云平台显卡选型所需要注意的一些点:CPU、GPU、FLOPs 是什么?
本文将介绍什么是GPU、CPU以及这两者之间的关系以及参数,再结合FLOPs的知识告诉你如何对显卡进行选型。
前言:近来在云平台AutoDL上进行模型训练,碰到如何选择合适的显卡的问题(性能好、价格低),随后对相关方面进行了学习,故在此进行记录并分享个人所学。
目录
GPU篇
1.什么是GPU
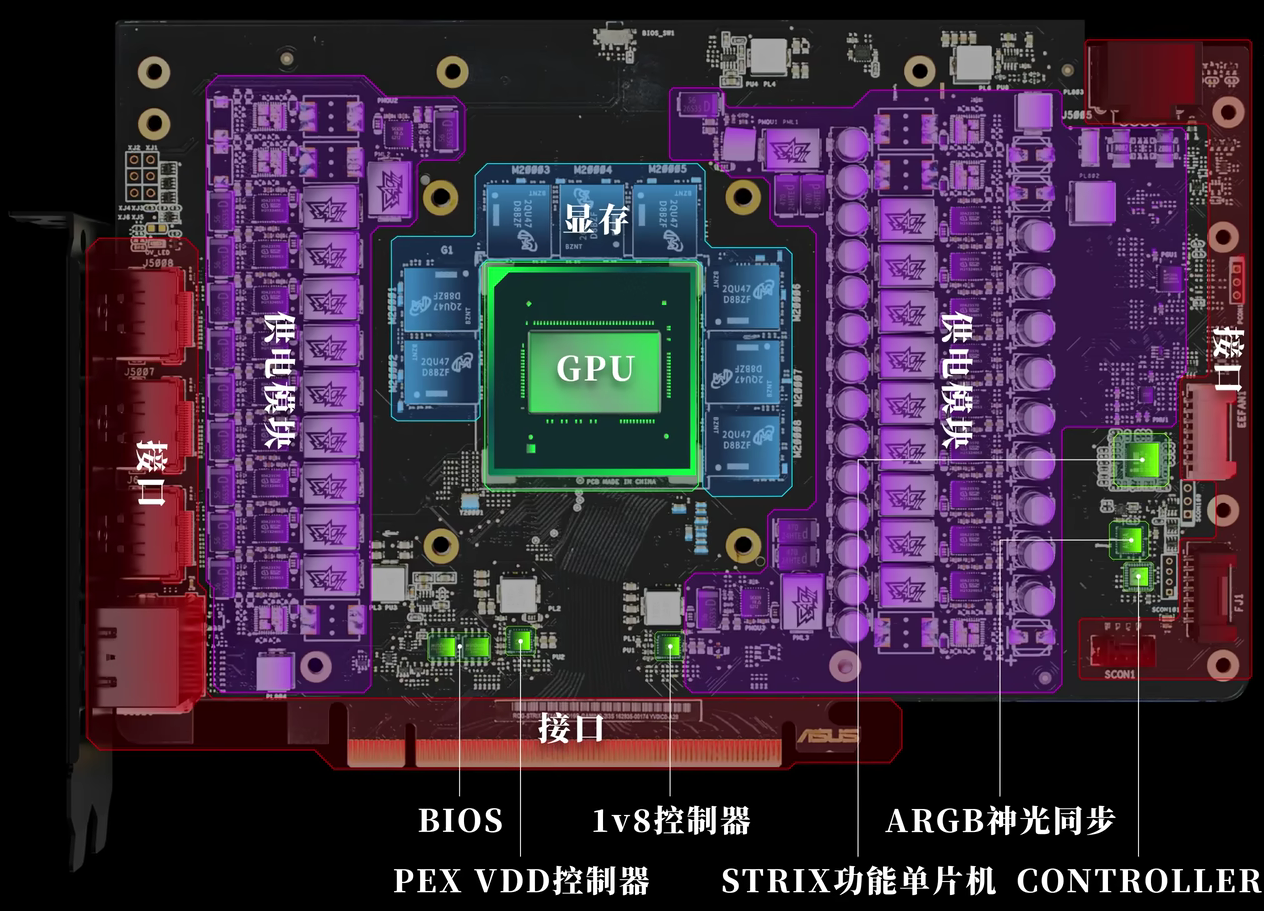
对于GPU和显卡,在日常认知中大家总是把两者混为一谈,但实际上二者并不等同:
1)GPU(图形处理器)是一种专门用于处理图形和并行计算任务的芯片,设计初衷是加速图像渲染、视频处理以及深度学习等大规模并行计算工作。
2)显卡(Graphics Card)则是包含GPU的完整硬件设备。除了GPU外,显卡还集成了专用的显存(VRAM)、电路板、散热系统以及其他辅助组件,目的是为计算机提供高性能的图形渲染能力和其他GPU加速的功能。
简单来说:GPU 是显卡中的核心处理单元,负责执行实际的图形和并行计算任务。显卡 是一块完整的硬件产品,其中包含了GPU以及所有支持该GPU正常运行的配套组件。这种关系类似于“发动机”与“汽车”:GPU就像是发动机,而显卡则是将发动机、散热、供电等系统集成在一起的整车产品。
2.显存是什么
显存的全称是Video RAM(显卡内存),一般说“显卡有24GB内存”指的就是显存。在深度学习中显存主要作用有:存放神经网络模型参数(如权重)、输入数据(如图片、文本)、中间计算结果(如激活值、中间层输出)等。在训练时,还存放梯度、优化器状态(如Adam的动量等)。
因此在显卡选型中,显存越大,能放更大的模型、更大的batch size。如果显存不足,会OOM(Out of Memory)报错,或者只能减小batch size、用模型压缩/分布式训练等手段。
例如常见的容量有:
-
游戏卡:8GB、12GB(RTX 3060, 4070等)
-
高端卡:24GB、48GB(RTX 4090、A100、H100)
3.缓存是什么
缓存的层级类似CPU,也有 L1 Cache、L2 Cache,甚至L3。缓存的作用是:提高数据访问速度。GPU在计算时会反复使用某些数据,比如同一个卷积核或数据块,不必每次都从显存读取。缓存起到“就近存取”,提高效率,降低显存带宽压力。故此大容量、高带宽缓存能减少等待时间,提升吞吐量。
例如常见的容量有:
-
A100的L2 Cache有40MB
-
H100的L2 Cache高达50MB+
4.内存是什么
日常学习中有时初学者会把“内存”和“显存”搞混,但两者其实是不同的概念,内存(RAM)指的是CPU内存,而显存指的是显卡内存。CPU内存的作用主要是:在训练时,CPU内存用于加载训练数据(比如dataset)和与GPU交换数据。虽然计算主要在GPU显存里进行,但数据加载、预处理常在内存完成。
例如:我们需要加载图像数据集imagenet,而imagenet有138 GB,如果需要将全部数据进行训练,那么对于cpu的内存就有比较高的要求。但需要注意的是虽然 ImageNet 数据集在磁盘上的总大小大约是 138GB,但训练时并不需要一次性将所有数据加载到 CPU 内存中。一般来说,训练过程中会用到数据加载器(如 PyTorch 的 DataLoader),它会按 mini-batch 的方式从磁盘上读取数据,加载到内存中进行预处理,然后输入模型进行训练。因此,只需要足够的内存来存储当前正在处理的 mini-batch 数据,而不必将整个数据集同时加载到内存中。实际所需的 CPU 内存大小取决于 batch size、数据预处理操作以及系统其它占用内存的情况,通常远小于数据集总大小。
| 项目 | 位置 | 作用 | 对深度学习影响 |
|---|---|---|---|
| 显存(VRAM) | 显卡 | 存模型、数据、梯度 | 决定模型规模、batch size,太小会OOM |
| 缓存(Cache) | GPU核心内部 | 快速存取热数据 | 提高计算效率,降低访问延迟 |
| 内存(RAM) | 主板/CPU | 数据加载、预处理 | 影响数据流转、训练整体流畅性 |
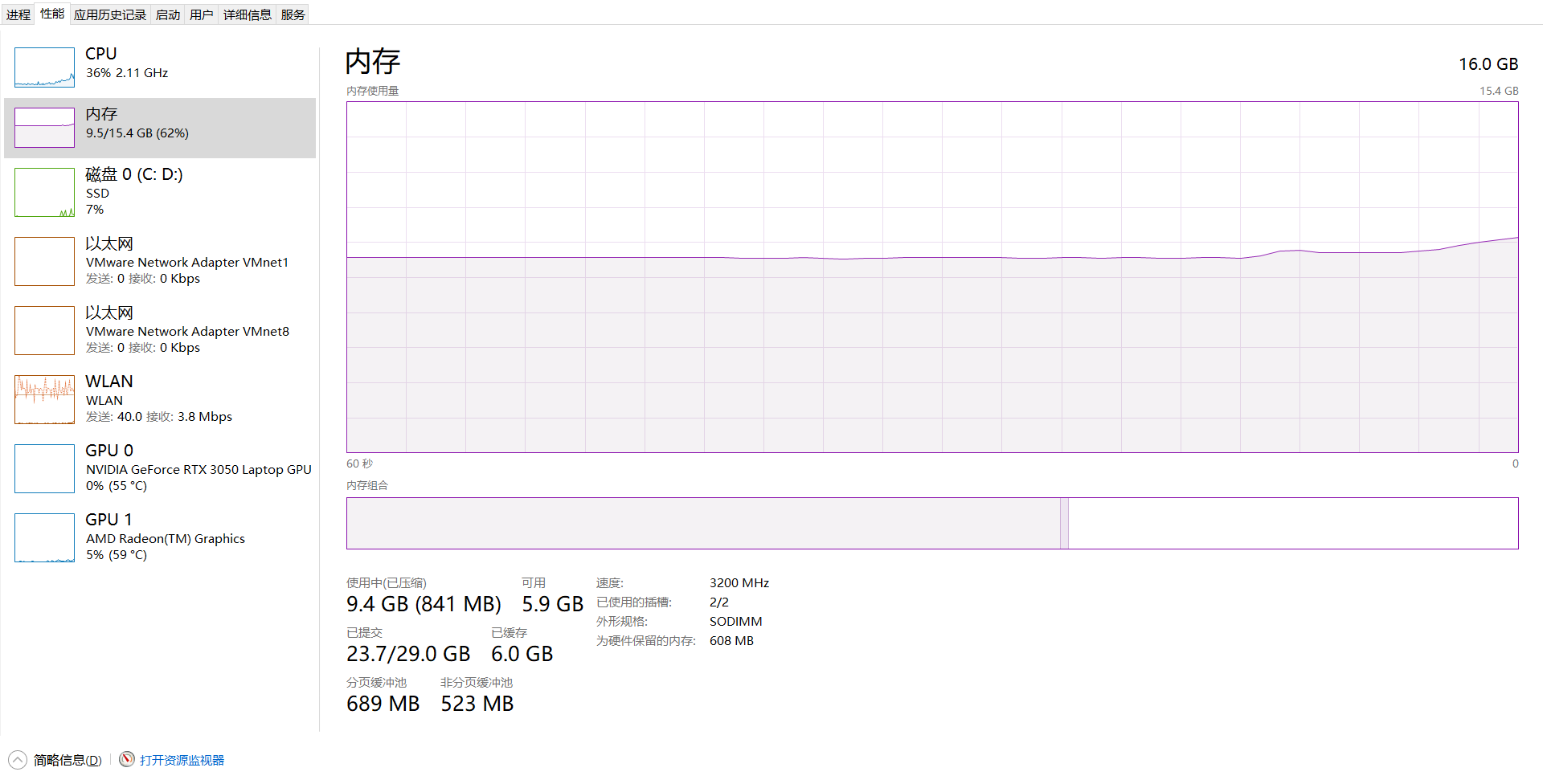
补充:如何查看电脑的内存、显存呢,这里提供在window是下查看的方法:
- 按住快捷键:
Ctrl + Shift + Esc打开任务管理器 - 选择【性能】标签,点击左侧的【内存】,可以看到:已用内存、可用内存
CPU篇
1.CPU是什么
CPU,全称为中央处理器(Central Processing Unit),是计算机系统的核心部分,被称为计算机的“大脑”。它主要负责执行程序指令、进行算术和逻辑运算,以及控制和协调其他硬件组件的工作。CPU通过从内存中提取数据和指令,再经过解释、执行后输出结果,来实现各种应用程序和操作系统的运行。一般来说,CPU拥有多个核心和较大的缓存,适合处理复杂、分支较多以及需要高单线程性能的任务。
2.CPU与GPU有什么区别
CPU(中央处理器)和GPU(图形处理器)各自具有独特的设计目标和架构特点,主要区别在于它们擅长解决不同类型的计算任务。
CPU具有如下特点:
-
通用性强
CPU 设计用于处理各种各样的任务,包括操作系统管理、程序指令执行、复杂逻辑判断和串行计算。 -
核心数量少但性能强大
一般只有几核到十几核,每个核心拥有丰富的缓存和复杂的控制逻辑,适合处理需要高单线程性能的任务。 -
适合复杂、分支较多的任务
适合处理需要频繁分支、数据依赖和调度的任务,如办公软件、网页浏览和大部分传统应用。
GPU具有如下特点:
-
专注于并行计算
GPU 拥有成百上千个相对简单的核心,这些核心能同时处理大量相似或重复的计算任务,极大地提高了并行处理能力。 -
优化图形和数据密集型任务
最初为图形渲染设计,现广泛应用于深度学习、科学计算、图像处理等需要大量矩阵和向量运算的场景。 -
较低单核性能,但总吞吐量高
虽然每个核心的单独计算能力不及 CPU,但通过大量核心协同工作,能实现极高的总计算量。
区别:两者的区别主要分为以下两点:
- 设计目标不同:CPU面向任务的逻辑控制,负责任务之间的调度,能够处理复杂的指令;GPU主要面向大规模的并行运算,更加注重数据的吞吐量。
- 核心架构差异:CPU 核心数量少、缓存大、控制单元复杂;GPU 核心数量多、每个核心较为简单,主要用于并行执行相同类型的运算。
举例:在深度学习中,通常涉及到神经网络的前向传播运算,例如线性层或卷积层的运算,它们往往会涉及到大量的矩阵运算,比如计算两个 1024×1024 的矩阵相乘,在这种需要大量重复计算的任务当中,GPU就比CPU更适合处理这类任务。在 GPU 上,GPU 拥有数百到上千个并行计算核心,可以将这 1024×1024 个乘加运算任务分配给不同的核心同时处理。由于每个核心只执行简单的乘加运算,整个矩阵乘法可以在极短的时间内完成;而在 CPU 上,大多数 CPU 只有 4~16 个高性能核心,虽然每个核心的单核性能很强,但它们并不适合处理如此大量的并行任务。CPU 需要逐步完成大部分运算,即使利用多线程并行,也远远达不到 GPU 的并行度,因此整个运算时间会显著延长。
(形象点地表示,CPU就像一些具有很多知识、能力很强的从业者,他们能处理复杂的任务,但缺点在于人数少;而GPU就像一群只会简单加减乘除的小孩子,他们或许每个人的能力不强,但他们胜在人多,对于简单而重复的工作能够更快地完成。)
参数篇
1.FLOPs 是什么
FLOPS(浮点运算次数/秒),全称是Floating Point Operations Per Second,表示GPU每秒能进行多少次浮点数运算,单位通常带有前缀,如:
-
MFLOPS:每秒百万次(10^6)浮点运算。
-
GFLOPS:每秒十亿次(10^9)浮点运算。
-
TFLOPS:每秒万亿次(10^12)浮点运算。
-
PFLOPS:每秒千万亿次(10^15)浮点运算。
2.常见的数据精度类型
| 精度类型 | 位数 | 全称 | 简写 | 应用场景 |
| FP64 | 64位 | 双精度浮点 | Double Precision | 科学计算、高性能计算(HPC)、仿真等 |
| FP32 | 32位 | 单精度浮点 | Single Precision | 传统深度学习训练、图形渲染 |
| FP16 | 16位 | 半精度浮点 | Half Precision | 深度学习训练/推理、AI加速 |
| BF16 | 16位 | bfloat16 | Brain Floating Point | AI训练,谷歌TPU推广,兼容FP32动态范围 |
| INT8 | 8位整数 | - | - | 深度学习推理(部署) |
| INT4/INT1 | 更低整数精度 | - | - | 极端压缩的AI推理,如边缘设备 |
如表2所示,表中列出了平常深度学习中常见的数据精度类型,精度越高对数据的表示越细致。
3.如何选择合适的显卡
将FLOPS以及自己所需的数据精度结合起来考量,则有助于我们选择合适我们的显卡,以NVIDIA A100为例,我们可以看到它对各个精度的数据的运算能力:
| 精度 | 理论性能 |
|---|---|
| FP64 | 9.7 TFLOPS |
| FP32 | 19.5 TFLOPS |
| FP16 | 312 TFLOPS(Tensor Core加速下) |
| BF16 | 312 TFLOPS(Tensor Core加速下) |
| INT8 | 624 TOPS(Tensor Core) |
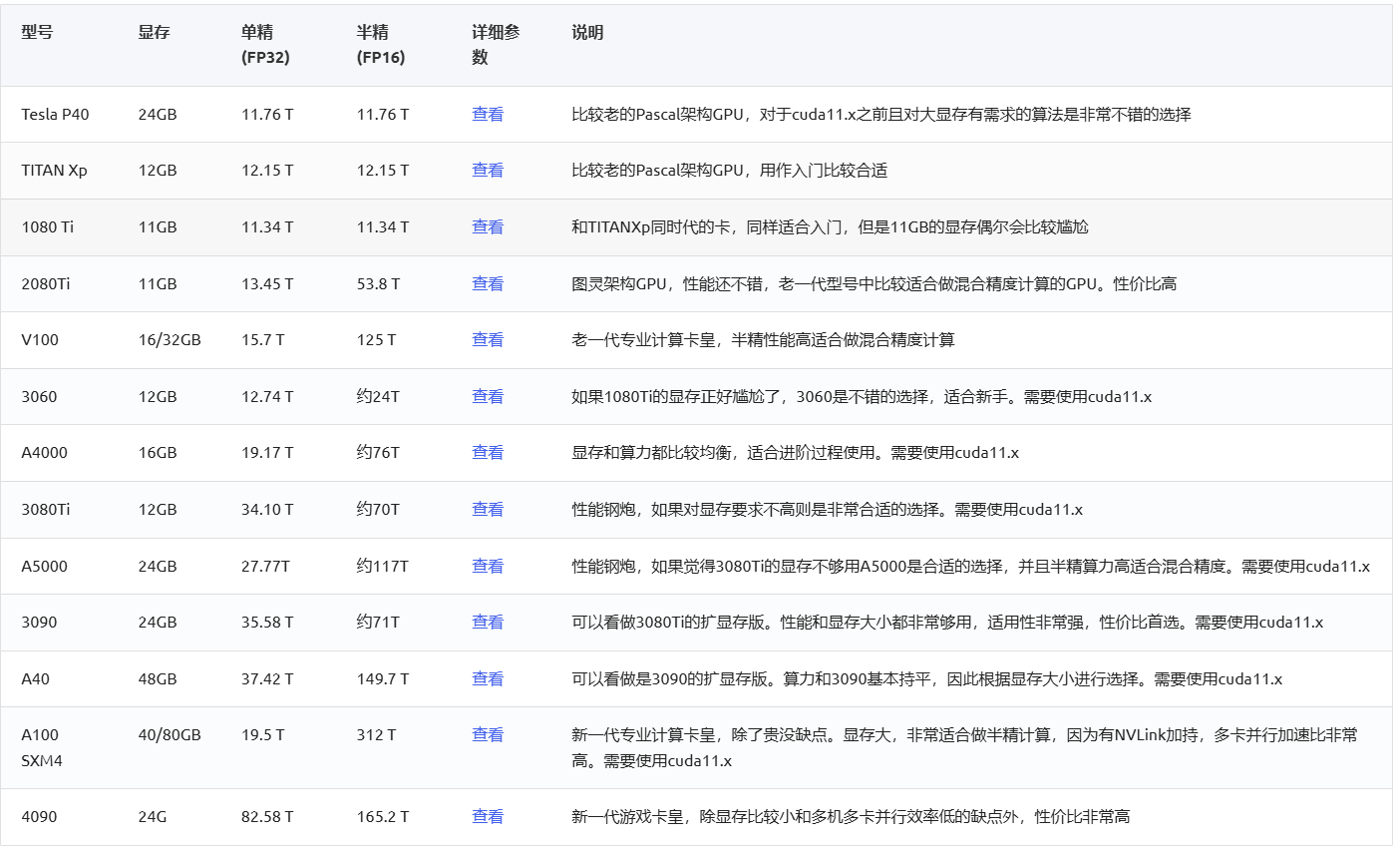
同时,在云平台AutoDL中,如图3所示帮助文档里也详细介绍了各个显卡的性能,如:显存,显卡的单精度(FP32)的运算能力,显卡的半精度(FP16)的运算能力:
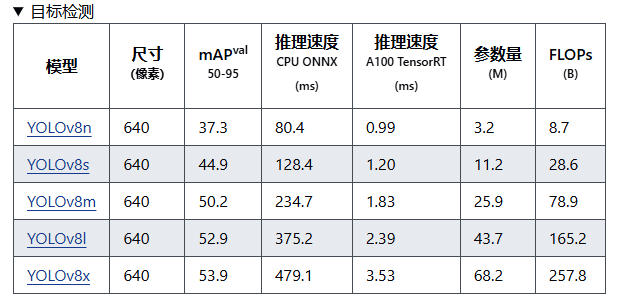
除此之外,我们除了要关注显卡的性能,还需要明确我们的需求,例如我们在显卡选型之前,也需要对模型的推理速度需求有一个明确的认知,如下图4所示,在 YOLOv8 的参数图中,最后一列显示的 FLOPs(Floating Point Operations per Second)表示模型在处理输入数据时所需的浮点运算次数。这一指标用于衡量模型的计算复杂度和性能需求。需要注意的是,FLOPs 实际上表示的是浮点运算次数,而非每秒浮点运算次数,如YOLOv8n的FLOPs为8.7billion,模型参数默认采用单精度浮点数(FP32)进行计算。
参考文献:
[1] bilibili硬件茶谈:【硬核科普】从零开始认识显卡
[2] CSDNblog:组装电脑超详细步骤(超多图+用了2个小时写的)
结语:对于深度学习而言,处了了解各个神经网络架构之外,我们也需要对硬件知识有一定的认识和了解,以上均为个人之见,欢迎大家评论区讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)