BFR算法详解
BFR算法(Bradley Fayyad Reina)是一种聚类算法,用于处理大规模数据集。该算法将数据集分为内存和磁盘中的两部分,首先在内存中对数据进行聚类,然后将无法适应内存的数据存储到磁盘中。通过多次迭代,在内存和磁盘中进行数据聚类,最终得到整个数据集的聚类结果。BFR算法通过处理大规模数据集的分布式计算,避免了在内存容量受限的情况下无法进行数据聚类的问题。该算法具有高效性和可扩展性,在大规
这里写自定义目录标题
BFR简介
BFR算法(Bradley Fayyad Reina)是一种聚类算法,用于处理大规模数据集。该算法将数据集分为内存和磁盘中的两部分,首先在内存中对数据进行聚类,然后将无法适应内存的数据存储到磁盘中。通过多次迭代,在内存和磁盘中进行数据聚类,最终得到整个数据集的聚类结果。
BFR算法通过处理大规模数据集的分布式计算,避免了在内存容量受限的情况下无法进行数据聚类的问题。该算法具有高效性和可扩展性,在大规模数据集上具有很好的表现。
BFR算法的主要思路是将数据集分为若干个簇,每个簇可以存储在内存或磁盘中。在内存中,使用基于密度的聚类算法(如DBSCAN)或基于划分的聚类算法(如K-means)对数据进行聚类。当内存容量不足时,使用一些方法将一部分数据存储到磁盘中。这些数据可能是离簇中心较远的点或未被分配到任何簇的点。在每个迭代中,根据内存和磁盘中的数据来更新簇的中心和大小,并重新分配数据到不同的簇中。最终,通过多次迭代,得到整个数据集的聚类结果。
前提
BFR整体算法是基于重要假设簇的形状必须满足以质心为期望的正态分布的(后面会讲到为什么这个假设这么重要),其包含下面的子假设。
- 一个簇在不同维度下的均值和标准差可能不同,但是维度之间必须相互独立
- 满足正态分布的假设说明每个簇看上去应该都是轴平行的椭圆形状。如下图绿色部分表示𝑦维度上的标准差比较大,因此分布会沿𝑦轴平行展开。
- 对于每个点,可以定量计算它属于某一个类别的概率
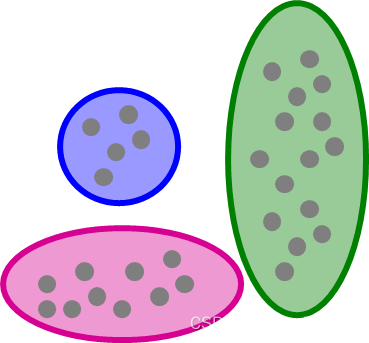
其次需要注意,BFR是针对大规模数据集采用的,例如待分类数据集有16G,而主机内存(运行内存)有8G,此时无法讲数据一次读入内存,所以需要利用BFR这个的批处理方法对其进行处理。BFR算法基本上是基于K-means的,相比于K-means还多了一些别的问题(所以能一次读入内存尽量使用K-means)
概念强调
BFR有三个重要的概念:
- 废弃集(Discard set - DS):距离某个质心足够近且生成概要信息的点集
- 压缩集(Compression set - CS):距离足够近的点,但是这些点又距离中心点较远;生成概要但还未分配簇
- 保留集(Retained set - RS):待分配到压缩集的孤立点
千万不能被名字所迷惑,这里的废弃集、压缩集保留集同样重要,为了不被名字所影响,后面一律使用DS、CS、RS表示。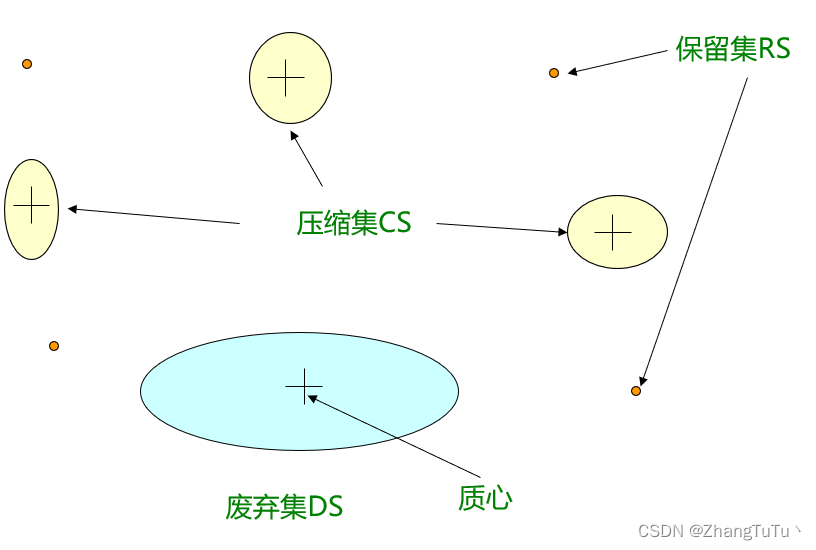
具体算法流程
首先针对一个大于本地内存的数据(假设有20G),我们本地内存只有5G,为了对这么大规模数据进行举例,我们对该数据进行分块读入,这里我们假设分成10块依次读入。
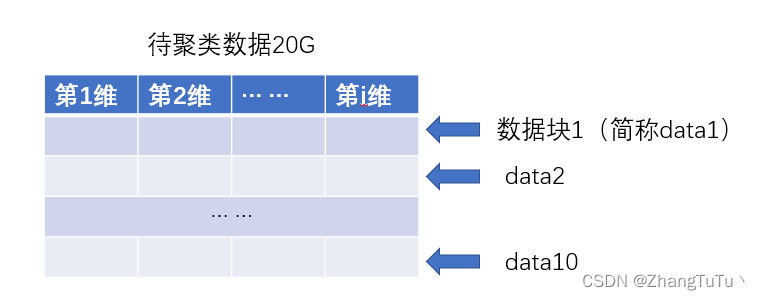
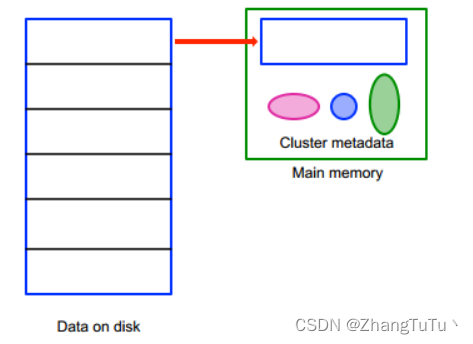
我们首先针对data1进行处理,我们对data1的数据块进行k-means,(后面都使用计算机函数语言)
k-means(data1, cluster=7*10)
后面为了方便我都会使用类似于k-means(data1, cluster=710) 这种写法
表示对data数据使用k-means进行聚簇,共分成cluster=710个簇
同时需要注意这里cluster=7*10作为超参数出现,可以随便选择,但是首次使用k-means可以稍微大一些
我们遍历这70个聚簇,若发现某些聚簇中只有一条数据,把该点加入到保留集RS中,剩下的聚簇归为DS中。
之后针对RS集中这些孤立点使用k-means(RS, cluster=len(RS)*0.7),在聚簇结果中继续找RS并将RS集更新,剩下的归类为CS。
k-means(RS, cluster=len(RS)*0.7),其中值得注意的是cluster=len(RS)*0.7也作为超参数,cluster必须小于len(RS),否则聚簇无意义,同时不一定要乘0.7,这个地方作为超参数出现,只要小于1都可以
此时我们已经对data1完成聚簇,此时我们得到了三个集合DS、CS、RS。
聚簇如何标识𝑁−𝑆𝑈𝑀−𝑆𝑈𝑀𝑆𝑄
对于大规模数据而言,首轮的聚簇已经完成了,Data1数据块的数据已经可以转至硬盘或者其他存储单元了。现在我们要思考如何用DS、CS、RS来表示整个Data1。
对于RS而言其内部为离散的孤立点,这些点通常是无意义的。所以使用字典表示即可
RS = { 数据标识/数据Index:其在硬盘中的地址}
DS、CS中不仅要存放相关数据的地址,还有其聚簇的标识𝑁−𝑆𝑈𝑀−𝑆𝑈𝑀𝑆𝑄
- 所表示的点的数目:𝑁
- 向量𝑆𝑈𝑀:所有点在每一维的分量之和,即𝑆𝑈𝑀[𝑖]表示第 i t h i^{th} ith维上的分量和
- 向量𝑆𝑈𝑀𝑆𝑄:所有点在每一维的分量平方和
标识𝑁−𝑆𝑈𝑀−𝑆𝑈𝑀𝑆𝑄仅仅为了表示信息存在其本事意义不大,他的存在是为了计算DS、CS中聚簇的质心(聚簇中心)和方差
根据N-SUM-SUMSQ我们可以得到:
该DS、CS中某聚簇
第 i i i维度上的质心: S U M i N \frac{SUM_i}{N} NSUMi
第 i i i维度上的方差: S U M S Q i N − S U M i 2 N 2 \frac{SUMSQ_i}{N} - \frac{{SUM_i}^2}{N^2} NSUMSQi−N2SUMi2
这个地方就要讲一下我们前面提到的假设:簇的形状必须满足以质心为期望的正态分布,如果簇不符合正态分布,这里计算的所谓的方差和质心就没有意义了。
迭代
到此为止data1的聚类任务结束了,data1全部清除内存,data2引入内存。
对于data2中的每一个数据(或者说每一个点)逐一与DS、CS进行比较,此时data2中的数据有三种去向DS中的某一聚簇、CS中的某一聚簇或者作为独立点加入RS中。
马氏距离与正态概率分布
我们如何认定某一点距离该聚簇足够近可以将这一点并入响应类别呢?
此时引入了马氏距离Mahalanobis Distance
马氏距离是一种归一化距离中心点的欧式距离,表示该点到该聚簇质心的距离,计算方法如下
对于点 ( X i , . . . , X k ) (X_i,...,X_k) (Xi,...,Xk)和质点 ( C 1 , . . . , C k ) (C_1,...,C_k) (C1,...,Ck)
其中 σ i \sigma_i σi表示第 i i i维簇中心的标准差
d ( x , c ) = ∑ i k ( x i − c i σ i ) 2 d(x,c)=\sqrt{\sum_{i}^k(\frac{x_i-c_i}{\sigma_i})^2} d(x,c)=∑ik(σixi−ci)2
该点某聚簇质心的距离为 d ( x , c ) d(x,c) d(x,c),此时我们已经解决了距离问题,如何评估距离近呢?
我们使用正态分布的标准差来衡量
68.26%的点马氏距离 < d = σ <\sqrt{d}=\sigma <d=σ
95.44%的点马氏距离 < 2 d = 2 σ <2\sqrt{d}=2\sigma <2d=2σ
99.73%的点马氏距离 < 3 d = 3 σ <3\sqrt{d}=3\sigma <3d=3σ
其实我认为这里的标准差衡量也不是固定的,可以作为一种超参调整的手段,你可以说 d ( x , c ) < 1.52 d d(x,c)<1.52\sqrt{d} d(x,c)<1.52d这个点就属于该聚类。主要还是为聚簇的分类进行服务的。
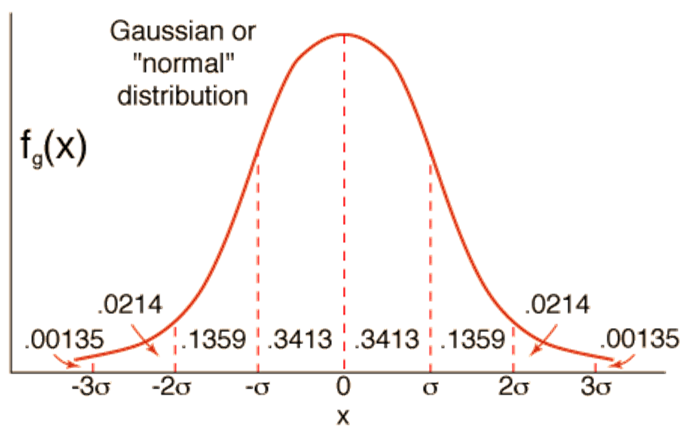
那这里为了方便我们统一认为 d ( x , c ) < d d(x,c)<\sqrt{d} d(x,c)<d 我们将点加入聚簇下。
为此我们遍历整个data2,为了把data2中的所有点按照上面的评估标准分别加入到DS、CS中的某一聚类中。【若有新点加入聚簇中,聚簇质心可能会变】如果不能加入到DS和CS的聚类中,我们将该点装入RS中。
遍历完整个data2之后我们对三个集进行调整。
对于RS集:k-means(RS,cluster=len(RS)×0.7),孤立点加入RS,其余聚簇加入CS聚簇集中。
对于CS集,将CS集与DS集进行融合,此时评估标准为质心间距离是否 < d <\sqrt{d} <d,若小于则隶属于CS中的某聚簇的所有点加入DS中,剩余的聚簇组成新的CS集。
至此data2完成迭代。剩余的data3-data10用同样的方法进行迭代即可。
收尾
最后我们的结果剩余了RS、CS、DS
其中RS我们可以理解为离群的孤立点集(噪声点)
DS是我们最后聚簇的结果
优缺点
优点:BFR算法的优点是能够处理大规模数据集
缺点:由于簇的数量是动态的,因此难以确定聚类的最佳数量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)