经典文献阅读之--AirSLAM(抗复杂光照点线视觉SLAM)
高效率。系统应在资源受限的平台上具备实时性能。可扩展性。系统应易于扩展,以满足各种目的和实际应用。易于部署。系统应易于在真实机器人上部署,并能够实现鲁棒的定位。因此,我们设计了如图1所示的系统。所提出的系统是一个混合系统,因为我们需要数据驱动方法的鲁棒性和几何方法的准确性。它由三个主要组件组成:立体视觉里程计(VO/VIO)、离线地图优化和轻量级重定位。图1. 所提出的系统由三个主要部分组成:在线
0. 简介
《AirSLAM: An Efficient and Illumination-Robust Point-Line Visual SLAM System》提出了一个高效的基于点线特征的视觉SLAM系统,旨在应对短期和长期的复杂光照对视觉定位的挑战。我们的系统采用了一种混合方法,在前端使用深度学习检测和匹配特征,在后端使用传统图优化算法优化地图。为了提升系统鲁棒性的同时兼顾效率,我们提出了一个统一的网络同时提取特征点,描述符和线特征。之后这两种特征会被关联起来,并以耦合的方式用于匹配、三角化、优化和重定位。为了长期复用建立的地图,我们设计了一个轻量级的层级重定位流程。点特征和线特征会被同时用于查询帧和地图之间匹配。为了增强系统的实用性,我们使用C++和NVIDIA TensorRT部署并加速了特征检测和匹配网络。这使得我们的系统可以在PC上以73Hz的速度运行,在嵌入式平台上以40Hz的速度运行。我们在不同数据集上进行了实验,结果表明我们的系统可以在复杂光照条件下建立准确的地图,并且建立的地图可以在不同光照条件下复用。相关的代码已经在Github上开源了
1. 主要贡献
本文引入了AirSLAM。我们观察到,线特征可以提高vSLAM系统的准确性和鲁棒性[4],[21],[22],因此我们将点特征和线特征结合起来,用于跟踪、映射、优化和重定位。为了在效率和性能之间取得平衡,我们将系统设计为混合系统,采用基于学习的方法进行特征检测和匹配,同时使用传统几何方法进行位姿和地图优化。此外,为了提高特征检测的效率,我们开发了一个统一模型,能够同时检测点特征和线特征。我们还通过提出一种多阶段重定位策略来解决长期定位挑战,该策略有效地重用我们的点线地图。总之,我们的贡献包括:
- 我们提出了一种新颖的基于点线的vSLAM系统,该系统结合了传统优化技术的效率与基于学习方法的鲁棒性。我们的系统在面对短期和长期的光照挑战时表现出色,同时在嵌入式平台上保持足够的效率以便于部署。
- 我们开发了一个统一的关键点和线检测模型,称为PLNet。据我们所知,PLNet是第一个能够同时检测点特征和线特征的模型。此外,我们将这两种特征关联起来,并共同利用它们进行跟踪、映射和重定位任务。
- 我们提出了一种基于点特征和线特征的多阶段重定位方法,利用外观和几何信息。该方法能够在现有视觉地图中,仅使用单幅图像提供快速且对光照变化鲁棒的定位。
- 我们进行了广泛的实验,以证明所提方法的效率和有效性。结果表明,我们的系统在各种光照挑战条件下实现了准确且鲁棒的映射和重定位性能。此外,我们的系统也非常高效。在PC上运行速率为73Hz,在嵌入式平台上为40Hz。
2. 系统概述
我们认为,一个实用的vSLAM系统应具备以下特性:
- 高效率。系统应在资源受限的平台上具备实时性能。
- 可扩展性。系统应易于扩展,以满足各种目的和实际应用。
- 易于部署。系统应易于在真实机器人上部署,并能够实现鲁棒的定位。
因此,我们设计了如图1所示的系统。所提出的系统是一个混合系统,因为我们需要数据驱动方法的鲁棒性和几何方法的准确性。它由三个主要组件组成:立体视觉里程计(VO/VIO)、离线地图优化和轻量级重定位。
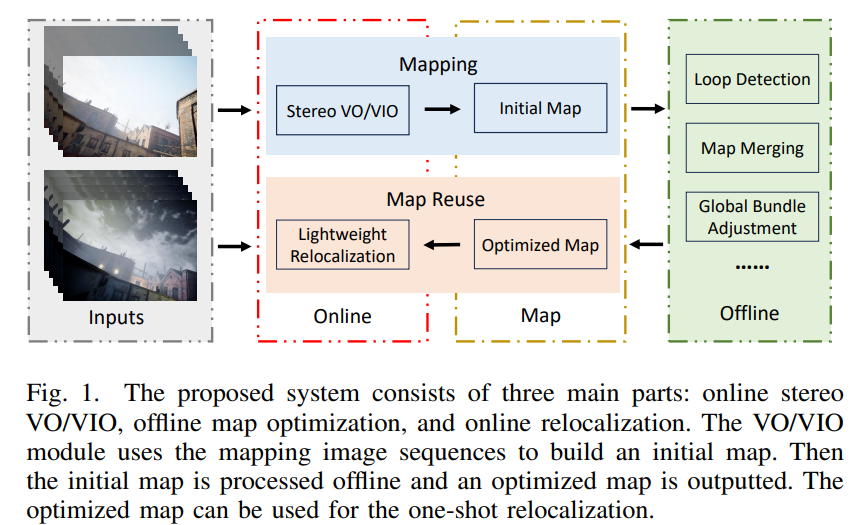
图1. 所提出的系统由三个主要部分组成:在线立体视觉里程计(VO/VIO)、离线地图优化和在线重定位。VO/VIO模块利用映射图像序列构建初始地图。随后,初始地图在离线阶段进行处理,并输出优化后的地图。优化后的地图可用于一次性重定位。
(1) 立体视觉里程计(VO/VIO):我们提出了一种基于点线的视觉里程计,能够处理立体和立体惯性输入。
(2) 离线地图优化:我们实现了几个常用的插件,如回环检测、位姿图优化和全局束调整。通过添加定制插件,系统可以轻松扩展以满足其他地图处理需求。例如,我们实现了一个插件,利用线特征的端点训练场景依赖的交叉口词汇,这在我们的轻量级多阶段重定位中得到了应用。
(3) 轻量级重定位:我们提出了一种多阶段重定位方法,在保持有效性的同时提高效率。在第一阶段,使用所提出的PLNet检测关键点和线特征,并利用在大数据集上训练的关键点词汇检索多个候选项。在第二阶段,使用场景依赖的交叉口词汇和结构图快速过滤掉大多数错误候选项。在第三阶段,在查询帧和剩余候选项之间进行特征匹配,以找到最佳匹配并估计查询帧的位姿。由于第三阶段的特征匹配通常耗时较长,因此第二阶段的过滤过程提高了我们系统的效率,相较于其他两阶段重定位系统更具优势。
我们将一些耗时的过程(例如,回环闭合检测、位姿图优化和全局束调整)转移到离线阶段。这提高了我们在线映射模块的效率。在许多实际应用中,例如仓库机器人,地图通常由一台机器人构建,然后被其他机器人重用。我们的系统正是考虑到这些应用而设计的。轻量级的映射和地图重用模块可以轻松部署在资源受限的机器人上,而离线优化模块则可以在更强大的计算机上运行,以进行各种地图操作,如地图编辑和可视化。映射机器人将初始地图上传到计算机,计算机随后将优化后的地图分发给其他机器人,从而确保无漂移重定位。在接下来的章节中,我们将在第3节和第4节分别介绍我们的特征检测和视觉里程计(VO)管道。离线优化和重定位模块将在第5节中介绍。
3. 特征检测
3.1 动机
随着深度学习技术的进步,基于学习的特征检测方法在光照挑战环境中表现出比传统方法更稳定的性能。然而,现有的基于点线的视觉里程计(VO/VIO)和同步定位与地图构建(SLAM)系统通常分别检测关键点和线特征。虽然对于手工设计的方法来说,这种做法是可以接受的,因为其效率较高,但在VO/VIO或SLAM系统中,尤其是在立体配置下,同时应用关键点检测和线检测网络往往会妨碍在资源受限平台上的实时性能。因此,我们的目标是设计一个高效的统一模型,能够同时检测关键点和线特征。然而,实现一个用于关键点和线检测的统一模型是具有挑战性的,因为这些任务通常需要不同的真实图像数据集和训练过程。关键点检测模型通常在包含多样化图像的大型数据集上进行训练,并依赖于提升步骤或图像对的对应关系进行训练 [23], [37], [38]。对于线检测,我们发现线框解析方法 [47], [49] 能提供比自监督模型 [48], [65] 更强的几何线索,因为它们能够检测到更长且更完整的线条。然而,这些方法是在线框数据集 [66] 上训练的,该数据集的规模有限,仅包含5,462幅不连续的图像。在接下来的部分中,我们将解决这一挑战,并展示如何训练一个能够同时执行这两项任务的统一模型。需要注意的是,在本文中,“线检测”一词特指线框解析任务。
3.2 架构设计
如图2所示,在可视化关键点和线检测网络的结果时,我们有两个发现:(1)线检测模型检测到的大多数交点(线的端点)也被关键点检测模型选为关键点;(2)关键点检测模型输出的特征图包含边缘信息。因此,我们认为可以在预训练的关键点检测模型的基础上构建线检测模型。基于这一假设,我们设计了PLNet,以在统一框架中检测关键点和线条。如图3所示,它由共享的主干、关键点模块和线模块组成。
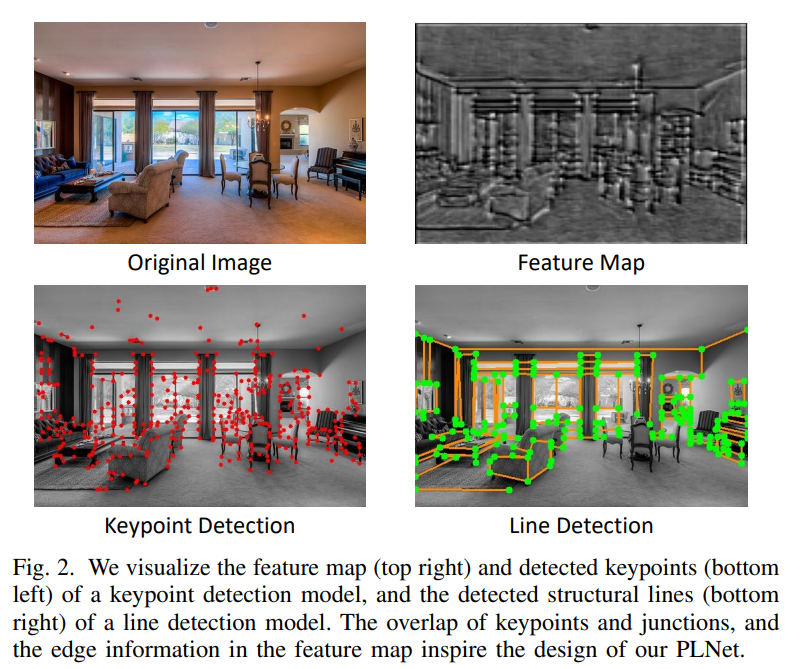
图2. 我们可视化了关键点检测模型的特征图(右上角)和检测到的关键点(左下角),以及线检测模型检测到的结构线(右下角)。关键点与交点的重叠,以及特征图中的边缘信息,启发了我们PLNet的设计。
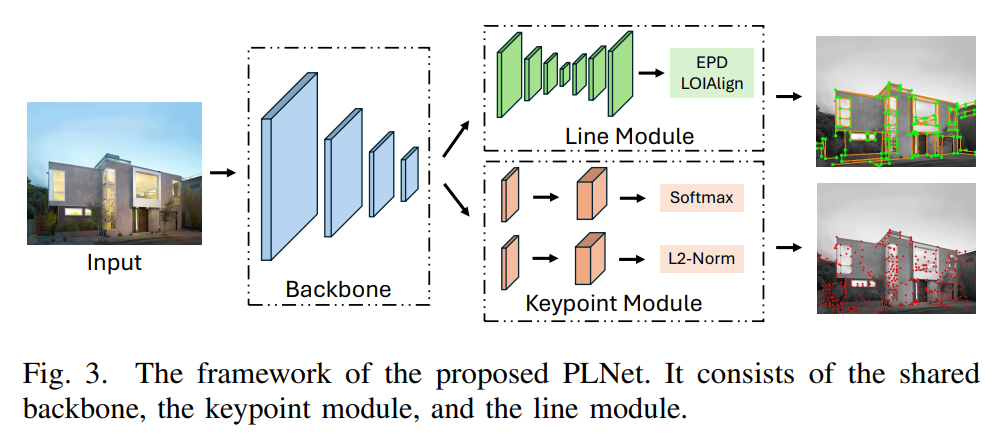
图3. 所提出的PLNet框架。它由共享主干、关键点模块和线模块组成。
3.2.1 主干
我们遵循SuperPoint [23] 的设计,选择其良好的效率和有效性。它使用8个卷积层和3个最大池化层。输入为尺寸为 H × W H \times W H×W 的灰度图像。输出为 H × W × 64 H \times W \times 64 H×W×64、 H 2 × W 2 × 64 \frac{H}{2} \times \frac{W}{2} \times 64 2H×2W×64、 H 4 × W 4 × 128 \frac{H}{4} \times \frac{W}{4} \times 128 4H×4W×128 和 H 8 × W 8 × 128 \frac{H}{8} \times \frac{W}{8} \times 128 8H×8W×128 的特征图。
3.2.2 关键点模块
我们同样遵循SuperPoint [23] 的设计来构建关键点检测头。它有两个分支:得分分支和描述符分支。输入为主干输出的 H 8 × W 8 × 128 \frac{H}{8} \times \frac{W}{8} \times 128 8H×8W×128 特征图。得分分支输出一个尺寸为 H 8 × W 8 × 65 \frac{H}{8} \times \frac{W}{8} \times 65 8H×8W×65 的张量。65个通道对应于一个 8 × 8 8 \times 8 8×8 的网格区域和一个表示无关键点的垃圾箱。该张量经过softmax处理后,调整为 H × W H \times W H×W 的尺寸。描述符分支输出一个尺寸为 H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 的张量,用于插值计算关键点的描述符。
3.2.3 线模块
该模块以 H 4 × W 4 × 128 \frac{H}{4} \times \frac{W}{4} \times 128 4H×4W×128 的特征图作为输入。它由一个类似U-Net的卷积神经网络和线检测头组成。我们对U-Net [67] 进行了修改,使其包含更少的卷积层,从而提高效率。类似U-Net的卷积神经网络用于增加感受野,因为检测线条所需的感受野大于检测关键点的感受野。EPD LOIAlign [49] 被用来处理线模块的输出,最终输出交点和线条。
3.3 网络训练
由于在第3.1节中描述的训练问题以及第3.2节中的假设,我们将PLNet分为两个阶段进行训练。在第一阶段,仅训练主干网络和关键点检测模块,这意味着我们需要训练一个关键点检测网络。在第二阶段,主干网络和关键点检测模块保持固定,我们仅在Wireframe数据集上训练线检测模块。我们省略第一阶段的细节,因为它们与文献[23]非常相似。相反,我们将重点介绍线检测模块的训练。
3.3.1 线编码
我们采用吸引区域场[49]来编码线段。对于线段 l = ( x 1 , x 2 ) l = (x_1, x_2) l=(x1,x2),其中 x 1 x_1 x1 和 x 2 x_2 x2 是线段 l l l 的两个端点,以及位于 l l l 的吸引区域中的点 p p p,我们使用四个参数和点 p p p 来编码 l l l:
p ( l ) = ( d , θ , θ 1 , θ 2 ) , (1) p(l) = (d, \theta, \theta_1, \theta_2) , \tag{1} p(l)=(d,θ,θ1,θ2),(1)
其中 d = ∣ p o ∣ d = |po| d=∣po∣, o o o 是垂足。 θ \theta θ 是线段 l l l 与图像Y轴之间的角度。 θ 1 \theta_1 θ1 是点 p x 1 p{x_1} px1 与 p o po po 之间的角度。 θ 2 \theta_2 θ2 是点 p x 2 p{x_2} px2 与 p o po po 之间的角度。网络可以为点 p p p 预测这四个参数,然后通过以下方式解码 l l l:
l = d ⋅ [ cos θ − sin θ sin θ cos θ ] [ 1 tan θ 1 1 tan θ 2 ] + [ p p ] ⋅ ( 2 ) l = d \cdot \left[ \begin{matrix} \cos \theta & -\sin \theta \\\sin \theta & \cos \theta \end{matrix} \right] \left[ \begin{matrix}\frac{1}{\tan \theta_1} & \frac{1}{\tan \theta_2}\end{matrix} \right] + \left[ \mathbf{p} \mathbf{p} \right] \cdot (2) l=d⋅[cosθsinθ−sinθcosθ][tanθ11tanθ21]+[pp]⋅(2)
3.3.2 线段预测
线检测模块输出一个大小为 H 4 × W 4 × 4 \frac{H}{4} \times \frac{W}{4} \times 4 4H×4W×4 的张量,以预测公式(1)中的参数,并生成一个热图以预测交点。对于通过公式(2)解码的每个线段,将选择与其端点最近的两个交点,以与之形成线段提议。具有相同交点的提议将被去重,仅保留一个。然后,应用EPD LOIAlign [49] 和一个头部分类器,以决定该线段提议是否为真实的线特征。
3.3.3 线模块训练
我们使用 L 1 L_1 L1 损失来监督公式(1)中参数的预测,并使用二元交叉熵损失来监督交点热图和头部分类器。总损失是它们的总和。如图4所示,为了提高在光照挑战环境下线检测的鲁棒性,应用了七种类型的光度数据增强来处理训练图像。训练过程中使用ADAM优化器 [68],在前35个周期的学习率为 l r = 4 × 1 0 − 4 lr = 4 \times 10^{-4} lr=4×10−4,在最后5个周期的学习率为 l r = 4 × 1 0 − 5 lr = 4 \times 10^{-5} lr=4×10−5。

图4. 我们使用七种类型的光度数据增强来训练我们的PLNet,以提高其对复杂光照条件的鲁棒性。
4. 立体视觉里程计
4.1 概述
所提出的基于点线的立体视觉里程计如图5所示。它是一个混合的视觉里程计系统,结合了基于学习的前端和传统的优化后端。对于每对立体图像,我们首先使用所提出的PLNet提取关键点和线特征。然后,使用GNN(LightGlue [26])进行关键点匹配。与此同时,我们将线特征与关键点关联,并利用关键点匹配结果进行匹配。之后,我们进行初步的位姿估计并剔除异常值。基于这些结果,我们对关键帧的二维特征进行三角化,并将其插入地图中。最后,将执行局部束调整,以优化点、线和关键帧的位姿。同时,如果可获取IMU,其测量值将通过IMU预积分方法 [69] 进行处理,并添加到初步位姿估计和局部束调整中。

图5. 我们的视觉(惯性)里程计框架。该系统分为两个主要线程,分别用两种不同颜色的区域表示。请注意,IMU输入并不是严格要求的。系统可以选择使用立体数据或立体惯性数据。
将基于学习的特征检测和匹配方法应用于立体视觉里程计是耗时的。因此,为了提高效率,我们的系统采用了以下三种技术。
(1) 对于关键帧,我们在左右图像上提取特征并进行立体匹配,以估计真实的尺度。但对于非关键帧,我们仅处理左图像。此外,我们使用一些宽松的标准,使得我们系统中选择的关键帧非常稀疏,从而使特征检测和匹配的运行时间和资源消耗接近单目系统的水平。
(2) 我们将CNN和GNN的推理代码从Python转换为C++,并使用ONNX和NVIDIA TensorRT进行部署,其中16位浮点运算替代了32位浮点运算。
(3) 我们设计了一个多线程管道。采用生产者-消费者模型将系统分为两个主要线程,即前端线程和后端线程。前端线程负责提取和匹配特征,而后端线程则执行初步位姿估计、关键帧插入和局部束调整。
4.2 特征匹配
我们使用 LightGlue [26] 来匹配关键点。对于线特征,目前大多数视觉里程计(VO)和同步定位与地图构建(SLAM)系统使用 LBD 算法 [70] 或跟踪样本点进行匹配。然而,LBD 算法是从线的局部带状区域提取描述符,因此在光照或视角变化较大的情况下,线检测的稳定性受到影响。跟踪样本点可以在两个帧中匹配不同长度的线,但当前的 SLAM 系统通常使用光流来跟踪样本点,而在光照条件快速或剧烈变化时,其性能较差。一些基于学习的线特征描述符 [48] 也被提出,但由于时间复杂度的增加,它们在当前的 SLAM 系统中很少被使用。因此,为了解决有效性和效率的问题,我们设计了一种快速且稳健的线匹配方法,以应对光照挑战条件。首先,我们通过关键点与线段之间的距离进行关联。假设在图像上检测到 𝑀 个关键点和 𝑁 条线段,其中每个关键点表示为 p i = ( x i , y i ) p_i = (x_i, y_i) pi=(xi,yi),每条线段表示为 l j = ( A j , B j , C j , x j , 1 , y j , 1 , x j , 2 , y j , 2 ) l_j = (A_j, B_j, C_j, x_{j,1}, y_{j,1}, x_{j,2}, y_{j,2}) lj=(Aj,Bj,Cj,xj,1,yj,1,xj,2,yj,2),其中 ( A j , B j , C j ) (A_j, B_j, C_j) (Aj,Bj,Cj) 是线段 l j l_j lj 的参数,而 ( x j , 1 , y j , 1 , x j , 2 , y j , 2 ) (x_{j,1}, y_{j,1}, x_{j,2}, y_{j,2}) (xj,1,yj,1,xj,2,yj,2) 是线段的端点。我们首先通过以下公式计算 p i p_i pi 和 l j l_j lj 之间的距离:
d i j = d ( p i , l j ) = ∣ A j ⋅ x i + B j ⋅ y i + C j ∣ A j 2 + B j 2 (3) d_{ij} = d(p_i, l_j) = \frac{|A_j \cdot x_i + B_j \cdot y_i + C_j|}{\sqrt{A_j^2 + B_j^2}} \tag{3} dij=d(pi,lj)=Aj2+Bj2∣Aj⋅xi+Bj⋅yi+Cj∣(3)
如果 d i j < 3 d_{ij} < 3 dij<3 且 p i p_i pi 在坐标轴上的投影位于线段端点的投影范围内,即 min ( x j , 1 , x j , 2 ) ≤ x i ≤ max ( x j , 1 , x j , 2 ) \min(x_{j,1}, x_{j,2}) \leq x_i \leq \max(x_{j,1}, x_{j,2}) \quad min(xj,1,xj,2)≤xi≤max(xj,1,xj,2)或 min ( y j , 1 , y j , 2 ) ≤ y i ≤ max ( y j , 1 , y j , 2 ) \quad \min(y_{j,1}, y_{j,2}) \leq y_i \leq \max(y_{j,1}, y_{j,2}) min(yj,1,yj,2)≤yi≤max(yj,1,yj,2) 我们将认为 p i p_i pi 属于 l j l_j lj。然后,基于这两幅图像的点匹配结果,可以对两幅图像上的线段进行匹配。对于图像 k k k 上的线段 l k , m l_{k,m} lk,m 和图像 k + 1 k + 1 k+1 上的线段 l k + 1 , n l_{k+1,n} lk+1,n,我们计算一个分数 S m n S_{mn} Smn 来表示它们是同一条线的置信度:
S m n = N p m min ( N k , m , N k + 1 , n ) (4) S_{mn} = \frac{N_{pm}}{\min(N_{k,m}, N_{k+1,n})} \tag{4} Smn=min(Nk,m,Nk+1,n)Npm(4)
其中 N p m N_{pm} Npm 是属于 l k , m l_{k,m} lk,m 的点特征与属于 l k + 1 , n l_{k+1,n} lk+1,n 的点特征之间的匹配数量。 N k , m N_{k,m} Nk,m 和 N k + 1 , n N_{k+1,n} Nk+1,n 分别是属于 l k , m l_{k,m} lk,m 和 l k + 1 , n l_{k+1,n} lk+1,n 的点特征数量。然后,如果 S m n > δ S S_{mn} > \delta_S Smn>δS 且 N p m > δ N N_{pm} > \delta_N Npm>δN,其中 δ S \delta_S δS 和 δ N \delta_N δN 是两个预设阈值,我们将视 l k , m l_{k,m} lk,m 和 l k + 1 , n l_{k+1,n} lk+1,n 为同一条线。这种耦合特征匹配方法使我们的线匹配能够共享关键点匹配的稳健性能,同时由于不需要另一个线匹配网络而具有高度的效率。
4.3 3D特征处理
…详情请参照古月居

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献128条内容
已为社区贡献128条内容

所有评论(0)