Transformer XL【详细解析】
目前普遍认为,transformer存在如下局限性:1.输入序列定长,无法捕捉过长的依赖2.解码自回归过程仅仅考虑到了之前已经生成的信息,完成像单词填空类的任务效果可能不会那么好3.attention计算资源消耗过大,复杂度O(N^2)对于问题2,有bert类的架构;对于问题3,有一系列例如gMLP来简化attention操作,以减少计算资源消耗;而Transformer XL 致力于解决问题一,
Transformer模型及其局限性
可以对先对transformer进行一下简单回顾
周玄九-CSDN博客![]() https://blog.csdn.net/keith66?spm=1000.2115.3001.5343目前普遍认为,transformer存在如下局限性:
https://blog.csdn.net/keith66?spm=1000.2115.3001.5343目前普遍认为,transformer存在如下局限性:
1.输入序列定长,无法捕捉过长的依赖
2.解码自回归过程仅仅考虑到了之前已经生成的信息,完成像单词填空类的任务效果可能不会那么好
3.attention计算资源消耗过大,复杂度O(N^2)
对于问题2,有bert类的架构;对于问题3,有一系列例如gMLP来简化attention操作,以减少计算资源消耗;而Transformer XL 致力于解决问题一,在正式介绍该模型之前,先引入
传统处理长文本的方法一般是切分输入文本,其中每份的大小设置为预训练语言模型能够单次处理的最大长度(如512)。 最终将多片文本的决策结果进行综合(如对分类结果进行投票)或者拼接(如序列标注或生成任务)得到最终结果 。然而,这种方法不能很好地构建文本块之间的联系,挖掘长距离文本依赖的能力较弱。因此,更好的方法还是需要从根本上提高预训练语言模型单次能够处理的最大文本长度,从而能够更加充分地利用自注意力机制。针对这一挑战,Transformer-XL模型给出了解决方法。
Transformer XL架构
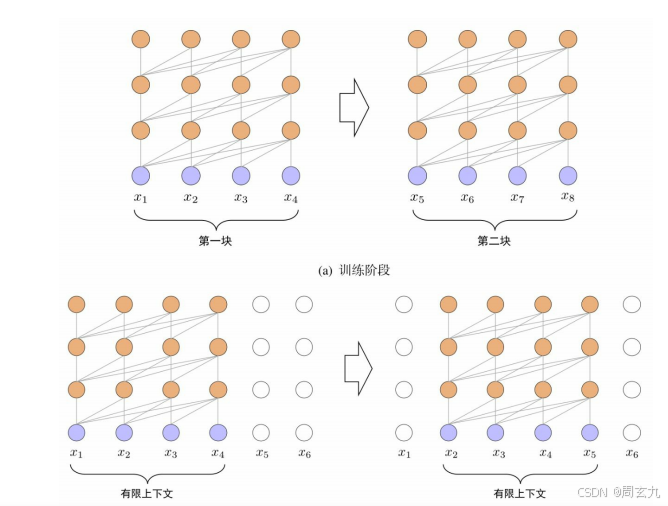
状态复用的块级别循环
记Transformer XL Encoder 有N个 layer,每个layer 输出的隐状态为h_i,有一个mem池用于存储上一阶段原始输入以及经过每一个layer的隐状态(共m+1个),本段在经过每一层的时候都和mem中对应元素做concat,于是就可以捕捉到来自不同段的信息了。
相对位置编码
虽然状态复用的块级别循环技术能够将不同块之间的信息联系起来,但在实际应用中还存在一个非常重要的问题:如何区分不同块中的相同位置(如第块和第
块中的第二个位置)?采用传统Transformer中的绝对位置编码方法是不可行的,不同段的位置会共享相同的编码,所以需要一种编码方式,使得输入不同段的时候能够获得不同的位置编码
为了解决这个问题,Transformer-XL引入了 相对位置编码 策略。位置信息的重要性主要体现在注意力矩阵的计算上,用于构建不同词之间的关联关系。
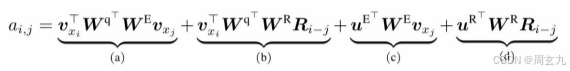
式中,W 和表示可训练的权重; 表示词xi对应的词向量;表示相对位置矩阵(N表示最大编码长度),是一个不可训练的正弦编码矩阵,其第i行表示相对位置间隔为i的位置向量。接下来针对上式中的各个部分进行介绍。
基于内容的相关度(a):计算查询xi与键xj的内容之间关联信息;
内容相关的位置偏置(b):计算查询xi的内容与键xj的位置编码之间的关联信息,表示两者的相对位置信息,表示取R中的第i−j行;
全局内容偏置(c):计算查询xi的位置编码与键xj的内容之间的关联信息;
全局位置偏置(d):计算查询xi与键xj的位置编码之间关联信息。
附原文链接
[1901.02860] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)