【Datawhale】大模型基础与量化微调-t2
GPT-2 有 15 亿参数,比原 GPT 大了 10 多倍,在受测的 8 个语言模型数据集上拿了 7 个 SOTA,采用 **零尝试迁移配置(zero-shot transfer setting)**不需要任何任务微调。175B的参数将GPT3展示出强大的上下文学习能力(In-context Learning),即在推理阶段,不需要更新模型权重,仅凭输入提示中给出的少量示例,就能理解并完成任务。
BERT 学习笔记:从缺点到改进的逻辑演进
BERT(Bidirectional Encoder Representations from Transformers)是自然语言处理(NLP)领域的一个里程碑模型,由 Google 于 2018 年提出。它基于 Transformer 编码器,通过双向上下文学习来生成词向量表示。
BERT 的核心机制
BERT 的模型架构为多层双向 Transformer 编码器。
BERT 的架构是多层 Transformer 编码器堆叠而成,输入序列为 token embeddings、segment embeddings 和 position embeddings 的求和:
E = E token + E segment + E position \mathbf{E} = \mathbf{E}_{\text{token}} + \mathbf{E}_{\text{segment}} + \mathbf{E}_{\text{position}} E=Etoken+Esegment+Eposition
其中,position embeddings 使用正弦函数编码绝对位置信息:
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d model ) , P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d model ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right), \quad PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos),PE(pos,2i+1)=cos(100002i/dmodelpos)
位置编码的旋转不变性
位置编码的设计确保了相对位置的平移不变性。考虑两个位置 p o s pos pos 和 p o s + k pos + k pos+k,它们的编码差可以通过旋转矩阵表示。令 P E p o s = [ sin ( ω i p o s ) , cos ( ω i p o s ) ] T \mathbf{PE}_{pos} = [\sin(\omega_i pos), \cos(\omega_i pos)]^T PEpos=[sin(ωipos),cos(ωipos)]T(简化到二维),则:
P E p o s + k = ( cos ( ω i k ) − sin ( ω i k ) sin ( ω i k ) cos ( ω i k ) ) P E p o s \mathbf{PE}_{pos + k} = \begin{pmatrix} \cos(\omega_i k) & -\sin(\omega_i k) \\ \sin(\omega_i k) & \cos(\omega_i k) \end{pmatrix} \mathbf{PE}_{pos} PEpos+k=(cos(ωik)sin(ωik)−sin(ωik)cos(ωik))PEpos
这推导自三角恒等式: sin ( a + b ) = sin a cos b + cos a sin b \sin(a + b) = \sin a \cos b + \cos a \sin b sin(a+b)=sinacosb+cosasinb 等。通过矩阵乘法,位置编码捕捉相对距离,而非绝对值,这有助于注意力机制处理序列依赖。
核心Self-Attention:
Attention ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = softmax\left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k}}\right) \mathbf{V} Attention(Q,K,V)=softmax(dkQKT)V
输入嵌入
输入嵌入是三部分的和:
- 字段标识嵌入(WordPiece tokenization embeddings):字段模型原本是针对日语或德语的分词问题提出的。相较于使用自然分隔的英文单词,它们可以进一步分成更小的子词单元便于处理罕见词或未知词。感兴趣的话可以看看分词优化方式的论文[论文1][13][论文2][14]。
- 片段嵌入(segment embedding):如果输入有两句话,分别有句子 A 和句子 B 的嵌入向量,并用特殊标识
[SEP]隔开;如果输入只有一句话就只用句子 A 的嵌入向量 - 位置嵌入(position embeddings):位置 embedding 需要学习而非硬编码
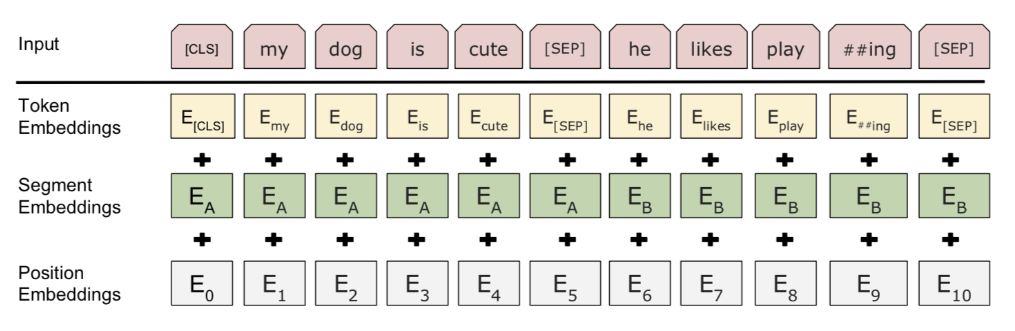
BERT 输入表示
注意第一个标识必须是 [CLS]——之后下游任务预测中会用到的占位符。
BERT 的预训练采用两个任务:
- Masked Language Model (MLM):随机掩码 15% 的 token(80% 替换为 [MASK],10% 随机替换,10% 保持原样),预测掩码 token。损失函数为交叉熵:
L MLM = − ∑ i ∈ masked log P ( w i ∣ C ) \mathcal{L}_{\text{MLM}} = -\sum_{i \in \text{masked}} \log P(w_i | \mathbf{C}) LMLM=−i∈masked∑logP(wi∣C)
MLM 交叉熵损失的梯度推导
假设输出 logits 为 o i \mathbf{o}_i oi,真实标签为 one-hot y i \mathbf{y}_i yi,则 P ( w i ) = s o f t m a x ( o i ) P(w_i) = softmax(\mathbf{o}_i) P(wi)=softmax(oi)。损失对 logits 的梯度: ∂ L ∂ o i = P ( w i ) − y i \frac{\partial \mathcal{L}}{\partial \mathbf{o}_i} = P(w_i) - \mathbf{y}_i ∂oi∂L=P(wi)−yi。
推导: ∂ ∂ o i k ( − log P i j ) = ∂ ∂ o i k ( o i j − log ∑ m e o i m ) = δ j k − P i k \frac{\partial}{\partial o_{ik}} (-\log P_{ij}) = \frac{\partial}{\partial o_{ik}} \left( o_{ij} - \log \sum_m e^{o_{im}} \right) = \delta_{jk} - P_{ik} ∂oik∂(−logPij)=∂oik∂(oij−log∑meoim)=δjk−Pik(Kronecker delta)。这确保梯度向正确类拉近,向错误类推远,促进上下文学习。
- Next Sentence Prediction (NSP):给定两个句子对,预测是否为连续句子(50% 是,50% 随机)。使用 [CLS] token 的表示进行二分类,损失为:
L NSP = − ∑ [ y log P ( isNext ) + ( 1 − y ) log P ( notNext ) ] \mathcal{L}_{\text{NSP}} = -\sum \left[ y \log P(\text{isNext}) + (1-y) \log P(\text{notNext}) \right] LNSP=−∑[ylogP(isNext)+(1−y)logP(notNext)]
总预训练损失: L = L MLM + L NSP \mathcal{L} = \mathcal{L}_{\text{MLM}} + \mathcal{L}_{\text{NSP}} L=LMLM+LNSP。
在微调阶段,BERT 在下游任务上添加任务特定层,并使用端到端训练。
BERT 的缺点分析
BERT设计存在若干数学和工程上的局限性,这些缺点直接影响了模型的效率、泛化能力和训练效果。
-
计算资源消耗高(参数多、训练昂贵):BERT-Large 有 340M 参数,导致预训练需要大量计算资源(4 天在 16 TPU 上)。从数学角度,这源于多层 Transformer 的参数规模:每层注意力头有 O ( h ⋅ d 2 ) O(h \cdot d^2) O(h⋅d2) 参数( h h h 为头数, d d d 为维度),累积后导致内存占用大,推理时间长。梯度计算在反向传播中涉及 O ( L ⋅ d 2 ) O(L \cdot d^2) O(L⋅d2) 的复杂度( L L L 为层数),进一步放大资源需求。
-
预训练与微调不匹配(Masking 策略问题):MLM 使用静态掩码(预训练时固定 [MASK]),但微调时输入无 [MASK],导致分布偏移。数学上,这表现为预训练损失 L MLM \mathcal{L}_{\text{MLM}} LMLM 优化的是条件概率 P ( w i ∣ C , [ MASK ] ) P(w_i | \mathbf{C}, [\text{MASK}]) P(wi∣C,[MASK]),而微调时是 P ( label ∣ C ) P(\text{label} | \mathbf{C}) P(label∣C),缺少 [MASK] 的条件,造成泛化偏差。推导偏移:使用 Jensen-Shannon 散度(JS)量化, J S ( P ∣ ∣ Q ) = 1 2 K L ( P ∣ ∣ M ) + 1 2 K L ( Q ∣ ∣ M ) JS(P || Q) = \frac{1}{2} KL(P || M) + \frac{1}{2} KL(Q || M) JS(P∣∣Q)=21KL(P∣∣M)+21KL(Q∣∣M)(M 为平均分布),其中 P 为预训练分布,Q 为微调分布,导致泛化误差增大。
-
NSP 任务效率低下:NSP 的二分类损失 L NSP \mathcal{L}_{\text{NSP}} LNSP 被证明对句子级理解贡献有限,因为随机负样本太简单,无法捕捉复杂语义。实验显示,移除 NSP 后性能不降反升,表明该损失项的梯度贡献弱( ∇ L NSP \nabla \mathcal{L}_{\text{NSP}} ∇LNSP 对整体参数更新影响小)。推导:NSP 梯度 ∂ L NSP ∂ h C L S = ( P − y ) W T \frac{\partial \mathcal{L}_{\text{NSP}}}{\partial \mathbf{h}_{CLS}} = (P - y) \mathbf{W}^T ∂hCLS∂LNSP=(P−y)WT( h C L S \mathbf{h}_{CLS} hCLS 为 [CLS] 表示),但由于负样本简单,P 接近 0/1,梯度范数小,导致更新缓慢。
-
位置编码的局限性:绝对位置编码 P E PE PE 无法处理超长序列,且在序列长度变化时泛化差。数学上, sin / cos \sin/\cos sin/cos 函数假设位置是周期性的,但实际 NLP 任务中位置关系更复杂,导致在长序列上的注意力分数 $ softmax(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k}})$ 可能偏倚。推导偏倚:对于长序列,远距离位置的 ω i p o s \omega_i pos ωipos 可能导致振荡,注意力权重分布不均,方差 Var [ Q K T ] \text{Var}[\mathbf{Q}\mathbf{K}^T] Var[QKT] 随 pos 增长。
-
知识压缩不足:BERT 未使用知识蒸馏等技术,模型参数冗余高,导致部署在边缘设备上困难。从信息论角度,模型的熵(entropy)较高,未有效压缩表示空间。推导:互信息$ I(X;Y) = H(X) - H(X|Y)$,BERT 的 H ( X ∣ Y ) H(X|Y) H(X∣Y) 高,表示冗余。
这些缺点在数学上可以统一视为优化问题:预训练损失 L \mathcal{L} L 未充分捕捉下游任务的分布,且参数效率低(参数量与性能不成正比)。
后续的改进
后续模型如 RoBERTa、ALBERT 和 DistilBERT 等,直接针对 BERT 的缺点进行改进。这些改进通过调整损失函数、架构和训练策略来提升效率和性能,数学上体现了从静态到动态、从冗余到精简的逻辑演进。我会添加更多推导示例,如参数共享的复杂度降低和蒸馏的 KL 最小化。
-
针对计算资源高和参数冗余:ALBERT 的参数共享与嵌入分解
ALBERT(A Lite BERT)引入跨层参数共享(所有层共享相同参数)和嵌入分解(将词嵌入维度从 d model d_{\text{model}} dmodel 降到更小的 e e e,然后投影)。数学上,这减少了参数量:原 BERT 参数为 O ( L ⋅ d 2 ) O(L \cdot d^2) O(L⋅d2),ALBERT 降为 O ( d 2 ) O(d^2) O(d2)(独立于 L L L)。嵌入分解使用低秩矩阵: E = E low W P \mathbf{E} = \mathbf{E}_{\text{low}} \mathbf{W}^P E=ElowWP,其中 E low ∈ R V × e \mathbf{E}_{\text{low}} \in \mathbb{R}^{V \times e} Elow∈RV×e, e ≪ d e \ll d e≪d。参数共享的梯度聚合
共享参数 θ \theta θ 在多层中的梯度为 ∇ L = ∑ l = 1 L ∇ l L \nabla \mathcal{L} = \sum_{l=1}^L \nabla_l \mathcal{L} ∇L=∑l=1L∇lL,这相当于平均梯度,减少噪声(方差 Var [ ∇ ] = 1 L Var [ ∇ l ] \text{Var}[\nabla] = \frac{1}{L} \text{Var}[\nabla_l] Var[∇]=L1Var[∇l])。结果:参数从 110M 降到 12M,同时性能提升(GLUE 分数更高)。这解决了资源消耗问题,通过最小化参数规范(parameter norm)来正则化模型。 -
针对预训练与微调不匹配:RoBERTa 的动态 Masking 和更大规模训练
RoBERTa(Robustly Optimized BERT)移除 NSP(直接 L = L MLM \mathcal{L} = \mathcal{L}_{\text{MLM}} L=LMLM),并采用动态掩码(每个 epoch 随机重新掩码),使预训练更接近微调分布。数学上,动态掩码增加样本多样性,提升条件概率估计的鲁棒性: P ( w i ∣ C ) P(w_i | \mathbf{C}) P(wi∣C) 的方差减小。同时,使用更大数据集(160GB vs. BERT 的 16GB)和更长序列,优化 Adam 优化器超参(更大 batch size、学习率)。
5:动态掩码的方差减小
静态掩码下,样本协方差 Cov ( w i , w j ) \text{Cov}(w_i, w_j) Cov(wi,wj) 固定,导致过拟合。动态下,每个 epoch 的掩码服从 Bernoulli(0.15),有效样本数增加,似然估计的渐近方差 Var [ P ^ ] ≈ P ( 1 − P ) n eff \text{Var}[\hat{P}] \approx \frac{P(1-P)}{n_{\text{eff}}} Var[P^]≈neffP(1−P)( n eff n_{\text{eff}} neff 增大)。结果:MLM 损失收敛更快,下游任务性能提升 2-5%。这从分布匹配角度改进,减少了 Kullback-Leibler 散度(KL-divergence)之间的预训练-微调差距: min K L ( P pre ∣ ∣ P fine ) = E P pre [ log P pre P fine ] \min KL(P_{\text{pre}} || P_{\text{fine}}) = \mathbb{E}_{P_{\text{pre}}} [\log \frac{P_{\text{pre}}}{P_{\text{fine}}}] minKL(Ppre∣∣Pfine)=EPpre[logPfinePpre]。 -
针对 NSP 效率低下:Electra 的 Replaced Token Detection (RTD)
Electra 替换 NSP 为 RTD:用生成器掩码并替换 token,判别器预测哪些是替换的。损失为:
L RTD = − ∑ i [ y i log P ( original i ) + ( 1 − y i ) log P ( replaced i ) ] \mathcal{L}_{\text{RTD}} = -\sum_i \left[ y_i \log P(\text{original}_i) + (1-y_i) \log P(\text{replaced}_i) \right] LRTD=−i∑[yilogP(originali)+(1−yi)logP(replacedi)]
这比 MLM 更高效,因为所有 token 都参与优化(而非仅 15%),梯度 ∇ L RTD \nabla \mathcal{L}_{\text{RTD}} ∇LRTD 覆盖全序列。
6:RTD 的信息增益
RTD 等价于二元分类,信息增益 IG = H(Y) - H(Y|X) > MLM 的(MLM 只掩码部分,H(Y|X) 较高)。梯度推导类似 NSP,但覆盖率高: ∂ L RTD ∂ h i = ( P i − y i ) W T \frac{\partial \mathcal{L}_{\text{RTD}}}{\partial \mathbf{h}_i} = (P_i - y_i) \mathbf{W}^T ∂hi∂LRTD=(Pi−yi)WT 对所有 i。数学上,RTD 类似于对抗训练(adversarial training),提升表示的判别能力,性能媲美更大模型但计算量减半。
-
针对位置编码局限:相对位置编码的引入(e.g., DeBERTa)
DeBERTa 使用相对位置偏置(disentangled attention):注意力分数为 Q i ( K j + R i − j ) T d k \frac{\mathbf{Q}_i (\mathbf{K}_j + \mathbf{R}_{i-j})^T}{\sqrt{d_k}} dkQi(Kj+Ri−j)T,其中 R i − j \mathbf{R}_{i-j} Ri−j 是相对位置嵌入。
7:相对位置的注意力稳定性
绝对位置下, Q i K j T \mathbf{Q}_i \mathbf{K}_j^T QiKjT 随 |i-j| 振荡;相对下,添加 Q i R i − j T + K j R j − i T \mathbf{Q}_i \mathbf{R}_{i-j}^T + \mathbf{K}_j \mathbf{R}_{j-i}^T QiRi−jT+KjRj−iT(DeBERTa 扩展),方差稳定: Var [ s c o r e ] = d k + 2 Var [ R ] \text{Var}[score] = d_k + 2 \text{Var}[\mathbf{R}] Var[score]=dk+2Var[R],独立于绝对 pos。这比绝对 P E PE PE 更灵活,处理长序列时注意力矩阵更稳定,减少位置偏差导致的 softmax 饱和问题。 -
针对知识压缩不足:DistilBERT 的知识蒸馏
DistilBERT 通过蒸馏(knowledge distillation)从 BERT 教师模型中学习学生模型。损失包括 softmax 分布匹配:
L distil = α L MLM + β KL ( P teacher ∣ ∣ P student ) + γ ∥ H teacher − H student ∥ 2 \mathcal{L}_{\text{distil}} = \alpha \mathcal{L}_{\text{MLM}} + \beta \text{KL}(P_{\text{teacher}} || P_{\text{student}}) + \gamma \|\mathbf{H}_{\text{teacher}} - \mathbf{H}_{\text{student}}\|^2 Ldistil=αLMLM+βKL(Pteacher∣∣Pstudent)+γ∥Hteacher−Hstudent∥2
KL 散度的梯度最小化
KL = ∑ P t log P t P s \sum P_t \log \frac{P_t}{P_s} ∑PtlogPsPt,梯度对学生 logits: ∂ KL ∂ o s = 1 τ ( P s − P t ) \frac{\partial \text{KL}}{\partial \mathbf{o}_s} = \frac{1}{\tau} (P_s - P_t) ∂os∂KL=τ1(Ps−Pt)(温度 τ \tau τ 软化)。这拉近分布,结合 L2 项正则化隐藏层。参数减半(66M),速度提升 40%,保留 97% 性能。这数学上通过最小化教师-学生表示的 L2 范数和 KL 散度,实现高效压缩。
GPT
GPT-2
GPT-2 有 15 亿参数,比原 GPT 大了 10 多倍,在受测的 8 个语言模型数据集上拿了 7 个 SOTA,采用 **零尝试迁移配置(zero-shot transfer setting)**不需要任何任务微调。
预训练数据集包括 80 亿 Web 页面,页面是从 Reddit上爬下来的合格外链。在小数据集和评估**长程依赖(long-term dependency)**的数据集上 GPT-2 进步明显。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传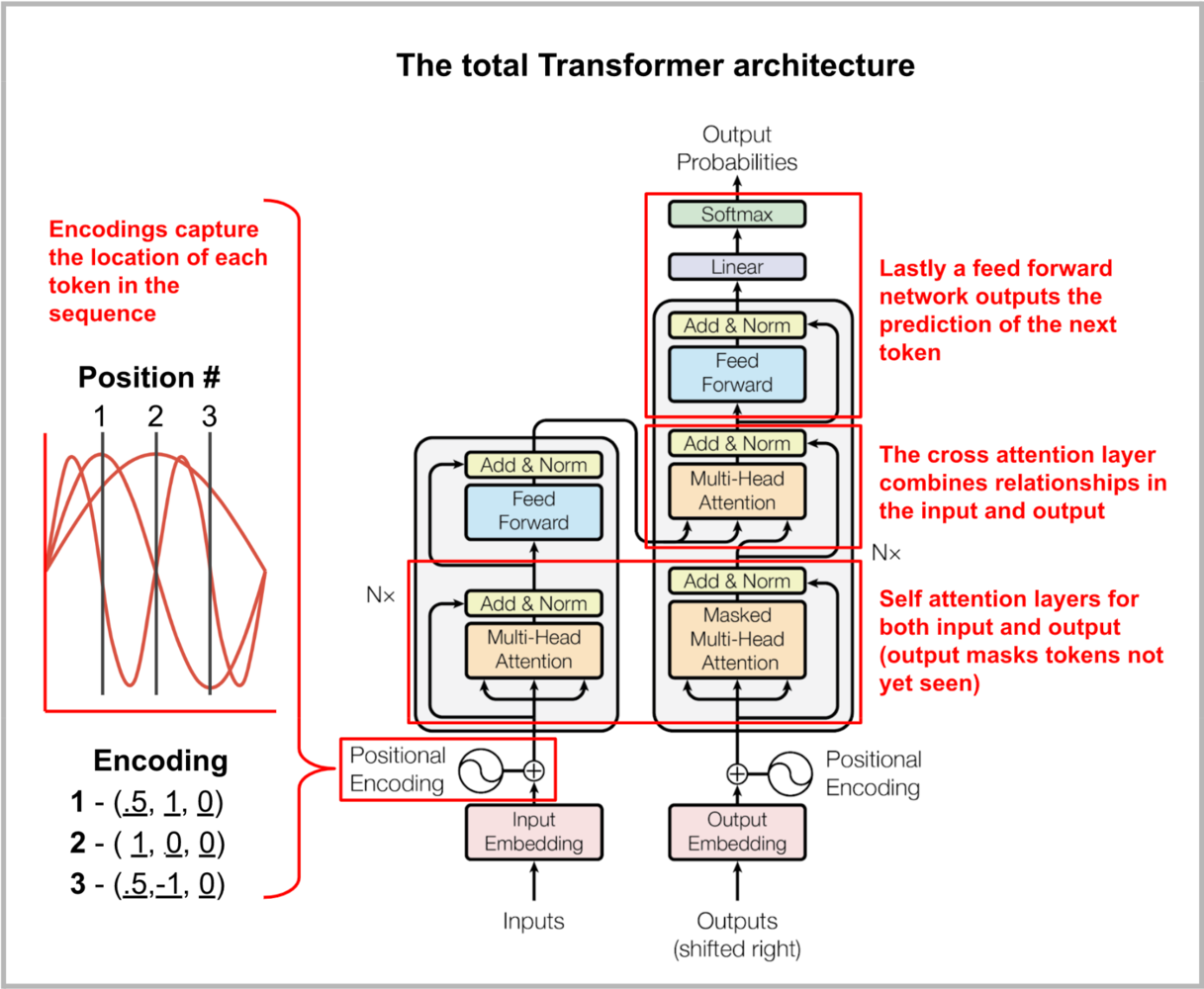
零尝试迁移
GPT-2 的预训练就纯是语言建模。所有下游语言任务都被规制成对条件概率的预测,不存在对任务的微调。
-
文本生成就是直接用 LM
-
机器翻译任务,比如英语到汉语,通过 LM 条件化完成。末端加上“英文=中文”和“待翻英文=”两部分
-
- 要预测的条件概率可能像这样:
P(?| I like green apples. = 我喜欢绿苹果。A cat meows at him. = 一只猫对他喵喵叫。It is raining cats and dogs. =)
- 要预测的条件概率可能像这样:
-
QA 任务也转成是和翻译类似的形式,给上下文里加上成对的问答
-
摘要任务是在上下文中给文章末尾加上
TL;DR:
字节序列 BPE
和原 GPT 一样,GPT-2 也对 UTF-8 字节序列采用了 BPE。每个字节可以用 8 比特表示 256 种不同的含义,UTF-8 最多可以使用 4 字节来表示一个字符,最高支持 2 31 2^{31} 231种字符。所以用字节序列表示,我们只需要一个大小为 256 的词汇表,而不需要操心预训练、标识化等内容。尽管有这些好处,当前字节级 LM 仍与 SOTA 字词级 LM 间有着不可忽视的性能差距。
BPE 不断贪婪地合并共现字节对,为防止常用词出现多个版本表示(由 dog 到dog.,dog!,dog?)GPT-2 不许 BPE 跨类别合并字符(dog 不会与 .,!,?这些标点合并)。这一技巧有效增加了最终字节段的质量。
通过字节序列表示,GPT-2 可以对任意 Unicode 字符串给出一个概率,而不需要任何预训练步骤。
模型改进
相较于 GPT,除了更多的 transformer 层和参数,GPT-2 只做了很少的架构调整:
- 层归一化(layer-normalization)移到子块输入上
- 在最后的自注意块之后加了个层归一化
- 改良初始化,使其成为模型深度的一个函数
- 残差层的权重一开始要缩小至 1 N \frac 1{\sqrt N} N1, N N N是残差层数量
- 用更大的词汇表和上下文
GPT-3
核心:上下文学习,大规模Transformer的堆叠,更大的上下文窗口(2048),注意力复杂度 O ( n 2 d ) O(n^2d) O(n2d)虽高,通过稀疏优化缓解
175B的参数将GPT3展示出强大的上下文学习能力(In-context Learning),即在推理阶段,不需要更新模型权重,仅凭输入提示中给出的少量示例,就能理解并完成任务
- Zero-shot: 仅给出任务描述。例如:“将中文翻译成英文:你好 ->”
- One-shot: 给出一个示例。例如:“将中文翻译成英文:\n苹果 -> apple\n你好 ->”
- Few-shot: 给出多个示例。这通常能显著提升模型性能,甚至达到微调模型的效果。
T5
将多任务看做“txt to text”的形式,是新的模型范式,这使得模型无需为每个任务设计独立头,只需微调提示(prompt)即可切换任务
预训练目标 Span Corruption(随机掩码连续文本片段并重建)比传统 MLM 更贴近真实生成任务,但是为了text2text使用encoder-decoder的双向的模型架构并不在推理上占优势
相对位置编码
BERT 和 GPT 的绝对位置编码,本质是给每个词打上“座位号”:第 1 个词用向量 [0.1, 0.3, …],第 2 个用 [0.2, 0.5, …]。这在短句中有效,但一旦句子变长、结构复杂,模型难以泛化“两个词相隔 100 步”和“相隔 101 步”是否本质相同。
T5 的突破在于:注意力应关心“谁离谁近”,而不是“谁在第几位”。
-
分桶机制(Bucketing):
- 距离 ≤ 8:用 16 个独立编码(-8 到 +7),精确建模邻近依赖(如“the cat sat”中“cat”和“sat”)。
- 距离 > 8:映射到对数桶中(如 9–15 → 桶1,16–31 → 桶2,32–63 → 桶3…),远距离词共享同一编码。
→ 意义:模型学会“远距离词关系相似”,避免过拟合长距离噪声,同时压缩参数。
-
Bias 加在 Q·K 上,参数跨层共享:
不像 BERT 将位置向量加到词嵌入,T5 将相对位置偏置直接注入注意力分数:
Attention ( Q , K ) = softmax ( Q K T d + B rel ) \text{Attention}(Q, K) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}} + B_{\text{rel}}\right) Attention(Q,K)=softmax(dQKT+Brel)
所有 Transformer 层使用同一组 $ B_{\text{rel}} $ 参数,而非每层独立学习。
意义:参数量减少近 30%,训练更稳定,且强制各层学习“一致的相对关系表征”。
补充:原版 T5 使用 ReLU,但 T5 v1.1 引入 GEGLU(Gated GLU):
GEGLU ( x ) = GELU ( W 1 x ) ⊗ ( W 2 x ) \text{GEGLU}(x) = \text{GELU}(W_1 x) \otimes (W_2 x) GEGLU(x)=GELU(W1x)⊗(W2x)
门控机制让模型能动态选择激活路径,显著提升语言建模效果
简化版LayerNorm
标准 LayerNorm 对每个特征维度做:
LayerNorm ( x ) = γ ⋅ x − μ σ + β \text{LayerNorm}(x) = \gamma \cdot \frac{x - \mu}{\sigma} + \beta LayerNorm(x)=γ⋅σx−μ+β
其中 β \beta β 是可学习的加性偏置
T5 直接去掉 β \beta β,只保留缩放因子 γ \gamma γ:
T5-LN ( x ) = γ ⋅ x − μ σ \text{T5-LN}(x) = \gamma \cdot \frac{x - \mu}{\sigma} T5-LN(x)=γ⋅σx−μ
-
为什么能去掉?
实验发现:在 Transformer 的残差连接和初始化良好的前提下,偏置 β \beta β 对性能贡献极小,反而增加过拟合风险。 -
收益:
- 每层减少约 1% 参数(对 11B 模型仍是千万级参数节省)
- 训练更稳定,梯度噪声更低
SentencePiece
BERT 使用 WordPiece,依赖预分词,英文按空格切分中文语意模糊分词困难
GPT 使用 BPE,虽能处理中文,但仍需语言特定的预处理。
T5 的 SentencePiece 直接在原始字符序列上训练,不依赖任何语言规

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)