[论文阅读]Benchmarking Poisoning Attacks against Retrieval-Augmented Generation
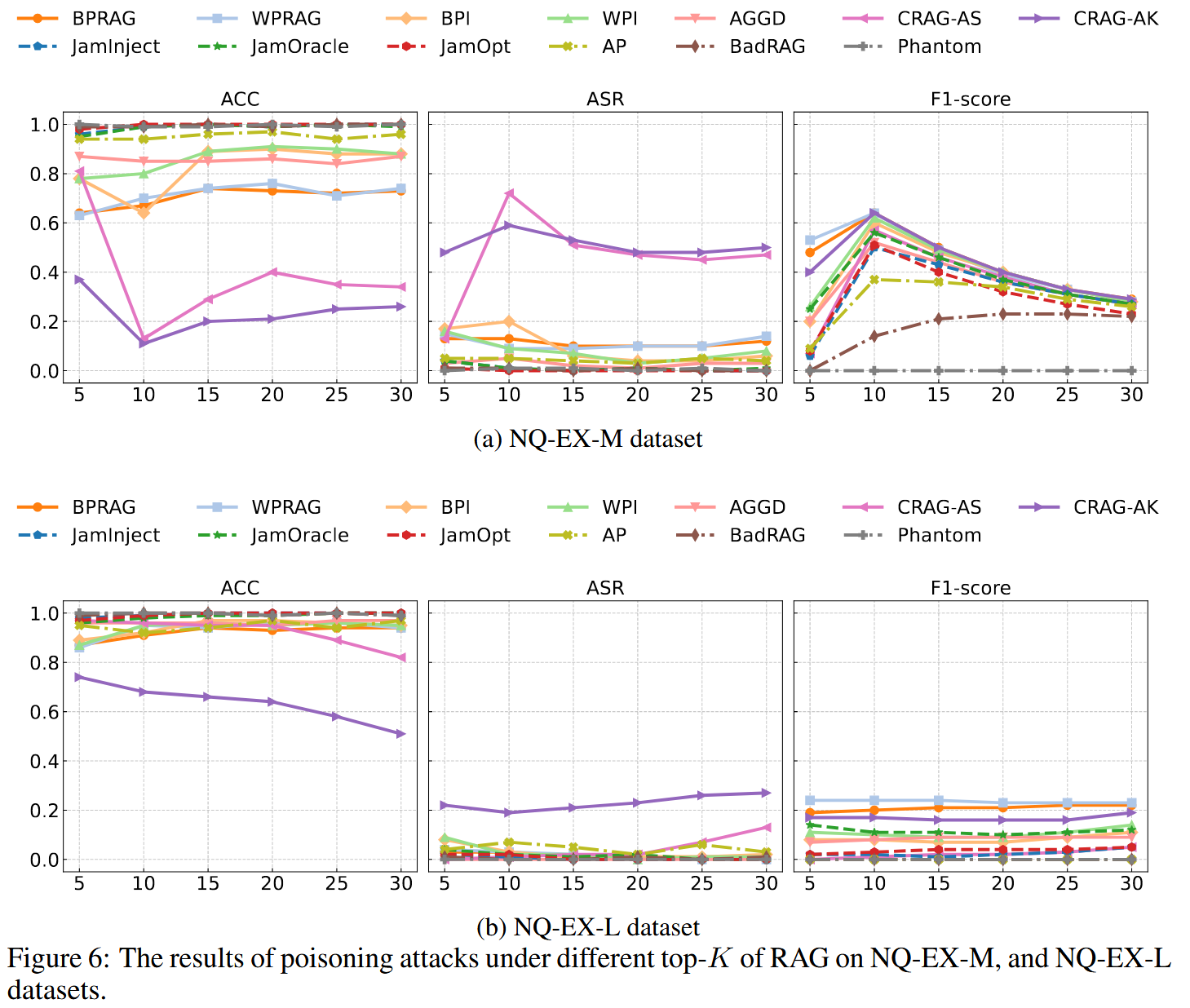
扩展的数据集上,较高的K值会提高中毒文本的召回率,但攻击不会变得更有效,因为包含正确答案为LLM提供了足够的可靠信息来抵抗操纵;其次,具有自适应检索功能的框架(例如FLARE)通过在不需要时跳过检索来展示强大的鲁棒性,从而减少了对中毒内容的暴露。值得注意的是,LLM代理的额外复杂性并没有阻碍攻击。相反,EX-M和EX-L版本检索到更多具有更高相似度的正确文本,为LLM提供了更强的信号,并降低了攻击
Benchmarking Poisoning Attacks against Retrieval-Augmented Generation
https://arxiv.org/abs/2505.18543v1
针对RAG系统的三种主要攻击向量:
- 隐私推理攻击:精心设计的查询来提取机密信息
- 基于触发器的检索器攻击:利用嵌入式触发器操纵检索器以影响下游生成
- 投毒攻击:讲对抗性内容注入知识数据库
威胁模型
攻击者的目标:
- 目标投毒攻击:攻击者旨在使RAG针对特定查询返回攻击者选择的特定响应
- 拒绝服务攻击:让系统拒绝回答一般的用户查询
- 基于触发器的拒绝服务:攻击者让系统中毒,只有出现特定的触发器短语时才拒绝响应,选择性地组织目标主题上的功能
攻击者的背景知识:
- 知识库:知道/不知道
- LLM:始终无法访问内部参数
- 检索器:黑盒条件下无法访问或者查询检索器;白盒条件下可以访问参数但是不能修改;
- 查询:攻击者有/无目标查询
攻击者的能力:
- 假设攻击者可以通过修改构建数据库的数据源,把任意文本注入到知识数据库中
- 攻击者无法修改用户的查询
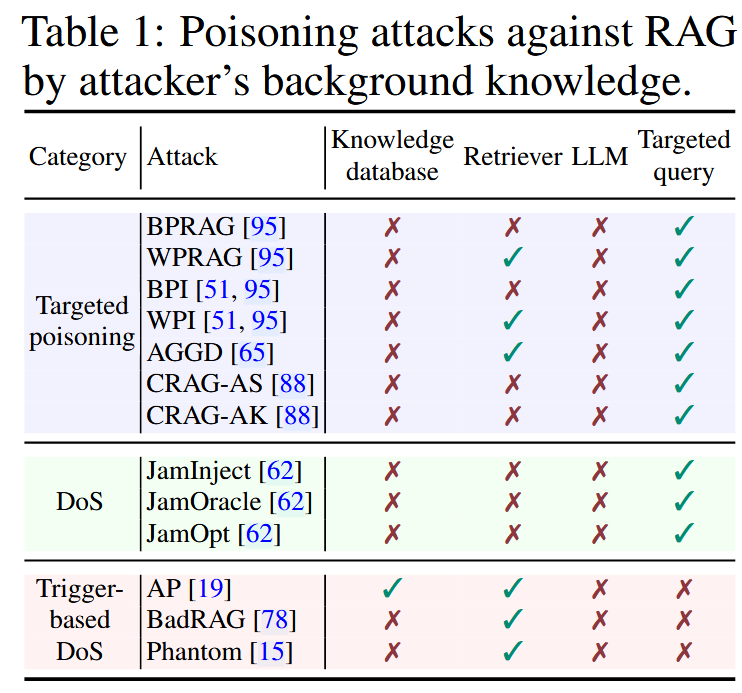
针对RAG的投毒攻击
目标投毒攻击:攻击者选择一组目标查询,为每一个查询把中毒文本注入知识库中,目的是在问道问题时返回特定的回答。
拒绝服务:选择一组目标查询,每个查询把中毒文本注入,使得在问道问题时拒绝回答
基于触发器的拒绝服务:构造特定领域的触发器字符串,导致对特定主题的目标问题拒绝回答。
评估
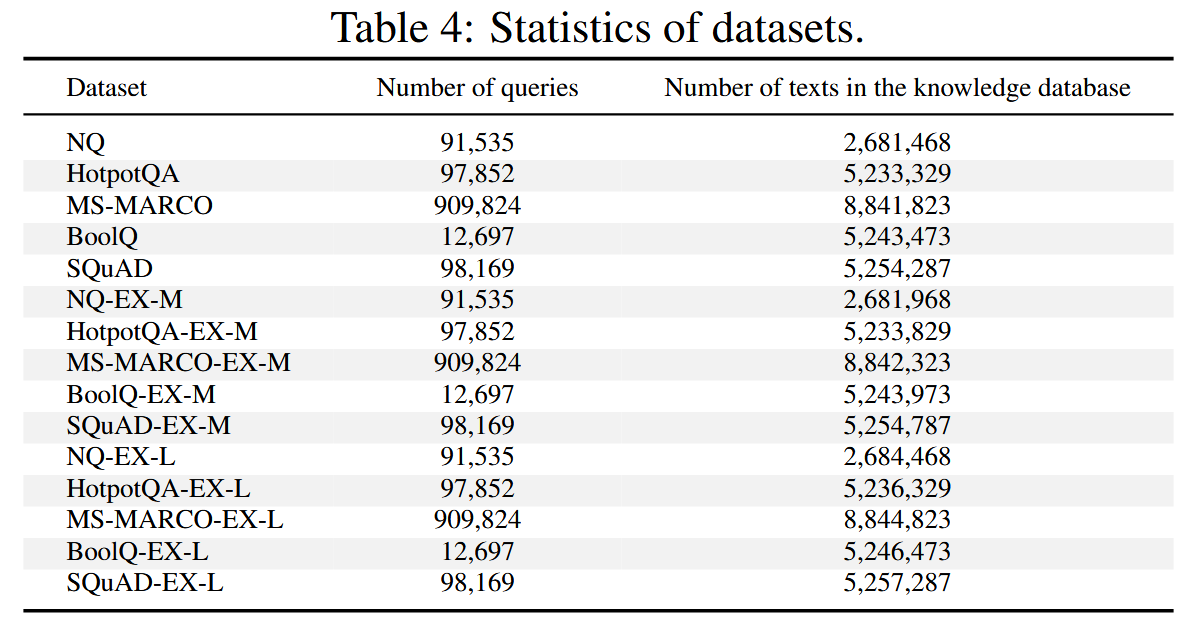
原始数据集:NQ,HotpotQA,MS-MARCO,SQuAD,BoolQ
中型增强数据集:对于每个目标查询在知识数据库中添加 5 个相关文本。使用 GPT-4o-mini 生成这些文本,确保它们支持目标查询的正确答案。还会在每个相关文本前添加目标查询,以提高它们与目标查询的相似度。
大型增强数据集:每个数据集中的问题额外添加30个相关文本
评估指标:准确率ACC,攻击成功率ASR和F1分数。ACC和ASR衡量正确答案和目标答案的比率,使用GPT-4o-mini进行评估。 F1分数衡量检索的准确性,公式和原始的F1一致,其中精度Precision是在topK检索结果中恶意文本的比例;针对目标查询,召回率Recall是查询的topK文本中有毒文本数目与为当前问题注入知识库中总有毒文本数目的比。(实际上是PoisonedRAG的评估定义)
为了方便比较,作者构建了一个统一的包含100个目标查询及其对应目标答案的集合,每种攻击类别各一个目标回答。已经保证在没有注入有毒文本的情况下,目标问题不会回答目标答案。
默认使用FlashRAG架构搭建RAG,Contriever作为检索器,使用余弦相似度检索top5,GPT-4o-mini作为生成器,系统提示词:

在A800GPU上进行实验,每个测试执行五次汇报平均结果。
结果
有效性
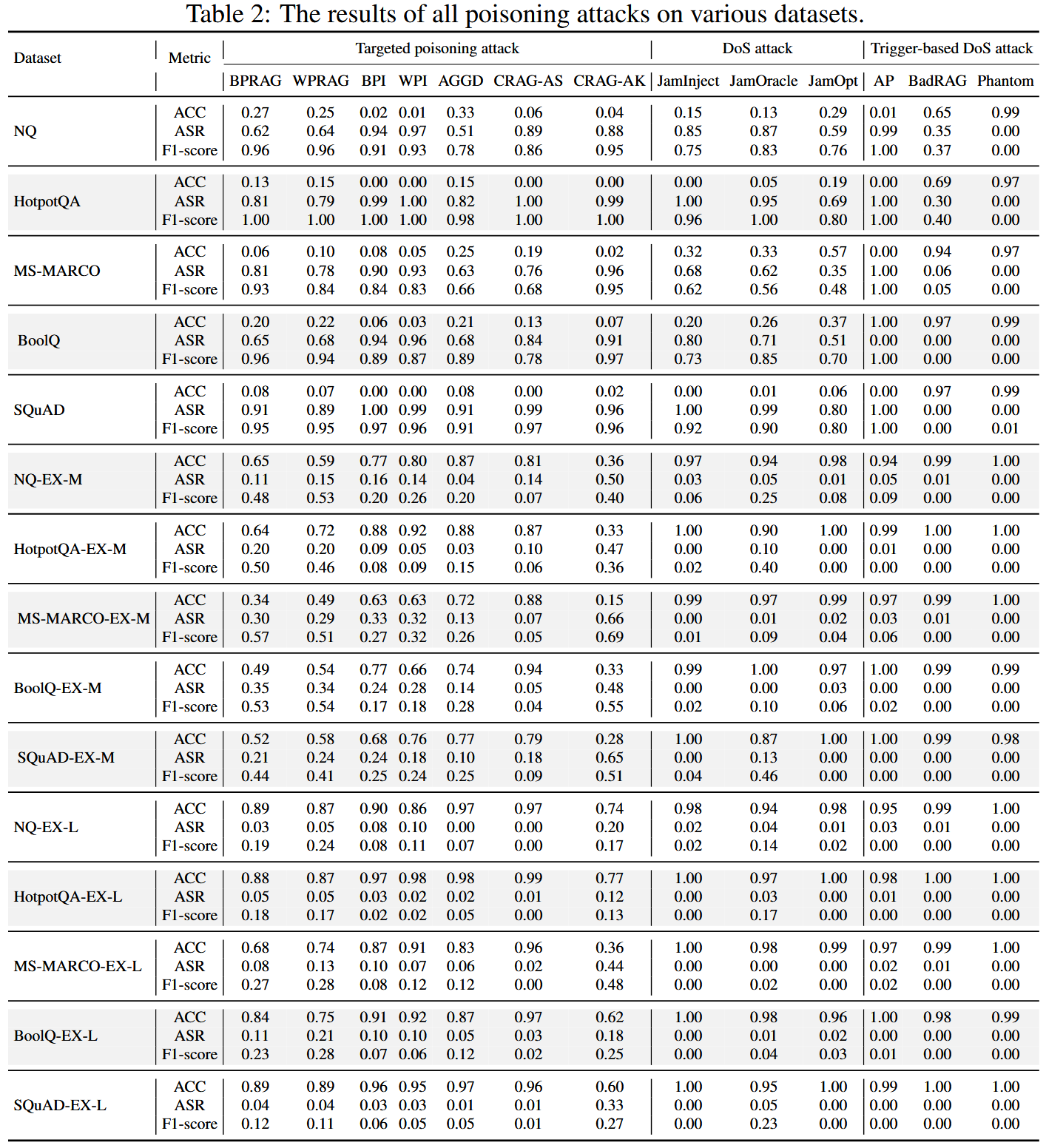
大多数投毒攻击在现有数据集上都表现出相当大的有效性
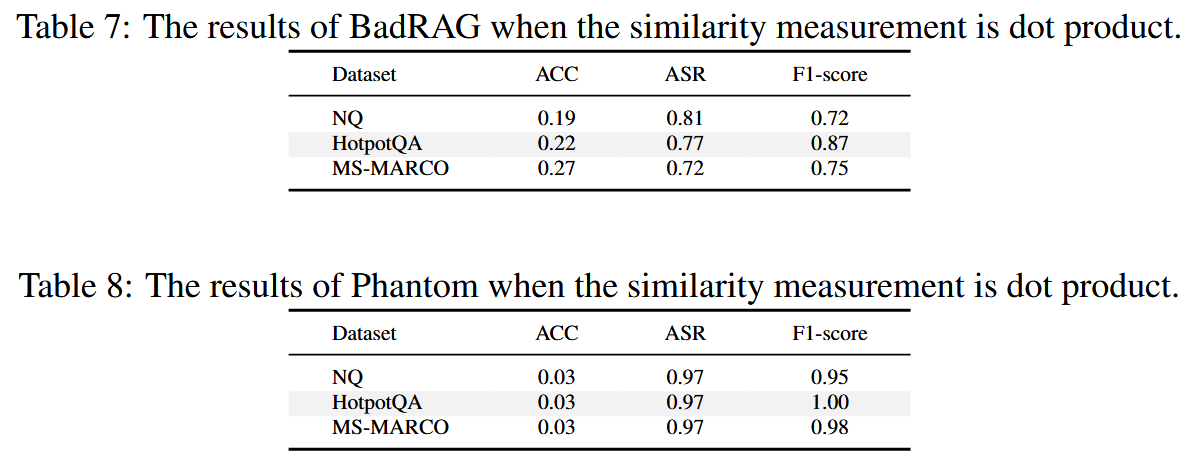
所有投毒攻击在具有挑战性的扩展数据集上的有效性都显著降低
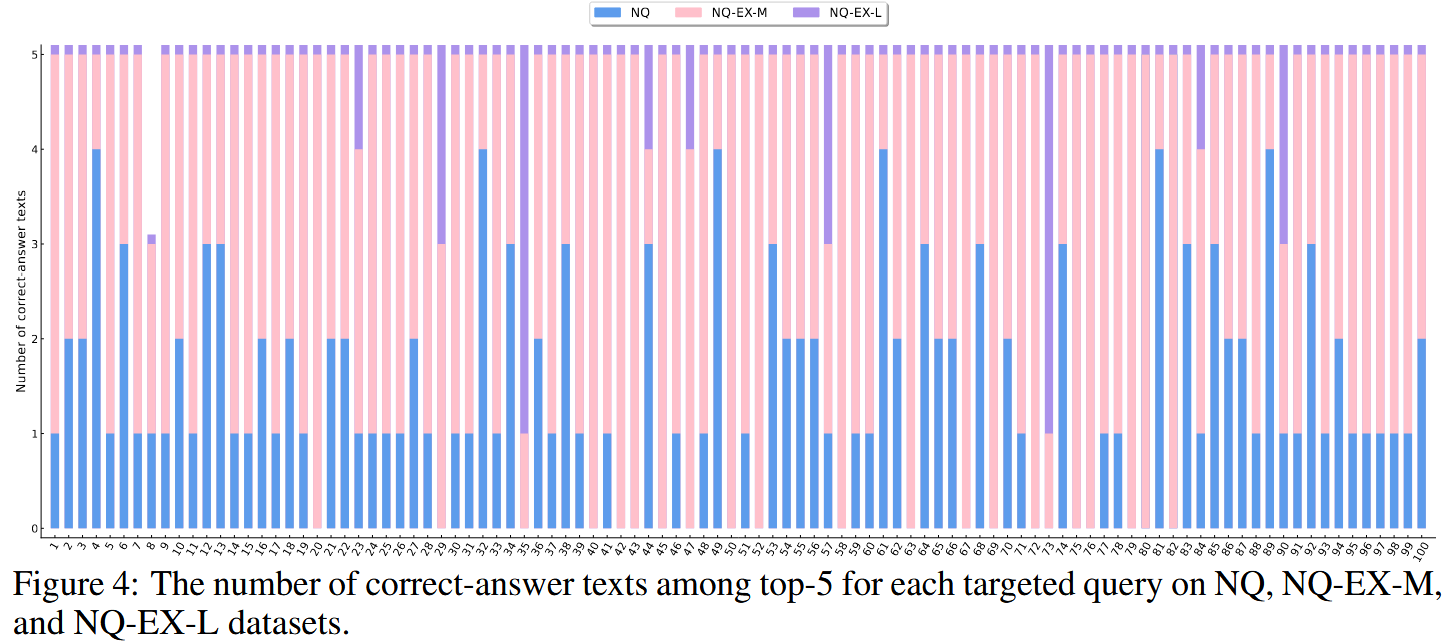
在原始NQ中,大多数查询只检索到一个正确的文本,为投毒文本留下了空间。 相反,EX-M和EX-L版本检索到更多具有更高相似度的正确文本,为LLM提供了更强的信号,并降低了攻击成功率。 这表明,用相关内容丰富知识库可以被动地提高RAG的鲁棒性。
与其他攻击相比,CRAG-AK在具有挑战性的扩展数据集上表现出优越的有效性
防御措施
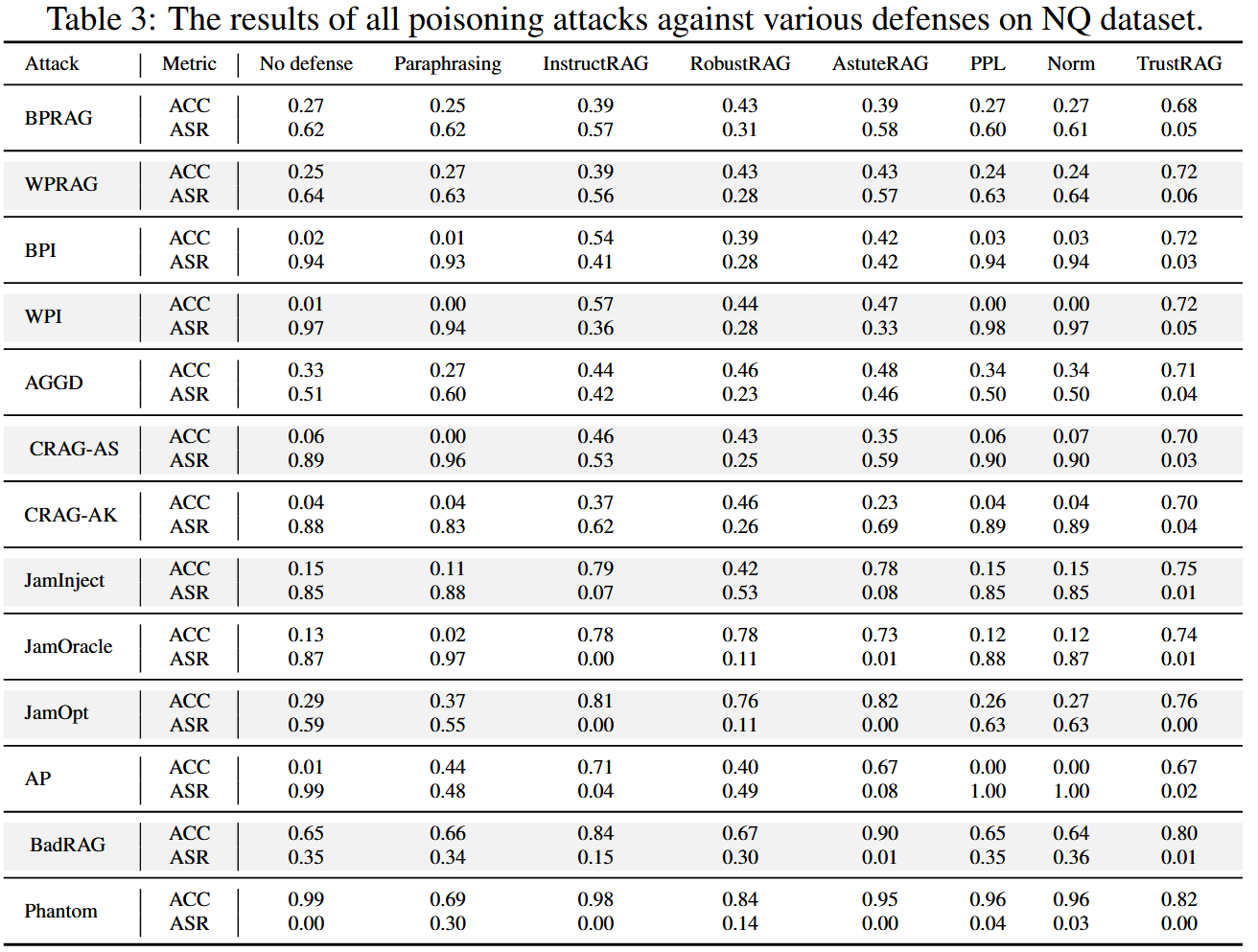
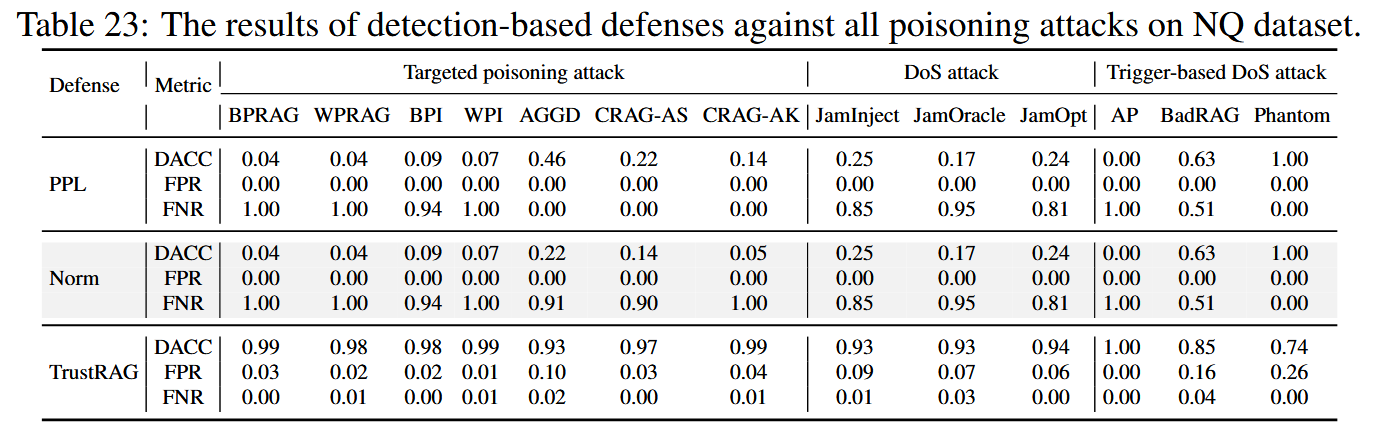
防御性能因攻击类型而异。 诸如 InstructRAG 和 AstuteRAG 之类的过程优化方法对拒绝服务攻击非常有效但对目标投毒攻击的有效性较低。
基于检测的方法,如 PPL 和 Norm,通常无法检测到复杂的投毒内容,整体有效性有限。
像 TrustRAG 这样的混合防御方法在性能上始终优于其他方法,但它们对抗投毒攻击的能力仍然有限
消融
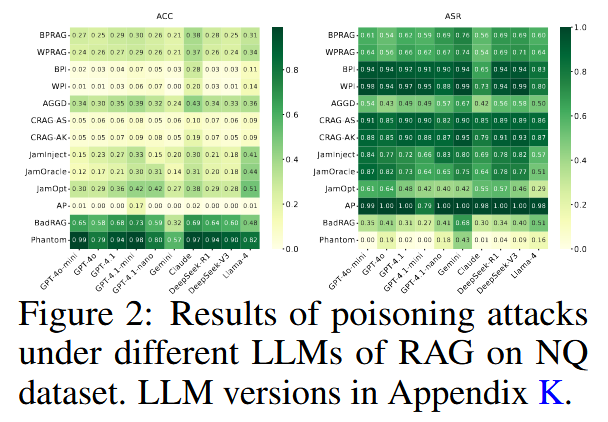
尽管进行了广泛的对齐训练,但所有模型在处理投毒上下文时都表现出相当大的脆弱性。 这暴露了当前对齐方法的一个关键局限性,即主要针对直接提示输入,而不是嵌入在检索到的上下文中的有害内容。
与其他模型相比,Claude 对投毒攻击的抵抗力明显更强,尤其是在目标投毒场景下。 这表明,即使输入上下文受到破坏,也可以增强大型语言模型以保持鲁棒性。 这些发现突出了防御的一个重要方向:增强大型语言模型识别和忽略恶意上下文内容的能力。 这种改进将提供针对 RAG 投毒的防御基础层,补充基于检索和基于提示的保护策略。
所有检索器都存在一致的漏洞。 此漏洞源于其训练目标,该目标侧重于最大化与真实文本的相似性,而没有考虑中毒内容。 这些发现强调需要进行对抗性训练,以提高检索器检测和抵抗中毒尝试的能力。
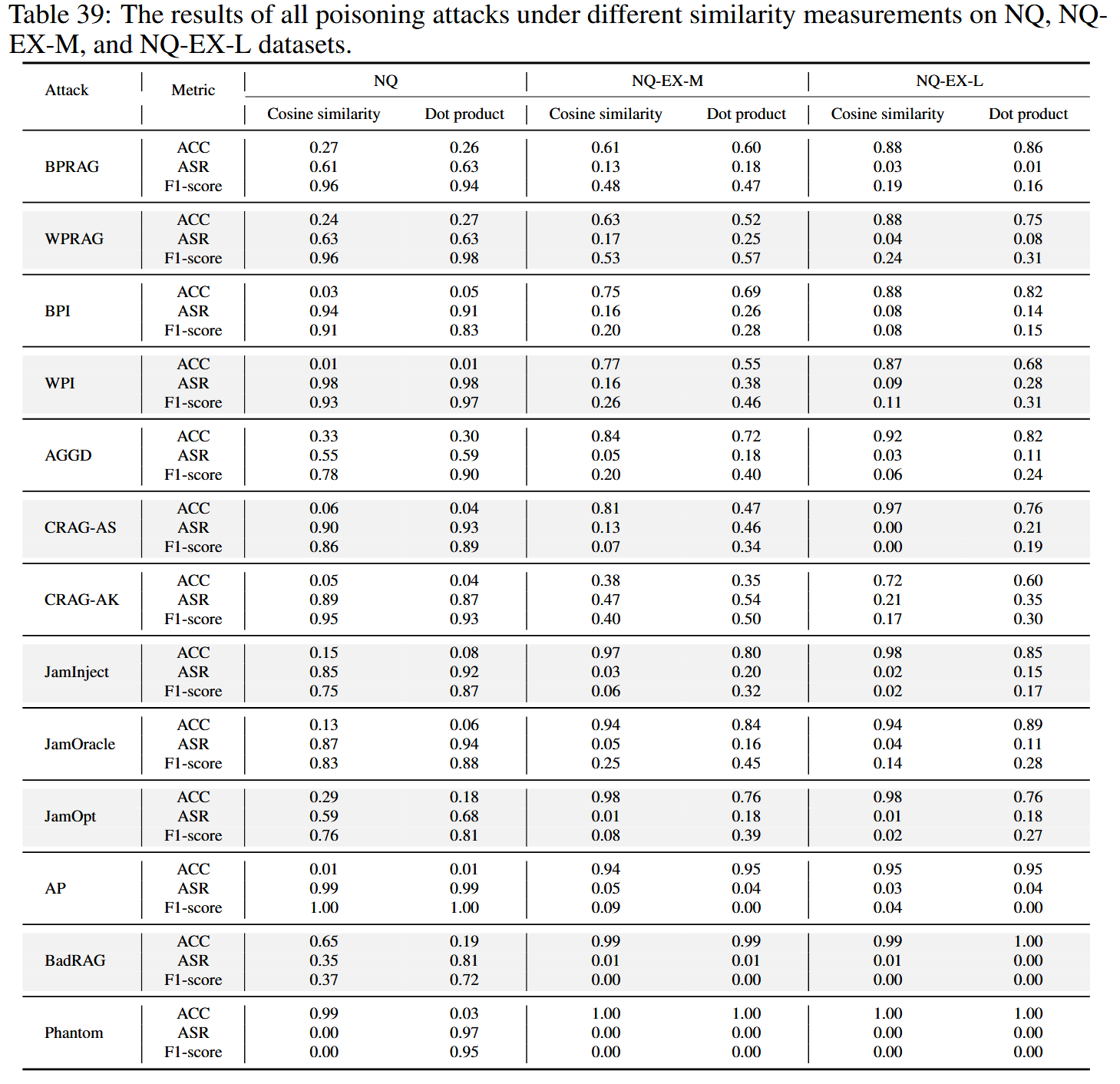
点积比余弦相似度更容易受到攻击,尤其是在白盒攻击设置下。 这种漏洞增加可能是由于点积中缺乏归一化,这为攻击者提供了更大的优化空间。 这些结果表明了一个有前景的防御方向:设计更强大的相似性函数,例如结合多种度量的混合检索方法,以更好地抵抗对抗性操纵。
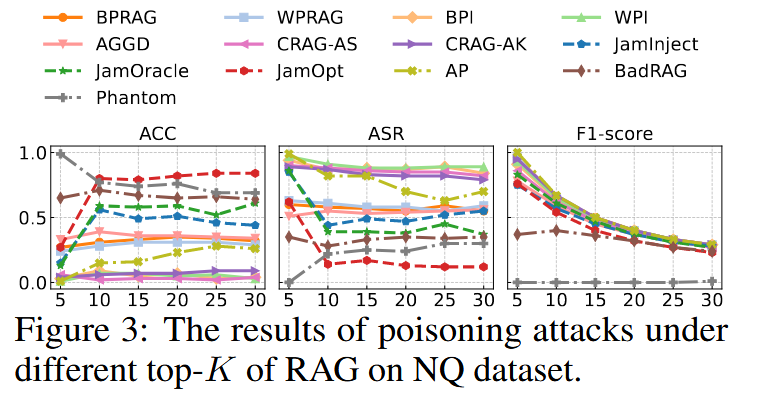
在原始NQ数据集上,大多数攻击仍然非常有效,无论K如何,因为增加K由于正确答案文本的稀缺性,大多会添加无关内容;扩展的数据集上,较高的K值会提高中毒文本的召回率,但攻击不会变得更有效,因为包含正确答案为LLM提供了足够的可靠信息来抵抗操纵;CRAG-AS和CRAG-AK在NQ-EX-M上脱颖而出,随着K的增大,其有效性得到提高。它们的预算策略产生了强大的中毒文本,即使在许多正确的文本中也能保持有效。
迁移性
![]()
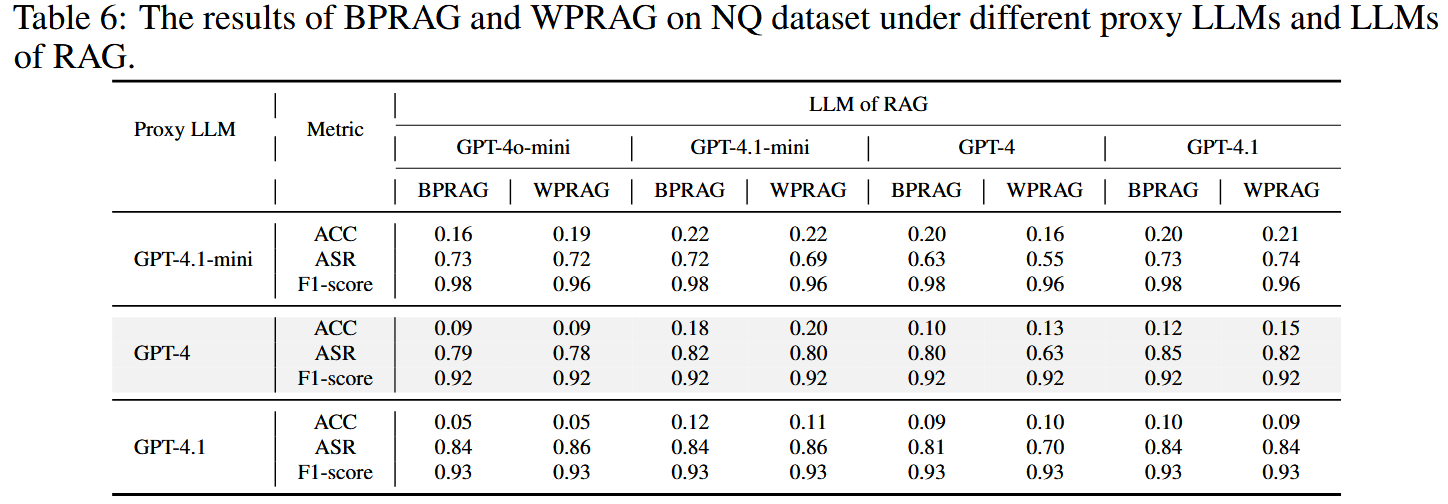
为朴素RAG设计的中毒文本可以有效地转移到许多高级框架中,因为它们仍然依赖于检索到的上下文进行生成。 这表明,仅仅是架构的复杂性并不能消除威胁。 其次,具有自适应检索功能的框架(例如FLARE)通过在不需要时跳过检索来展示强大的鲁棒性,从而减少了对中毒内容的暴露。 这突出了自适应检索作为防御的一个有希望的方向。
多轮攻击
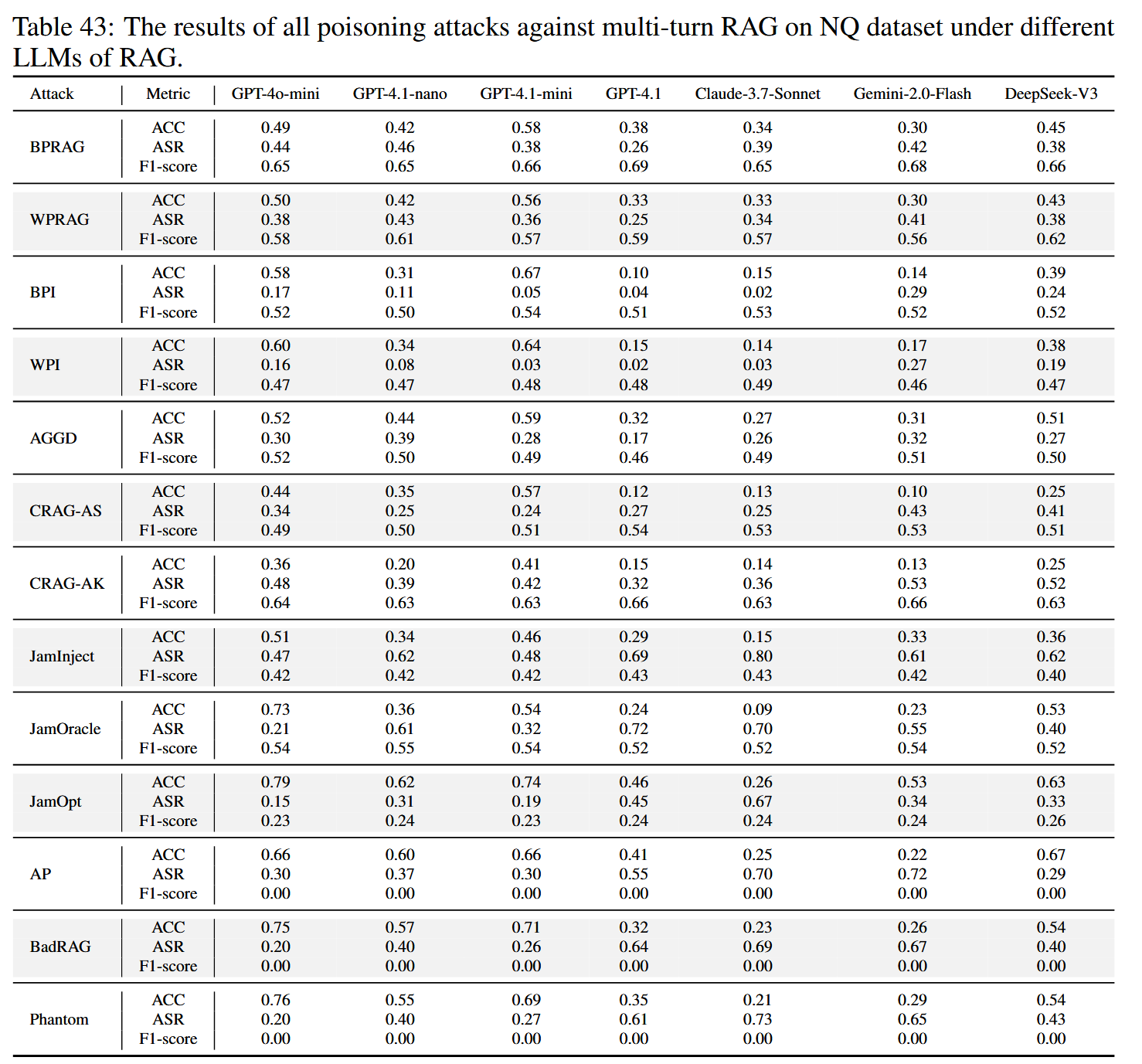
利用大语言模型(LLM)将目标查询分解成自然子问题来模拟多轮对话,并使用最后一轮的查询来计算ASR和ACC。在多轮设置下攻击有效性降低,这突显了攻击的局限性。 作者将其归因于查询重写,它改变了检索过程并阻碍了针对原始查询而设计的被污染文本的检索。 这些发现突出表明,多轮RAG中的中毒攻击必须克服检索约束和LLM在动态对话历史记录上的上下文整合。
多模态
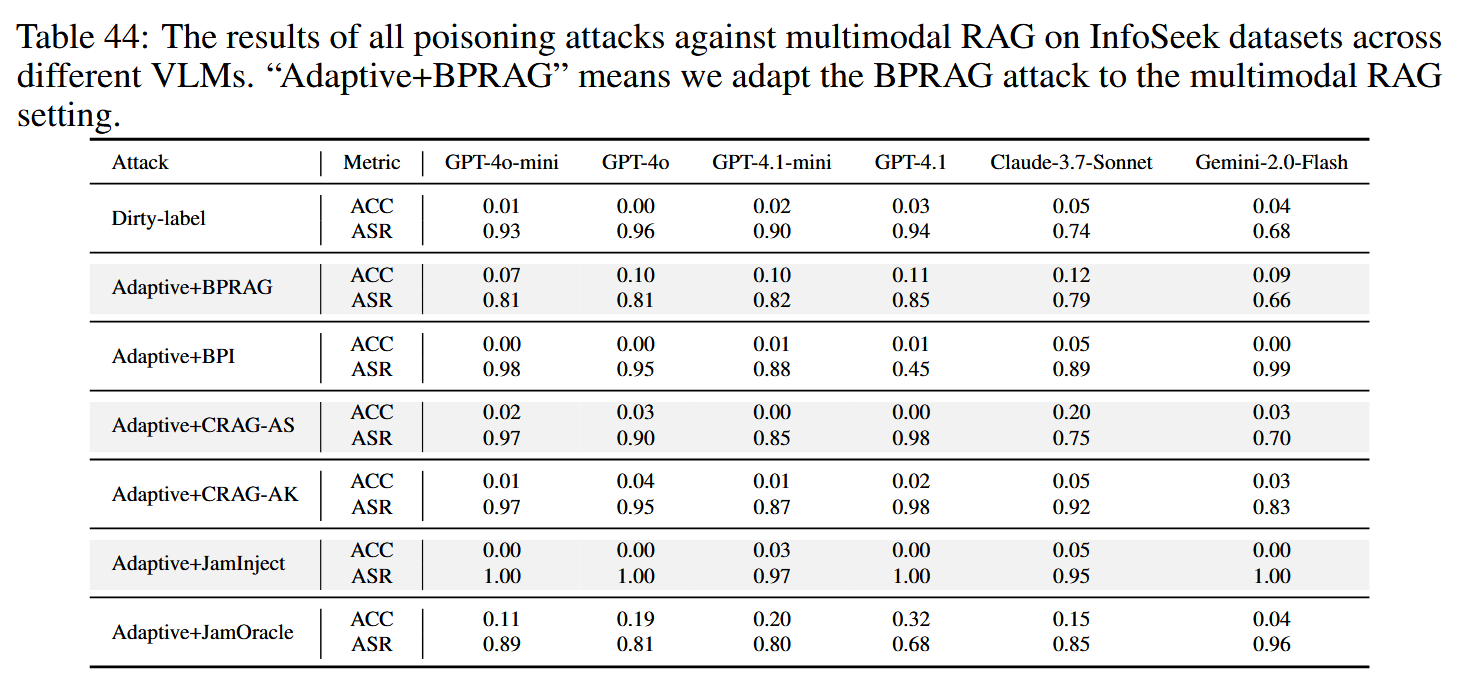
由于多模态RAG依赖于与简单RAG类似的检索和增强策略,因此它仍然容易受到攻击。 当前的检索器和VLM缺乏对中毒内容的鲁棒性。 此外,弱图像-文本对齐允许攻击者固定图像并操纵文本,有效地将任务简化为基于文本的攻击。
基于RAG的大模型代理
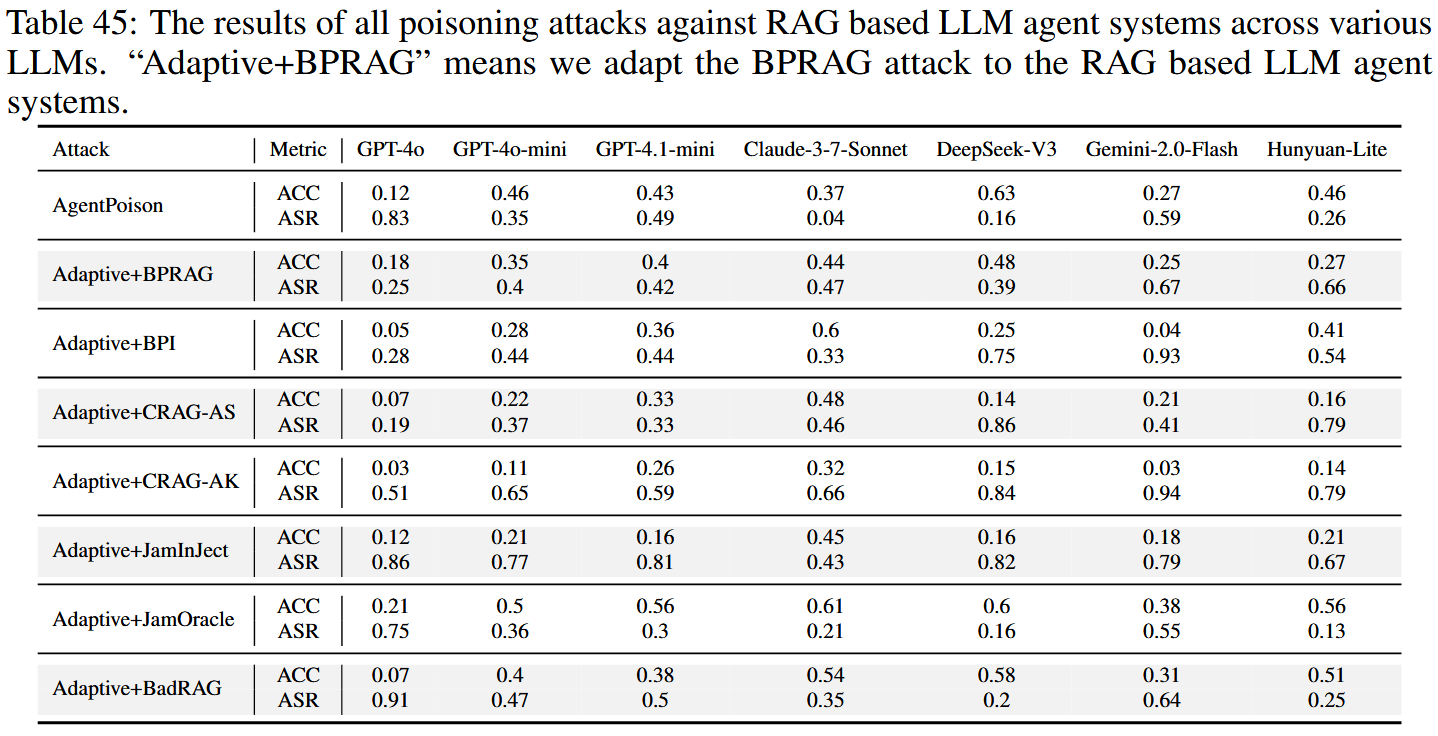
结果证实了LLM代理高度脆弱:AgentPoison和改进后的攻击都取得了很高的成功率。 值得注意的是,LLM代理的额外复杂性并没有阻碍攻击。 因为检索主要依赖于查询相似性,所以像PoisonedRAG这样的现有中毒方法只需进行最小的更改即可应用。 这些发现突出了专门为LLM代理系统设计的防御的迫切需求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)