基于InternVL的遥感大模型智能分析平台丨与书生共创
本项目主要通过数据集创新、算法优化与场景适配,显著提升了模型遥感图像解析的效率与精度,其核心技术可进一步拓展至跨模态特征对齐、自主决策智能体、“端—边—云”协同等方向,为遥感智能分析领域的发展提供重要参考。
随着书生大模型开源生态的不断壮大,越来越多的产品和平台纷纷接入书生大模型。科研人员依托书生大模型持续探索创新,取得了丰富的研究成果;社区用户也不断创造出令人耳目一新的项目。“与书生共创”将推出一系列文章,聚焦这些合作与创新案例。欢迎订阅并踊跃投稿,一起分享经验与成果,共同推动大模型技术的应用与发展。
本文来自社区投稿,作者周木炎,书生大模型实战营学员,将向大家介绍孵化于书生大模型实战营期间,依托书生·万象 InternVL 多模态大模型,构建的遥感大模型智能分析平台。
动机
随着遥感影像在空间、光谱、时间等维度的分辨率不断提升,传统人工解译和规则方法已无法满足海量异构数据的实时处理需求。尽管多模态大模型在自然图像任务中表现优异,但由于领域差距,在遥感(RS)图像推理中受限。
一方面,传统遥感方法依赖任务特定模型,缺乏清晰的显式推理路径;另一方面,现有多模态大模型在训练中高度依赖手动标注数据,容易出现“伪思维链(Pseudo-CoT)”现象,同时强化学习(RL)过程也常面临梯度停滞、性能退化等问题。
为此,我们首先构建了高质量的遥感多模态推理数据集,并基于此对 InternVL 模型进行强化学习训练,以系统提升模型的逻辑推理能力与可解释性。同时,我们开发了可视化推理界面,打造了面向遥感场景的智能分析平台,实现从数据到推理再到结果展示的一体化智能工作流。
技术实现
遥感推理数据集构建
以“答案引导模态桥接”方法生成 20k 含“图像思维链(Image-CoT)”的样本,支持模型冷启动,无需手动标注。
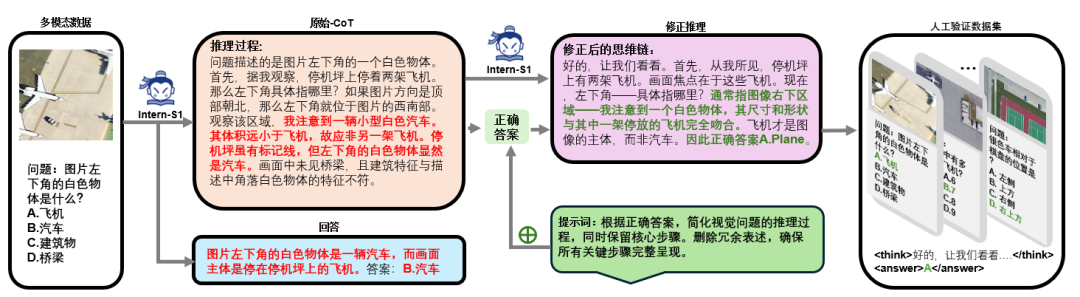
在训练多模态大模型以胜任复杂多模态推理任务的过程中,生成高质量、复杂且与人类思维模式紧密契合的CoT数据,已成为提升模型性能的关键因素。
针对这一需求,我们提出了一种创新性的答案引导的“模态桥接”(Modality Bridging)方法。该方法通过整合现有多模态大型模型的推理能力,实现了多模态信息的间接转换与复杂推理过程的精准捕捉,具体实施流程如下:
首先,以机场场景视觉问答任务为例,系统首先接收多模态输入数据,包含机场图像、问题(如“What is the white object in the picture?”)及候选答案集(如Plane、Car等)。
这些数据被输科学入多模态大模型 Intern-S1,模型通过分析生成包含图像描述与推理过程的“原始思维链”(Raw-CoT)。在此过程中,模型对候选答案进行多维度评估:针对“汽车”选项,模型会考察其颜色属性与图像中视觉特征的匹配度;对于“建筑物”选项,则通过规模特征判断其与“白色物体”描述的矛盾性;而“桥梁”选项因在场景中不可见被直接排除。最终模型输出初步推理结论,倾向于选择“汽车”并给出相应依据。
其次,对于错误的条目,将生成的原始思维链与标准正确答案进行关联,形成增强型输入数据并重新输入Intern-S1。Intern-S1 会结合正确答案执行思维链修正操作,重新聚焦图像中白色物体与飞机特征的匹配性,考虑到飞机在商用或军用机型中普遍呈现的白色外观等因素,对初始推理逻辑进行优化调整,经此修正过程,最终确定答案为“飞机”。
最后,对 Intern-S1 生成的推理过程进行人工校验,筛选出与实际场景高度吻合的有效推理样本。通过严格的过滤机制,构建包含图像、问题、修订后推理过程及正确答案的标准化数据集。该数据集可应用于模型训练环节,为冷启动提供支持,借助贴近人类认知模式的“图像-CoT”数据,使推理过程呈现自然且符合逻辑的思考范式,进而提升模型在多模态视觉问答任务中的推理能力。
模型训练
冷启动阶段用专用损失函数提升基础推理能力;通过改进 GRPO,加入自适应优势优先缓解梯度停滞,结合精细化质量奖励优化推理输出。
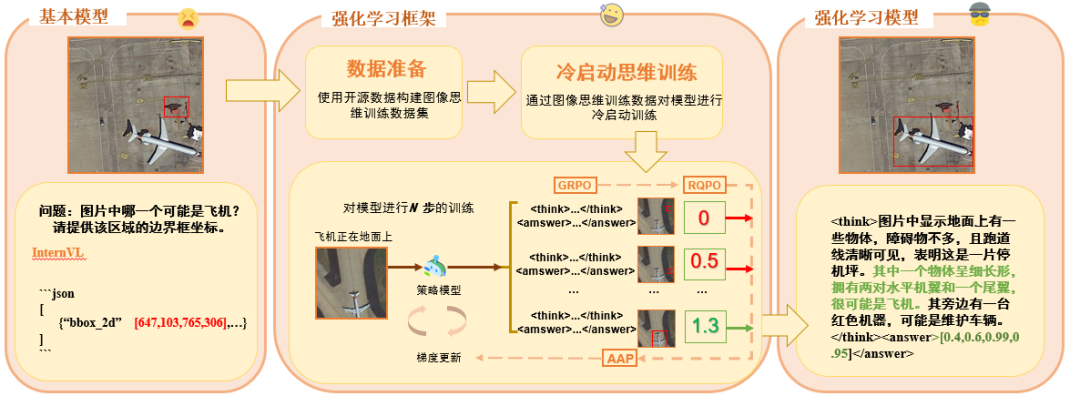
在获得“图像-CoT”数据集后,对 InternVL 多模态大模型(4b)进行监督微调(SFT)冷启动,得到冷启动模型“书生”-Cold。尽管此时模型已经学习了复杂推理模式,但我们发现,冷启动后的模型只是获取了一定的思维模式,如果原始模式性能较好的情况下判断能力反倒有所下降,原因分析是模型只会思考,但是不知道思考的方向哪一个是正确的。因此,在早期阶段模型掌握正确的思维方式后,通过强化学习的奖励 Reward 引导模型的思考方向,对于后续推理性能的提升至关重要。
在多模态大模型的推理能力构建中,策略模型的冷启动初始化阶段是启动后续强化学习流程的核心基础。这一阶段通过为初始模型注入基础自我反思能力,确保策略模型在进入强化学习循环前,能够生成具备反思特性的推理路径,从而为高质量推理和自主修正能力奠定关键基础。
初始化的核心目标有两个:
一是通过更高级语言模型生成的反思性指导内容,训练策略模型将在输入提示 q 下生成的原始答案(𝑎₁)迭代优化至接近真实答案(𝑎₂)。例如,当模型对视觉问答任务给出初步回答时,外部 LLM 会通过结构化思考段落(⟨think⟩...⟨/think⟩)标注初始回答中的逻辑缺陷或冗余表述,引导模型进行
针对性修正。冷启动初始化的损失函数定义为:
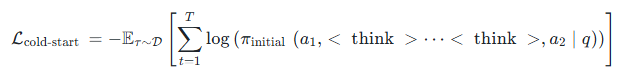
二是模型通过解析真实答案中隐含的推理逻辑与领域知识,构建预测轨迹的优化准则。这种知识迁移机制使模型不仅能修正当前错误,更能内化正确推理范式,形成可持续进化的预测能力。
页面可视化
各个模块展示使用 Python 的 B/S 架构,利用 Streamlit 与 Gradio 技术设计了 Web 界面的前端交互功能,同时依赖云原生管理平台为底层环境提供支撑。
Web 可视化如图下所示,主要分为状态显示区、参数配置区、图片上传区以及智能对话区;其中状态显示区用来实时监控和展示平台、模型、API 以及处理的状态;参数配置区提供了功能模式、文本设置等参数调节功能,支持用户进行自定义配置并保存;图片上传区允许用户上传图片,旁边有预览功能方便确认;智能对话区则是用户与系统交互的对话框区域,用于接收反馈或输入指令。
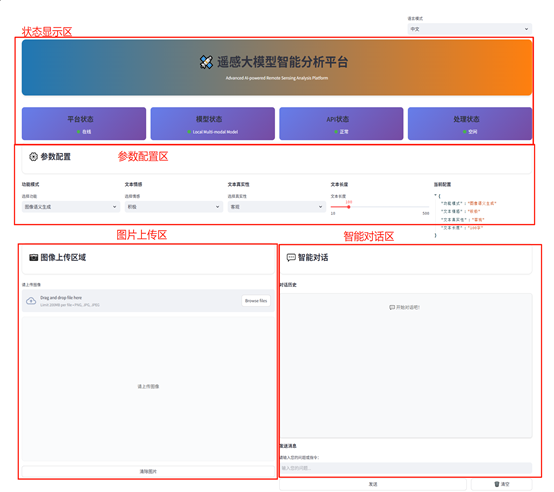
模块示意图
当前已经具备图像语义生成、目标识别与计数能力、空间感知与定位能力、地物分类与状态评估、场景推理与决策等功能,支撑自定义图像上传与智能对话辅助。例如在上传图像后,选择空间定位功能,然后输出目标指示点击启动功能,即可展示定位效果,如下图所示。
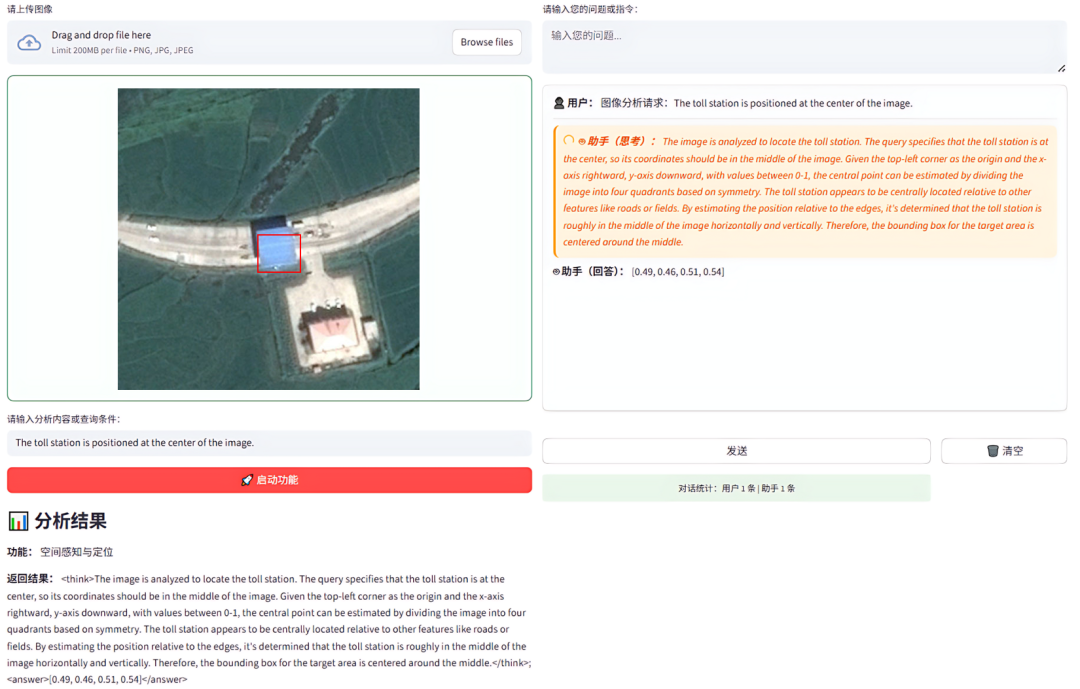
定位功能展示
示例
数据集构建后示例如下:

运行图片推理示例如下:

问题 question 为:“What is the color of the vehicle?”;
运行后结果示例如下:

运行结果为“<think>The image shows a basketball court with two courts side by side. On the left side, near the top of the image, there is a red vehicle parked on the street. The vehicle's color is clearly visible and stands out against the background. No other vehicles are present in the scene. Therefore, the only vehicle shown is red.</think>;<answer>Red</answer>”
可以看到结果不仅输出了正确答案,并且还能够输出有效的推理过程。并且在训练后,在 VRS-Bench 中的测试集中的 VAQ 问题中可以达到 0.6054 的正确率,使得 4b 的 InternVL 也能够比肩众多闭源大模型的推理能力。
总结
本项目主要通过数据集创新、算法优化与场景适配,显著提升了模型遥感图像解析的效率与精度,其核心技术可进一步拓展至跨模态特征对齐、自主决策智能体、“端—边—云”协同等方向,为遥感智能分析领域的发展提供重要参考。
相关链接
-
可视化页面展示视频:
https://www.bilibili.com/video/BV1P6x6zBEJB
-
“图像-CoT”数据集地址:
https://gitee.com/zhou-muyan/image-cot
(下载数据集后将数据集中的图片地址改为自己本地的 VRS-Bench 训练集图片地址即可)
-
InternVL 开源链接:
https://github.com/OpenGVLab/InternVL
-
书生大模型在线体验链接:
https://chat.intern-ai.org.cn/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)