SFT数据指令评估-1.AlpaGasus/基于强大模型直接评估数据
这种情况下一般指的是文本理解能力很强的黑盒api大模型,如chatgpt。这种情况下,大模型对文本理解不会有什么大的问题,因此对于嵌套数据也能理解,例如我让大模型执行指令微调数据打分,以一个任务的prompt和output为输入。小模型可能会对这种包含了两个指令的文本理解错误,强模型基本能理解。因此,可以以强模型来直接对指令微调数据进行打分。
强大模型评估数据质量
这种情况下一般指的是文本理解能力很强的黑盒api大模型,如chatgpt。这种情况下,大模型对文本理解不会有什么大的问题,因此对于嵌套数据也能理解,例如我让大模型执行指令微调数据打分,以一个任务的prompt和output为输入。小模型可能会对这种包含了两个指令的文本理解错误,强模型基本能理解。因此,可以以强模型来直接对指令微调数据进行打分。
score(triplet)=LLM(rate instruction,triplet,Metrics),triplet=(Instruction,Input,Output) score(triplet) = LLM(rate~instruction, triplet, Metrics), \\ triplet = (Instruction, Input, Output) score(triplet)=LLM(rate instruction,triplet,Metrics),triplet=(Instruction,Input,Output)
评分指令如下:
给定一组指令、输入和输出的三元组,你需要基于以下指标对该三元组进行5分制打分。评分为0-5的整数,分数越高,表示该数据依据某个指标是更好的。
以下是评估的指标名称和说明:
{metric_descriptions}
其中可以灵活改变的部分有:
- 打分制度: 几分制,每个分数是否有具体的规则,这部分我们暂时不考虑,同时写死的5分制能打分的制不会很多,通常越多的可打分制对数据结果有一点坏处,主要表现在数值分布很不均匀,有些数值断层式少。
- 评估方面: 具体需要评估数据的哪些方面,例如准确度偏向输出答案更贴近真实情况,而友善度偏向语言的表达方式和口吻。我不希望每一个不同指标都需要单独写一个 prompt,因为指标的说明很简单而评估数据会更长,不同指标的 prompt 会线性增加 token 消耗,所以只需要在评估 prompt 里交代指标名称和其说明。同时我们也要求大模型在输出具体的打分结果前,先输出对应的理由或者分析。最终结果以嵌套 dict 输出, 形如 {“result”:[{“metric_name”:“指标A”, “reasoning”:“xxx”, “score”: 0-5}, …]}。嵌套dict只有两次,不会带来理解上的压力,而且比正常 dict 方便后期遍历。
import json
with open('./data/alpaca_gpt4_data_zh_100.json', 'r', encoding='utf-8') as file:
triplet_list = json.load(file)
Deepseek R1的特殊处理
R1的输出结构如下
<think>reasoning</think>
answer
由于R1有内容,这部分虽然对后面真正回答有益,但对解析不友好,以下类负责把reasoning部分剥离,正式回答还是正常解析类解析
from langchain_core.runnables import Runnable
from langchain_core.messages.ai import AIMessage
class ThinkContentParser(Runnable):
def __init__(self, output_parser):
super().__init__()
self.output_parser = output_parser
def invoke(self, message: AIMessage, config) -> tuple:
return self.parse(message)
def parse(self, message: AIMessage) -> tuple:
"""
解析AIMessage中的content,找到</think>标签的位置,并将其分为两个部分:
- 一个是标签前的部分(包括 <think> 前的内容)
- 一个是标签后的部分(包括 </think> 后的内容)
:param message: 原始的AIMessage对象
:return: 一个元组,包含两个字符串,第一个是</think>前的内容,第二个是</think>后的内容
"""
original_content = message.content
think_end_index = original_content.find('</think>')
if think_end_index != -1:
content_before_think = original_content[:think_end_index + len('</think>')]
content_after_think = original_content[think_end_index + len('</think>'):].strip()
else:
content_before_think = ""
content_after_think = original_content
result = self.output_parser.parse(content_after_think)
return content_before_think, result
import numpy as np
import asyncio
from typing import List, Dict
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser
# ============== Parser ==============
# 单个指标的结果
class Metric_Score(BaseModel):
metric_name: str = Field(description="This is the name of the metric currently evaluted. ")
reasoning: str = Field(description="This is the reasoning process of evaluating the triplet according to the metric. ")
score: float = Field(description="This is a decisive score based on the reasoning process above. ")
# 多个指标合并为一个类
class Multi_Metric_Score(BaseModel):
result: List[Metric_Score] = Field(description="A list of results.")
output_parser = PydanticOutputParser(pydantic_object=Multi_Metric_Score)
wrap_output_parser = ThinkContentParser(output_parser)
# ============== Prompt ==============
metric2description = {
"accuracy": "Ensure that the output is logically correct and factually accurate, especially for questions with clear answers, such as knowledge-based Q&A.",
"effectiveness": "Evaluate whether the content of the answer meets the user's needs, not just superficial relevance.",
"readability": "Ensure that the answer is easy for the user to read and understand, avoiding excessive jargon or complex sentence structures.",
"relevance": "Evaluate whether the model accurately understands the question and maintains contextual coherence in the answer."
}
metric_str = '\n'.join([f'- {metric}:{description}' for metric, description in metric2description.items()])
rating_prompt = (
"You are a helpful and precise assistant for checking the quality of the data."
"You will be given a triplet, including the instruction, the optional input and the output. "
"Note that the input will be blank if the instruction needs no input to generate the output. \n"
"Please rate the quality of the triplet according to the following standards:\n"
"\n{metric_str}\n"
"You will rate on a scale of 0 to {score_scale}, where a higher score indicates higher level of the accuracy. \n"
"Output format: {format}\n\n"
"[START of instruction]:\n{instruction}\n[END of instruction]\n\n"
"[START of input]:\n{input}\n[END of input]\n\n"
"[START of output]:\n{output}\n[END of output]\n\n"
"Present the response in {language} language. \n"
)
rating_prompt = PromptTemplate(
template=rating_prompt,
partial_variables={
"metric_str":metric_str,
"format":output_parser.get_format_instructions(), # 可自定义的评分参考规则
"language": "chinese",
"score_scale":5, # 可自定义的打分值
}
)
# ============== LLM ==============
# 这是正常非推理模型
# llm_interface = ChatOpenAI(
# base_url='http://localhost:5551/v1',
# api_key='EMPTY',
# model_name='Qwen2.5-14B-Instruct',
# temperature=0.5,
# max_retries=3,
# )
# 这是推理模型
llm_interface = ChatOpenAI(
base_url='http://172.31.101.26:9995/v1',
api_key='EMPTY',
model_name='DeepSeek-R1-Distill-Qwen-32B',
temperature=0.5,
)
# ============== chain ==============
# 这是正常非推理模型的chain
# LLM_evaluator = rating_prompt | llm_interface | output_parser
# 这是推理模型的chain
LLM_evaluator = rating_prompt | llm_interface | wrap_output_parser
a_think, a_result = LLM_evaluator.invoke(triplet_list[0])
print(a_think)
a_result.result
<think>
好,我现在需要评估这个triplet的质量,包括准确性、有效性、可读性和相关性。让我一步一步地分析。
首先,准确性。输出中的三个健康提示分别是保持身体活动、均衡饮食和充足睡眠。这些都是经过科学验证的健康建议,内容正确且符合事实。没有错误的信息,所以准确性很高,给5分。
接下来是有效性。这三个提示涵盖了身体健康的主要方面,能够满足用户的需求。用户通过这些建议可以采取实际行动,比如开始运动、调整饮食或改善睡眠习惯。因此,有效性也很高,给5分。
然后是可读性。输出使用了清晰简洁的语言,每个建议都以简短的句子列出,易于理解。没有使用复杂的术语,适合所有读者,所以可读性也很好,给5分。
最后是相关性。输出完全符合用户的指令,提供了三个保持健康的提示,没有任何偏离主题的内容。因此,相关性也很高,给5分。
综合来看,这个triplet在各个方面都表现得很出色,所以每个指标都得了满分。
</think>
[Metric_Score(metric_name='准确性', reasoning='输出中的三个健康提示均基于科学,内容正确且无误。', score=5),
Metric_Score(metric_name='有效性', reasoning='建议涵盖了身体活动、饮食和睡眠,满足用户需求。', score=5),
Metric_Score(metric_name='可读性', reasoning='语言简洁清晰,易于理解。', score=5),
Metric_Score(metric_name='相关性', reasoning='输出完全符合用户指令,提供三个健康提示。', score=5)]
调用方式
取决于api可接受请求的程度,有以下三种方法
## ======= sequential =======
from tqdm import tqdm
result_list = []
for a_triplet in tqdm(triplet_list):
a_think, a_result = LLM_evaluator.invoke(a_triplet)
result_list.append(a_result)
100%|██████████| 10/10 [01:04<00:00, 6.45s/it]
## ======= parrallel =======
tasks = [
LLM_evaluator.ainvoke(a_triplet)
for a_triplet in triplet_list
]
result_list = await asyncio.gather(*tasks)
result_list = [item[-1] for item in result_list]
10条数据,线性执行1min,异步调用10s
异步调用的效率还是很高的,但如果自己部署时显存不够多,异步调用会报错
## ======= parrallel =======
from concurrent.futures import ThreadPoolExecutor, as_completed
result_list = [None] * len(triplet_list)
with ThreadPoolExecutor(max_workers=2) as executor:
futures = {executor.submit(LLM_evaluator.invoke, triplet): data_indice for data_indice, triplet in enumerate(triplet_list)}
for future in as_completed(futures):
# 获取完成任务的索引
index = futures[future]
# 将结果存放到对应的索引位置
result_list[index] = future.result()
线程方法适用于可控的情况,通过max_workers限制同时调用
分数示例
scores = [[m.score for m in item.result] for item in result_list]
scores = np.array(scores)
import matplotlib.pyplot as plt
plt.hist(scores, bins=5, edgecolor='black')
plt.title('Histogram of Data')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
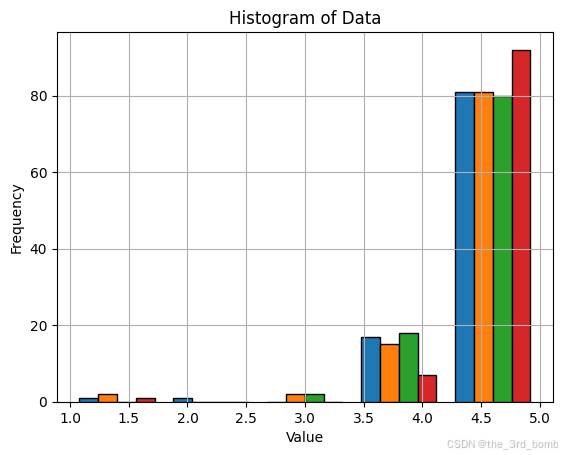
图中可见部分低质量数据,零散的几个,3.5就有点欠优化了

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)