旅鼠优化算法(ALA)-2025年SCI顶刊新算法—附MATLAB完整版代码
智能信息时代的到来见证了跨各个学科的复杂优化问题的激增。尽管现有的元启发式算法在许多场景中都表现出了功效,但它们仍在与某些挑战作斗争,例如过早收敛、探索不足以及在高维、非凸搜索空间中缺乏鲁棒性。这些限制凸显了对能够在保持计算效率的同时更好地平衡探索和利用的新颖优化技术的需求。针对这一需求,我们提出了人工旅鼠算法(ALA),这是一种受生物启发的元启发式算法,它在数学上模拟了自然界中旅鼠的四种不同行为
智能信息时代的到来见证了跨各个学科的复杂优化问题的激增。尽管现有的元启发式算法在许多场景中都表现出了功效,但它们仍在与某些挑战作斗争,例如过早收敛、探索不足以及在高维、非凸搜索空间中缺乏鲁棒性。这些限制凸显了对能够在保持计算效率的同时更好地平衡探索和利用的新颖优化技术的需求。针对这一需求,我们提出了人工旅鼠算法(ALA),这是一种受生物启发的元启发式算法,它在数学上模拟了自然界中旅鼠的四种不同行为:长距离迁徙、挖洞、觅食和躲避捕食者。
具体而言,长距离迁移和挖洞行为致力于高度探索搜索域,而觅食和躲避捕食者行为则在优化过程中提供了开发。于2025年1月发表在中科院2区(IF>10).
2.2 数学模型
2.2.1 初始化
ALA 是一种基于种群的算法,要求在进入迭代过程之前初始化所有搜索代理的位置。候选解集 Z⃗\vec{Z}Z 是一个由 NNN(种群大小)行和 DimDimDim(给定问题的维度数)列组成的矩阵,位于上下界之间,如公式 (3) 所示。每次迭代中的最佳位置被认为是到目前为止获得的最优解或接近最优解。通过公式 (4) 计算每个维度的决策变量 zi,jz_{i,j}zi,j:
Z⃗=[z1,1z1,2⋯z1,Dim−1z1,Dimz2,1z2,2⋯z2,Dim−1z2,Dim⋮⋮⋮⋮⋮zN−1,1zN−1,2⋯zN−1,Dim−1zN−1,DimzN,1zN,2⋯zN,Dim−1zN,Dim] \vec{Z} = \begin{bmatrix} z_{1,1} & z_{1,2} & \cdots & z_{1,Dim-1} & z_{1,Dim} \\ z_{2,1} & z_{2,2} & \cdots & z_{2,Dim-1} & z_{2,Dim} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ z_{N-1,1} & z_{N-1,2} & \cdots & z_{N-1,Dim-1} & z_{N-1,Dim} \\ z_{N,1} & z_{N,2} & \cdots & z_{N,Dim-1} & z_{N,Dim} \\ \end{bmatrix} Z=
z1,1z2,1⋮zN−1,1zN,1z1,2z2,2⋮zN−1,2zN,2⋯⋯⋮⋯⋯z1,Dim−1z2,Dim−1⋮zN−1,Dim−1zN,Dim−1z1,Dimz2,Dim⋮zN−1,DimzN,Dim
然后得到初始化如下
zi,j=LBj+rand×(UBj−LBj),i=1,2,⋯ ,N,j=1,2,⋯ ,Dim z_{i,j} = LB_j + rand \times (UB_j - LB_j), i = 1, 2, \cdots, N, j = 1, 2, \cdots, Dim zi,j=LBj+rand×(UBj−LBj),i=1,2,⋯,N,j=1,2,⋯,Dim
其中 rand 是范围在 0-1 之间的随机值,LBjLB_jLBj 表示第 jjj 维的下限,UBjUB_jUBj 是第 jjj 维的上限。
2.2.2 长距离迁移(探索)
在第一种行为中,当食物稀缺时,鼹鼠会随机进行长距离迁移。在这里,鼹鼠将根据当前位置和种群中随机个体的位置探索搜索空间,以找到资源丰富的栖息地,从而获得更好的生存条件和资源。同时,值得注意的是,鼹鼠迁移的方向和距离由于各种因素(如生态环境)而不稳定。为了模拟这种行为,提出了以下公式:
Z⃗i(t+1)=Z⃗best(t)+F×BM×(R⃗×(Z⃗best(t)−Z⃗i(t))+(1−R⃗)×(Z⃗b(t)−Z⃗i(t))) \vec{Z}_i(t+1) = \vec{Z}_{best}(t) + F \times BM \times \left( \vec{R} \times \left( \vec{Z}_{best}(t) - \vec{Z}_i(t) \right) + \left( 1 - \vec{R} \right) \times \left( \vec{Z}_b(t) - \vec{Z}_i(t) \right) \right) Zi(t+1)=Zbest(t)+F×BM×(R×(Zbest(t)−Zi(t))+(1−R)×(Zb(t)−Zi(t)))
其中 Z⃗i(t+1)\vec{Z}_i(t+1)Zi(t+1) 表示第 iii 个搜索代理在 (t+1)(t+1)(t+1) 次迭代中的位置,Z⃗best(t)\vec{Z}_{best}(t)Zbest(t) 表示当前最优解。FFF 用于改变搜索方向,通过公式 (7) 计算,这有助于避免局部最优并为搜索代理提供更高的机会来严格扫描问题域。BMBMBM 表示随机数向量,用于描述布朗运动,其具有动态和均匀的步长,以探索搜索空间中的某些潜在区域。标准布朗运动的步长通过正态分布的概率密度函数获得,方差为 1,均值为 0,如公式 (6) 所示。R⃗\vec{R}R 是一个 1×Dim1 \times Dim1×Dim 的向量,其元素是均匀分布在区间 [-1, 1] 中的随机数,通过公式 (8) 生成。该向量用于表示种群中当前最优个体和随机个体之间的相互作用。Z⃗i(t)\vec{Z}_i(t)Zi(t) 表示第 iii 个搜索代理的当前位置。Z⃗b(t)\vec{Z}_b(t)Zb(t) 表示从种群中随机选择的搜索个体的位置,aaa 是介于 1 和 NNN 之间的整数索引。图 4 展示了二维中长距离迁移行为的数学建模原理。
fBM(x;0,1)=12π×exp(−x22) f_{BM}(x;0,1) = \frac{1}{\sqrt{2\pi}} \times \exp \left( -\frac{x^2}{2} \right) fBM(x;0,1)=2π1×exp(−2x2)
其次:
F={1if [2×rand+1]=1−1if [2×rand+1]=2 F = \begin{cases} 1 & \text{if } [2 \times rand + 1] = 1 \\ -1 & \text{if } [2 \times rand + 1] = 2 \end{cases} F={1−1if [2×rand+1]=1if [2×rand+1]=2
其中
R⃗=2×rand(1,Dim)−1 \vec{R} = 2 \times rand(1, Dim) - 1 R=2×rand(1,Dim)−1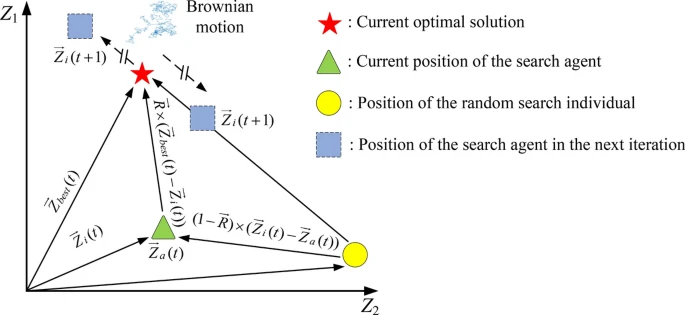
图 4 展示了二维中长距离迁移模型的示意图
2.2.3 挖洞(探索)
鼹鼠的第二种行为涉及在栖息地中挖洞以形成复杂的隧道,提供安全的庇护所和食物储存。鼹鼠将根据当前位置和种群中随机个体的位置随机挖新洞。这种设计有助于它们快速逃离捕食者并更有效地寻找食物。图 5 展示了挖洞的简单示例。该行为通过公式 (9) 模拟:
Z⃗i(t+1)=Z⃗i(t)+F×L×(Z⃗best(t)−Z⃗i(t)) \vec{Z}_i(t+1) = \vec{Z}_i(t) + F \times L \times \left( \vec{Z}_{best}(t) - \vec{Z}_i(t) \right) Zi(t+1)=Zi(t)+F×L×(Zbest(t)−Zi(t))
其中 LLL 是与当前迭代次数相关的随机数。Z⃗b\vec{Z}_bZb 表示从种群中随机选择的搜索个体,bbb 是介于 1 和 NNN 之间的随机整数索引。LLL 和 Z⃗b\vec{Z}_bZb 用于描述鼹鼠在挖新洞时的相互作用。LLL 的值计算如下:
L=rand×(1+sin(tTmax)) L = rand \times \left( 1 + \sin \left( \frac{t}{T_{max}} \right) \right) L=rand×(1+sin(Tmaxt))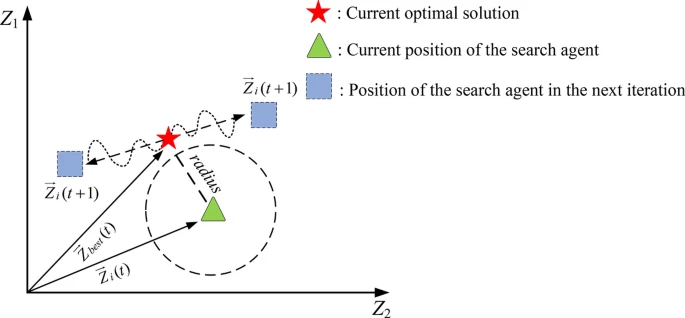
图 5 展示了二维中挖洞模型的示意图
2.2.4 觅食(开发)
在第三种行为中,鼹鼠在其栖息地的洞穴中广泛而任意地移动,依靠其敏锐的嗅觉和听觉来定位食物来源。鼹鼠通常在其栖息地内建立一个相对较小的觅食区域,该区域取决于食物的丰富度和可用性。为了尽可能多地摄入食物,鼹鼠将在其觅食区域内随机游荡。图 6 展示了鼹鼠的随机觅食行为。螺旋缠绕机制被认为可以模拟这一阶段,如下所示:
Z⃗i(t+1)=Z⃗best(t)+F×spiral×rand×Z⃗i(t) \vec{Z}_i(t+1) = \vec{Z}_{best}(t) + F \times spiral \times rand \times \vec{Z}_i(t) Zi(t+1)=Zbest(t)+F×spiral×rand×Zi(t)
其中 spiral 表示觅食过程中随机搜索的螺旋形状,通过公式 (12) 和 (13) 计算:
spiral=radius×(sin(2×π×rand)+cos(2×π×rand)) spiral = radius \times \left( \sin \left( 2 \times \pi \times rand \right) + \cos \left( 2 \times \pi \times rand \right) \right) spiral=radius×(sin(2×π×rand)+cos(2×π×rand))
其中
radius=Dim∑j=1Dim(zbest,j(t)−zi,j(t))2 radius = \sqrt{\frac{Dim}{\sum_{j=1}^{Dim} \left( z_{best,j}(t) - z_{i,j}(t) \right)^2}} radius=∑j=1Dim(zbest,j(t)−zi,j(t))2Dim
其中 radius 表示觅食范围的半径,即当前位置与最优解之间的欧几里得距离。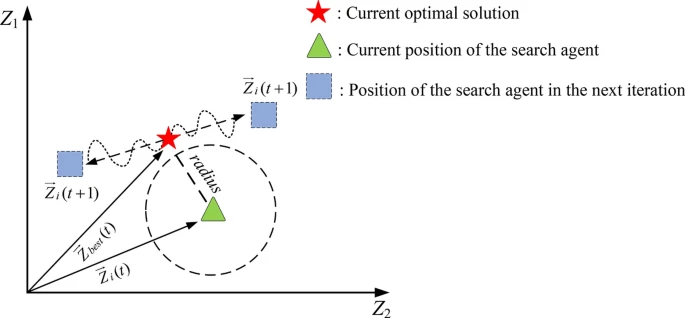
图 6 展示了二维中觅食模型的示意图
2.2.5 逃避天敌(开发)
在最后一个阶段,建模重点放在鼹鼠在遇到危险时的逃避和保护行为上。洞穴为鼹鼠提供了庇护所。一旦检测到敌人,鼹鼠利用其出色的奔跑能力逃回洞穴。同时,鼹鼠还进行欺骗性机动以逃避捕食者的追击。图 7 展示了鼹鼠逃避捕食者的行为。相应的数学表达式在公式 (14) 中描述:
Z⃗i(t+1)=Z⃗best(t)+F×G×Levy(Dim)×(Z⃗rest(t)−Z⃗i(t)) \vec{Z}_i(t+1) = \vec{Z}_{best}(t) + F \times G \times Levy(Dim) \times \left( \vec{Z}_{rest}(t) - \vec{Z}_i(t) \right) Zi(t+1)=Zbest(t)+F×G×Levy(Dim)×(Zrest(t)−Zi(t))
其中
G=2×(1−tTmax) G = 2 \times \left( 1 - \frac{t}{T_{max}} \right) G=2×(1−Tmaxt)
其中 GGG 是鼹鼠的逃避系数,表示其逃避能力,随着迭代次数的增加而降低,参见公式 (15)。TmaxT_{max}Tmax 表示最大迭代次数。Levy(⋅)Levy(\cdot)Levy(⋅) 是莱维飞行函数,用于模拟鼹鼠在逃避过程中的欺骗性机动。莱维飞行函数表示如下:
Levy(x)=0.01×u×σ∣x∣1β,σ=(Γ(1+β)×sin(πβ2)Γ(1+β2)×β×2β−12)1β Levy(x) = 0.01 \times \frac{u \times \sigma}{|x|^{\frac{1}{\beta}}}, \sigma = \left( \frac{\Gamma \left( 1 + \beta \right) \times \sin \left( \frac{\pi \beta}{2} \right)}{\Gamma \left( \frac{1+\beta}{2} \right) \times \beta \times 2^{\frac{\beta-1}{2}}} \right)^{\frac{1}{\beta}} Levy(x)=0.01×∣x∣β1u×σ,σ= Γ(21+β)×β×22β−1Γ(1+β)×sin(2πβ) β1
其中 uuu 和 vvv 是区间 [0-1] 中的随机值,β\betaβ 是常数,取值为 1.5。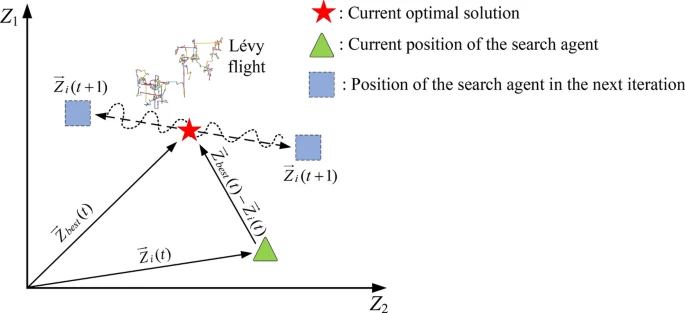
图 7 展示了二维中捕食者规避模型的示意图
2.2.6 从探索到开发的过渡
在 ALA 中,四种搜索策略与鼹鼠自身的能量水平密切相关。在初始阶段,鼹鼠主要参与探索过程以定位有前景的区域,而在搜索的后期阶段,它们倾向于实施局部开发以获得更优越的全局最优解。为了在探索和开发之间保持最佳平衡,设计了一个能量因子,随着迭代次数的增加而减少。当鼹鼠有足够的能量时,它们选择性地迁移或挖洞;否则,它们觅食和逃避捕食者。能量因子的计算公式如下:
E(t)=4×arctan[1−tTmax]×ln(1rand) E(t) = 4 \times \arctan \left[ 1 - \frac{t}{T_{max}} \right] \times \ln \left( \frac{1}{rand} \right) E(t)=4×arctan[1−Tmaxt]×ln(rand1)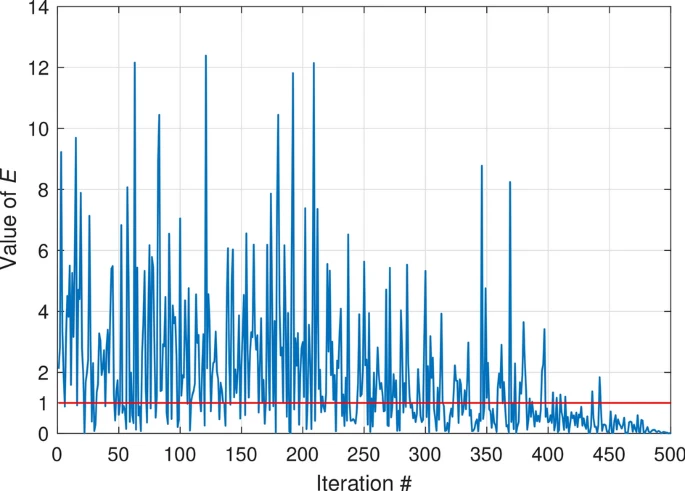
图 8 展示了 500 次迭代中 EEE 的变化曲线。可以看出,随着迭代次数的增加,EEE 逐渐减少到 0 并出现波动。我们将阈值设为 1,因此鼹鼠在迭代过程中几乎有相同的机会进行探索和开发。设:
δ=(1−tTmax) \delta = \left( 1 - \frac{t}{T_{max}} \right) δ=(1−Tmaxt)
然后
E(t)=4×arctanδ×ln(1rand) E(t) = 4 \times \arctan \delta \times \ln \left( \frac{1}{rand} \right) E(t)=4×arctanδ×ln(rand1)
E(t)>1E(t) > 1E(t)>1 的概率通过公式 (20) 计算:
P(E(t)>1)=∫01∫011−δ14π21cos2(14ρ)dρdδ⇒y=14arctanδ,∫−∞−1δeu14ρ2cos2(14ρ)dy≈0.5060 P(E(t) > 1) = \int_0^1 \int_0^{\frac{1}{1-\delta}} \frac{1}{4\pi^2} \frac{1}{\cos^2 \left( \frac{1}{4\rho} \right)} d\rho d\delta \Rightarrow y = \frac{1}{4\arctan \delta}, \int_{-\infty}^{-\frac{1}{\delta}} e^u \frac{1}{4\rho^2 \cos^2 \left( \frac{1}{4\rho} \right)} dy \approx 0.5060 P(E(t)>1)=∫01∫01−δ14π21cos2(4ρ1)1dρdδ⇒y=4arctanδ1,∫−∞−δ1eu4ρ2cos2(4ρ1)1dy≈0.5060
因此,E>1E > 1E>1 的概率约为 0.5,这有助于优化器从探索平稳过渡到开发。
参考文献
[1] Xiao Y, Cui H, Khurma R A, et al. Artificial lemming algorithm: a novel bionic meta-heuristic technique for solving real-world engineering optimization problems[J]. Artificial Intelligence Review, 2025, 58(3): 84. https://doi.org/10.1007/s10462-024-11023-7
完整代码
https://github.com/suthels/-/edit/main/README.md

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)