LangGraph从入门到实战
定义状态# 创建 graph# )# 定义一个执行节点# 调用大模型,并返回消息(列表)# 返回值会触发状态更新 add_messages# Prompt模板template = """请根据对话历史和下面提供的信息回答上面用户提出的问题:{input}"""# 检索 top-3 结果# 定义 rag查询节点else:# 填 prompt 模板。
LangGraph 是为智能体和工作流设计一套底层编排框架
是一个基于图结构(Graph)构建复杂工作流的框架,通常与 LangChain(一个用于开发语言模型应用的框架)结合使用。它允许开发者通过定义“节点”和“边”来创建有状态(state)的应用程序,特别适合需要多步骤交互、循环或动态决策的任务(如聊天机器人、自动化流程等)。
安装:
pip install langgraph核心概念
StateGraph将工作流定义成一个状态机Node工作流中的节点Edge边,定义节点之间的跳转State状态,随着工作流的进行可以被更新
主要功能
-
灵活的工作流设计:通过代码定义复杂的执行逻辑,支持条件分支、并行处理等。
-
与 LangChain 集成:直接使用 LangChain 的组件(如链、工具、模型等)。
-
长期记忆/状态管理:在多次调用之间保持上下文(如聊天历史记录)。
-
人类交互支持:允许在流程中暂停并等待用户输入。
典型使用场景
-
多轮对话机器人
根据用户输入动态调整回复策略,维护对话历史。 -
自动化决策系统
例如客服工单处理:解析问题 → 分类 → 调用不同工具解决。 -
复杂数据处理
分步骤清洗、分析数据,并根据中间结果决定下一步操作。 -
迭代式内容生成
生成文本 → 检查质量 → 若不满意则重新生成。
一、基础入门
1、导入包
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph,START,END
from langgraph.graph.message import add_messages
from langchain.chat_models import init_chat_model
from IPython.display import Image, display
from models import chat_model2、定义状态以及图谱
# 定义状态
class State(TypedDict):
messages: Annotated[list,add_messages]
# 创建 graph
graph_builder = StateGraph(State)3、定义节点执行的函数
# llm = init_chat_model(
# "gpt-4o-mini",
# api_key = os.getenv("DMX_OPENAI_API_KEY"),
# base_url = os.getenv("DMX_BASE_URL"),
# model_provider="openai"
# )
llm = chat_model()
# 定义一个执行节点
def chatbot(state:State):
# 调用大模型,并返回消息(列表)
# 返回值会触发状态更新 add_messages
return {"messages": [llm.invoke(state["messages"])]}4、构建graph图谱
# 定义节点以及边
graph_builder.add_node("chatbot",chatbot)
# 定义边
graph_builder.add_edge(START,"chatbot")
graph_builder.add_edge("chatbot",END)
graph = graph_builder.compile()
# 可视化展示这个工作流
# try:
# display(Image(data=graph.get_graph().draw_mermaid_png()))
# except Exception as e:
# print(e)可视化图谱:
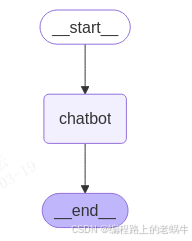
5、运行
while True:
user_input = input("请输入您的问题:")
if user_input == "exit":
print("退出程序")
break
# 向 graph 传入一条消息(触发状态更新 add_messages)
for message in graph.stream({"messages":[{"role":"user","content":user_input}]}):
for value in message.values():
content = value["messages"][-1].content
print(f"Assistant: {content}")例子只是一个简单的入门,初步体验了LangGraph构建一个简单的工作流需要定义的状态(State)、节点(chatbot)、边、(graph_builder.add_edge(START,"chatbot"))、图谱(graph_builder = StateGraph(State))等信息。然后执行过程会按照定义的图谱结构进行执行。
上面只是一个节点,那么再加一个节点呢,下面结合Rag进行扩展。
二、结合Rag进阶
1、获取并存储文档
embedding_model = DashScopeEmbeddings(
model = 'text-embedding-v1',
dashscope_api_key = os.getenv('DASHSCOPE_API_KEY')
)
# 保存向量数据库
db_dir = "./faiss_db"
# 创建向量数据库
def create_db() -> FAISS:
pdf_loader = PyPDFLoader("C:/wwqqq.pdf")
docs = pdf_loader.load()
# 进行分词
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=1000,
chunk_overlap=200,
add_start_index=True
)
chunks = text_splitter.split_documents(docs)
# 创建向量数据库
vector_store = FAISS.from_documents(chunks, embedding_model)
vector_store.save_local(db_dir)
return vector_store
# 判断数据库是否存在,不存在则创建数据库
def is_db_exist() -> FAISS:
vector_store = None
is_db_exist = os.path.exists(db_dir)
if is_db_exist:
vector_store = FAISS.load_local(
db_dir,
embedding_model,
allow_dangerous_deserialization=True
)
else:
vector_store = create_db()
return vector_store
# 获取向量数据库
vector_store = is_db_exist()2、定义文档查询节点
# Prompt模板
template = """请根据对话历史和下面提供的信息回答上面用户提出的问题:
{input}
"""
prompt = ChatPromptTemplate.from_messages(
[
HumanMessagePromptTemplate.from_template(template),
]
)
# 检索 top-3 结果
# retriever = vector_store.as_retriever(search_kwargs={"k": 3})
# 定义 rag查询节点
def retrieval(state:State):
user_query = ""
if len(state["messages"]) >= 1:
user_query = state["messages"][-1]
else:
return {"messages": []}
# text = retriever.invoke(str(user_query))
text = vector_store.similarity_search(str(user_query))
# 填 prompt 模板
messages = prompt.invoke("\n".join([doc.page_content for doc in text])).messages
return {"messages": messages}3、定义图谱
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot",chatbot)
graph_builder.add_node("retrieval",retrieval)
graph_builder.add_edge(START,"retrieval")
graph_builder.add_edge("retrieval","chatbot")
graph_builder.add_edge("chatbot",END)
graph = graph_builder.compile()4、运行
while True:
user_input = input("请输入您的问题:")
if user_input == "exit":
print("退出程序")
break
# 向 graph 传入一条消息(触发状态更新 add_messages)
for message in graph.stream({"messages":[{"role":"user","content":user_input}]}):
for value in message.values():
print(type(value["messages"][-1]))
if "messages" in value and isinstance(value["messages"][-1], AIMessage):
print("Assistant:", value["messages"][-1].content)备注:这里面的状态和机器人节点chatbot和例子一中的的一样,直接可以复用
思考:这个例子中,查询文档并让大模型进行输出的,那么如果说文档中查询不到用户的问题,那么该怎么友好的进行处理呢,假如是一个机器人客服,如果查询不到的话,那么就转入人工进行回答,所以这个时候可以加入条件分支进行处理。
Rag的基础知识可详见:langchain + Faiss + embedding构建基于RAG的PDF文件问答系统_faiss embedding-CSDN博客
三、加入分支
1、进行分支判断
# 定义条件函数
def verify(state:State) -> Literal["chat_boot","human_ask"]:
message = HumanMessage("请根据对话历史和上面提供的信息判断,已知的信息是否能够回答用户的问题。直接输出你的判断'Y'或'N'")
response = llm.invoke(state["messages"] + [message])
if response.content == "Y":
print("Assistant:", "机器人正在搜索中.....")
return "chat_boot"
else:
print("Assistant:", "我无法回答你的问题,转入人工回答.....")
return "human_ask"2、构建图谱
# from langgraph.checkpoint.memory import MemorySaver
# 持久化信息
memory = MemorySaver()
graph_builder.add_node("retrieval", retrieval)
graph_builder.add_node("chat_boot", chat_boot)
graph_builder.add_node("human_ask", human_ask)
graph_builder.add_edge(START, "retrieval")
graph_builder.add_conditional_edges("retrieval", verify)
graph_builder.add_edge("human_ask", END)
graph_builder.add_edge("chat_boot", END)
# 中途会被转人工打断,所以需要 checkpointer 存储状态
graph = graph_builder.compile(checkpointer=memory)
# 当使用 checkpointer 时,需要配置读取 state 的 thread_id
thread_config = {"configurable": {"thread_id": "rag_thread_id"}}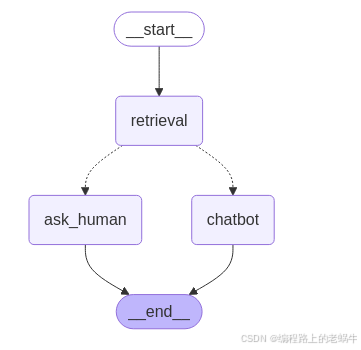
3、流程执行
def stream_graph_updates(user_input: str):
# 向 graph 传入一条消息(触发状态更新 add_messages)
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
thread_config
):
for value in event.values():
if isinstance(value, tuple):
return value[0].value["question"]
elif "messages" in value and isinstance(value["messages"][-1], AIMessage):
print("Assistant:", value["messages"][-1].content)
return None
return None
def resume_graph_updates(human_input: str):
for event in graph.stream(
Command(resume=human_input), thread_config, stream_mode="updates"
):
for value in event.values():
if "messages" in value and isinstance(value["messages"][-1], AIMessage):
print("Assistant:", value["messages"][-1].content)
def run():
# 执行这个工作流
while True:
user_input = input("请输入问题: ")
if user_input.strip() == "":
break
question = stream_graph_updates(user_input)
print("Assistant question :", question)
if question:
human_answer = input("Ask Human: "+question+"\nHuman: ")
resume_graph_updates(human_answer)以上就是一个简单的条件分支的工作流,这样一步步的扩展,可以加入很多节点,去过不同的事。这里还有循环节点等。可以进行自己扩展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)