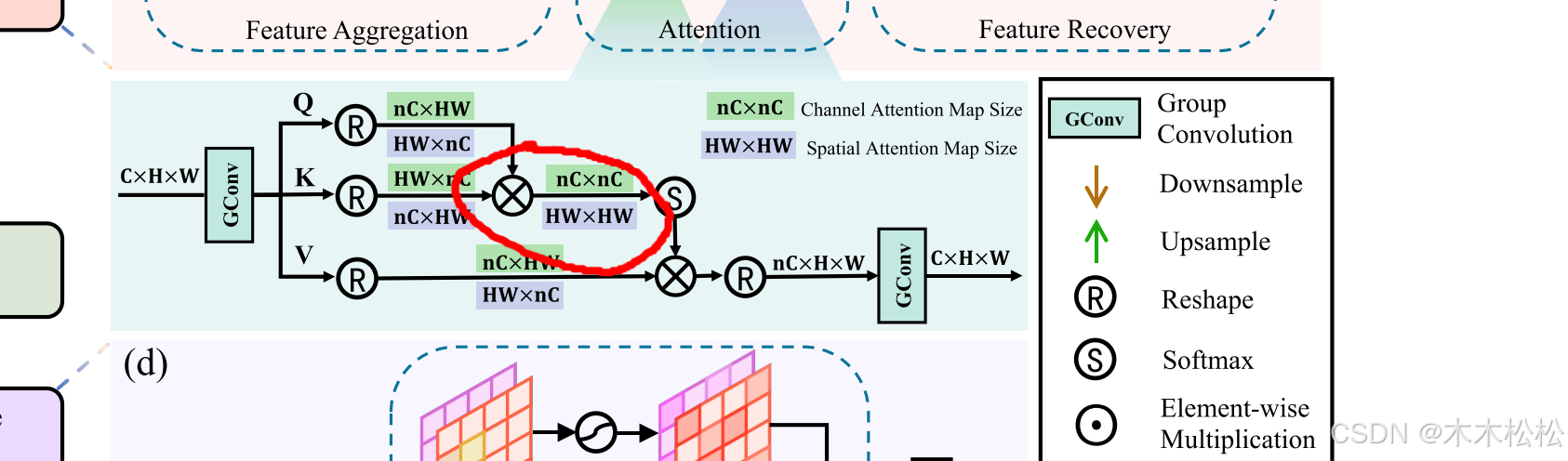
通道和空间注意力都遵循上述方法,唯一的区别是在F的计算中,前者沿着通道维度计算注意力,而后者沿着空间维度计算注意力。也就是图中红圈出的矩阵乘法是否进行转置,从而导致乘法得出的矩阵大小不一样。
2.3 双自适应神经阻滞(Dual Adaptive Neural Block DA)
DA的基本结构图如图:
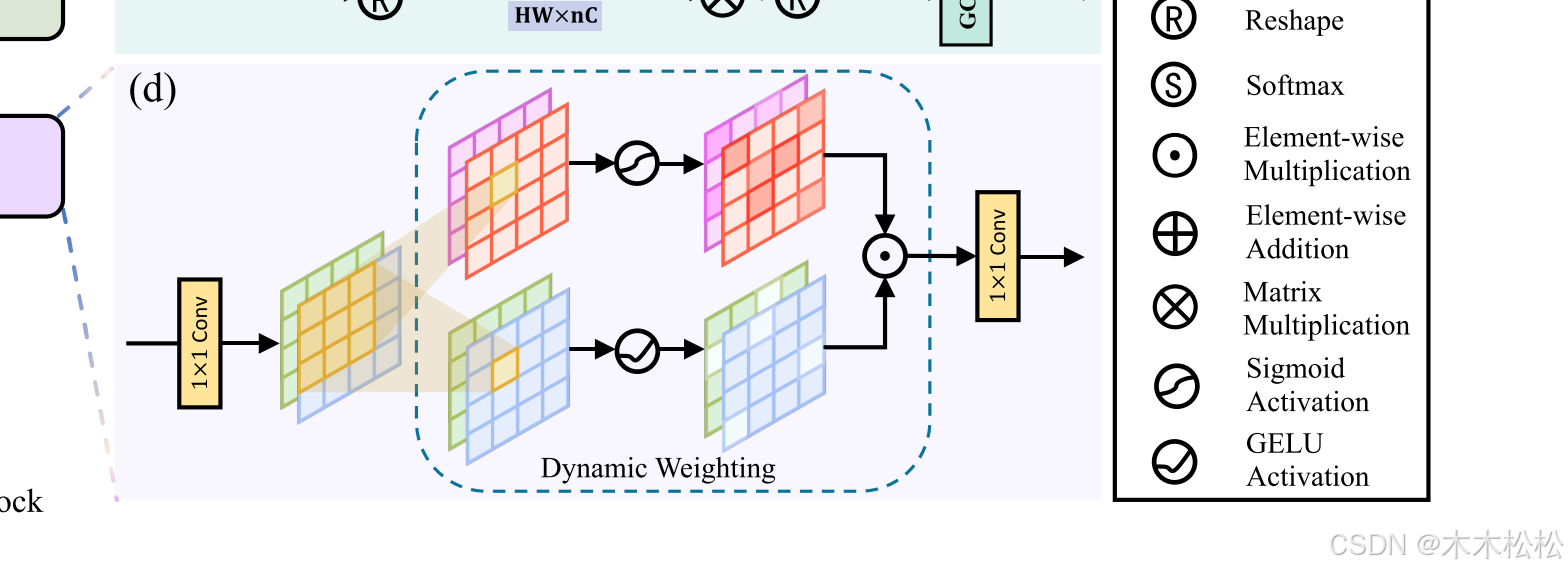
为了将超像素全局性封装到像素全局依赖性中,我们引入了双自适应神经块(DA),通过一种新颖的双向结构和动态加权结构。具体来说,DA首先采用点向卷积来混合超像素特征,即
然后,由于每个超像素包含全局信息,DA引入双向结构。在短范围内捕获每个像素对超像素的依赖关系,同时在局部区域内从超像素的特征中提取像素的特征。之后,我们让前者以动态加权的方式作用于后者,即:
式中为通道索引。简而言之,
从每个通道
中提取两个通道切片
,这是通过核大小为7 × 7的群卷积实现的。
和
是Sigmoid和GELU激活,它们分别将依赖关系转换为权重并过滤提取的像素特征。
最后,采用逐点卷积对具有全局性的特征进行细化,即:
通过上述设计,数据分析可以通过将全局依赖关系和全局特征从超像素转移到每个像素来捕获逐像素的全局依赖关系,而只引入少量的计算和参数。
3.笔者总结:
本文对vit进行改良,使得transformer可以从像素角度通过超分辨率捕获全局信息。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 44
44 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)