常见优化器
它是对 Adagrad 的改进,旨在解决 Adagrad 学习率逐渐变小的问题。Adadelta 通过限制累积梯度的窗口大小,动态调整每个参数的学习率,从而提高训练效率和稳定性。它通过计算梯度的一阶和二阶矩估计来动态调整每个参数的学习率,并包含偏差校正步骤,以确保在训练初期估计值的准确性。Nadam 的核心思想是结合 Adam 的自适应学习率和 Nesterov 动量的提前梯度计算。两个超参数:学
目录
1. SGD(Stochastic Gradient Descent) 随机梯度下降
2. SGDM(SGD with Momentum)随机梯度下降---引入动量
3. NAG(Nesterov Accelerated Gradient) 改进的动量-梯度下降方法
4. Adagrad (Adaptive Gradient)自适应学习率优化算法、编辑
5. RMSProp(Root Mean Square Propagation)是一种自适应学习率优化算法
6. Adam (Adaptive Moment Estimation)
13. Cyclical Learning Rates (CLR)
1. SGD(Stochastic Gradient Descent) 随机梯度下降



import numpy as np
# 假设我们有一个简单的线性回归模型
def model(x, theta):
return np.dot(x, theta)
# 损失函数(均方误差)
def loss(y_pred, y_true):
return np.mean((y_pred - y_true) ** 2)
# 梯度计算
def gradient(x, y, theta):
y_pred = model(x, theta)
grad = np.dot(x.T, (y_pred - y)) / len(y)
return grad
# 随机梯度下降
def sgd(x, y, theta, learning_rate, epochs):
for epoch in range(epochs):
for i in range(len(y)):
grad = gradient(x[i:i+1], y[i:i+1], theta)
theta = theta - learning_rate * grad
return theta
# 示例数据
x = np.array([[1, 2], [2, 3], [3, 4]])
y = np.array([3, 5, 7])
theta = np.random.randn(2)
# 训练模型
learning_rate = 0.01
epochs = 1000
theta = sgd(x, y, theta, learning_rate, epochs)
print("训练后的参数:", theta)2. SGDM(SGD with Momentum)随机梯度下降---引入动量
注:用动量 (也就是累计梯度) 来更新参数
两个超参数:学习率 、 动量系数 (梯度累计中,上一次梯度的比例)



import numpy as np
# 假设我们有一个简单的线性回归模型
def model(x, theta):
return np.dot(x, theta)
# 损失函数(均方误差)
def loss(y_pred, y_true):
return np.mean((y_pred - y_true) ** 2)
# 梯度计算
def gradient(x, y, theta):
y_pred = model(x, theta)
grad = np.dot(x.T, (y_pred - y)) / len(y)
return grad
# SGD with Momentum
def sgdm(x, y, theta, learning_rate, epochs, beta):
v = np.zeros_like(theta)
for epoch in range(epochs):
for i in range(len(y)):
grad = gradient(x[i:i+1], y[i:i+1], theta)
v = beta * v + (1 - beta) * grad
theta = theta - learning_rate * v
return theta
# 示例数据
x = np.array([[1, 2], [2, 3], [3, 4]])
y = np.array([3, 5, 7])
theta = np.random.randn(2)
# 训练模型
learning_rate = 0.01
epochs = 1000
beta = 0.9
theta = sgdm(x, y, theta, learning_rate, epochs, beta)
print("训练后的参数:", theta)3. NAG(Nesterov Accelerated Gradient) 改进的动量-梯度下降方法
改进的动量-梯度下降方法
用动量预测下一步的梯度位置,动量系数 belta
动量更新:用梯度更新动量, 学习率 n
动量更新参数:


import numpy as np
# 假设我们有一个简单的线性回归模型
def model(x, theta):
return np.dot(x, theta)
# 损失函数(均方误差)
def loss(y_pred, y_true):
return np.mean((y_pred - y_true) ** 2)
# 梯度计算
def gradient(x, y, theta):
y_pred = model(x, theta)
grad = np.dot(x.T, (y_pred - y)) / len(y)
return grad
# Nesterov Accelerated Gradient
def nag(x, y, theta, learning_rate, epochs, beta):
v = np.zeros_like(theta)
for epoch in range(epochs):
for i in range(len(y)):
lookahead_theta = theta - beta * v
grad = gradient(x[i:i+1], y[i:i+1], lookahead_theta)
v = beta * v + learning_rate * grad
theta = theta - v
return theta
# 示例数据
x = np.array([[1, 2], [2, 3], [3, 4]])
y = np.array([3, 5, 7])
theta = np.random.randn(2)
# 训练模型
learning_rate = 0.01
epochs = 1000
beta = 0.9
theta = nag(x, y, theta, learning_rate, epochs, beta)
print("训练后的参数:", theta)4. Adagrad (Adaptive Gradient)自适应学习率优化算法、

5. RMSProp(Root Mean Square Propagation)是一种自适应学习率优化算法


6. Adam (Adaptive Moment Estimation)
Adam(Adaptive Moment Estimation)是一种自适应学习率优化算法,结合了动量和 RMSProp 的优点。它通过计算梯度的一阶和二阶矩估计来动态调整每个参数的学习率,并包含偏差校正步骤,以确保在训练初期估计值的准确性。


7. Adadelta -- 自适应学习率优化算法
Adadelta 是一种自适应学习率优化算法,由 Matthew D. Zeiler 于 2012 年提出。它是对 Adagrad 的改进,旨在解决 Adagrad 学习率逐渐变小的问题。Adadelta 通过限制累积梯度的窗口大小,动态调整每个参数的学习率,从而提高训练效率和稳定性。

8. AdaMax Adam 优化器的改进

9. Nadam Adam 和 Nesterov 动量
Nadam 的核心思想是结合 Adam 的自适应学习率和 Nesterov 动量的提前梯度计算

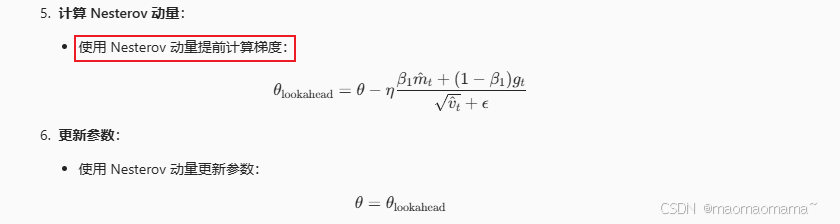

10. AMSGrad


11. Lookahead

 。
。
12. RAdam



13. Cyclical Learning Rates (CLR)


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)