vllm attention算子
在vllm/worker/model_runner.py中,class GPUModelRunnerBase的初始化过程决定使用attention的类型。
·
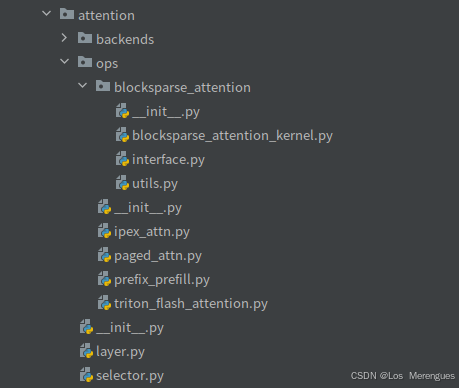
attention调用方式
在vllm/worker/model_runner.py中,class GPUModelRunnerBase的初始化过程决定使用attention的类型
self.attn_backend = get_attn_backend(
self.model_config.get_head_size(),
self.model_config.get_sliding_window(),
self.model_config.dtype,
self.kv_cache_dtype,
self.block_size,
self.model_config.is_attention_free,) if needs_attn_backend else None
if self.attn_backend:
self.attn_state = self.attn_backend.get_state_cls()(
weakref.proxy(self))
else:
self.attn_state = CommonAttentionState(weakref.proxy(self))
跳转到vllm/attention/selector.py中,get_attn_backend定义如下:
@lru_cache(maxsize=None)
def get_attn_backend(
head_size: int,
sliding_window: Optional[int],
dtype: torch.dtype,
kv_cache_dtype: Optional[str],
block_size: int,
is_attention_free: bool, # model中不包含attention计算
is_blocksparse: bool = False,
) -> Type[AttentionBackend]:
"""Selects which attention backend to use and lazily imports it."""
if is_blocksparse:
logger.info("Using BlocksparseFlashAttention backend.")
from vllm.attention.backends.blocksparse_attn import BlocksparseFlashAttentionBackend
return BlocksparseFlashAttentionBackend
backend = which_attn_to_use(head_size, sliding_window, dtype,
kv_cache_dtype, block_size, is_attention_free)
if backend == _Backend.FLASH_ATTN:
from vllm.attention.backends.flash_attn import FlashAttentionBackend
return FlashAttentionBackend
if backend == _Backend.XFORMERS:
logger.info("Using XFormers backend.")
from vllm.attention.backends.xformers import XFormersBackend
return XFormersBackend
elif backend == _Backend.ROCM_FLASH:
logger.info("Using ROCmFlashAttention backend.")
from vllm.attention.backends.rocm_flash_attn import ROCmFlashAttentionBackend
return ROCmFlashAttentionBackend
elif backend == _Backend.TORCH_SDPA:
assert is_cpu(), RuntimeError("Torch SDPA backend is only used for the CPU device.")
logger.info("Using Torch SDPA backend.")
from vllm.attention.backends.torch_sdpa import TorchSDPABackend
return TorchSDPABackend
elif backend == _Backend.OPENVINO:
logger.info("Using OpenVINO Attention backend.")
from vllm.attention.backends.openvino import OpenVINOAttentionBackend
return OpenVINOAttentionBackend
elif backend == _Backend.IPEX:
assert is_xpu(), RuntimeError("IPEX attention backend is only used for the XPU device.")
logger.info("Using IPEX attention backend.")
from vllm.attention.backends.ipex_attn import IpexAttnBackend
return IpexAttnBackend
elif backend == _Backend.FLASHINFER:
logger.info("Using Flashinfer backend.")
from vllm.attention.backends.flashinfer import FlashInferBackend
return FlashInferBackend
elif backend == _Backend.PALLAS:
logger.info("Using Pallas backend.")
from vllm.attention.backends.pallas import PallasAttentionBackend
return PallasAttentionBackend
elif backend == _Backend.NO_ATTENTION:
from vllm.attention.backends.placeholder_attn import PlaceholderAttentionBackend
return PlaceholderAttentionBackend
else:
raise ValueError("Invalid attention backend.")

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)