机器学习算法竞赛实战笔记
流程为。
思维导图

竞赛平台
kaggle
天池
DataFountain
datacastle
和鲸社区
总体流程
问题建模
-
题目理解
分为三个部分,业务背景,数据理解,评价指标
业务背景包含 深入业务,明确目标
数据理解包含数据基础层,数据表示层
评价指标包括分类指标和回归指标- 分类指标
* 错误率, E ( f ; D ) = 1 m ∑ i = 1 m Π ( f ( x i ) ≠ y i ) E(f;D)=\frac{1}{m}\sum_{i=1}^m \Pi(f(x_i ) \neq y_i) E(f;D)=m1∑i=1mΠ(f(xi)=yi),更一般形式为 E ( f ; D ) = ∫ x ∽ D Π ( f ( x ) ≠ y ) p ( x ) d x E(f;D) = \int_{x\backsim D} \Pi (f(x) \neq y)p(x)dx E(f;D)=∫x∽DΠ(f(x)=y)p(x)dx
* 精度, a c c ( f ; D ) = 1 m ∑ i = 1 m Π ( f ( x i ) = y i ) = 1 − E ( f ; D ) acc(f;D)=\frac{1}{m} \sum_{i=1}^m \Pi(f(x_i) = y_i) = 1 - E(f;D) acc(f;D)=m1∑i=1mΠ(f(xi)=yi)=1−E(f;D) ,更一般形式为 a c c ( f ; D ) = ∫ x ∽ D Π ( f ( x ) = y ) p ( x ) d x = 1 − E ( f ; D ) acc(f;D) = \int_{x\backsim D} \Pi (f(x) = y)p(x)dx = 1 - E(f;D) acc(f;D)=∫x∽DΠ(f(x)=y)p(x)dx=1−E(f;D)
混淆矩阵: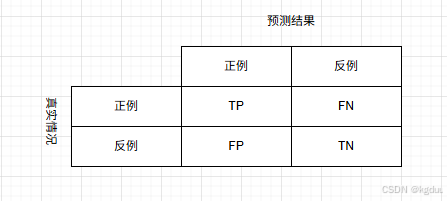
* 准确率(查准率),表示为 P = T P T P + F P P= \frac{TP}{TP+FP} P=TP+FPTP,即判定为正样本中,真正属于正样本的比率
* 召回率(查全率),表示为 R = T P T P + F N R = \frac{TP}{TP+FN} R=TP+FNTP,即真实正样本中,判断为正样本的比率
* F1-score,表示为 F 1 s c o r e = 2 ∗ P R P + R F1score = 2 * \frac{P R }{P + R} F1score=2∗P+RPR
* ROC曲线,真正例率为 T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP,假正例率为 F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP
* AUC:ROC曲线下的面积
* 对数损失:其基于最小对数似然。 ℓ ( y , y ^ ) = − l o g P ( Y ∣ X ) = − [ y ⋅ l o g p + ( 1 − y ) ⋅ l o g ( 1 − p ) ] \ell(y, \hat y) = -logP(Y|X)=-\left[y\cdot log p + (1-y) \cdot log(1-p) \right] ℓ(y,y^)=−logP(Y∣X)=−[y⋅logp+(1−y)⋅log(1−p)] - 回归指标
* 平均绝对误差,MAE,也称L1范数损失
* 均方误差,MSE,也称L2范数损失
* 均方根误差RMSE
* 平均绝对百分比误差MAPE
- 分类指标
-
样本选择
样本选择是因为以下原因- 数据集过大
- 数据噪声
- 数据冗余
- 正负样本分布不均衡
对于数据量大情况原因,可以使用以下方法
- 简单随机抽样
- 分层采样
对于正负样本分布不均衡原因,可以使用以下方法
- 评分加权处理,如Micro Fscore和Weighted Fscore
- 欠采样,如随机欠采样,Tomek Links
- 过采样,如随机过采样和SMOTE
- 线下评估策略
对于强时序,时间上最拼近测试集的数据作验证集,验证集的时间分布在训练集之后
对于弱时序,则使用K折交叉验证
数据探索
- 数据初探
思路:采用多种探索思路和方法
方法:单变量可视化分析,多变量可视化分析,降维分析
明确目的:数据基本类型,重复值、缺失值和异常值,特征之间是否冗余,是否存在时间信息,标签分布,训练集与测试集的分布,单变量/多变量分析 - 变量分析
分为单变量分析和多变量分析 - 模型分析
学习曲线:欠拟合学习曲线,过拟合学习曲线
特征重要性分析:对于 树模型计算特征的信息增益或分裂次数,对于模型LR或者SVM,使用特征系数
误差分析:回归问题看预测结果的分布,分类问题看混淆矩阵
特征工程
数据预处理
寻找异常值使用可视化方法时,可以考虑使用matplotlib的boxplot或者seaborn的boxplot
特征变换
自然数编码:LabelEncoder
独热编码:OneHotEncoder
特征提取
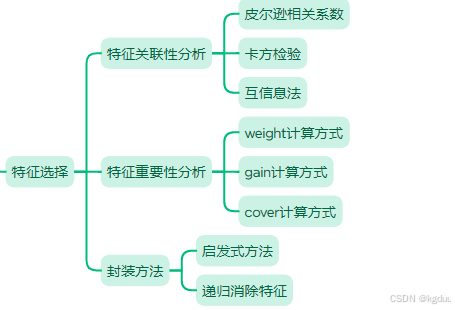
特征选择
模型训练
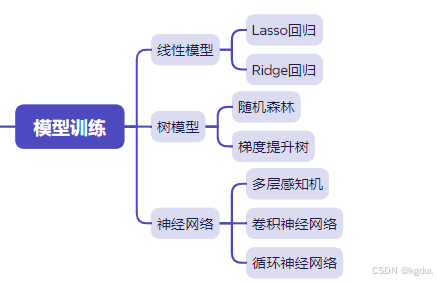
Lasso回归:也称为L1正则化
Ridge回归:也称为L2正则化
随机森林:基于决策树+bagging,是从属性集d中随机选择k个属性作为子集,然后基于k个属性子集使用决策树算法。推荐 k = l o g 2 d k=log_2 d k=log2d
梯度提升有
- LightGBM
- XGBoost
- Catboost
库
scikit-learn
lightgbm
pandas 数据分析库
matplotlib 数据可视化
seaborn 数据可视化
xgboost
问题
在使用jupyter notebook打开浏览器使用的是默认目录,如何修改?
在cmd中输入jupyter notebook --generate-config,会在用户的目录.jupyter下生成jupyter_notebook_config.py文件,修改到指定目录
c.NotebookApp.notebook_dir = '你的目录'
重启anaconda,启动jupyter notebook发现已经修改。可以使用jupyter notebook看是否修改成功

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)