K近邻算法的实现
K近邻算法的简单性也使得它成为一种常用的分类和回归方法之一,通过计算样本之间的相似度,K近邻算法可以对新样本进行分类或回归预测。其核心思想是:给定一个新实例,通过计算它与训练集中每个实例的距离,找出距离最近的K个邻居,然后根据这些邻居的类别(分类任务)或值(回归任务)来预测新实例的输出。在K近邻算法中,k值的选定是一个重要的参数,它表示用于预测新样本的最近邻居的数量。而对于较大的数据集,选择较大的
目录
一、K近邻算法概述
二、K近邻核心思想
三、K值选择
四、K近邻算法的优势和劣势
五、K近邻算法中常用的距离指标
六、K近邻算法的实现步骤
七、在python中实现
八、总结
一、K近邻算法概述
K近邻算法(K-Nearest Neighbors,KNN)是一种简单的监督学习算法,用于分类和回归。其核心思想是:给定一个新实例,通过计算它与训练集中每个实例的距离,找出距离最近的K个邻居,然后根据这些邻居的类别(分类任务)或值(回归任务)来预测新实例的输出。
二、K近邻核心思想
K近邻算法基于实例之间的相似度进行分类或回归。其核心思想是,如果一个样本在特征空间中的K个最近邻中的大多数属于某个类别,则该样本也属于该类别。在分类问题中,K近邻算法通过统计K个最近邻中各类别的数量,并选择最多的类别作为预测结果。在回归问题中,K近邻算法通过计算K个最近邻样本的平均值或加权平均值作为预测结果。
三、K值选择
在K近邻算法中,k值的选定是一个重要的参数,它表示用于预测新样本的最近邻居的数量。选择适当的k值对K近邻算法的性能和准确率有着重要影响。通常情况下,k值的选择应该考虑以下几个方面:
(1)数据集的大小:如果数据集较小,选择较小的k值可能更合适,以避免过拟合。而对于较大的数据集,选择较大的k值可能更合适,以充分利用更多的邻居信息。
(2)类别的平衡性:如果不同类别的样本数量差别较大,那么选择较大的k值可能更合适,以避免对少数类别的过度依赖。而对于类别较为平衡的数据集,选择较小的k值可能更合适。
(3)噪声和异常值:如果数据集中存在噪声或异常值,选择较大的k值可以降低它们对分类结果的影响。
所以一般k值较小;k通常取奇数,避免产生相等占比的情况。
四、K近邻算法的优势和劣势
K近邻(KNN)算法优点
简单直观:KNN算法的原理易于理解和实现,无需复杂的数学推导。
无需训练:KNN是一种懒惰学习算法,没有显式的训练过程,直接使用训练数据进行预测。
适应性强:可以处理非线性数据,适用于多分类问题。
对数据的分布假设少:不要求数据符合特定的统计分布,适用于各种类型的数据。
K近邻(KNN)算法缺点
对内存要求较高,因为该算法存储了所有训练数据
预测阶段可能很慢
对不相关的功能和数据规模敏感
五、K近邻算法中常用的距离指标
在K近邻算法中,距离向量是用于衡量样本之间的相似度或距离的向量。常用的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离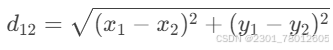
两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…x2n)间的欧式距离

曼哈顿距离:KNN算法通常的距离测算方式为欧式距离和曼哈顿距离,相比之下欧氏距离会更常用欧式距离公式 六. K近邻算法的实现步骤
六. K近邻算法的实现步骤
1.加载数据集:从文件或其他数据源中加载训练数据。
2.数据预处理:对数据进行清洗、去除异常值、归一化等处理,以便更好地应用算法。
3.计算距离:对于给定的未知样本,计算它与训练集中每个样本的距离,常用的距离度量包括欧式距离、曼哈顿距离等。
4.:选择K值:选择K的值,即选择离未知样本距离最近的K个样本。
5.进行分类或回归预测:根据选择的K个样本的标签,进行分类或回归预测。
6.评估模型:使用测试集评估模型的准确率或其他评估指标。
七、在python中实现
1.实现
步骤1:导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
步骤2:创建示例数据集
用make_classification函数生成一个二维的分类数据集,其中包含700个样本,3个特征,每个类别有1个相关特征
X, y = make_classification(n_samples=700, n_features=3, n_informative=1, n_redundant=0, n_clusters_per_class=1, random_state=64)
步骤3:将数据集划分为训练集和测试集,60%的训练集和40%的测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
步骤4:设置K值为3
knn = KNeighborsClassifier(n_neighbors=3)
步骤5:进行拟合
knn.fit(X_train, y_train)
步骤6:对测试数据进行预测
y_pred = knn.predict(X_test)
步骤7:计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
步骤8:绘制散点图
# 绘制散点图
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('每一周打一次篮球')
plt.ylabel('每天喝王老吉')
plt.title('Scatter Plot of Data Set')
整体代码
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成数据集
X, y = make_classification(n_samples=700, n_features=3, n_informative=1, n_redundant=0, n_clusters_per_class=1,
random_state=64)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=64)
# 创建并训练KNN分类器
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 预测测试集结果
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 绘制散点图
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('每一周打一次篮球')
plt.ylabel('每天喝王老吉')
plt.title('Scatter Plot of Data Set')
plt.show()
结果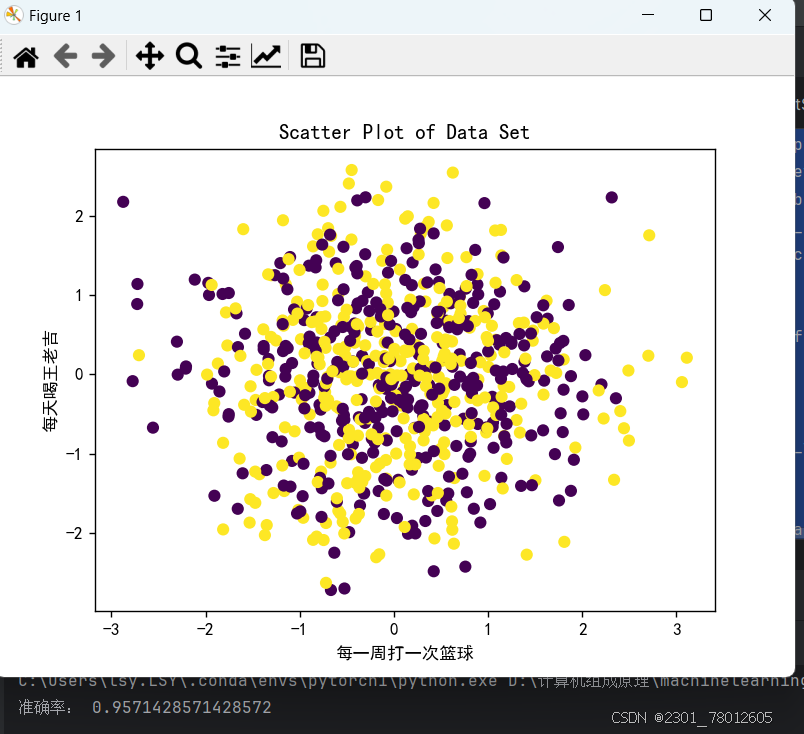
八、总结
从本次实验中,我明白了K近邻算法是一种简单而有效的分类和回归算法。K近邻算法的简单性也使得它成为一种常用的分类和回归方法之一,通过计算样本之间的相似度,K近邻算法可以对新样本进行分类或回归预测。总结起来,K近邻算法的关键是选择合适的k值和距离度量方法。合理选择这些参数,结合适当的特征选择和数据预处理,可以提高算法的准确性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)