跟着李沐老师学习深度学习(十五)
局部最小 vs 全局最小全局最小:局部最小:使用迭代优化算法来求解,一般只能保证找到局部最小值。
·
优化算法
优化问题
-
一般形式:

- 目标函数 f
- 限制集合C:有一些约束
- 一般会将C 设为 不受限,会快一点
- 优化的目标是减少训练误差,而深度学习的目标是减少泛化误差。(深度学习除了使用优化算法减少训练误差之外,还需要注意过拟合)
- 在深度学习中,大多数目标函数都很复杂,没有解析解。相反,我们必须使用数值优化算法。
-
局部最小 vs 全局最小
-
全局最小:
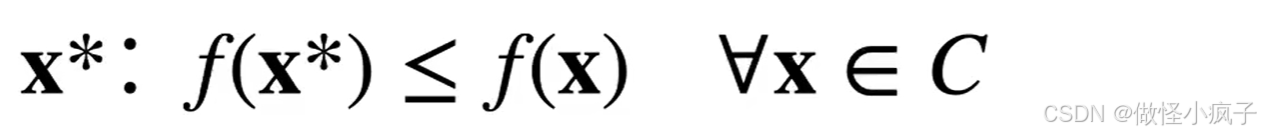
-
局部最小:
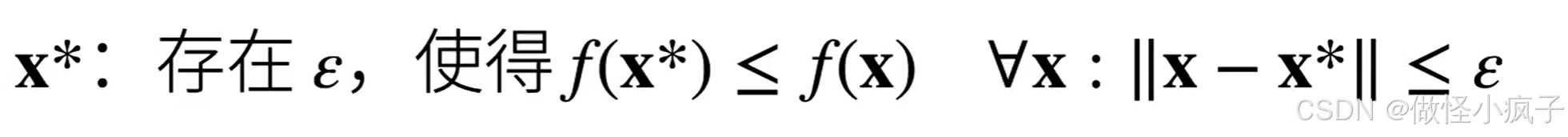
-
使用迭代优化算法来求解,一般只能保证找到局部最小值。
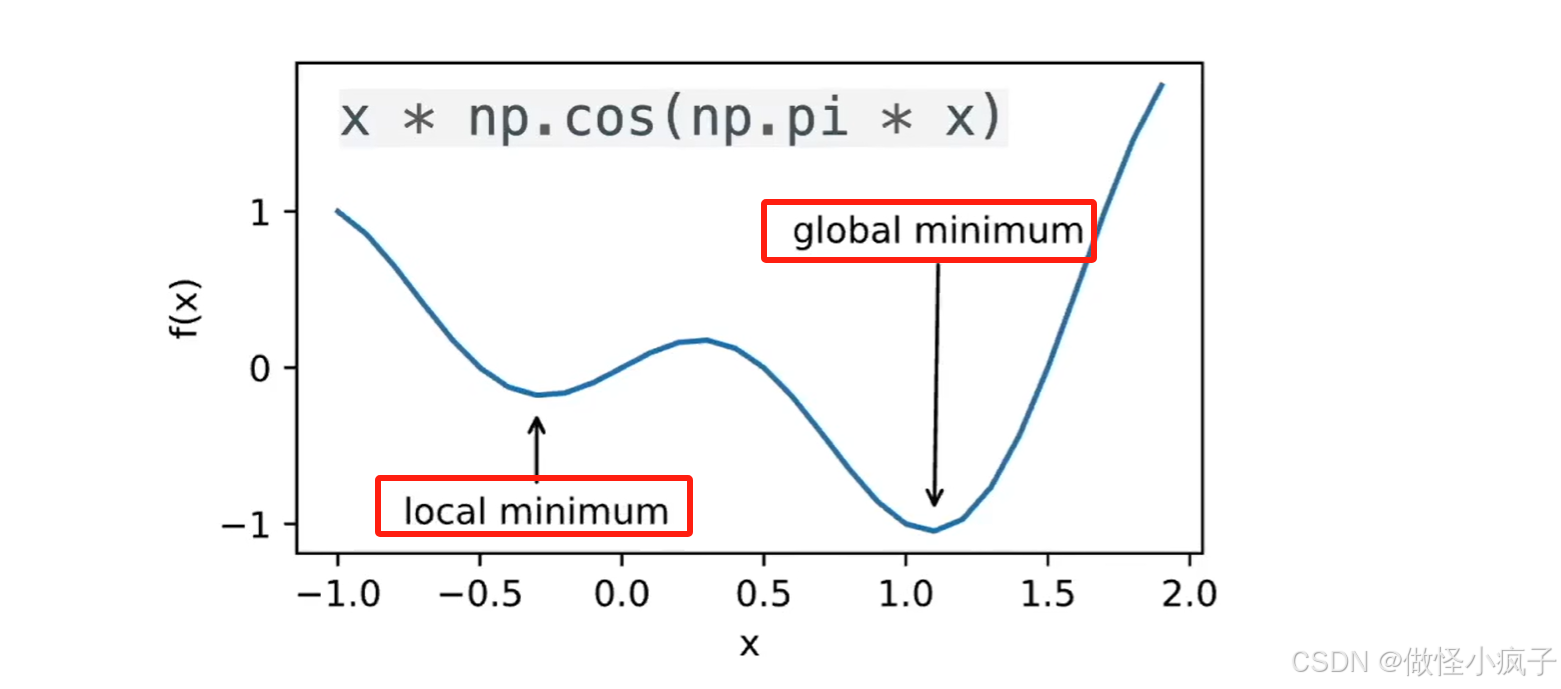
-
凸函数
 - 凸函数 - 函数 f :C → R 是凸当且仅当:
- 凸函数 - 函数 f :C → R 是凸当且仅当: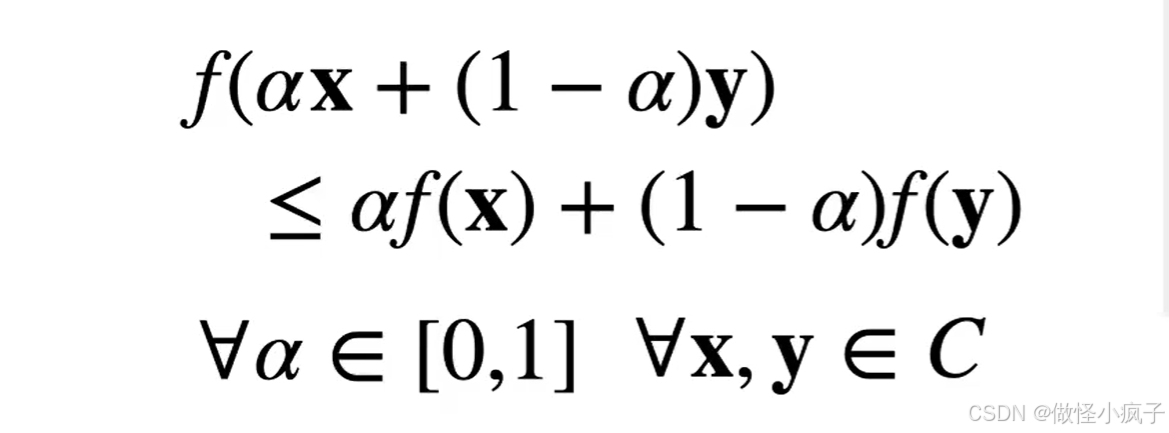
- 如果x≠y,α∈(0,1)时不等式严格成立那么叫严格凸函数。
- 如下图,任意取两个点,两个点连线,整个函数都在连线的下面。(上面的不等式)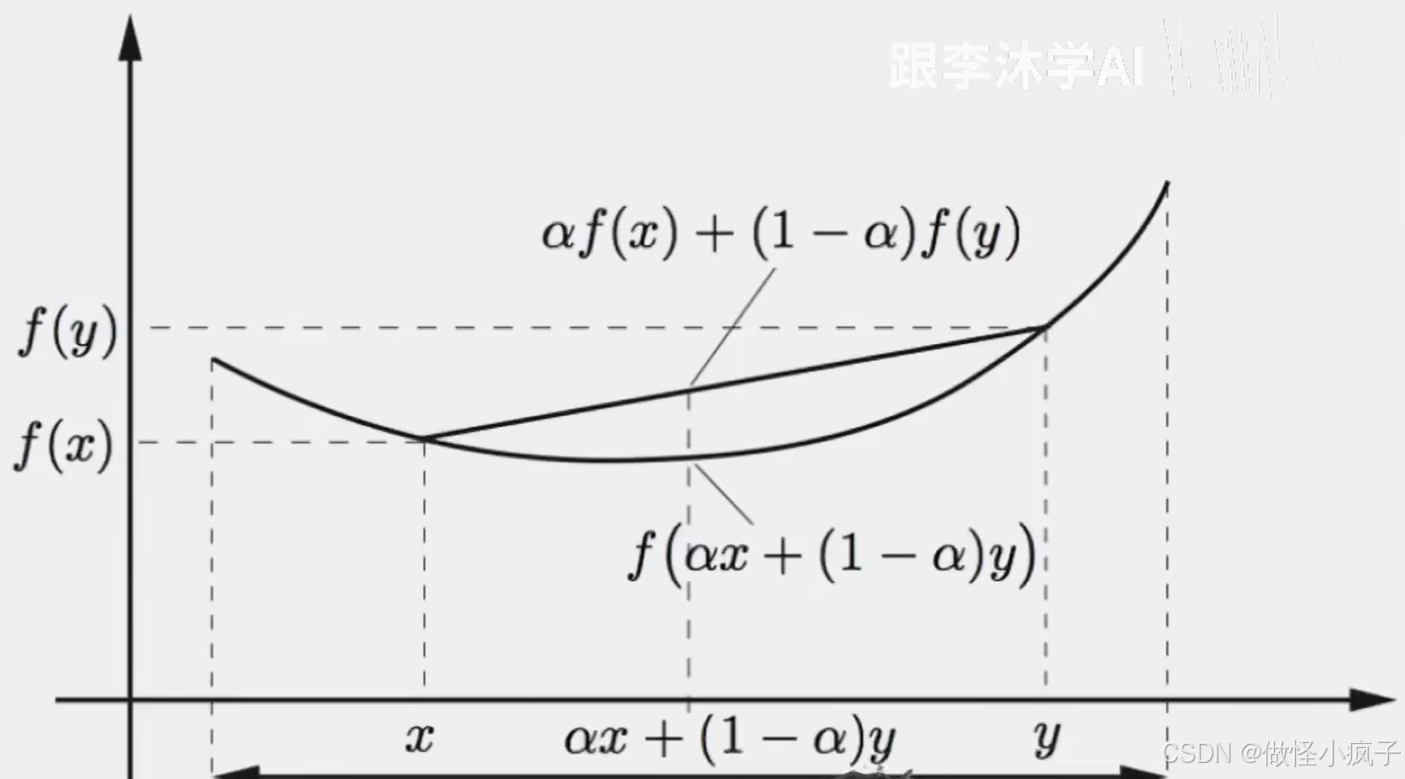
- 凸函数优化
- 如果代价函数 f 是凸的,且限制集合C是凸的,那么就是凸优化问题,那么局部最小一定是全局最小
- 严格凸优化问题有唯一的全局最小。
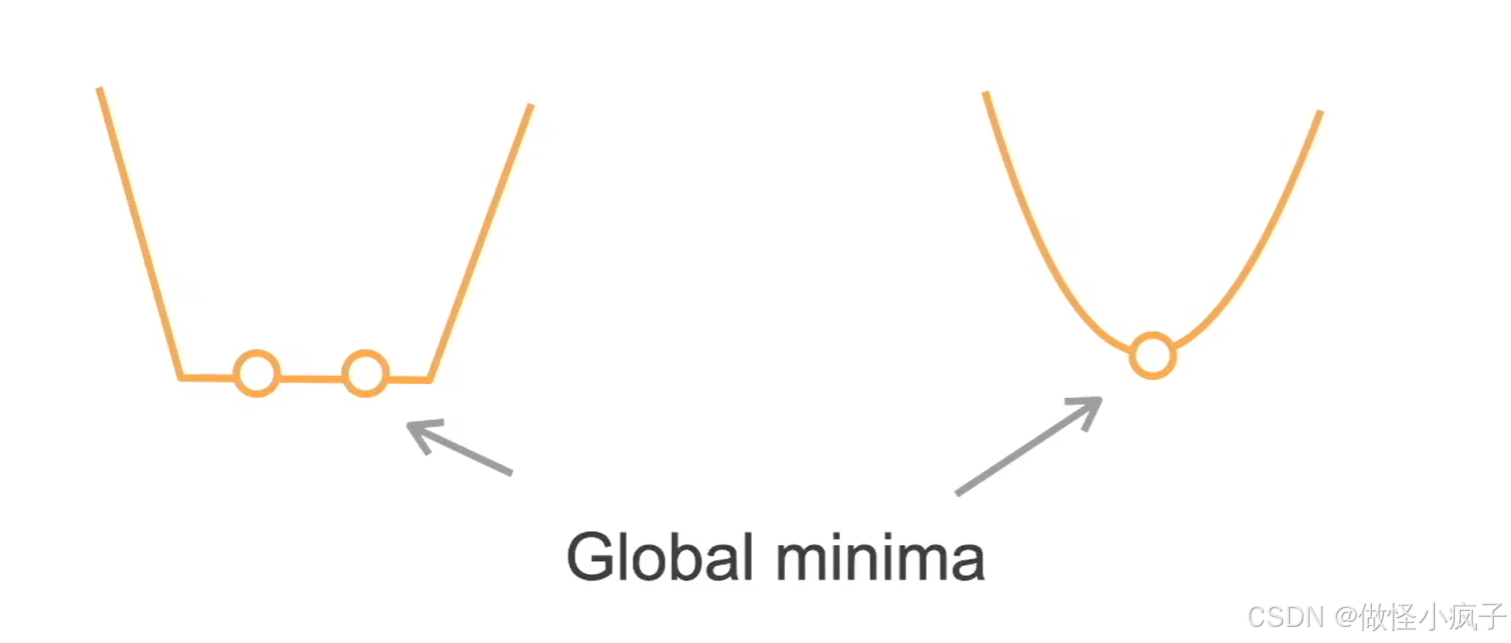
- 凸和非凸例子
- 凸:(表达能力比较有限)
-
线性回归
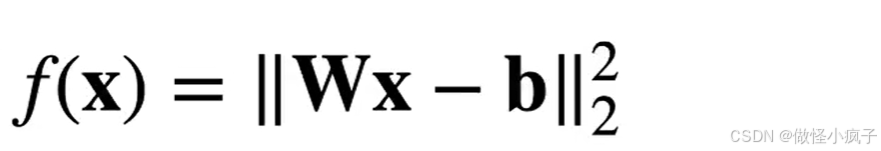
-
softmax回归
-
- 非凸:
- MLP,CNN,RNN,attention,…(加了激活函数就不是凸函数了)
- 凸:(表达能力比较有限)
梯度下降
梯度下降
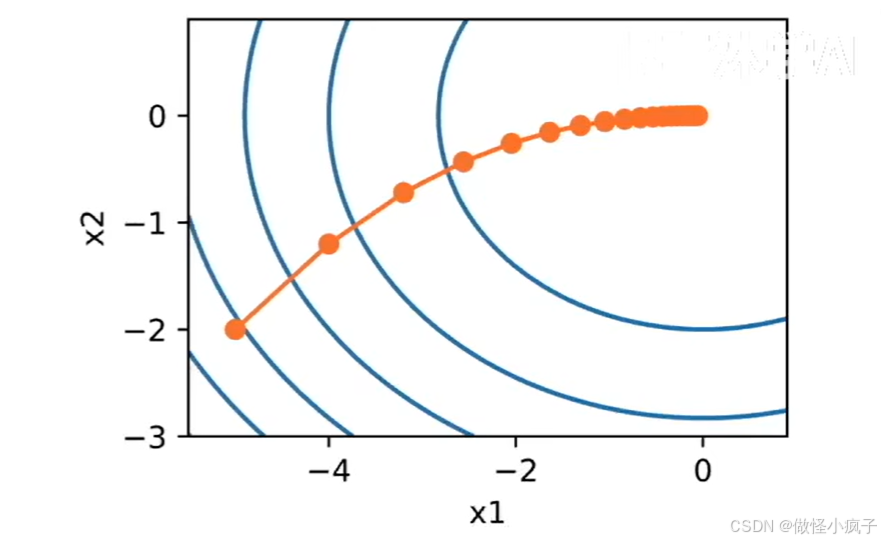
- 最简单的迭代求解算法
- 选取开始点x0
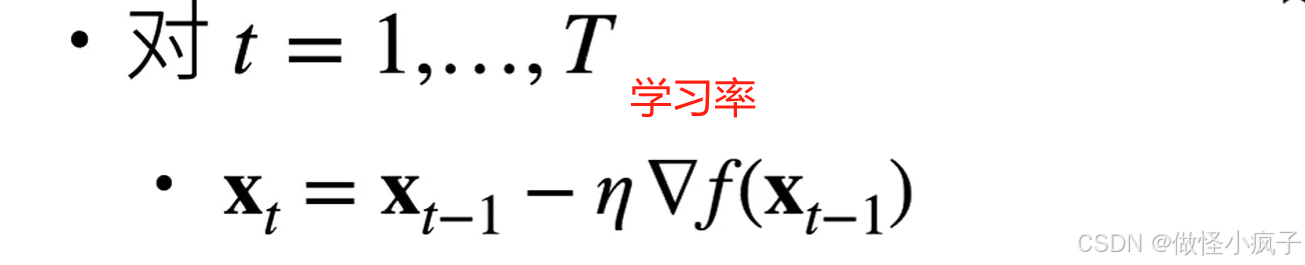
随机梯度下降Stochastic Gradient Descent,简称SGD)
- SGD梯度下降算法的一种变体,主要用于大规模数据集的优化问题。
- 与传统的梯度下降法不同,SGD每次更新参数时只利用部分数据(即随机抽取的一个样本或者一小批样本),而不是全部数据,从而减少了计算量和内存消耗。
- 有n个样本时,计算导数的计算量太大
- 随机梯度下降在时间 t 随机选项样本 t_i 来近似f(x)
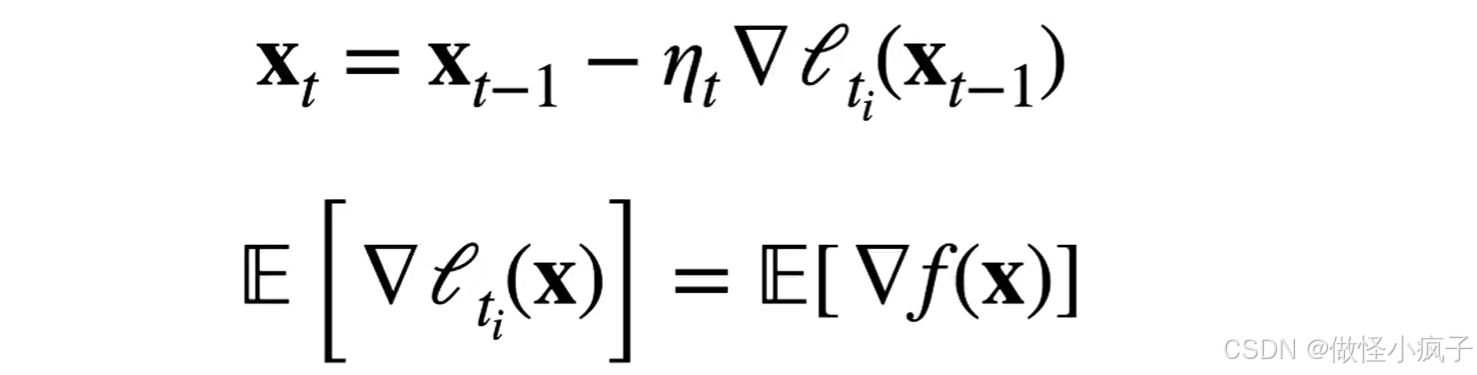
由于在梯度中注入了不确定性的影响,随机梯度下降中变量的轨迹会比一般的梯度下降法中的轨迹嘈杂许多,即使经过多次迭代,最终的效果也不那么好,因此需要我们改变学习率。但是,如果我们选择的学习率太小,我们一开始就不会取得任何有意义的进展。另一方面,如果我们选择的学习率太大,我们将无法获得一个好的解决方案。解决这些相互冲突的目标的唯一方法是在优化过程中动态降低学习率。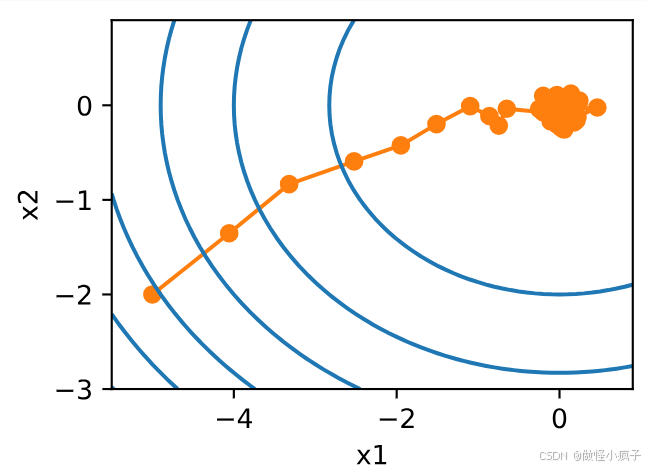
小批量随机梯度下降
-
使用完整数据集来计算梯度并更新参数的梯度下降法和一次处理一个训练样本来取得进展的随机梯度下降法的折中方案。
-
计算单样本的梯度难完全利用硬件资源
-
小批量随机梯度下降在时间 t 采样一个随机子集I_t ∈ {1.……,n}使得|I_t| = b
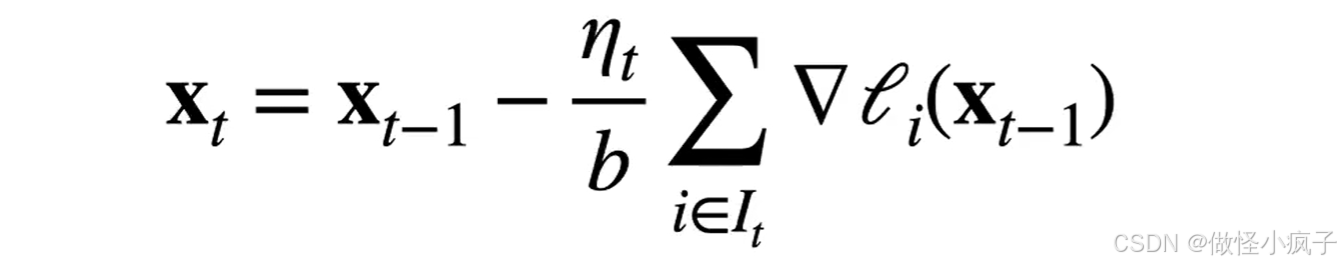
-
同样,这是一个无偏的近似,但降低了方差
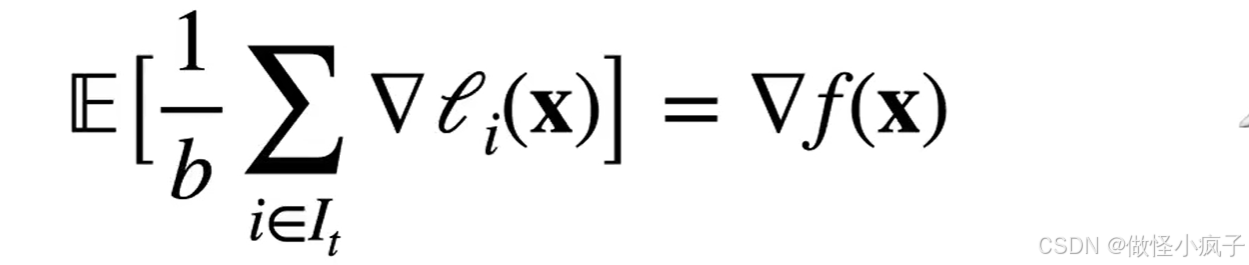
冲量法
- 维护一个冲量(惯性);方向不要改变的过快(平滑的改变方向)
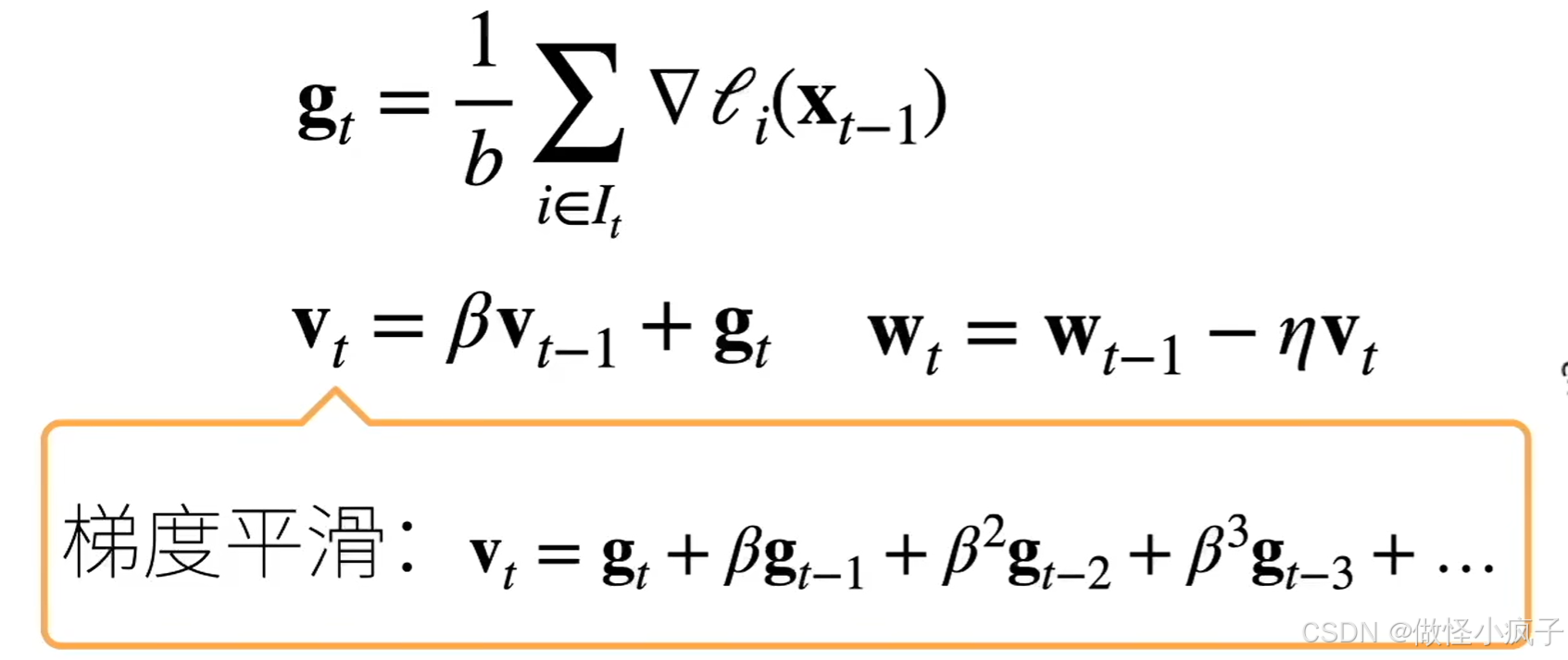
- β 常见取值:[0.5, 0.9, 0.95, 0.99]
Adam
Adam算法是一种用于优化神经网络训练的自适应学习率优化算法。它结合了动量梯度下降和自适应学习率方法的优点,具有广泛的应用和高效的性能。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)