【时间序列聚类】Temporal Phenotyping using Deep Predictive Clustering of Disease Progression
由于医疗电子健康记录的普及,患者的护理数据通常以时间序列形式存储。对这类时间序列数据进行聚类分析在患者分型、预测预后及制定同质亚群治疗策略中具有重要意义。本文提出了一种基于深度学习的时间序列聚类方法,旨在将患者分成不同群组,每个群组的成员具有相似的未来结果(如不良事件或并发症的发生)。通过学习离散表示并引入新的损失函数,该方法鼓励聚类内具有同质化的未来结果分布。实验在真实世界数据集上验证了模型的优
文章目录
1.文章

-
论文出处:ICML 2020
-
【摘要】:由于现代电子健康记录的普及,病人护理数据通常以时间序列的形式存储。对此类时间序列数据进行聚类对于患者表型分析、通过识别 “相似 ”患者预测患者预后以及设计针对同质患者亚群的治疗指南至关重要。在本文中,我们开发了一种对时间序列数据进行聚类的深度学习方法,其中每个聚类由具有相似未来结果(如不良事件、合并症的发生)的患者组成。为了鼓励每个聚类具有同质的未来结果,聚类是通过学习离散表示来进行的,离散表示能根据新的损失函数最好地描述未来结果分布。在两个真实世界数据集上的实验表明,我们的模型实现了优于最先进基准的聚类性能,并识别出有意义的聚类,这些聚类可转化为临床决策的可操作信息。
2.问题背景
-
慢性疾病——如囊性纤维化和老年痴呆——在本质上是异质的,即使在患者亚群中,其结果也有很大差异
-
慢性疾病发展缓慢,容易导致共病的发生
-
以前的聚类方法是纯无监督的,它们不考虑患者观察到的结果,即如果疾病的临床表现不同,即使对具有相同结果的患者也会导致异质性聚集
3.拟解决的问题
- 对未来结果的预测与聚类结合起来
4.主要贡献
-
基于给定时间序列的pedictor输出和给定的质心之间的KL散度定义了聚类目标
-
将求解聚类识别的组合问题转化为迭代求解两个子问题:聚类分配优化和质心优化
-
通过采用actor-critic训练,允许通过selector的采样过程进行“反向传播”
-
模型可以识别有意义的聚类,可以转化为临床决策的可操作信息。
5.提出的方法
5.1问题公式化
- 问题定义
给定数据集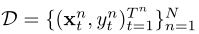 ,它包含N个患者对(X, Y)的观察序列, ( x t n , y t n ) t = 1 T n (x^{n}_t,y^{n}_t)^{T^{n}}_{t=1} (xtn,ytn)t=1Tn对应患者n的 T n T^{n} Tn个观察对的序列, t ∈ T n ≜ { 1 , . . . , T n } t\in T^{n} \triangleq \{1,...,T^{n}\} t∈Tn≜{1,...,Tn}为时间戳,另外,为了省略对n的依赖关系,定义 x 1 : t = { x 1 , . . . , x t } x_{1:t}=\{x_{1},...,x_{t}\} x1:t={x1,...,xt}
,它包含N个患者对(X, Y)的观察序列, ( x t n , y t n ) t = 1 T n (x^{n}_t,y^{n}_t)^{T^{n}}_{t=1} (xtn,ytn)t=1Tn对应患者n的 T n T^{n} Tn个观察对的序列, t ∈ T n ≜ { 1 , . . . , T n } t\in T^{n} \triangleq \{1,...,T^{n}\} t∈Tn≜{1,...,Tn}为时间戳,另外,为了省略对n的依赖关系,定义 x 1 : t = { x 1 , . . . , x t } x_{1:t}=\{x_{1},...,x_{t}\} x1:t={x1,...,xt}
-
目标是为时间序列数据划分K个预测聚类集合, C = C ( 1 ) , ⋅ ⋅ ⋅ , C ( K ) C = {C(1),···,C(K)} C=C(1),⋅⋅⋅,C(K)
-
与传统方法不同,我们将每个时间序列的子序列作为数据样本,即将 { { x 1 : t n } t = 1 T n } n = 1 N \{\{x^{n}_{1:t}\}^{T^{n}}_{t=1}\}^N_{n=1} {{x1:tn}t=1Tn}n=1N划分到C中,因此定义一个cluster为
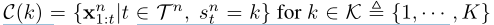
其中 s k n ∈ K s^n_k \in \mathcal K skn∈K是给定 x 1 : t n x^n_{1:t} x1:tn的聚类分配 -
KL散度公式
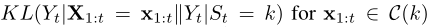
等价于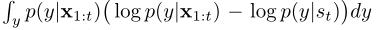
-
优化目标:
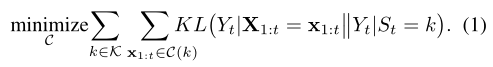
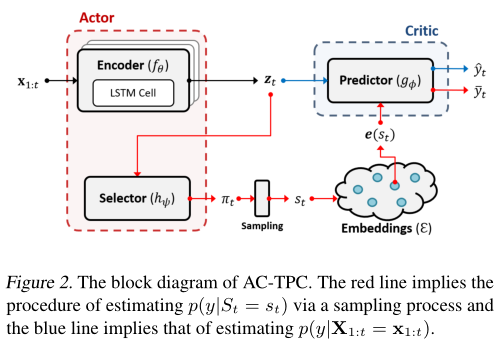
5.2模型结构
-
encoder:
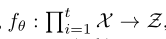
是一个RNN,将时间序列映射为隐藏表示 -
selector:
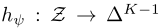
为一个FNN,提供了一个类别分布的概率映射 -
predictor:
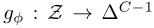
为一个FNN,它根据时间序列的编码或聚类的质心估计标签分布 -
embedding dictionary:
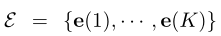
其中e(k) ∈ Z for k ∈ K,是一组位于潜在空间中的聚类质心,它代表了相应的聚类。
5.3损失函数
-
Predictive Clustering Loss:
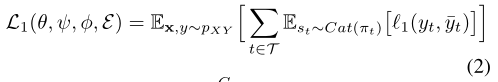
其中,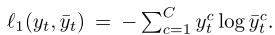
-
然而所有嵌入可能会坍陷到一个点中,或者选择器简单地将相等的概率分配给所有集群,为了解决这一问题,引入两个辅助损失函数
-
Sample-Wise Entropy of Cluster Assignment:

其中,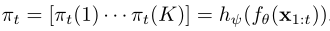 ,当πt为独热向量时,采样熵达到最小值
,当πt为独热向量时,采样熵达到最小值 -
Embedding Separation Loss:
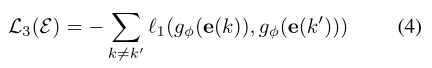
5.4优化
-
由于预测聚类的寻找包含了不可微的抽样过程,所以采用actor-critic模型进行训练
-
将编码器(fθ)和选择器(hψ)的组合看作由 ω A = [ θ , ψ ] ω_A = [θ, ψ] ωA=[θ,ψ]参数化的actor,把预测器(gφ)看作critic,critic将actor的输出(即聚类分配)作为输入,并基于给定所选的聚类的样本预测聚类损失
-
当 embedding dictionary E E E 固定时,通过最小化预测聚类损失 L 1 L_1 L1 和聚类分配的熵 L 2 L_2 L2 的组合来训练 actor,公式为:
L A ( θ , ψ , φ ) = L 1 ( θ , ψ , φ ) + α L 2 ( θ , ψ ) , 其中 α ≥ 0 \mathcal{L}_A(\theta, \psi, \varphi) = \mathcal{L}_1(\theta, \psi, \varphi) + \alpha \mathcal{L}_2(\theta, \psi), \quad \text{其中} \; \alpha \geq 0 \; LA(θ,ψ,φ)=L1(θ,ψ,φ)+αL2(θ,ψ),其中α≥0是用来平衡两个损失的系数。 E \mathcal{E} E、 ℓ 1 \ell_1 ℓ1 和 ℓ 2 \ell_2 ℓ2 分别表示 H H H 的输入嵌入字典,预测聚类损失和聚类分配熵。 -
在训练
Actor的同时,通过最小化预测聚类损失 L 1 L1 L1来训练Critic,即predictor: L C ( φ ) = L 1 ( θ , ψ , φ ) LC(\varphi) = L1(\theta, \psi, \varphi) LC(φ)=L1(θ,ψ,φ) -
当固定三个网络的参数时,通过最小化预测聚类损失L1和嵌入分离损失L3的组合来更新E中的嵌入
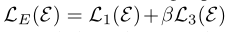
5.5参数初始化
-
对编码器和预测器进行预训练,在给定输入序列潜在编码的情况下,根据预测的标签分布最小化以下损失函数
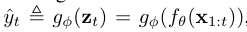 ,
,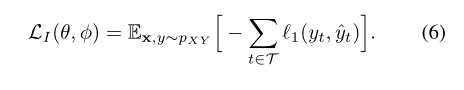
-
使用K-means初始化嵌入E和聚类分配
-
通过最小化交叉熵来预训练选择器hψ,将初始化的聚类分配视为真正的聚类
5.6算法伪代码



6.实验
6.1模型设置
-
数据集:两个真实世界数据,英国囊性纤维化登记处数据集(UKCF)和阿尔茨海默病神经成像计划数据集 (ADNI)
-
评价指标
-
聚类指标:纯度、NMI、ARI、SI
-
预测指标:AUROC、AUPRC
6.2Benchmarks
-
Dynamic time warping followed by K-means:
-
K-means with deep neural networks:
-
Extensions of DCN
-
SOM-VAE
-
部分Benchmarks的结构图
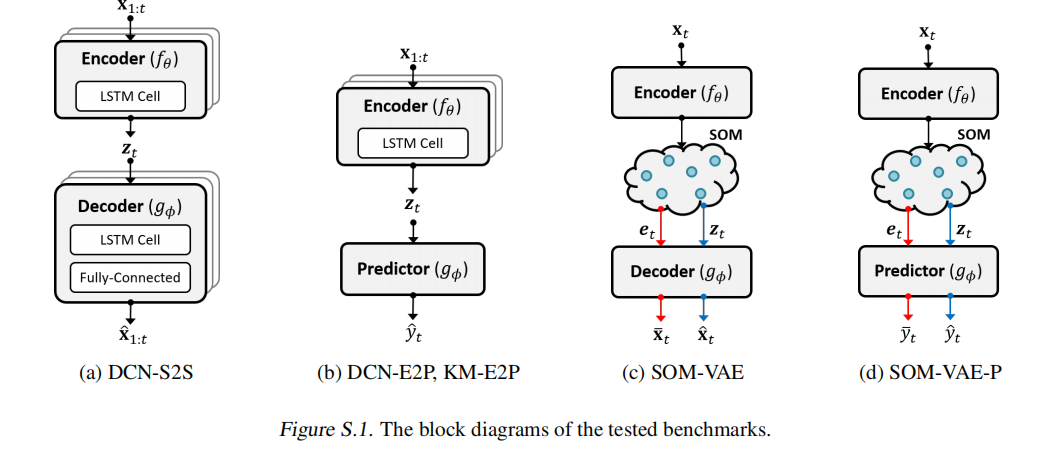

6.3实验结果
-
聚类和预测性能实验结果
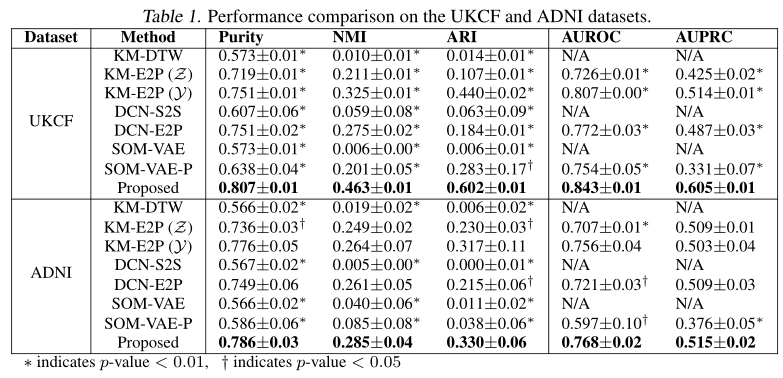
-
不同K的簇数对模型聚类性能的影响

-
不同K的簇数对模型预测性能的影响
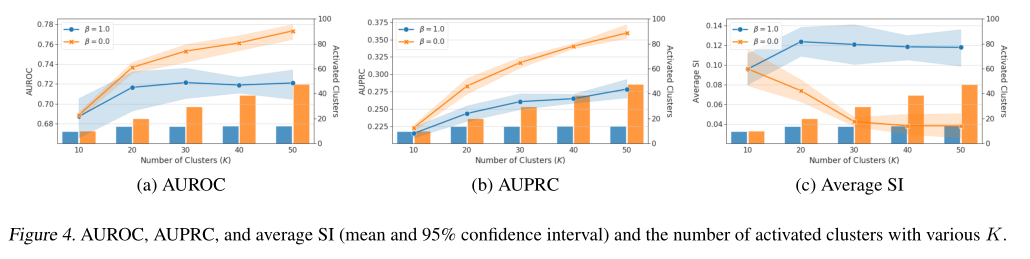
-
发展成糖尿病的高危人群
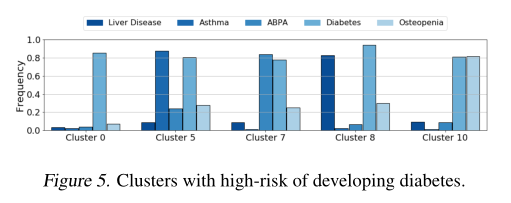
-
聚类和预测之间的权衡

7.结论
-
本文提出了一种用于时间序列数据预测聚类的深度学习方法AC-TPC,定义了新的损失函数,以鼓励每个聚类具有同质的未来结果(例如,不良事件、共病的发生等)
-
同时设计了优化程序,以避免在确定聚类分配和质心时出现琐碎的解决方案
-
通过在两个真实数据集上的实验,提出的模型比最先进的方法获得了更好的聚类性能,并识别出有意义的聚类,可以转化为临床决策的可操作信息
8.个人观点
-
本文所提出的方法主要局限在医疗数据集上,至于是否对其他常见的时间序列数据集,其性能是否会好,有待验证
-
个人认为,文中的一个启发点是结合聚类和预测,实现了比其他模型更好的性能,那我们是否也可以利用预测,提高聚类性能呢
-
文中的损失函数是通过最小化KL散度,并为了避免所有嵌入可能会坍陷到一个点中,或者选择器简单地将相等的概率分配给所有集群,引入两个辅助损失函数,这个损失函数对其他模型是否有用,有待验证

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)