DnCNN:Beyond a Gaussian Denoiser: Residual Learning ofDeep CNN for Image Denoising
图像去噪是低级视觉中一个经典但仍然活跃的课题,因为它是许多实际应用中不可或缺的步骤。图像去噪的目标是从遵循图像退化模型y = x + v的噪声观测y中恢复一个干净的图像x。一个常见的假设是v是具有标准差σ的加性高斯白噪声(AWGN)。从贝叶斯的角度来看,当可能性已知时,图像先验建模将在图像去噪中起着核心作用。
一、摘要
图像去噪的鉴别模型学习由于其良好的去噪性能而受到人们的广泛关注。在本文中,我们通过研究前馈去噪卷积神经网络(DnCNNs)的构建,以拥抱深度架构、学习算法和正则化方法到图像去噪的进展。具体来说,利用残差学习和批处理归一化来加快训练过程,提高去噪性能。与现有的判别去噪模型不同,通常在一定的噪声水平上训练加性高斯白噪声(AWGN)模型,我们的DnCNN模型能够处理未知噪声水平的高斯去噪(即盲高斯去噪)。利用残差学习策略,DnCNN隐式地去除隐层中潜在的干净图像。这一特性促使我们训练一个单一的DnCNN模型来处理一些一般的图像去噪任务,如高斯去噪、单图像超分辨率和JPEG图像去阻塞。我们的大量实验表明,我们的DnCNN模型不仅可以在一些一般的图像去噪任务中表现出较高的有效性,而且还可以通过受益GPU计算来有效地实现。
index:图像去噪,卷积神经网络,残差学习,批处理归一化
二、介绍
图像去噪是低级视觉中一个经典但仍然活跃的课题,因为它是许多实际应用中不可或缺的步骤。图像去噪的目标是从遵循图像退化模型y = x + v的噪声观测y中恢复一个干净的图像x。一个常见的假设是v是具有标准差σ的加性高斯白噪声(AWGN)。从贝叶斯的角度来看,当可能性已知时,图像先验建模将在图像去噪中起着核心作用。在过去的几十年里,各种模型已被用于图像先验建模,包括非局部自相似性(NSS)模型[1],[2],[3],[4],[5],稀疏模型[6],[7],[8],梯度模型[9],[10],[11]和马尔可夫随机场(MRF)模型[12],[13],[14].特别是,NSS模型在最先进的方法中很流行,如BM3D [2],LSSC [4],NCSR [7]和WNNM [15]。(加性高斯白噪声:是一种通信理论中常用的噪声模型。这种类型的噪声在许多实际环境中都会出现,特别是在电信号传输过程中。下面是对 AWGN 的一些关键特点的解释:加性(Additive):这意味着噪声是直接加到信号之上的,而不是以其他方式(如乘法)与信号相互作用。高斯(Gaussian):噪声的幅度遵循正态分布(也称为高斯分布)。白噪声(White):白噪声是指在所有频率上功率谱密度都是均匀分布的噪声。换句话说,每个频率成分都具有相同的强度。这种特性使得白噪声在频域内是平坦的,就像白光包含了所有颜色一样。虽然真正的 AWGN 很少存在,可以帮助工程师设计出鲁棒性强的通信系统。)
尽管其去噪质量很高,但大多数去噪方法通常有两个主要的缺点。首先,这些方法在测试阶段通常涉及一个复杂的优化问题,使得去噪过程耗时为[7],[16]。因此,大多数方法很难在不牺牲计算效率的情况下实现高性能。其次,这些模型一般是非凸的,涉及到几个手动选择的参数,为提高去噪性能提供了一些回旋余地。
为了克服上述缺点,最近开发了几种判别学习方法来学习截断推理过程中的图像先验模型。所得到的模型能够在测试阶段摆脱迭代优化过程。施密特和Roth [17]提出了一种收缩场级联(脑脊液)方法,该方法将基于随机场的模型和展开的半二次优化算法统一到一个单一的学习框架中。Chen等人[18],[19]提出了一个可训练的非线性反应扩散(TNRD)模型,该模型通过展开固定数量的梯度下降推理步骤,预先学习专家[14]图像的修正场。其他一些相关的工作可以在[20]、[21]、[22]、[23]、[24]、[25]中找到。尽管脑脊液和TNRD在弥合计算效率和去噪质量之间的差距方面显示出了良好的结果,但它们的性能本质上仅限于指定的先验形式。具体来说,脑脊液和TNRD中采用的先验都是基于分析模型,它只能捕捉图像结构的完整特征。此外,通过阶段级贪婪训练和各阶段之间的联合微调来学习参数,并涉及到许多手工参数。另一个不可忽视的缺点是,它们针对特定的噪声水平训练一个特定的模型,并且在盲图像去噪中受到限制。(先验:在开始数据分析之前,基于以往的经验或信息对参数值的主观判断或客观估计。)
在本文中,我们将图像去噪作为一个简单的判别学习问题,即通过前馈卷积神经网络(CNN)从噪声图像中分离噪声,而不是学习具有显式图像先验的判别模型。使用CNN的原因有三方面。首先,CNN具有非常深的架构[26],在提高利用图像特征的容量和灵活性方面是有效的。其次,在训练CNN的正则化和学习方法方面已经取得了相当大的进展,包括整流器线性单元(ReLU)[27]、批量归一化[28]和残差学习[29]。这些方法可以在CNN中被用来加快训练过程,提高去噪性能。第三,CNN非常适合在现代功能强大的GPU上进行并行计算,可以用来提高运行时性能。
我们将所提出的去噪卷积神经网络称为DnCNN。所提出的DnCNN不是直接输出去噪图像ˆx,而是用来预测残差图像ˆv,即噪声观测与潜在干净图像之间的差异。换句话说,所提出的DnCNN在隐层中通过操作隐式地去除潜在的干净图像。进一步引入批归一化技术来稳定和提高DnCNN的训练性能。结果表明,残差学习和批处理归一化可以相互受益,它们的集成可以有效地加快训练速度和提高去噪性能。
而本文旨在设计一个更有效的高斯去噪,我们观察到,当v的区别地面真相高分辨率图像和低分辨率图像的图像退化模型可以转换为一个图像超分辨率(SISR)问题;类似地,利用原始图像与压缩图像之间的差值,JPEG图像去块问题可以用同一图像退化模型进行建模。从这个意义上说,SISR和JPEG图像去噪可以被视为“一般”图像去噪问题的两种特殊情况,尽管在SISR和JPEG中,噪声与AWGN有很大的不同。我们很自然地会问,是否有可能训练一个CNN模型来处理这种一般的图像去噪问题?通过分析DnCNN和TNRD [19]之间的联系,我们提出对DnCNN进行扩展,用于处理几种一般的图像去噪任务,包括高斯去噪、SISR和JPEG图像去阻塞。(SISR:低分辨率到高分辨率)
大量的实验表明,我们的DnCNN训练在一定的噪声水平下,比最先进的方法,如BM3D [2],WNNM [15]和TNRD [19],可以产生更好的高斯去噪结果。对于未知噪声水平的高斯去噪(即盲高斯去噪),单个模型的DnCNN仍然可以优于特定噪声水平训练的BM3D [2]和TNRD [19]。DnCNN在扩展到几种一般的图像去噪任务时,也可以得到很好的结果。此外,我们还证明了对一般的高斯去噪、SISR去噪任务只训练JPENN模型的有效性。(盲:就是在不知道确切参数的情况下进行去噪)
这项工作的贡献总结如下:1)我们提出了一种端到端可训练的深度CNN来进行高斯去噪。与现有的基于深度神经网络的直接估计潜在的干净图像的方法相比,该网络采用残差学习策略从噪声观测中去除潜在的干净图像。2)我们发现剩余学习和批归一化可以极大地有利于CNN学习,因为它们不仅可以加快训练,还可以提高去噪性能。对于具有一定噪声水平的高斯去噪,DnCNN在定量指标和视觉质量方面都优于最先进的方法。3)我们的DnCNN可以很容易地扩展到处理一般的图像去噪任务。我们可以训练一个单一的DnCNN模型来进行盲高斯去噪,并获得比在特定噪声水平下训练的竞争方法更好的性能。此外,如果只有一个DnCNN模型,它还可以解决三个一般的图像去噪任务,即盲高斯去噪、SISR和JPEG去阻塞。(“端到端”(End-to-End)在深度学习和机器学习中指的是模型的设计和训练方式,它允许从输入数据直接到输出结果的整个流程都在一个统一的框架内完成,而无需手动设计中间的特征提取步骤。)
本文的其余部分组织如下。第二节简要介绍了相关的工作。第三节首先给出了所提出的DnCNN模型,然后将其扩展到一般的图像去噪。在第四节中,进行了广泛的实验来评估dncnn。最后,在第五节中给出了几点总结性。
三、相关工作
A.用于图像去噪的深度神经网络
人们已经多次尝试通过深度神经网络来处理去噪问题。在[30]中,Jain和Seung提出使用卷积神经网络(CNNs)进行图像去噪,并声称CNNs比MRF模型具有相似甚至更好的表示能力。在[31]中,多层感知器(MLP)成功地应用于图像去噪。在[32]中,采用堆叠稀疏去噪自动编码器方法处理高斯噪声去除,取得了与K-SVD [6]相当的结果。在[19]中,提出了一个可训练的非线性反应扩散(TNRD)模型,通过展开固定数量的梯度下降推理步骤,可以将其表示为一个前馈深度网络。在上述基于深度神经网络的方法中,MLP和TNRD可以取得良好的性能,并能够与BM3D竞争。然而,对于MLP [31]和TNRD [19],一个特定的模型被训练为特定的噪声水平。据我们所知,开发CNN用于一般图像去噪仍未被研究。
B.残差学习和批量标准化
近年来,由于大规模数据集的易于访问和深度学习方法的发展,卷积神经网络在处理各种视觉任务方面取得了巨大的成功。CNN模型的代表性成果包括修正线性单元(ReLU)[27]、深度和宽度之间的权衡[26]、[33]、参数初始化[34]、基于梯度的优化算法[35]、[36]、[37]、批归一化[28]和残差学习[29]。其他因素,如在现代强大的gpu上的高效培训实施,也有助于CNN的成功。对于高斯去噪,很容易从一组高质量的图像中生成足够的训练数据。本研究重点研究CNN图像去噪的设计和学习。下面,我们简要回顾了与我们的DnCNN相关的两种方法,即残差学习和批处理归一化。
1)残差学习:CNN的残差学习[29]最初被提出是为了解决性能下降的问题,即使是训练精度也会随着网络深度的增加而开始下降。通过假设残差映射比原始的未引用映射更容易学习,残差网络明确地学习了几个堆叠层的残差映射。利用这种残差学习策略,可以很容易地训练极有深度的CNN,提高了图像分类和目标检测[29]的精度。ResNet
所提出的DnCNN模型也采用了残差学习公式。与使用许多残余差单元(即识别快捷方式)的残差网络[29]不同,我们的DnCNN使用一个残差单元来预测残差图像。通过分析残差学习公式与TNRD [19]的关系,我们进一步解释了残差学习公式的基本原理,并将其扩展到解决几个一般的图像去噪任务。需要注意的是,在残差网络[29]出现之前,在单图像超分辨率[38]和彩色图像分离[39]等低水平视觉问题中已经采用了预测残差图像的策略。然而,据我们所知,目前还没有任何工作可以直接预测残差图像的去噪。
2)批归一化:小批量随机梯度下降(SGD)已广泛应用于CNN模型的训练。尽管小批量SGD简单而有效,但由于内部协变量移位[28],即训练过程中内部非线性输入分布的变化,大大降低了其训练效率。提出了批归一化[28],通过在每层非线性之前加入归一化步骤和尺度和移位步骤来缓解内部协变量偏移。对于批处理归一化,每个激活只添加两个参数,并且可以通过反向传播来更新它们。批处理归一化具有训练速度快、性能好、对初始化的敏感度低等优点。有关批处理标准化的详细信息,请参阅[28]。
到目前为止,还没有进行过基于cnn的图像去噪的批量归一化研究。经验发现,残差学习和批归一化的集成可以实现快速稳定的训练和更好的去噪性能。
四、所提出的去噪CNN模型
在本节中,我们提出了所提出的去噪CNN模型,即DnCNN,并将其扩展到处理几个一般的图像去噪任务。一般来说,针对一个特定的任务训练一个深度CNN模型通常包括两个步骤: (i)网络架构设计和(ii)从训练数据中进行模型学习。在网络架构设计中,我们对VGG网络[26]进行了修改,使其适合于图像去噪,并根据最先进的去噪方法中使用的有效补丁大小来设置网络的深度。在模型学习中,我们采用残差学习公式,并将其纳入批归一化,以快速训练和提高去噪性能。最后,我们讨论了DnCNN和TNRD [19]之间的联系,并将DnCNN扩展到几个一般的图像去噪任务中。
A.网络深度
根据[26]中的原理,我们将卷积滤波器的大小设置为3×3,但删除了所有的池化层。因此,深度为d的DnCNN的接受野应为(2d+1)×(2d+1)。增加接受场的大小可以利用更大的图像区域的上下文信息。为了更好地在性能和效率之间进行权衡,架构设计中的一个重要问题是为DnCNN设置一个适当的深度。
研究指出,去噪神经网络的感受野大小与去噪方法[30]、[31]的有效斑片大小相关。此外,高噪声水平通常需要更大的有效补丁大小来捕获更多的上下文信息来恢复[41]。因此,通过固定噪声水平σ = 25,我们分析了几种主要去噪方法的有效补丁大小,以指导我们的DnCNN的深度设计。在BM3D(图像去噪算法) [2]中,在大小为25×25的局部窗口中自适应搜索2次,最终有效斑块大小为49×49。与BM3D类似,WNNM [15]使用了一个更大的搜索窗口,并迭代地执行非局部搜索,从而产生了一个相当大的有效补丁大小(361×361)。MLP [31]首先使用大小为39×39的贴片生成预测贴片,然后采用大小为9×9的滤波器对输出贴片进行平均,其有效贴片大小为47×47。脑脊液[17]和TNRD [19]有5个阶段,共涉及10个卷积层,滤波器大小为7×7,其有效贴片大小为61×61。
表一:不同方法的有效补丁大小与噪声水平σ = 25。

表一总结了在噪声水平为σ = 25的不同方法中所采用的有效补丁大小。可以看出,EPLL [40]中使用的有效贴片尺寸最小,即36×36。验证具有与EPLL相似的感受场大小的DnCNN是否能够与领先的去噪方法竞争是很有趣的。因此,对于具有一定噪声水平的高斯去噪,我们将DnCNN的接受场大小设置为35×35,相应的深度为17。对于其他一般的图像去噪任务,我们采用一个更大的接受域,并将深度设置为20。(特定于高斯噪声模型:假设噪声是加性的且符合高斯分布(正态分布)。一般的图像去噪:可能涉及多种类型的噪声,不仅仅是高斯噪声,还包括泊松噪声、脉冲噪声(椒盐噪声)、混合噪声等)
B.网络架构
我们的DnCNN的输入是一个噪声观测y = x + v。区分去噪模型,如MLP [31]和脑脊液[17]的目的是学习一个映射函数F (y) = x来预测潜在的干净图像。对于DnCNN,我们采用残差学习公式来训练残差映射R (y)≈v,然后我们得到x = y−R (y)。形式上,期望的残差图像与来自有噪声输入的估计图像之间的平均均方误差(y:带噪声的图像,x:干净的图像,v:噪声)(为什么将有噪声的图像直接映射到噪声,而不是干净的图像? 简化学习任务,提高模型效率,更好的细节保留,残差表示更稳定)
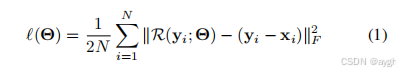
(均方差公式,除以2n是为了简化梯度计算)损失函数(loss function),用来衡量预测值 R(θ;yi) 和真实值 yi 的差距。其中ℓ(Θ) 是损失函数,Θ 表示模型参数,N 是样本数量,xi 是第 i 个样本的特征向量,yi 是对应的标签或者目标值。
可作为损失函数来学习DnCNN中的可训练参数Θ。这里{(yi,xi)} N i=1代表N有噪声-清洁的训练图像(补丁)对。图1展示了所用于学习R (y)的DnCNN的体系结构。下面,我们将解释DnCNN的体系结构和减少边界伪影的策略。
1)深度架构:给定深度为D的DnCNN,有三种类型的层,如图1所示,有三种不同的颜色。(i) Conv+ReLU:对于第一层,使用64个大小为3×3×c的滤波器生成64个特征图,然后使用校正线性单位(ReLU,max(0,·))进行非线性。这里c表示图像通道的数量,即c = 1表示灰度图像,c = 3表示彩色图像。(ii)Conv+BN+ReLU:对于层2∼(D−1),使用64个大小为3×3×64的滤波器,并在卷积和ReLU之间添加批归一化[28]。(iii)Conv:对于最后一层,使用大小为3×3×64的c滤波器重建输出。
综上所述,我们的DnCNN模型有两个主要特征:采用残差学习公式来学习R (y),并采用批处理归一化来加速训练,提高去噪性能。通过与ReLU进行卷积,DnCNN可以通过隐藏层逐步将图像结构从噪声观测中分离出来。这种机制类似于EPLL和WNNM等方法中采用的迭代噪声去除策略,但我们的DnCNN是以端到端的方式进行训练的。稍后,我们将对结合残余学习和批处理归一化的基本原理进行更多的讨论。
2)减少边界伪影:在许多低级视觉应用程序中,它通常要求输出图像的大小与输入图像的大小保持相同。这可能会导致边界伪影。在MLP [31]中,噪声输入图像的边界在预处理阶段被对称填充,而在脑脊液[17]和TNRD [19]中,在每个阶段之前都进行相同的填充策略。与上述方法不同的是,我们在卷积前直接填充零,以确保中间层的每个特征图与输入图像的大小相同。我们发现,简单的零填充策略不会产生任何边界伪影。这种良好的特性可能归因于DnCNN的强大的能力。
C. 图像去噪的残差学习与批量归一化的集成
图1中所示的网络既可以用来训练原始映射F (y)来预测x,也可以用来训练残差映射R (y)来预测v。根据[29]的说法,当原始映射更像是一个标识映射时,残差映射将更容易被优化。请注意,噪声观测y更像潜在的干净图像x,而不是剩余图像v(特别是当噪声水平较低时)。因此,F (y)将比R (y)更接近于一个恒等式映射,并且残差学习公式更适合于图像去噪。
图一:所提出的DnCNN网络的体系结构。
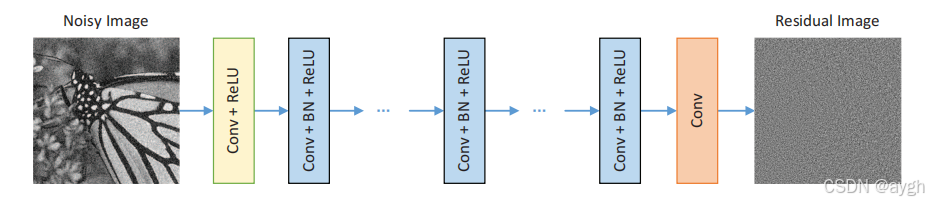
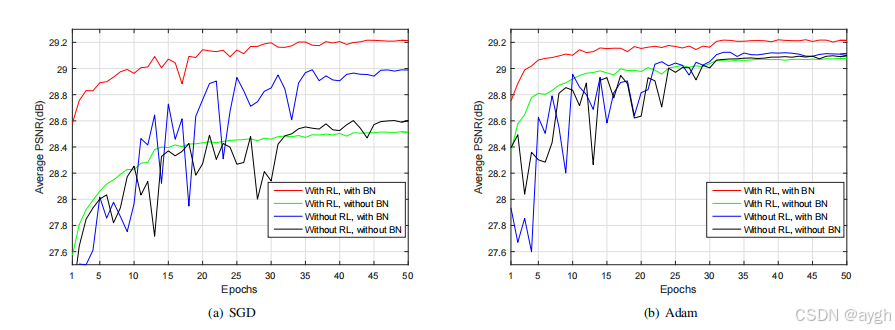
图2显示了在基于梯度的优化算法和网络架构的相同设置下,使用有/没有批量归一化的这两种学习公式得到的平均PSNR值。请注意,我们采用了两种基于梯度的优化算法:一种是具有动量的随机梯度下降算法(即SGD),另一种是Adam算法[37]。首先,我们可以观察到,残差学习公式比原始映射学习更快更稳定的收敛。同时,在没有批量归一化的情况下,传统SGD的简单残差学习无法与TNRD(28.92dB)去噪等最先进的方法竞争。我们认为性能不足应该归因于训练过程中网络参数的变化引起的内部协变量移位[28]。因此,采用批归一化的方法来解决这个问题。其次,我们观察到,在批处理归一化后,学习残差映射R(y)->v(红线)比学习原始映射(蓝线)收敛得更快,并表现出更好的去噪性能。特别是,SGD和Adam优化算法都可以使残差学习和批归一化的网络得到最好的结果。换句话说,它是残差学习公式和批处理归一化的集成,而不是优化算法(SGD或Adam),导致了最好的去噪性能。(PSNR:峰值信噪比,越高越好)计算公式:
ps:
实际上,我们可以注意到,在高斯去噪中,残差图像和批归一化都与高斯分布有关。很有可能是残留的对于高斯去噪,学习和批归一化可以相互受益。这一点可以通过下面的分析来进一步验证。
一方面,残差学习受益于批量标准化。这很简单,因为批处理规范化为cnn提供了一些优点,例如减轻内部协变量移位问题。从图2可以看出,即使没有批归一化的残差学习(绿线)收敛速度快,但它不如有批归一化的残差学习(红线)。
另一方面,批处理标准化受益于剩余学习。如图2所示,在没有残差学习的情况下,批归一化甚至对收敛有一定的不利影响(蓝线)。通过残差学习,可以利用批量归一化来加速训练,并提高性能(红线)。请注意,每个迷你浴缸都是一小组图像(例如,128张)。在没有残差学习的情况下,输入强度和卷积特征与相邻的特征相关,层输入的分布也依赖于每个训练小批图像的内容。通过残差学习,DnCNN在隐层中使用操作,隐式地去除潜在的干净图像。这使得每一层的输入都是类似高斯分布的,相关性较小,与图像内容的相关性较小。因此,残差学习也可以帮助批量归一化,以减少内部协变量的偏移。
综上所述,残差学习和批处理归一化的集成不仅可以加速和稳定训练过程,而且还可以提高去噪性能。
图二:在两种基于梯度的优化算法下,即(a) SGD和(b) Adam的高斯去噪结果。这四种特定的模型采用了残差学习(RL)和批处理归一化(BN)的不同组合,并使用噪声水平25进行训练。研究结果对来自伯克利分割数据集的68幅自然图像进行了评估。
D. 与TNRD连接*
我们的DnCNN也可以解释为单阶段TNRD [18],[19]的推广。通常,TNRD的目标是训练一个以下问题的鉴别解
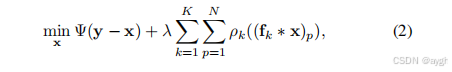 从大量的退化-干净的训练图像对。这里N表示图像大小,λ为正则化参数,fk∗x表示图像x与第k个滤波器核fk的卷积,ρk(·)表示在TNRD模型中可调节的第k个惩罚函数。对于高斯去噪,我们设置了
从大量的退化-干净的训练图像对。这里N表示图像大小,λ为正则化参数,fk∗x表示图像x与第k个滤波器核fk的卷积,ρk(·)表示在TNRD模型中可调节的第k个惩罚函数。对于高斯去噪,我们设置了![]()
第一阶段的扩散迭代可以解释为在起点y处执行一个梯度下降推理步骤,它由
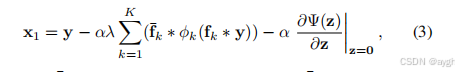
其中¯fk是fk的伴随滤波器(即¯fk通过将滤波器fk旋转180度得到),α对应于步长和ρ0k(·)=φk(·)。对于高斯去噪,我们有∂Ψ(z)∂zz=0=0,和Eqn。(3)是否等同于以下表达式
 其中v1是x相对于y的估计残差。
其中v1是x相对于y的估计残差。
由于影响函数φk(·)可以看作是应用于卷积特征映射的点态非线性,因此Eqn。(4)实际上是一个两层前馈CNN。从图1可以看出,所提出的CNN体系结构从三个方面进一步推广了初始TNRD:(TNRD)用ReLU替换影响函数,简化CNN训练;(ii)增加CNN深度,提高图像特征建模能力;(iii)结合批归一化,提高性能。与单阶段TNRD的联系为解释剩余学习的使用提供了见解用于基于cnn的图像恢复。Eqn中的大多数参数。(4)是由方程式的前一项的分析推导出来的。 (2).从这个意义上说,DnCNN中的大多数参数都表示图像的先验。
值得注意的是,即使噪声不是高斯分布的(或者高斯分布的噪声水平是未知的),我们仍然可以利用Eqn。(3)如果我们有,就可以得到v1
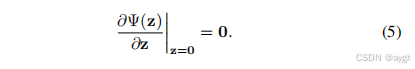
请注意,Eqn。(5)适用于许多类型的噪声分布,如广义高斯分布。我们很自然地假设它也适用于由SISR和JPEG压缩引起的噪声。可以训练一个单一的CNN模型来处理一些一般的图像去噪任务,如具有未知噪声水平的高斯去噪、具有多个升级因子的SISR和具有不同质量因子的JPEG去阻塞。
此外,Eqn。(4)也可以解释为从退化的观测y中去除潜在的干净图像x的操作来估计残差图像v。对于这些任务,即使噪声分布很复杂,也可以预期,我们的DnCNN也可以通过逐步去除隐藏层中潜在的干净图像来稳健地预测残差图像。
E. 对一般图像去噪的扩展
像MLP,脑脊液和TNRD一样,所有现有的去征高斯去噪方法都为固定的噪声水平[19],[31]训练一个特定的模型。当应用于未知噪声的高斯去噪时,一种常见的方法是首先估计噪声水平,然后使用用相应噪声水平训练的模型。这使得去噪结果受到噪声估计精度的影响。此外,这些方法也不能应用于非高斯噪声分布的情况,如SISR和JPEG去阻塞。
我们在第三-d节中的分析显示了DnCNN在一般图像去噪中的潜力。为了证明这一点,我们首先扩展了我们的DnCNN与未知噪声水平的高斯去噪。在训练阶段,我们使用来自广泛噪声水平的噪声图像(如σ∈[0,55])来训练单个DnCNN模型。给定一个噪声水平属于噪声水平范围的测试图像,可以利用学习到的单DnCNN模型对其进行去噪,而不估计其噪声水平。
采用所提出的DnCNN方法可以实现各种图像去噪任务。在本工作中,我们考虑了三个特定的任务,即盲高斯去噪、SISR和JPEG去阻塞。在训练阶段,我们利用来自广泛噪声水平的AWGN图像、具有多个上升因子的降采样图像和具有不同质量因子的JPEG图像来训练单个DnCNN模型。实验结果表明,学习到的单DnCNN模型对三种一般图像去噪任务都能产生良好的结果。
五、实验结果
A.实验设置
1)训练和测试数据:对于已知或未知噪声水平的高斯去噪,我们遵循[19],使用400张大小为180×180的图像进行训练。我们发现,使用一个更大的训练数据集只能带来很少的改进。为了训练DnCNN进行已知噪声水平下的高斯去噪,我们考虑了三个噪声水平,即σ = 15、25和50。我们将斑块大小设置为40×40,并裁剪128×1600个斑块来训练模型。我们将具有已知特定噪声水平的高斯去噪的DnCNN模型称为DnCNN-S。(“斑块”(Patch)通常指的是从一幅较大的图像中提取出来的较小的子图像区域)
我们将噪声水平的范围设置为σ∈[0,55],贴片大小设置为50×50,以便训练一个单一的DnCNN模型进行盲高斯去噪。128个×,3000个补丁被裁剪来训练模型。我们将盲高斯去噪任务的单DnCNN模型称为DnCNN-B。
参考两个广泛使用的数据集,我们建立了所有竞争方法的性能评估的测试图像。一个是测试数据集,其中包含来自伯克利分割数据集(BSD68)[14]的68张自然图像,另一个是包含12张图像,如图3所示。需要注意的是,所有这些图像都被广泛用于高斯去噪方法的评估,而且它们不包括在训练数据集中。
图3

除了灰度图像去噪外,我们还训练了盲彩色图像去噪模型CDnCNNB。我们使用BSD68数据集的颜色版本进行测试,并采用其余来自伯克利分割数据集的432张彩色图像作为训练图像。噪声水平也被设置在[0,55]的范围内,128×3000个50×50大小的补丁被裁剪来训练模型。
为了学习三种一般图像去噪任务的单一模型,如在[42]中,我们使用了一个数据集,该数据集包括来自[43]的91张图像和来自伯克利分割数据集的200张训练图像。在[0,55]范围内加入具有一定噪声水平的高斯噪声,生成噪声图像。SISR输入首先通过双降采样,然后对降尺度因子2、3和4的高分辨率图像进行双上采样。JPEG去块输入是通过使用MATLAB JPEG编码器压缩质量因子从5到99的图像来生成的。所有这些图像都被视为单个DnCNN模型的输入。我们总共生成了128个×,8,000对图像补丁(大小为50个×,50)对用于训练。在小批量学习过程中,对补丁对使用基于旋转/翻转的操作。参数用DnCNN-B初始化。对于这三种一般的图像去噪任务,我们将我们的单一DnCNN模型称为DnCNN-3。为了测试DnCNN-3,我们对每个任务采用不同的测试集,并在第IV-E节中进行详细描述。
2)参数设置和网络训练:为了获取足够的空间信息进行去噪,我们将DnCNN-S的网络深度设置为17,DnCNN-B和DnCNN-3的网络深度设置为20。Eqn(eqn是方程的意思)中的损失函数。(1)采用学习残差映射R (y),用于预测残差v。我们通过[34]中的方法初始化权值,并使用SGD,权值衰减为0.0001,动量为0.9和一个小批大小为128个。我们为我们的DnCNN模型训练了50个epoch。在50个epoch内,学习速率从1e−1到1e−4(10的-1次方到10的-4次方)呈指数衰减。
我们使用MatConvNet软件包[44]来训练所提出的DnCNN模型。除非另有说明,所有实验都是在Matlab(R2015b)环境下进行的,运行在Intel (R)核心(TM)i7-5820KCPU3.30 GHz和Nvidia Titan X GPU上。在GPU上训练DnCNN-S、DnCNNB/CDnCNN-B和DnCNN-3分别需要6小时、1天和3天。
B.比较方法
我们比较了所提出的DnCNN方法与几种最先进的去噪方法,包括两种基于非局部相似度的方法(即BM3D [2]和WNNM [15]),一种生成方法(即.,EPLL[40]),三种基于鉴别训练的方法(即.,MLP[31],脑脊液[17]和TNRD [19]).请注意,脑脊液和TNRD通过GPU实现非常高效,同时提供了良好的图像质量。实现代码从作者的网站下载,在我们的实验中使用默认参数设置。我们的DnCNN模型的训练和测试代码可以在https://github.com/cszn/DnCNN上下载。
C. 定量和定性评价
表二:在BSD68数据集上使用不同方法的PSNR(DB)结果。最佳结果用粗体突出显示。

不同方法在BSD68数据集上的平均PSNR结果见表2。可以看出,DnCNN-S和DnCNN-B都能比竞争方法获得最好的PSNR结果。与基准的BM3D方法相比,MLP和TNRD方法具有显著的PSNR增益,约为0.35 dB。根据[41],[45],很少有方法能比BM3D平均运行超过0.3 dB。相比之下,我们的DnCNN-S模型在所有三种噪声水平上都超过BM3D0.6 dB。特别是,即使在一个没有已知噪声水平的单一模型中,我们的DnCNN-B仍然可以优于针对已知特定噪声水平进行训练的竞争方法。需要注意的是,当σ = 50时,DnCNN-S和DnCNN-B的性能都比BM3D强约0.6 dB,这非常接近[45]中BM3D(0.7 dB)的估计PSNR结合。
图3中的12个测试图像。每个噪声级别的每个图像的最佳PSNR结果用粗体突出显示。可以看出,所提出的DnCNN-S在大多数图像上产生了最高的PSNR。具体来说,DnCNN-S在大多数图像上比竞争方法强0.2 dB到0.6 dB,仅在“House”和“芭芭拉”两种图像上没有达到最佳效果,这两种图像以重复结构为主。这一结果与[46]的研究结果一致:基于非局部均值的方法通常在具有规则和重复结构的图像上产生更好,而基于判别训练的方法通常在具有不规则纹理的图像上产生更好的结果。实际上,这是直观上合理的,因为具有规则和重复结构的图像与非局部相似先验吻合良好;相反,具有不规则纹理的图像会削弱这种特定先验的优势,从而导致较差的结果。
表三对12张广泛使用的测试图像进行了不同方法的PSNR(DB)结果。
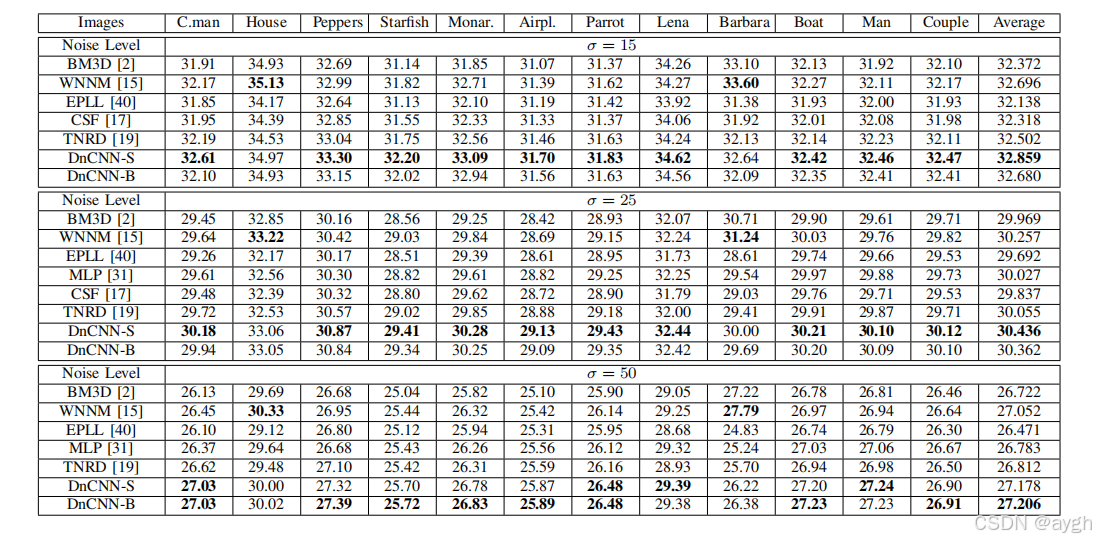
图4 来自BSD68的一幅图像的去噪结果,噪声水平为50。

图5。噪声水平为50的图像“鹦鹉”的去噪结果。

图中。4-5说明了不同方法的可视化结果。可以看出,BM3D、WNNM、EPLL和MLP倾向于产生过度光滑的边缘和纹理。在保留尖锐的边缘和细节的同时,TNRD很可能在平滑区域产生伪影。相比之下,DnCNN-S和DnCNN-B不仅可以恢复清晰的边缘和细节,而且可以在平滑区域产生视觉上令人愉快的效果。
图6。来自噪声水平为35的DSD68数据集的一幅图像的彩色图像去噪结果。

图7。来自噪声水平为45的DSD68数据集的一幅图像的彩色图像去噪结果。
对于彩色图像去噪,CDnCNN-B和基准CBM3D之间的视觉比较如图所示。6- 7.可以看出,CBM3D在某些区域产生虚假的颜色伪影,而CDnCNN-B可以恢复更自然颜色的图像。此外,CDnCNN-B可以生成比CBM3D具有更多细节和更清晰的边缘的图像。
图8。分别用DnCNN-B模型和CDnCNN-B模型对两幅真实图像进行高斯去噪结果

图8显示了我们的DnCNN-B和CDnCNN-B模型的两个真实图像去噪示例。请注意,我们的DnCNN-B是被训练为盲高斯去噪的。然而,正如在第二节中所讨论的。III-D,DnCNN-B当噪声为加性高斯白样或大致满足Eqn中的假设时,DnCNN-B可以很好地处理真实的噪声图像。 (5).从图8可以看出,我们的模型可以在保留图像细节的同时恢复视觉上令人愉快的结果。研究结果表明,将我们的方法应用在一些实际的图像去噪应用中是可行的。
图9。通过我们的DnCNN-B/CDnCNN-B模型,在不同的噪声水平下,比BM3D/CBM3D的平均PSNR改进。结果在灰色/彩色BSD68数据集上进行评估。(CDnCNN(Channel-wise DnCNN)是对DnCNN的一种改进版本,主要针对彩色图像的去噪。它引入了通道间的相互作用,使得模型能够更好地处理彩色图像中的噪声。)
纵轴表示性能提升(以dB为单位)
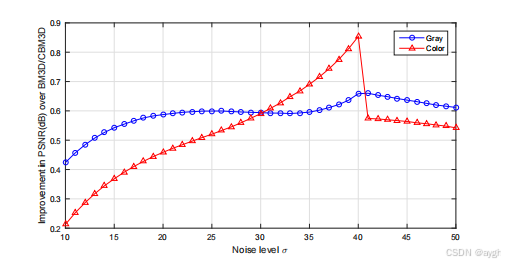
图9显示了DnCNN-B/CDnCNN-B模型在不同噪声水平下对BM3D/CBM3D的平均PSNR改善。可以看出,我们的DnCNN-B/CDnCNN-B模型在很大的噪声水平上始终超过BM3D/BCBM3D。该实验结果证明了训练单一DnCNN-B模型在大范围噪声水平内处理盲高斯去噪的可行性。
D. 运行时间
除了视觉质量外,图像恢复方法的另一个重要方面是测试速度。表四显示了大小为256×256、512×512和1024×1024的噪声水平为25的不同方法的运行时间。由于脑脊液、TNRD和我们的DnCNN方法非常适合在GPU上进行并行计算,因此我们也给出了在GPU上相应的运行时间。我们使用Nvidia cuDNNv5深度学习库来加速所提出的DnCNN的GPU计算。和在[19]中一样,我们不计算CPU和GPU之间的内存传输时间。可以看出,所提出的DnCNN在CPU上具有较高的速度,而且比MLP和脑脊液两种鉴别模型都要快。虽然它比BM3D和TNRD要慢,但考虑到图像质量的提高,我们的DnCNN在CPU实现方面仍然具有很强的竞争力。对于GPU时间,所提出的DnCNN实现了非常吸引人的计算效率,例如,它可以去噪一个大小的图像512×512在60 ms未知噪声水平,这是一个明显的优势。
表四:在大小为256×256、512×512和1024×1024、噪声级为25的图像上运行不同方法的时间(以秒为单位)。对于脑脊液、TNRD和我们提出的DNCNN,我们给出了在CPU(左)和GPU(右)上的运行时间。值得注意的是,由于GPU上的运行时间与GPU和GPU加速库之间的差异很大,因此很难对脑脊液、TNRD和我们提出的DNCNN进行公平的比较。因此,我们只需从原始论文中复制GPU上的脑脊液和TNRD的运行时间。

E. 三种通用图像去噪任务的单一模型学习实验
为了进一步展示所提出的DnCNN模型的能力,我们用一个单一的DnCNN-3模型训练了三个一般的图像去噪任务,包括盲高斯去噪、SISR和JPEG图像去阻塞。据我们所知,没有一种现有的方法被报道为只用一个模型来处理这三个任务。因此,对于每个任务,我们将DnCNN-3与特定的最新方法进行比较。下面,我们将描述每个任务的比较方法和测试数据集:
对于高斯去噪,我们使用最先进的BM3D和TNRD进行比较。BSD68数据集用于测试性能。对于BM3D和TNRD,我们假设噪声水平是已知的。
对于SISR,我们考虑了两种最先进的方法,即TNRD和VDSR [42]。TNRD为每个升级因子训练一个特定的模型,而VDSR [42]为所有三个升级因子(即2、3和4)训练一个单个模型。我们采用了[42]中使用的四个测试数据集(即Set5和Set14、BSD100和Urban100 [47])。
对于JPEG图像去阻塞,我们的DnCNN-3与两种最先进的方法进行了比较,即AR-CNN [48]和TNRD [19]。AR-CNN方法分别对JPEG质量因子10、20、30和40训练了4个特定的模型。对于TNRD,训练了JPEG质量因子10、20和30模型。与在[48]中一样,我们采用经典的5和LIVE1作为测试数据集。
表五:平均PSNR(DB)/SSIM不同方法的高斯去噪噪声水平15,25和50bsd68数据集,单图像超分辨率升级因素2、3和4集5,设置14,bsd100和城市100数据集,JPEG图像阻塞质量因素10、20、30和40经典5和生活1数据集。最佳结果用粗体突出显示。
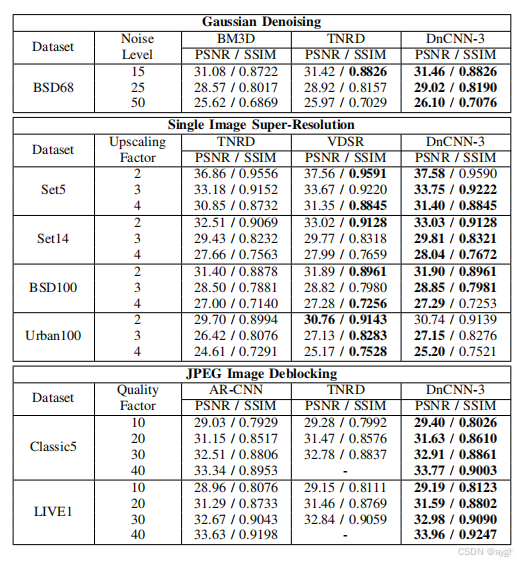
表V列出了不同方法对不同一般图像去噪任务的平均PSNR和SSIM结果。正如我们所看到的,即使我们训练了一个单一的DnCNN-3模型,它在高斯去噪方面仍然优于非盲的TNRD和BM3D。对于SISR来说,它远远超过了TNRD,与VDSR相当。对于JPEG图像去块,DnCNN-3在PSNR中比AR-CNN高出约0.3 dB,在所有质量因子上比TNRD增加约0.1 dB。
图10:具有上升比例因子3的集合5数据集的“蝴蝶”的单图像超分辨率结果。(“上升因子”(scaling factor 或 upscaling factor)指的是将低分辨率图像放大到更高分辨率时的比例系数,如果上升因子是2,那么输出的高分辨率图像的宽度和高度将是输入低分辨率图像的两倍)
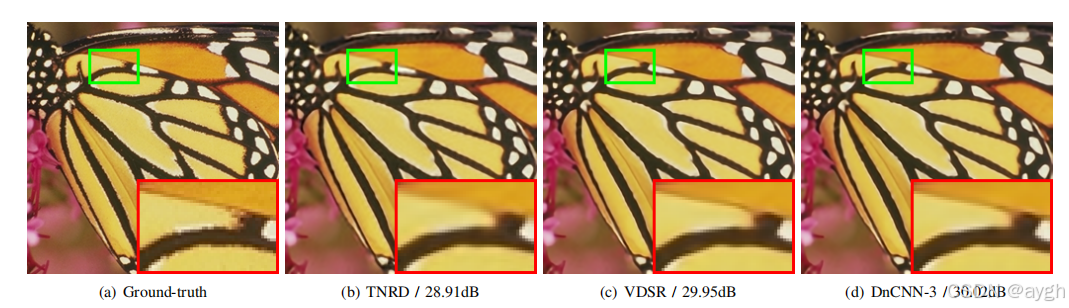
图11。来自Urban100数据集的一幅图像的单幅图像超分辨率结果。

图12。JPEG图像去块结果从LIVE1数据集LIVE1,质量因子10。

图13。举一个例子来说明我们提出的模型对三个不同任务的能力。输入图像由噪声水平为15(左上)和25(左下)的噪声图像,放大因子为2(中上)和3(中下)的低分辨率图像,质量因子为10(右上)和30(右下)的JPEG图像组成。请注意,输入图像中的白线仅用于区分六个区域,残差图像归一化到[0,1]范围进行可视化。即使输入的图像在不同的区域有不同的失真,恢复后的图像看起来很自然,没有明显的伪影。

图10和图11为SISR不同方法的视觉比较。可以看出,DnCNN-3和VDSR都能产生尖锐的边缘和细节,而TNRD则倾向于产生模糊的边缘和扭曲的线。图12显示了不同方法的JPEG解块结果。正如我们可以看到的,我们的DnCNN-3可以恢复直线,而AR-CNN和TNRD则容易产生扭曲的线。图13给出了另一个例子来显示所提模型的容量。我们可以看到,即使输入图像被DnCNN- 3在不同的区域发生了多次扭曲,也可以产生不同的视觉愉悦的输出结果。
六、结论
本文提出了一种用于图像去噪的深度卷积神经网络,其中采用残差学习方法来分离噪声观测中的噪声。集成了批处理归一化和残差学习,以加快训练过程,提高去噪性能。与传统的判别模型训练特定噪声水平的特定模型不同,我们的单一DnCNN模型具有处理未知噪声水平的盲高斯去噪的能力。此外,我们还展示了训练单个DnCNN模型处理三种一般图像去噪任务的可行性,包括未知噪声水平的高斯去噪、多升级因子的单图像超分辨率和不同质量因子的JPEG图像去块。大量的实验结果表明,该方法不仅在定量和定性上都具有良好的图像去噪性能,而且通过GPU实现具有良好的运行时间。在未来,我们将研究适当的CNN模型去噪与真实复杂噪声的图像和其他一般的图像恢复任务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)