机器学习:决策树——ID3和C4.5算法实现贷款审核实战
决策树(Decision Tree)是一种基本的分类与回归方法,在机器学习中被广泛应用,尤其适合处理结构化的、有明显规则逻辑的问题场景。它的核心思想是通过一系列“是/否”判断,不断将样本划分,直到最终落入一个明确的分类结果。比如选择好瓜的时候:我们可以认为色泽、根蒂、敲声是一个西瓜的三个特征,每次我们做出抉择都是基于这三个特征来把一个节点分成好几个新的节点。在上面的例子中,色泽、根蒂、声音特征选取
1.决策树算法简介
决策树(Decision Tree)是一种基本的分类与回归方法,在机器学习中被广泛应用,尤其适合处理结构化的、有明显规则逻辑的问题场景。它的核心思想是通过一系列“是/否”判断,不断将样本划分,直到最终落入一个明确的分类结果。
比如选择好瓜的时候:
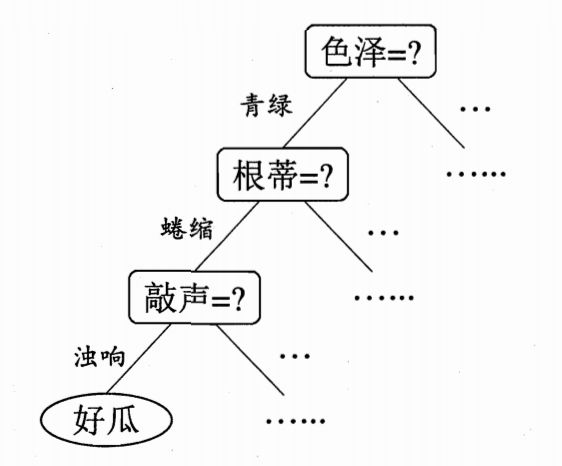
我们可以认为色泽、根蒂、敲声是一个西瓜的三个特征,每次我们做出抉择都是基于这三个特征来把一个节点分成好几个新的节点。
在上面的例子中,色泽、根蒂、声音特征选取完成后,开始进行决策,在我们的问题中,决策的内容实际上是将结果分成两类,即是(1)否(0)好瓜。
2.决策树原理
2.1 引例
顾名思义,决策树是一种树状结构的模型,其中:
- 根节点就是树最顶端的节点,比如上面图中的“色泽”。
- 每个内部节点表示对一个特征的判断;
- 每个分支代表一种判断结果(例如“触感”是"硬滑"或"软黏");
- 每个叶节点对应一个最终的类别标签(如“好瓜”或“坏瓜”)。
就像做选择题一样,决策树不断地根据条件排除、细分,直到锁定答案。
举个"栗子"
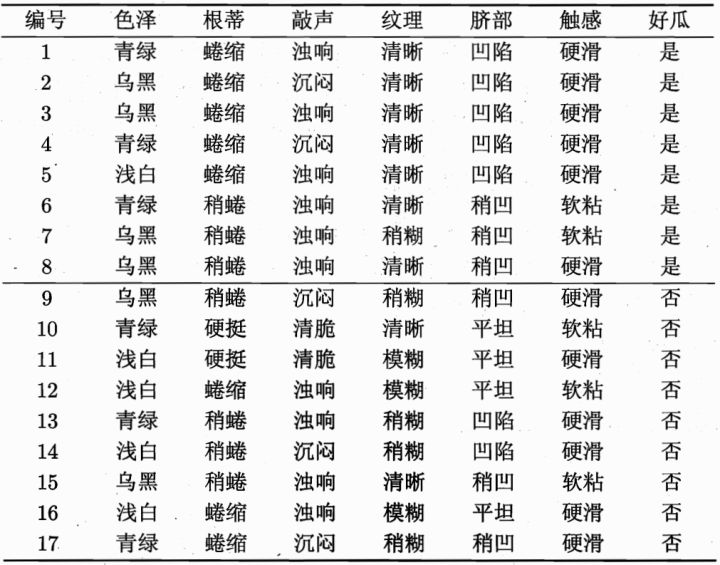
构造决策树如下:
3. 熵和信息熵的相关概念
决策树的构建首先从根节点开始,选择最优的特征进行分类。熵和信息熵的概念起到了至关重要的作用。它们帮助我们度量数据的混乱程度或不确定性,从而指导我们如何选择最优的划分属性。
3.1 信息熵
信息熵是对数据集中不确定性或混乱程度的度量。在一个数据集中,如果各类别的样本数量大致相等,那么该数据集的熵值较高,表示不确定性较大;反之,如果某个类别的样本数量占据绝对优势,那么熵值较低,表示不确定性较小。因此,信息熵可以用来评估数据集的纯度。
设X是一个有限值的离散随机变量,其概率分布为:
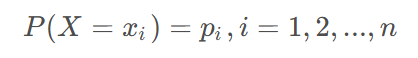
假设变量x的随机取值为X={x1,x2,…,xn},每一种取值的概率分布分别是{p1,p2…,pi},则变量X的熵为: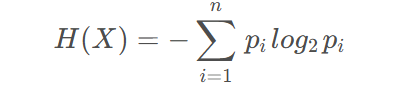
如判断"西瓜是好瓜还是坏瓜"这个例子
- 第一层
根节点:被分成17份,8是/9否,总体的信息熵为: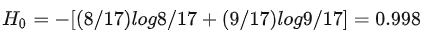
- 第二层
清晰:被分成9份,7是/2否,它的信息熵为: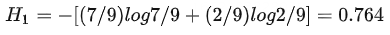
稍糊:被分成5份,1是/4否,它的信息熵为: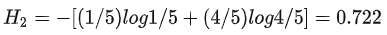
模糊:被分成3份,0是/3否,它的信息熵为: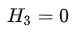
我们规定,假设我们选取纹理为分类依据,把它作为根节点,那么第二层的加权信息熵可以定义为: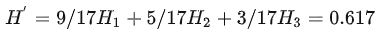
我们规定,H’< H0,也就是随着决策的进行,其不确定度要减小才行,决策肯定是一个由不确定到确定状态的转变。
因此,决策树采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为0,此时每个叶子节点中的实例都属于同一类。
3.2 条件熵
条件熵是在给定某个随机变量取值的情况下,另一个随机变量的不确定性度量。在决策树中,条件熵用于评估在给定某个特征条件下数据集的纯度。通过比较划分前后数据集的条件熵变化,我们可以选择出能够最大程度降低不确定性的划分属性。
条件熵(Conditional Entropy)表示在已知某一随机变量Y的条件下,另一随机变量X的不确定性。其公式为: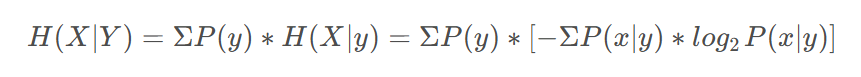
其中,P(y)表示随机变量Y取值为y的概率,P (x∣y)表示在Y取值为y的条件下,X取值为x的条件概率。
4.生成算法
决策树的构建首先从根节点开始,选择最优的特征进行分类。“最优“是通过评价指标来决定的:信息增益(ID3算法)、信息增益率(C4.5算法)和基尼指数(CATR算法)。
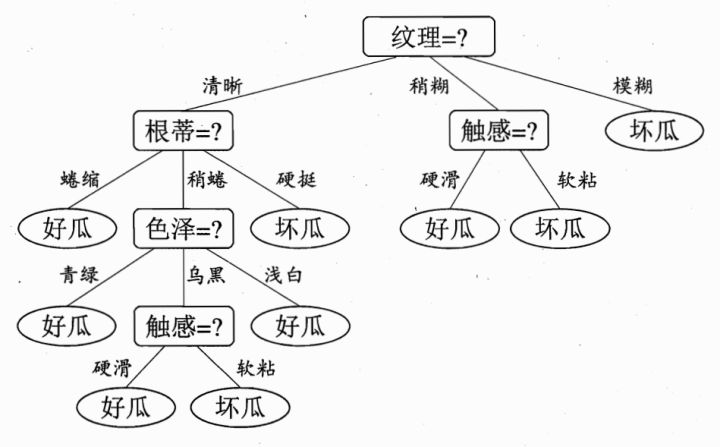
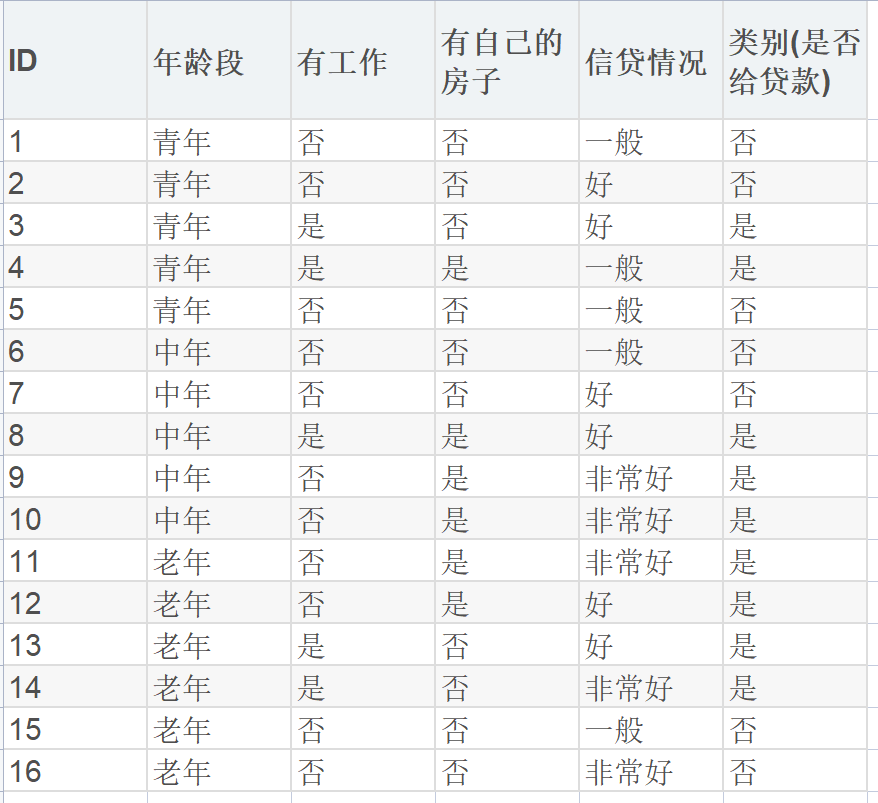
下面将使用贷款申请样本的数据表来进行算法实现,数据示例如下:
其中,对数据集进行属性标注:
年龄:{“青年”:0, “中年”:1, “老年”:2}
有工作: {“否”:0, “是”:1}
有自己的房子: {“否”:0, “是”:1}
信贷情况: {“一般”:0, “好”:1, “非常好”:2}
类别(是否给贷款): {“否”:0, “是”:1}
# 读取数据文件
def load_data(filename):
with open(filename, 'r') as file:
data = [line.strip().split(',') for line in file.readlines()]
for row in data:
for i in range(len(row)-1):
row[i] = int(row[i])
return data
4.1 信息增益(ID3算法)
从信息论的知识中我们知道:信息熵越大,样本的纯度越低。ID3 算法的核心思想就是以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。
信息增益 = 信息熵 - 条件熵: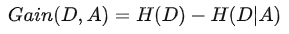
也可以表示为H0 - H1,比如上面实例中选择纹理作为根节点,将根节点一分为三,则: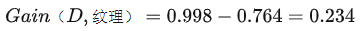
意思是,没有选择纹理特征前,是否是好瓜的信息熵为0.998,在我选择了纹理这一特征之后,信息熵下降为0.764,信息熵下降了0.234,也就是信息增益为0.234。
4.1.1计算经验熵(香农熵)
def calcShannonEnt(dataSet):
# 统计数据数量
numEntries = len(dataSet)
# 存储每个label出现次数
label_counts = {}
# 统计label出现次数
for featVec in dataSet:
current_label = featVec[-1]
if current_label not in label_counts: # 提取label信息
label_counts[current_label] = 0 # 如果label未在dict中则加入
label_counts[current_label] += 1 # label计数
shannon_ent = 0 # 经验熵
# 计算经验熵
for key in label_counts:
prob = float(label_counts[key]) / numEntries
shannon_ent -= prob * log(prob, 2)
return shannon_ent
4.1.2 计算信息增益
def splitDataSet(data_set, axis, value):
ret_dataset = []
for feat_vec in data_set:
if feat_vec[axis] == value:
reduced_feat_vec = feat_vec[:axis]
reduced_feat_vec.extend(feat_vec[axis + 1:])
ret_dataset.append(reduced_feat_vec)
return ret_dataset
def chooseBestFeatureToSplit(dataSet):
# 特征数量
num_features = len(dataSet[0]) - 1
# 计算数据香农熵
base_entropy = calcShannonEnt(dataSet)
# 信息增益
best_info_gain = 0.0
# 最优特征索引值
best_feature = -1
# 遍历所有特征
for i in range(num_features):
# 获取dataset第i个特征
feat_list = [exampel[i] for exampel in dataSet]
# 创建set集合,元素不可重合
unique_val = set(feat_list)
# 经验条件熵
new_entropy = 0.0
# 计算信息增益
for value in unique_val:
# sub_dataset划分后的子集
sub_dataset = splitDataSet(dataSet, i, value)
# 计算子集的概率
prob = len(sub_dataset) / float(len(dataSet))
# 计算经验条件熵
new_entropy += prob * calcShannonEnt(sub_dataset)
# 信息增益
info_gain = base_entropy - new_entropy
# 打印每个特征的信息增益
print("第%d个特征的信息增益为%.3f" % (i, info_gain))
# 计算信息增益
if info_gain > best_info_gain:
# 更新信息增益
best_info_gain = info_gain
# 记录信息增益最大的特征的索引值
best_feature = i
print("最优索引值:" + str(best_feature))
print()
return best_feature
4.1.3 树的生成
ID3算法通过递归地选择信息增益最大的属性进行划分来生成决策树。具体步骤如下:
- 步骤1:从根节点开始,计算所有属性的信息增益。
- 步骤1:选择信息增益最大的属性作为划分属性,根据该属性的不同取值将数据集划分为多个子集。
- 步骤3:对每个子集递归执行步骤1和步骤2,直到满足停止条件(如所有样本属于同一类别或没有属性可用)为止。
通过上述步骤,我们可以得到一个完整的决策树。
def majority_cnt(class_list):
class_count = {}
# 统计class_list中每个元素出现的次数
for vote in class_list:
if vote not in class_count:
class_count[vote] = 0
class_count[vote] += 1
# 根据字典的值降序排列
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
def creat_tree(dataSet, labels, featLabels):
# 取分类标签(是否放贷:yes or no)
class_list = [exampel[-1] for exampel in dataSet]
# 如果类别完全相同则停止分类
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
# 遍历完所有特征时返回出现次数最多的类标签
if len(dataSet[0]) == 1:
return majority_cnt(class_list)
# 选择最优特征
best_feature = chooseBestFeatureToSplit(dataSet)
# 最优特征的标签
best_feature_label = labels[best_feature]
featLabels.append(best_feature_label)
# 根据最优特征的标签生成树
my_tree = {best_feature_label: {}}
# 删除已使用标签
del(labels[best_feature])
# 得到训练集中所有最优特征的属性值
feat_value = [exampel[best_feature] for exampel in dataSet]
# 去掉重复属性值
unique_vls = set(feat_value)
for value in unique_vls:
my_tree[best_feature_label][value] = creat_tree(splitDataSet(dataSet, best_feature, value), labels, featLabels)
return my_tree
4.1.3 未知数据的预测
对于未知数据,我们可以根据生成的决策树进行预测。从根节点开始,根据未知数据的属性值沿着树结构进行条件判断,最终到达叶节点得到预测结果。
def classify(input_tree, feat_labels, test_vec):
first_str = next(iter(input_tree))
second_dict = input_tree[first_str]
feat_index = feat_labels.index(first_str)
for key in second_dict.keys():
if test_vec[feat_index] == key:
if type(second_dict[key]).__name__ == 'dict':
return classify(second_dict[key], feat_labels, test_vec)
else:
return second_dict[key]
return '未知'
4.1.4 主函数调用
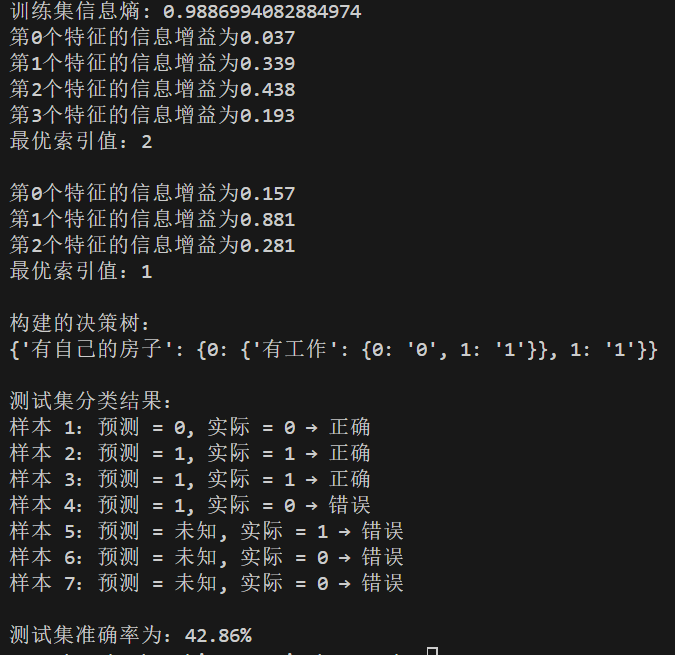
if __name__ == "__main__":
# 读取训练集和测试集
dataset = load_data('dataset.txt')
testset = load_data('testset.txt')
original_labels = ['年龄', '有工作', '有自己的房子', '信贷情况']
print(calcShannonEnt(dataset))
labels = original_labels[:]
featLabels = []
# 构建决策树
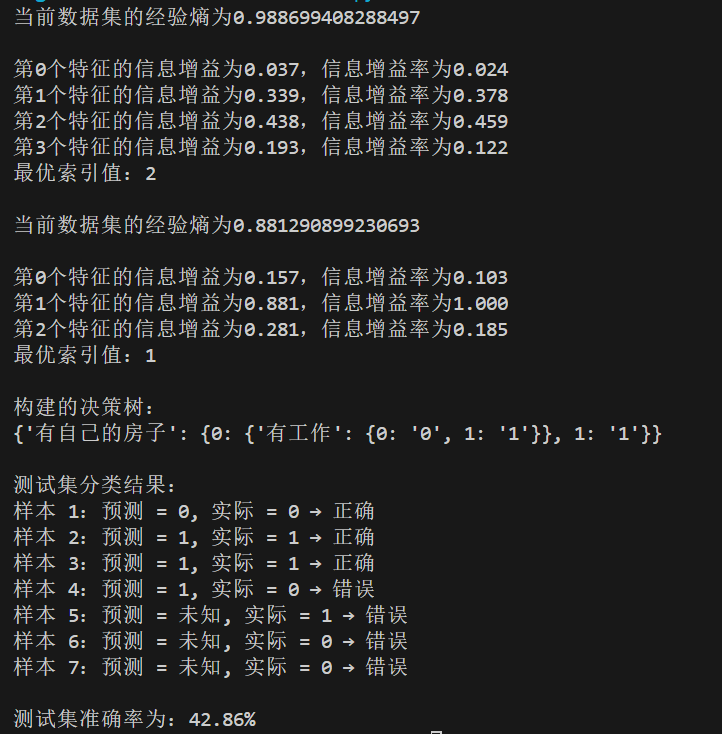
myTree = creat_tree(dataset, labels, featLabels)
print("构建的决策树:")
print(myTree)
# 遍历测试集预测结果
correct = 0
total = len(testset)
print("\n测试集分类结果:")
for idx, row in enumerate(testset):
features = row[:-1]
actual = row[-1]
predicted = classify(myTree, featLabels, features)
result = "正确" if predicted == actual else "错误"
if predicted == actual:
correct += 1
print(f"样本 {idx+1}:预测 = {predicted}, 实际 = {actual} → {result}")
# 准确率
accuracy = correct / total
print("\n测试集准确率为:{:.2%}".format(accuracy))
4.1.5 运行结果
4.2 信息增益率(C4.5算法)
C4.5算法最大的特点是克服了ID3对特征数目的偏重这一缺点,引入信息增益率来作为分类标准。
信息增益率=信息增益/特征本身的熵: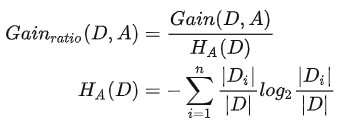
信息增益率对可取值较少的特征有所偏好(分母越小,整体越大),因此C4.5并不是直接用增益率最大的特征进行划分,而是使用一个启发式方法:先从候选划分特征中找到信息增益高于平均值的特征,再从中选择增益率最高的。
例如上述的例子,我们考虑纹理本身的熵,也就是是否是好瓜的熵。
纹理本身有三种可能,每种概率都已知,则纹理的熵为: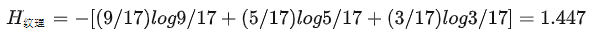
那么选择纹理作为分类依据时,信息增益率为: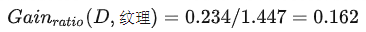
4.2.1 计算信息增益率
ID3算法与 C4.5 算法,主要的区别在于 C4.5 使用信息增益率来选择分裂特征,而 ID3 使用信息增益。信息增益率的计算方式是将信息增益除以分裂的熵(即每个分裂的熵比,反映了每个特征的分裂质量)。其他函数大致相同。
def chooseBestFeatureToSplit(dataSet):
num_features = len(dataSet[0]) - 1
base_entropy = calcShannonEnt(dataSet)
print("当前数据集的经验熵为%.15f\n" % base_entropy)
best_gain_ratio = 0.0
best_feature = -1
for i in range(num_features):
feat_list = [example[i] for example in dataSet]
unique_vals = set(feat_list)
new_entropy = 0.0
split_info = 0.0
for value in unique_vals:
sub_dataset = splitDataSet(dataSet, i, value)
prob = len(sub_dataset) / float(len(dataSet))
new_entropy += prob * calcShannonEnt(sub_dataset)
split_info -= prob * log(prob, 2) if prob != 0 else 0
info_gain = base_entropy - new_entropy
gain_ratio = info_gain / split_info if split_info != 0 else 0
print("第%d个特征的信息增益为%.3f,信息增益率为%.3f" % (i, info_gain, gain_ratio))
if gain_ratio > best_gain_ratio:
best_gain_ratio = gain_ratio
best_feature = i
print("最优索引值:" + str(best_feature) + "\n")
return best_feature
4.2.2 运行结果
5.实验总结
-
信息增益的偏向性:信息增益会偏向那些取值较多的特征,因为它们能够带来更多的分裂,导致较低的熵。因此,信息增益并不是最适合的特征选择标准,尤其是当数据中某些特征有大量取值时。
-
信息增益率的优势:信息增益率通过对信息增益进行标准化,避免了信息增益的偏向性。它更加公正地评估了特征的有效性,特别适合特征取值较多的场景。虽然信息增益率可能导致计算复杂度增加,但它在实际决策树模型中的表现更为均衡和准确。
-
实际应用中的选择:在实际应用中,C4.5算法常常使用信息增益率作为特征选择的标准,因为它有效克服了信息增益的不足,尤其是在多值特征的处理上表现出色。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)