【时间序列预测】From Similarity to Superiority: Channel Clustering for Time Series Forecasting
时间序列预测中,通道独立(CI)策略通过单独处理不同通道提升性能,但泛化能力差且忽视通道交互;通道依赖(CD)策略将所有通道混合,但导致过平滑问题。针对此,我们开发了基于内在相似性的通道聚类模块(CCM),动态分组通道并结合分组信息,兼顾CI和CD的优点。实验表明,CCM可显著提升长期和短期预测性能(CI模型平均提升2.4%,CD模型平均提升7.2%),实现零点预测,并有效挖掘时间序列的内在相似性
文章目录
1. 文章介绍

-
论文出处:NeurIPS 2024(CCF-A)
-
【摘要】:近几十年来,时间序列预测备受关注。以往的研究表明,通道独立(CI)策略通过单独处理不同的通道来提高预测性能,但会导致对未见实例的泛化效果不佳,并忽略通道间潜在的必要交互作用。相反,通道依赖(CD)策略将所有通道与甚至不相关和不加区分的信息混合在一起,但这会导致过平滑问题,限制预测的准确性。目前还缺乏一种通道策略,既能有效平衡各个通道的处理方法,提高预测性能,又不会忽略通道之间的基本互动。我们观察到时间序列模型对通道混合的性能提升与一对通道的内在相似性之间存在相关性,受此启发,我们开发了一种新颖且适应性强的通道聚类模块(CCM)。CCM 以内在相似性为特征对通道进行动态分组,并利用分组信息而不是单个通道身份,从而将 CD 和 CI 的优点结合起来。在真实世界数据集上进行的大量实验证明,CCM 可以:(1)在长期和短期预测方面,将 CI 和 CD 模型的性能分别平均提高 2.4% 和 7.2%;(2)利用主流时间序列预测模型实现零点预测;(3)发掘时间序列的内在相似性。
2. 拟解决的问题
- 如何结合通道独立和通道依赖这两种策略
3. 问题定义
-
时间序列预测:令 X = [ x 1 , … , x T ] ∈ R T × C X = [x_1, \dots, x_T] \in \mathbb{R}^{T \times C} X=[x1,…,xT]∈RT×C 为一个时间序列,其中 T T T 是历史数据的长度。 x t ∈ R C x_t \in \mathbb{R}^C xt∈RC表示时间 t t t的观测值, C C C 表示变量的数量(即通道数)。时间序列预测的目标是构建一个预测模型 f f f,用于估计该序列的未来值 Y = [ x ^ T + 1 , … , x ^ T + H ] ∈ R H × C Y = [\hat{x}_{T+1}, \dots, \hat{x}_{T+H}] \in \mathbb{R}^{H \times C} Y=[x^T+1,…,x^T+H]∈RH×C,其中 H H H 是预测范围。我们用 X [ : , i ] ∈ R T X[:,i] \in \mathbb{R}^T X[:,i]∈RT(为简化起见写作 X i X_i Xi)表示时间序列中的第 i i i 通道。
-
通道独立(Channel Independent, CI):CI策略分别建模每个通道 X i Xi Xi,并忽略任何潜在的跨通道交互作用。这种策略通常表示为函数 f ( i ) : R T → R H f^{(i)}: \mathbb{R}^{T} → \mathbb{R}^{H} f(i):RT→RH,其中 i = 1 , . . . , C i = 1, ..., C i=1,...,C,并且 f ( i ) f^{(i)} f(i) 特别针对第 i i i 个通道。
-
通道依赖(Channel Dependent, CD):CD策略将所有通道作为一个整体进行建模,使用一个函数 f : R T × C → R H × C f: \mathbb{R}^{T\times C} → \mathbb{R}^{H\times C} f:RT×C→RH×C。
4.方法动机
-
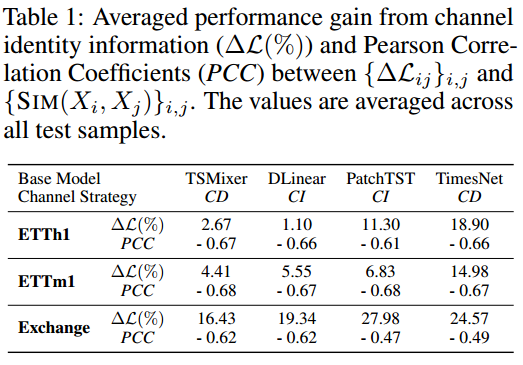
论文选取了四个基线模型进行实验:1)在所有通道上训练时间序列模型,并评估测试集上的通道平均平方误差 (MSE) 损失;2)在训练模型的同时在每个批次中随机调整通道。这意味着对于 CD 和 CI 模型,通道身份信息将被移除。基于径向基核函数的通道相似度定义(值越大,越相似):
S I M ( X i , X j ) = exp ( − ∥ X i − X j ∥ 2 2 σ 2 ) , (1) SIM(X_i, X_j) = \exp\left(-\frac{\|X_i - X_j\|^2}{2\sigma^2}\right)\text{ ,\qquad(1)} SIM(Xi,Xj)=exp(−2σ2∥Xi−Xj∥2) ,(1) -
下表说明了两个结论:
- 现有的预测方法严重依赖通道身份信息。解释:在对通道进行shuffle后,破坏了通道之间的相关性。通过计算每个通道的MSE(其平均MSE结果表示为 Δ L \Delta \mathcal{L} ΔL),可以看到所有的模型 Δ L \Delta \mathcal{L} ΔL都上升了;
- 这种依赖性与通道相似度不相关。解释:通过皮尔森相关性系数PCC度量 { Δ L i j } i , j 和 { S I M ( X i , X j ) } i , j \{\Delta L_{ij}\}_{i,j} 和\{SIM(X_i, X_j)\}_{i,j} {ΔLij}i,j和{SIM(Xi,Xj)}i,j之间的相关性,从表中可以看到,所有的PCC值在-0.5左右,相关性较小,表明通道 i i i和 j j j之间的相似性和排序后引起的通道 i i i和 j j j之间的mse差值的绝对值之间相关性较小。对于相似性高的信道,信道身份信息就不那么重要了。
5. 主要贡献
-
提出了一种新颖、统一的通道混合策略,即 CCM,实现通道独立和跨通道建模之间的最佳权衡
-
通过从聚类中学习原型,CCM 可以在单变量和多变量情况下对未见样本进行零次预测
6. 方法
- 模型结构:现有的时间序列模型通常由三个核心部分组成:(1)可选的归一化层(如RevIN);(2)以线性层、基于Transformer或卷积为backbone的时序模块;(3)预测未来值的前馈层。本文提出的CCM在时序模块之前加入了聚类分配器,然后是聚类感知前馈层。聚类分配器根据内在相似性实现通道聚类,并采用交叉关注机制为每个聚类生成原型,从而存储来自训练集的知识,并赋予模型零点预测能力。
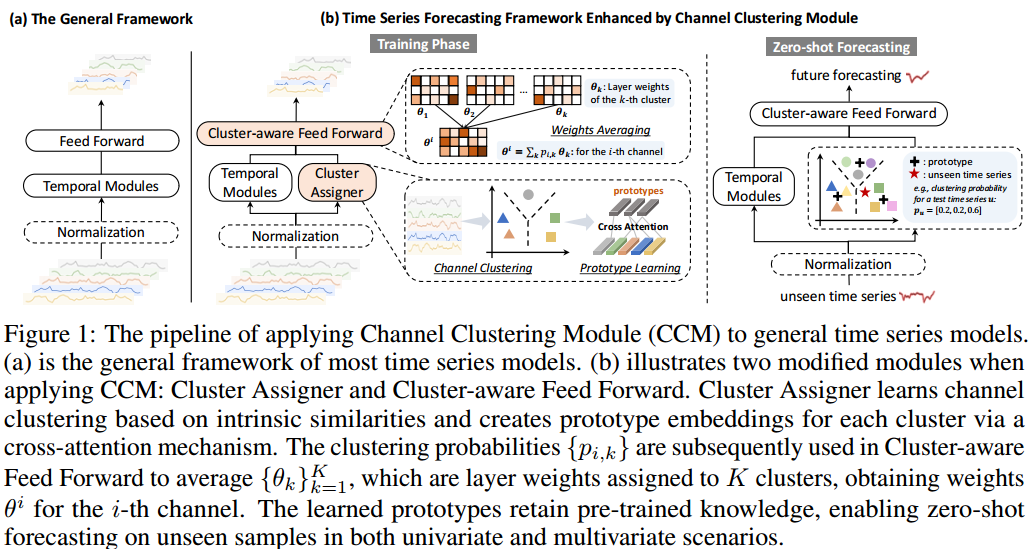
- 算法流程:

6.1通道聚类模块
6.1.1通道聚类
-
首先初始化K个类簇嵌入 { c 1 , . . . , c K } \{c_1,...,c_K\} {c1,...,cK},其中 c k ∈ R d c_k \in \mathbb{R}^d ck∈Rd, d d d为隐藏层维度, K K K为超参数
-
然后,给定一条多变量时间序列$X\in\mathbb{R}^{T\times C} , 每一个通道的输入 ,每一个通道的输入 ,每一个通道的输入X_i 通过 M L P 映射成 通过MLP映射成 通过MLP映射成d 维的嵌入 维的嵌入 维的嵌入h_i$
-
于是通道 X i X_i Xi属于第 k k k个类簇的概率值 p i , k p_{i,k} pi,k可表示为:
p i , k = N o r m a l i z e ( c k ⊤ h i ∥ c k ∥ ⋅ ∥ h i ∥ ) ∈ [ 0 , 1 ] . (2) p_{i,k}= Normalize(\frac{\mathbf{c}_k^\top \mathbf{h}_i}{\|\mathbf{c}_k\| \cdot \|\mathbf{h}_i\|}) \in [0, 1]\text{ .\qquad(2)} pi,k=Normalize(∥ck∥⋅∥hi∥ck⊤hi)∈[0,1] .(2)
- 最后,采用重参数化技巧获得聚类成员矩阵 M ∈ R C × K M \in \mathbb{R}^{C\times K} M∈RC×K,其中 M i k ≈ B e r n o u l l i ( p i , k ) M_{ik} \approx Bernoulli(p_{i,k}) Mik≈Bernoulli(pi,k)
6.1.2原型学习
- 为了强调簇内通道并消除簇外通道信息的干扰,设计了一种改进的交叉注意方法,公式表示如下:
C ^ = N o r m a l i z e ( exp ( ( W Q C ) ( W K H ) ⊤ d ) ⊙ M ⊤ ) W V H , (3) \widehat{\mathbf{C}}=\mathrm{Normalize}\left(\exp(\frac{(W_Q\mathbf{C})(W_K\mathbf{H})^\top}{\sqrt{d}})\odot\mathbf{M}^\top\right)W_V\mathbf{H}\text{ ,\qquad(3)} C =Normalize(exp(d(WQC)(WKH)⊤)⊙M⊤)WVH ,(3)
其中,聚类成员矩阵 M M M是一个近似二进制矩阵,以便对类内的通道进行稀疏关注, W Q W_Q WQ、 W K W_K WK和 W V W_V WV 是可学习参数。原型嵌入 C ^ ∈ R K × d \hat{C}∈\mathbb{R}^{K×d} C^∈RK×d 作为更新的聚类嵌入
6.1.3聚类损失
-
为了最大化通道中类内一致性和不同类之间的差异性,设计了以下聚类损失:
L C = − Tr ( M ⊤ S M ) + Tr ( ( I − M M ⊤ ) S ) , (4) \mathcal{L}_C=-\operatorname{Tr}\left(\mathbf{M}^\top\mathbf{SM}\right)+\operatorname{Tr}\left(\left(\mathbf{I}-\mathbf{MM}^\top\right)\mathbf{S}\right)\text{ ,\qquad(4)} LC=−Tr(M⊤SM)+Tr((I−MM⊤)S) ,(4)
其中, S ∈ R C × C S\in \mathbb{R}^{C\times C} S∈RC×C为通道相似矩阵, T r Tr Tr为迹操作 -
由于CCM是一个即插即用的模块,因此该聚类损失可以与任意模型进行结合,总的损失函数表达为 L = L F + β L C \mathcal{L}=\mathcal{L}_F+\beta\mathcal{L}_C L=LF+βLC,其中 L F \mathcal{L}_F LF为总的预测损失。
6.2聚类前向层
-
与现有方法不同,本文针对特征序列的时间依赖性建模采用了新的前馈网络架构设计。具体而言,CI对每个通道采用独立的前馈层,而CD则采用跨通道共享单一前馈层;本文为每个通道群分配独立的前馈层,从而更精准地捕捉到类内部隐藏的时间序列模式。
-
令 h θ k ( ⋅ ) h_{\theta_k}(·) hθk(⋅)为带有权重参数 θ k \theta_k θk的第 k k k个类的线性前向层, Z i Z_i Zi为第i个通道的隐层嵌入,则第 i i i个通道的最终的预测结果表示为 Y i = ∑ k p i , k h θ k ( Z i ) Y_i=\sum_kp_{i,k}h_{\theta_k}(Z_i) Yi=∑kpi,khθk(Zi),为了计算效率,其等价于 Y i = h θ i ( Z i ) Y_i=h_{\theta_i}(Z_i) Yi=hθi(Zi),其中平均权重 θ i = ∑ k p i , k θ k \theta^i=\sum_kp_{i,k}\theta_k θi=∑kpi,kθk
6.3单变量适应
- 方法利用公式 1 中定义的两个单变量时间序列之间的相似性,将具有相似模式的单变量时间序列归入同一聚类。这种单变量适应性使其能够捕捉样本内部的相互关系,并从类似的时间序列中提取有价值的信息。
6.4零样本预测
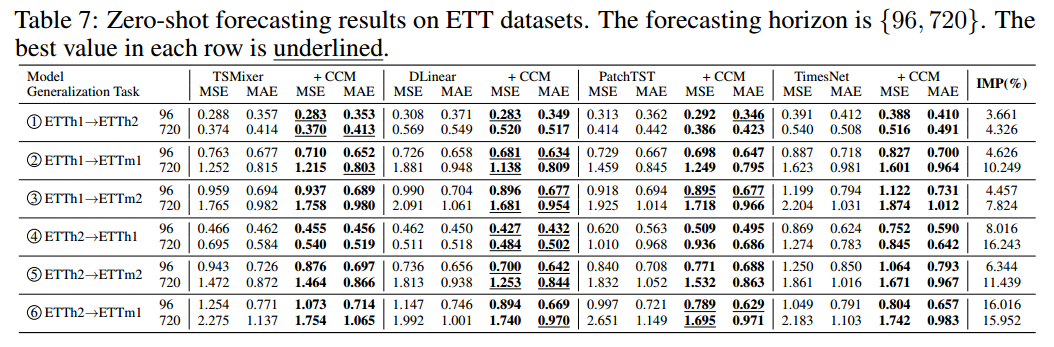
- 在训练阶段获得的原型嵌入是预训练知识的紧凑表示,可用于在零样本预测环境下将知识无缝转移到未见样本或新通道。根据公式 2,通过计算预训练簇上的聚类概率分布,将预训练知识应用于未见实例,随后用于平均聚类感知前馈层。在零次预测中,交叉注意力被禁用,以固定原型嵌入。
7.实验结果
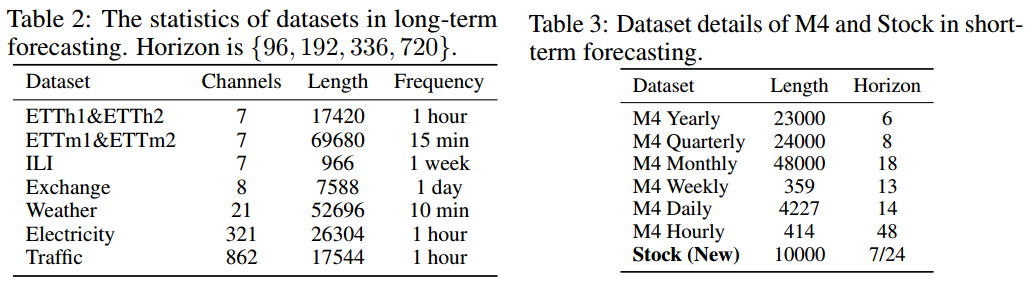
7.1 数据集信息
7.2 对比实验结果
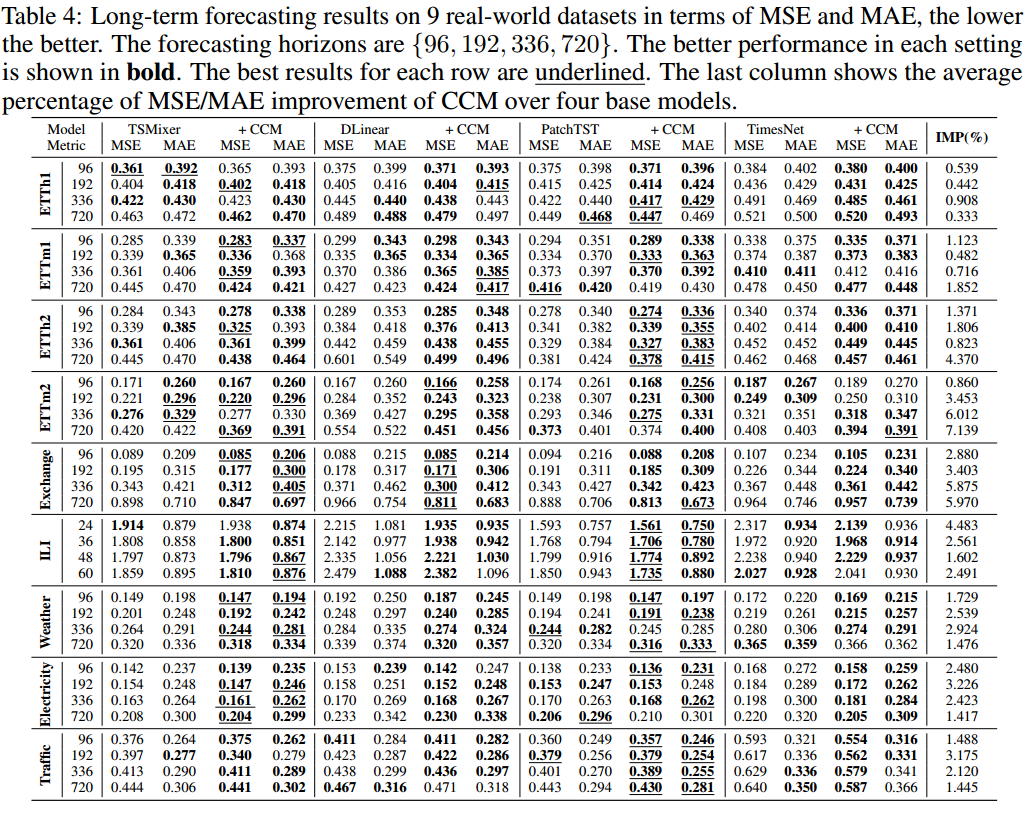
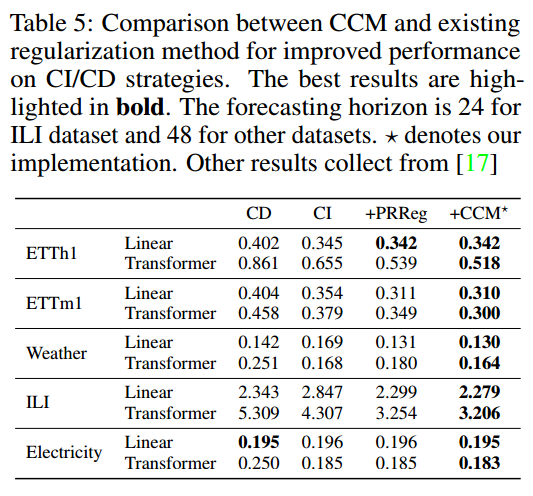
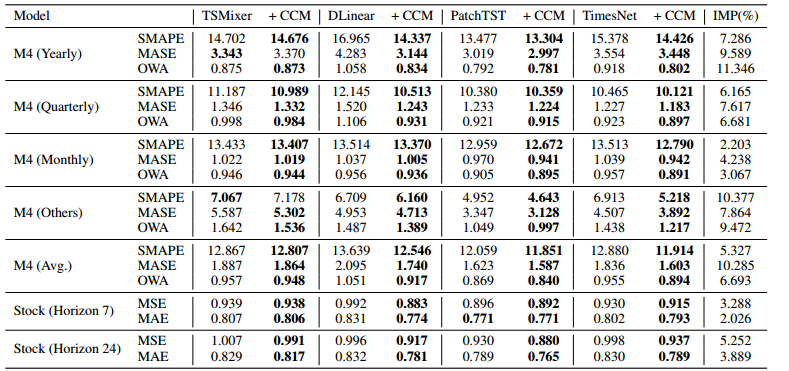
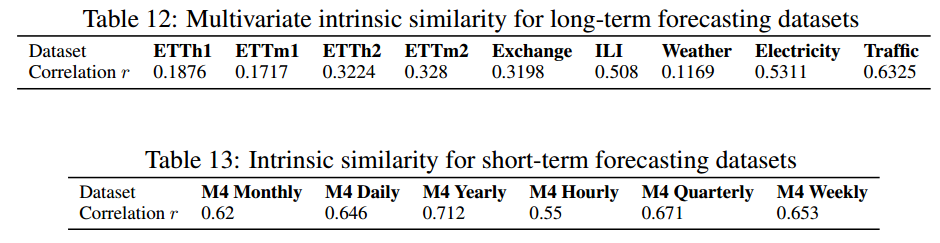
- r 表示多元相关程度。CCM 往往能在通道内具有内在相关性的数据集上实现更大的提升。与用于长期预测的数据集相比,M4 显示出时间序列之间更显著的相关性。因此,在短期预测情况下,捕捉数据集内部的相关性可能比在长期预测情况下更能提高预测性能。
7.3 零样本预测结果
7.4 可视化实验结果
7.4.1通道可视化
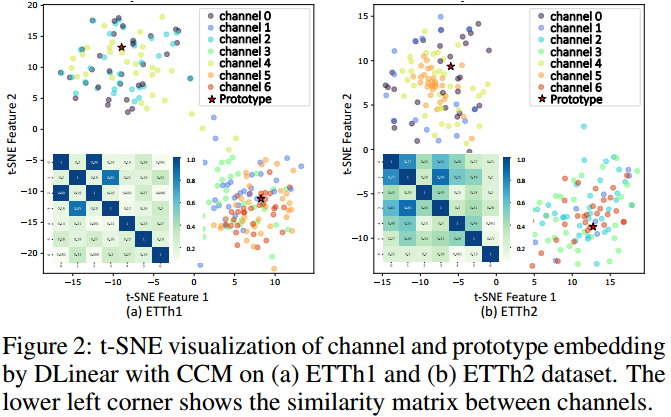
7.4.2权重可视化
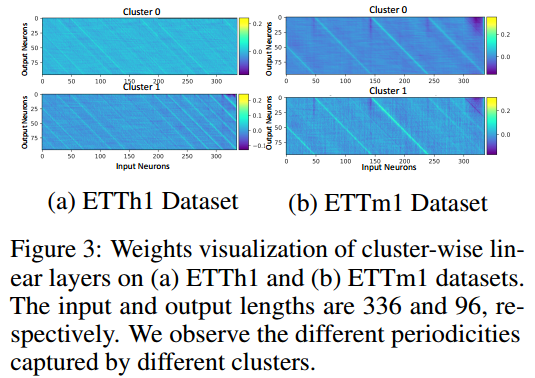
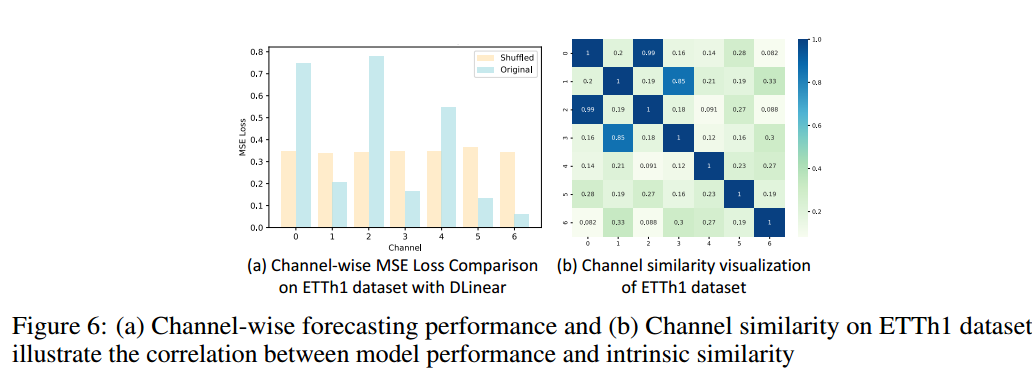
7.4.3相似度可视化
- 当两个通道表现出较高的相似度时,这些通道上的性能也往往具有相应的相似性,例如通道0和2,通道1和3
7.5 参数分析
7.5.1聚类个数分析
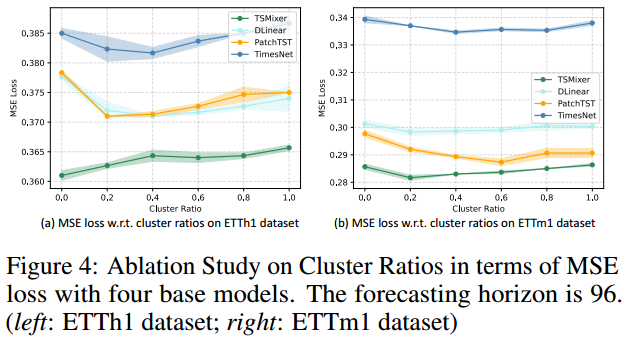
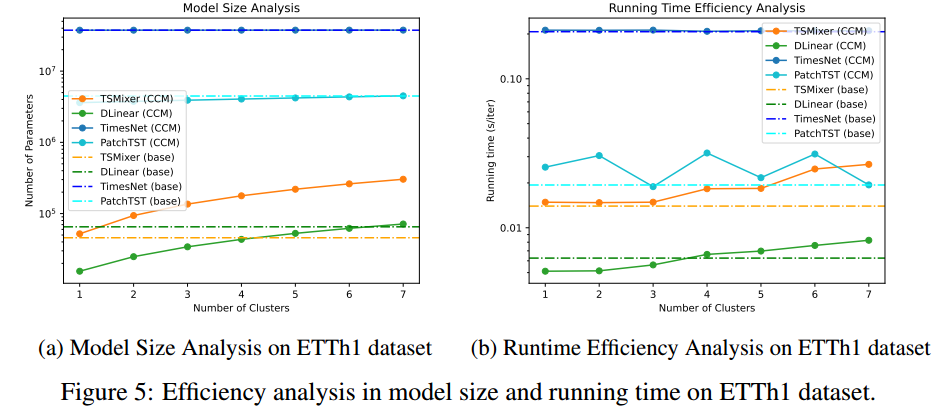
7.5.2计算效率分析
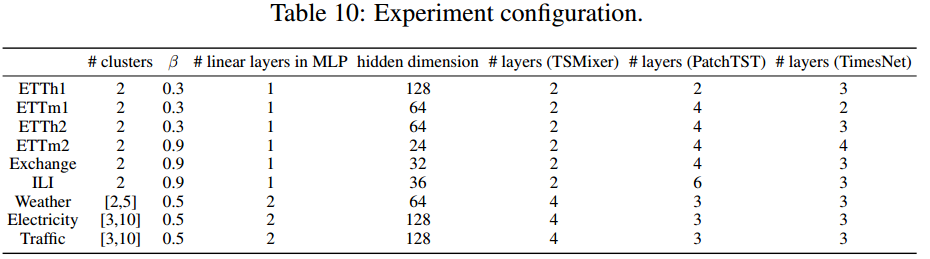
7.5.3超参数配置
7.6消融实验
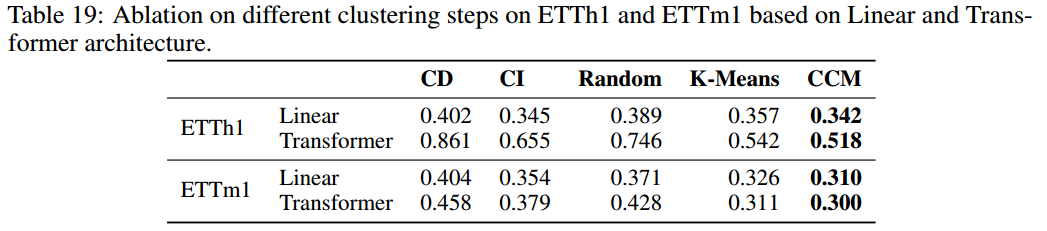
7.6.1聚类模块消融
- Random:将每个通道随机分配到一个聚类中;
- K-Means:使用 K-Means算法来替代聚类步骤;。
- CCM: 本质上是 K-Means 算法的高级变体,具有可学习的原型嵌入和交叉关注机制
8.结论
- 这篇文章为什么能中? 本文提出通过基于注意力的通道聚类方法对通道之间的相关性进行建模,以改进时间序列预测。实验结果证明了所提出的信道聚类方法的有效性。通道聚类方法比较新颖。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)