随机森林(Random Forest)(RF)
随机森林就是多棵决策树在一起组成的森林,就是多个决策树执行民主决策的过程。
·
一.简介与原理
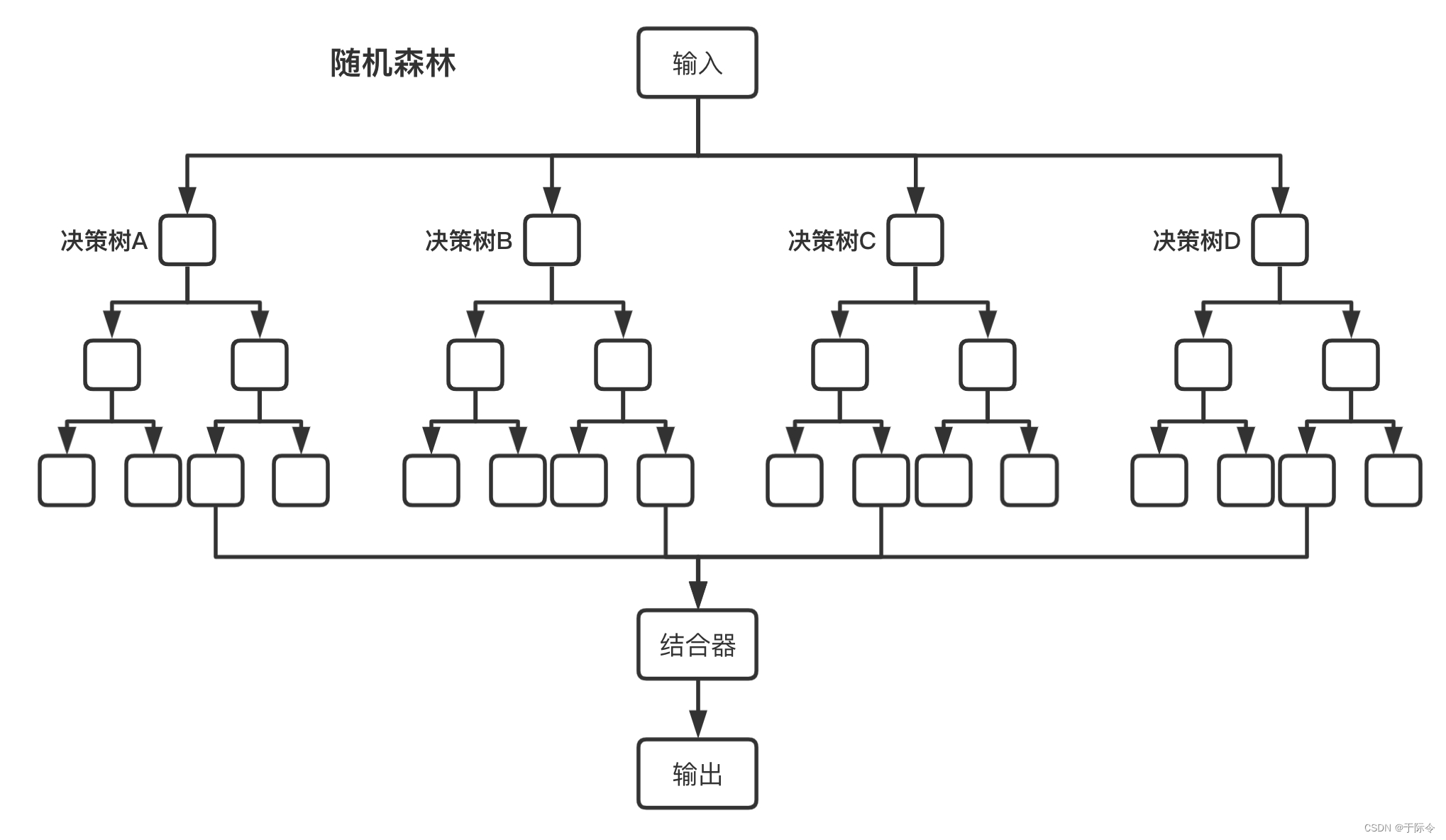
随机森林就是多棵决策树在一起组成的森林,就是多个决策树执行民主决策的过程
随机森林算法的优点:
- 对于很多种资料,可以产生高准确度的分类器
- 可以处理大量的输入变量
- 可以在决定类别时,评估变量的重要性
- 在建造森林时,可以在内部对于一般化后的误差产生不偏差的估计
- 包含一个好方法可以估计丢失的资料,并且如果有很大一部分的资料丢失,仍可以维持准确度
- 对于不平衡的分类资料集来说,可以平衡误差
- 可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类,也可侦测偏离者和观看资料
- 学习过程很快速
随机森林算法的缺点:
- 牺牲了决策树的可解释性
- 在某些噪音较大的分类或回归问题上会过拟合
- 在多个分类变量的问题中,随机森林可能无法提高基学习器的准确性
二.程序
1.导入随机森林模型
随机森林分类模型:
from sklearn.ensemble import RandomForestClassifier 随机森林回归模型:
from sklearn.ensemble import RandomForestRegressor2.划分数据集用到的函数:
train_test_split()

3.iris
datasets.load_iris()是sklearn中内置的鸾尾花数据集
4.注释
iris = datasets.load_iris() #datasets.load_iris()是sklearn中内置的鸾尾花数据集
#print(iris)
X = iris.data[:, [2, 3]] #表示从鸢尾花数据集中选取所有行、第三列第四列的数据。[2:3]才不包括3,是左闭右开. [2,3]是第三列和第四列,是闭区间
y = iris.target5.代码
随机森林回归模型:
随机森林回归模型(RandomForestRegressor)的常用参数:
- n_estimators:森林中树的数量,默认为100。增加树的数量可以提高模型的性能,但也会增加计算成本。
- criterion:衡量分割质量的评价准则,默认为'mse'(均方误差)。其他可选的评价准则包括'mae'(平均绝对误差)和'mse'(均方误差)。
- max_depth:树的最大深度,默认为None。如果不指定深度,树会一直生长直到所有叶节点都是纯净的或者包含的样本数小于min_samples_split。
- min_samples_split:分割内部节点所需的最小样本数,默认为2。如果某个内部节点的样本数小于该值,则不会再进行分割。
- min_samples_leaf:叶节点所需的最小样本数,默认为1。如果某个叶节点的样本数小于该值,则该叶节点会被剪枝。
- max_features:寻找最佳分割时考虑的特征数,默认为'auto'(即sqrt(n_features))。可以是整数(考虑固定数量的特征)或浮点数(考虑固定比例的特征)。
- random_state:随机种子,用于控制随机性。
# 导入必要的库和数据集:
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
# 导入数据集
#x, y = load_data() # 加载自己的数据集
iris = load_iris()
x = iris.data
y = iris.target
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 创建随机森林回归模型并进行训练:
# 创建随机森林回归模型
rf_regressor = RandomForestRegressor(n_estimators=100, random_state=42)
# 训练模型
rf_regressor.fit(x_train, y_train)
# 进行预测并评估模型:
# 进行预测
y_pred = rf_regressor.predict(x_test)
print(y_pred)
# 计算均方误差(Mean Squared Error)
mse = mean_squared_error(y_test, y_pred)
print(mse)
#计算得分
score=rf_regressor.score(x_test,y_test)
print(score)
随机森林分类模型:
- n_estimators:指定森林中决策树的数量,默认值为100。增加n_estimators可以提高模型的性能,但会增加训练时间。
- criterion:用于衡量特征选择质量的度量标准。常见的取值有"gini"和"entropy"。默认值为"gini",表示使用基尼系数作为度量标准。
- max_depth:决策树的最大深度。默认值为None,表示不限制决策树的深度。增加max_depth可以增加模型的复杂度,但也容易导致过拟合。
- min_samples_split:拆分内部节点所需的最小样本数。默认值为2。如果某个内部节点的样本数小于min_samples_split,则不会再继续拆分。
- min_samples_leaf:叶节点上所需的最小样本数。默认值为1。如果某个叶节点的样本数小于min_samples_leaf,则该叶节点会被剪枝。
- max_features:寻找最佳分割时考虑的特征数量。可以是整数、浮点数或字符串。默认值为"auto",表示考虑所有特征。还可以取"sqrt"、"log2"等值
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
x = iris.data
y = iris.target
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 训练随机森林模型
clf = RandomForestClassifier(n_estimators=100, random_state=42) #n_estimators是森林中树的数量默认100,,random_state是随机数种子
clf.fit(x_train, y_train)
# 预测测试集
y_pred = clf.predict(x_test)
print(y_pred)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)