SE注意力机制
论文来源:https://arxiv.org/pdf/1709.01507计算流程:当数据传入后,兵分两路进行数据计算,最后对各通道中数据乘对应权重完成通道注意力。
·
一、注意力机制
论文来源:https://arxiv.org/pdf/1709.01507
计算流程: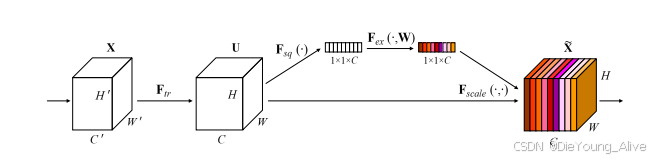
当数据传入后,兵分两路进行数据计算,最后对各通道中数据乘对应权重完成通道注意力。
注意事项:
注意力机制中采用AdaptiveAvgPool2d(1) 进行通道中数据降维操作,同时采用Relu函数进行激活。当Relu函数通道维度较低时,容易造成不可逆数据丢失。
因此在采用通道注意力机制时,应该尽可能保持中间层通道数大于30,保证中间层采用Relu函数进行激活后,不会造成信息数据丢失。
class SENET(nn.Module):
def __init__(self,inchannels,ratio = 16): # 同时需要修改 ratio 缩放因子 ,保持 模型通道数最少为32通道
super(SENET,self).__init__()
# 定义初始变量
self.inchannels = inchannels
self.ratio = ratio # 自定义缩放因子 == 减少参数量 == 同时防止过拟合
self.sq = nn.AdaptiveAvgPool2d(1) # 自适应平均池化 1*1
# TODO:注意事项
# medio = max(inchannels//ratio,32) # 缩放因子最小为32 # 可以采用 medio替代 inchannels//ratio 保证中间层数据维度满足relu激活函数要求
self.ex = nn.Sequential(
nn.Linear(self.inchannels,self.inchannels//self.ratio) , # 依据全连接层生成动态权重进行后续权重优化,
nn.ReLU(inplace=True),
nn.Linear(self.inchannels//self.ratio,self.inchannels) , # 保持输入 输出维度不变 == 中间层 为输入,
nn.Softmax(),
)
def forward(self,x):
identity = x
x = self.sq(x)
x = x.view(x.size(0),-1)
x = self.ex(x)
x = x.unsqueeze(2).unsqueeze(3) # 对x进行升维操作,[1,512] ==> [1,512,1,1]
return identity * x

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)