【编译原理】上下文无关文法
文章目录
上下文无关文法
引入
-
有这样一种语言
X- 句子结构为:主语 + 谓语 + 宾语
- 主语中只有:你、我、他
- 谓语中只有:吃
- 宾语中只有:饭、菜
-
该语言的语法以下面的形式给出
语句 -> 主语 谓语 宾语 主语 -> 你 | 我 | 他 谓语 -> 吃 宾语 -> 饭 | 菜-
该语法中的每一行,如
语句 -> 主语 谓语 宾语,这样的式子称为产生式(production) -
产生式的左侧称为非终结符(
nonterminal),如语句-
非终结符代表可以产生新的符号,如
语句可以产生主语 谓语 宾语 -
在产生式的右侧遇到了非终结符时,可以用该非终结符的产生式的右侧替换它
例如:
语句 -> 主语 谓语 宾语 谓语 -> 吃 语句 -> 主语 吃 宾语
-
-
某些符号无法产生新的符号,如
吃,这样的符号称为终结符(terminal) -
非终结符中,有一个特殊的符号,所有的句子都由它产生,该符号称为起始符号(
start symbol)在
X语言中,起始符号为语句
-
定义
- 上下文无关文法是一个 4 元组
- 终结符
- 非终结符
- 起始符号(开始符号)
- 产生式
分析树
介绍
-
分析树可以描述某个句子是如何产生的
-
以【引入】中语言为例
我吃饭是该语言的一个句子,分析树为: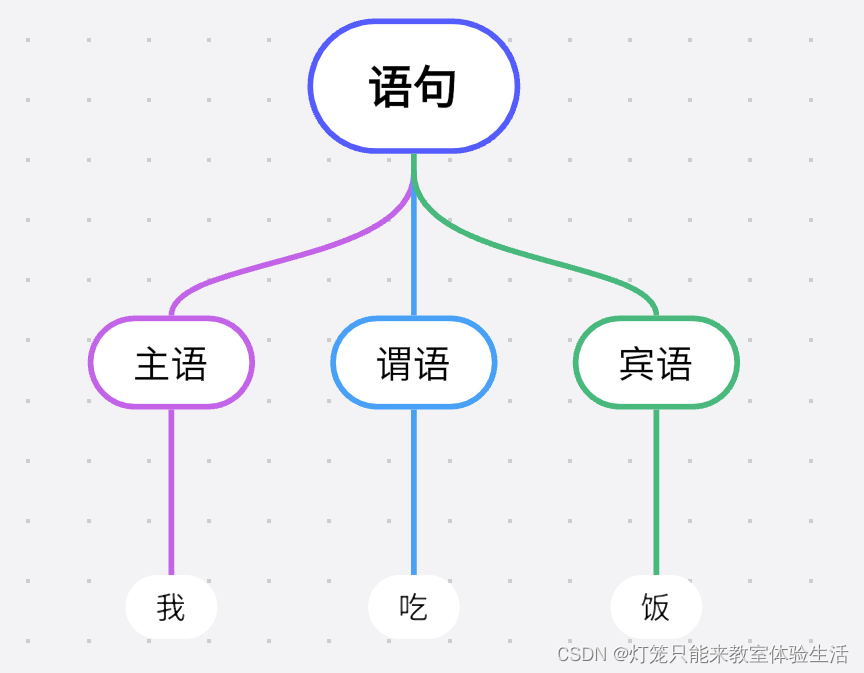
观察分析树:
-
根节点为起始符号
-
子节点为非终结符
-
叶子节点为终结符
叶子节点是没有子节点的节点,该分析树中的叶子节点有:我、吃、饭
-
二义性
-
某个语言的上下文无关文法表示为:
S -> E E -> E OP E | (E) | number OP -> + | -其中
number记为整数 -
该语言有这样一个句子:
1 + 2 - 3-
我们可以得到该句子的分析树:
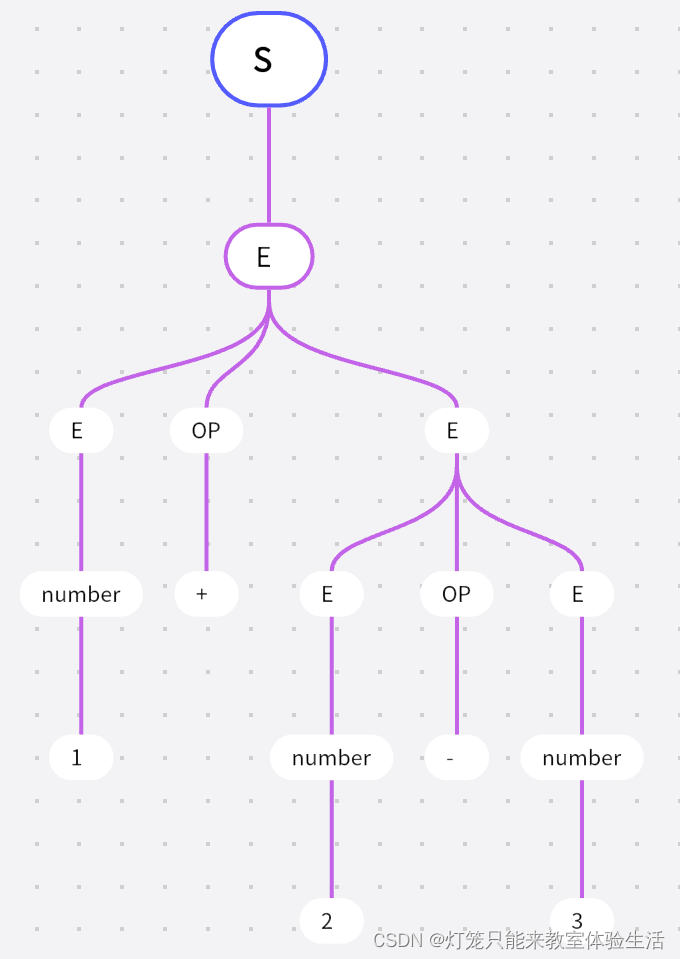
该分析树的思想是:
1 + (2 - 3),即将(2 - 3)视为一个整体 -
如果我们将
1 + 2视为一个整体呢?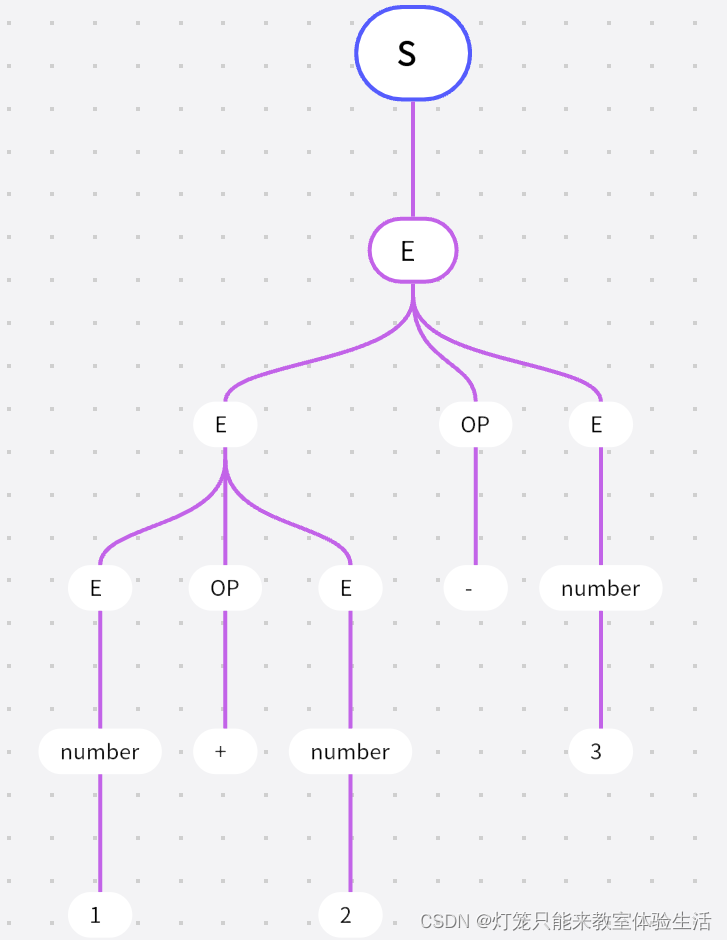
也能得到该语句
-
-
所谓二义性,指的是推导过程不唯一
分析方法
自上而下分析
-
自上而下分析是:起始符号开始,不断挑选合适的产生式,最终得到给定的句子
-
某种语言的语法如下:
S -> AB A -> aA | ε B -> bB | b -
假设要分析的句子是:
aab中间句子 产生式 S S -> AB AB A -> aA aAB A -> aA aaAB A -> ε aaB B -> b aab ACCEPT ACCEPT表示语法能够接收给定的句子
自下而上分析
-
自下而上分析:从给定的句子开始,不断挑选合适的产生式,最终得到起始符号
-
某种语言的语法如下:
S -> AB A -> Aa | ε B -> Bb | b -
假设要分析的句子是:
aabb中间句子 产生式 aabb 插入 ε εaabb A -> ε Aaabb A -> Aa Aabb A -> Aa Abb B -> Bb ABb B -> Bb AB S -> AB S ACCEPT ACCEPT表示语法能够接收给定的句子
左递归与右递归
左右递归的概念
-
左递归是形如
A -> Aa的产生式-
其中右侧的
A又可以推导出Aa,即A -> Aa -> Aaa -> ... -
这样的推导能够无限执行
-
由于递归过程中,是左侧的符号在执行推导,因此称为左递归
-
-
右递归是形如
B -> bB的产生式- 同理,
B -> bB -> bbB -> ...
- 同理,
分析过程可能出现的问题
-
实际上,在【自上而下分析】和【自下而上分析】中,两个例子都是精心挑选出来的
而推导过程中,有可能产生回溯,甚至是匹配失败
-
假设有这样的语法
S -> A A -> a | b要分析的句子是:
b显然,可以通过
A -> b这样的产生式来直接得到结果,但其实在我们思考的过程中,不经意间进行了回溯实际上,我们思考的过程是
中间句子 产生式 S S -> A A A -> a a 与句子不符,需要回溯 A A->b b ACCEPT ACCEPT表示语法能够接收给定的句子
-
假设有这样的语法
S -> A A -> a | b要分析的句子是:
c分析的过程是:
中间句子 产生式 S S -> A A A -> a a 与句子不符,需要回溯 A A -> b b 与句子不符,需要回溯 A 没有其他的符号可以选择,REJECT REJECT表示语法不能接收给定的句子
-
左递归对自上而下分析的影响
-
由上一节的讲解得知,判断一个句子能否被接收,大致是这样的算法
- 从起始符号
S出发,推导出产生式的右侧AB - 从给定句子的第一个符号
α开始 - 从产生式左侧的第一个非终结符
A开始 - 遍历
A所有能够产生的符号,若包含α,则继续,否则回溯 - 所有的符号均不能产生
α,结束 - 匹配成功后,将给定句子的下一个符号标记为
α - 句子中所有的符号匹配成功,结束
- 从起始符号
-
不如在【自上而下分析】中引入左递归
S -> AB A -> Aa | ε B -> b我们需要分析的句子是:
aab-
我们先将起始符号展开
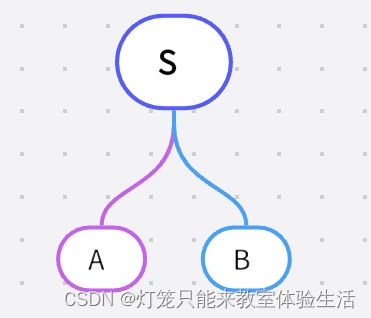
-
对于
A,我们尝试能够产生的符号:Aa、ε,首先尝试Aa(若首先尝试ε会立刻回溯,简化这个回溯的过程吧)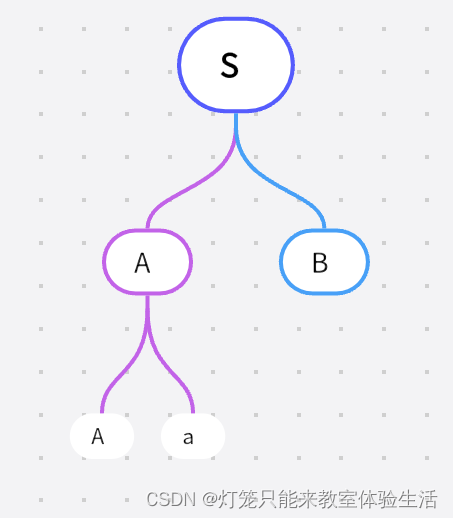
-
从
A产生的符号Aa中,按顺序开始,第一个是A,对于A,我们尝试能够产生的符号:Aa、ε,,首先尝试Aa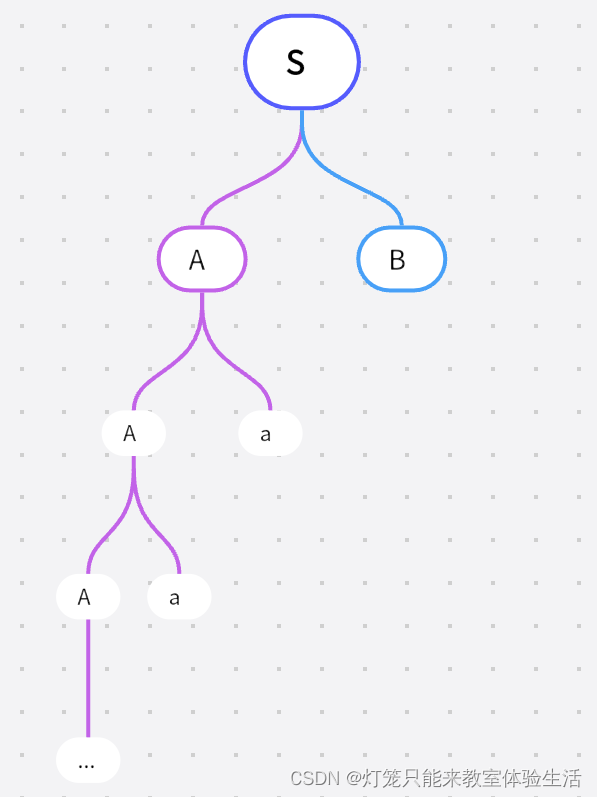
我们会发现,这个过程是永远不会停下来的
因此,将自上而下分析用于包含左递归的语法,是不合适的
-
-
但是!我们目前在上帝视角,还是可以通过某种方式,用自上而下分析解决这个问题
-
首先之前会无限循环是因为
A被不断推导,那么我们观察 A 的产生式A -> Aa | ε没错,只需要将
A推导成ε即可结束这一个过程 -
我们将句子改写为
εaab,这和原语句是等价的 -
重新开始分析这个句子吧
-
仍然是由起始符号,推导出产生式右侧,并且
A选择产生式右侧的Aa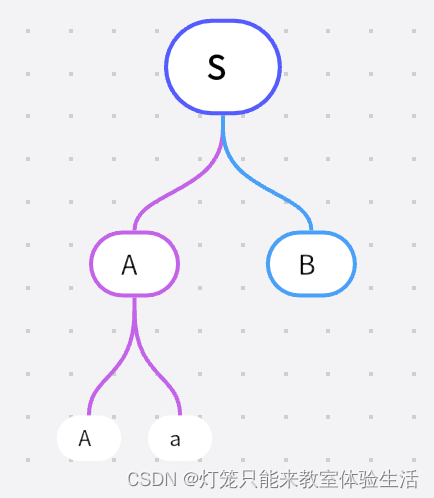
-
虽然要产生
ε,但是仍然选择A -> Aa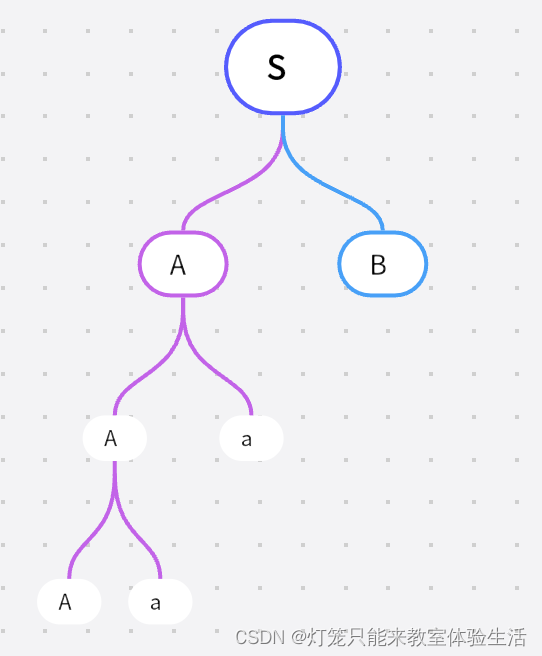
-
此时,已经有 2 个
a作为叶子节点在 A 的右侧了,我们选择ε,顺便将 B 直接通过B -> b推导为b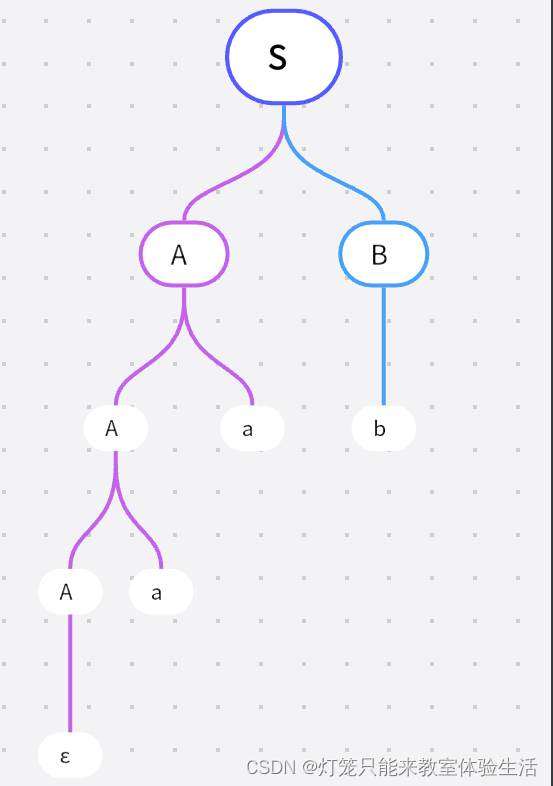
得到了句子
εaab -
去掉开头的
ε,最终结果就是aab
-
-
-
在上面的分析过程中,产生式右侧符号的选择,没有保持不变,这就需要更多的上下文信息(我们通过
A -> Aa产生 2 个a),然后再使用
A -> ε结束递归 -
再思考一下,实际上,我们不需要考虑无限递归,每一次的推导,都会使得最终结果的串变长,当长度超过给定语句时,就可以回溯
总结
- 自上而下分析,是可以通过转化给定句子,实现对左递归语法的分析
左递归的消去
-
假设有这样的产生式:
A -> Aa | b-
先画出该产生式的分析树吧
我将该产生式分成两个部分:左递归、非左递归
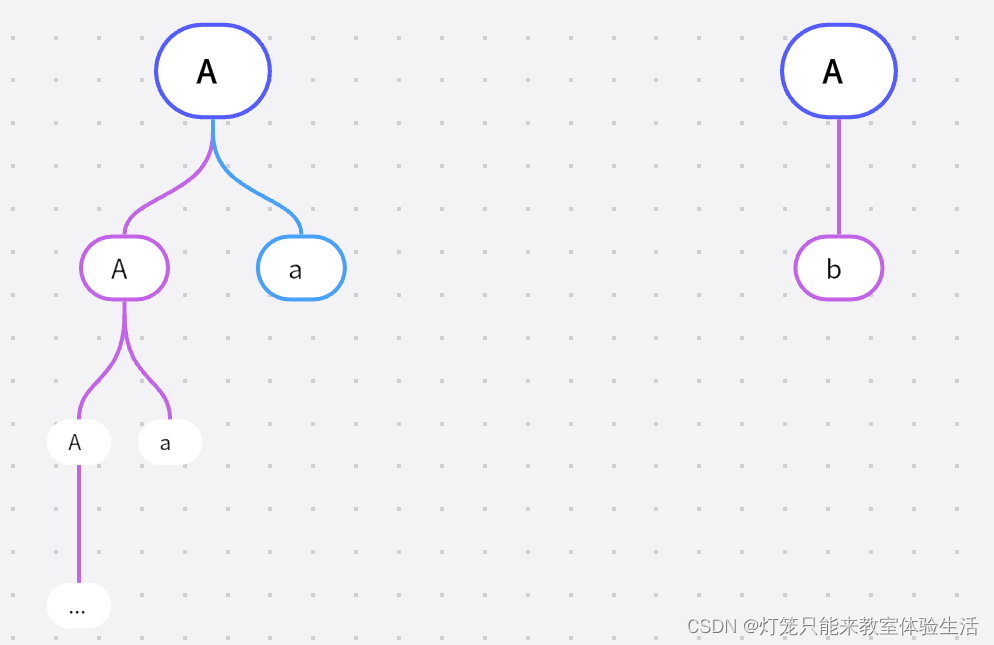
如果
A的推导想要结束,必然是经过了非左递归的推导,即b那么我们将 A 的推导重写为
A -> bA' -
接下来分析
A'到底是什么其实
A'就是左侧的递归部分,因为非递归部分是确定的那么
A'可以产生的串有:A、a,而A又会产生a(不考虑非递归部分)所以
A' -> a | A' -
结合
A -> bA',有可能 A 以A -> b就结束推导,因此A'还可以是ε所以
A' -> A' | a | ε
-
引用
参考文档:
https://pandolia.net/tinyc绘图工具:
https://boardmix.cn/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)