使用 TensorFlow 实现神经网络
我们还提供了 batch_size,e 它的作用是将我们的数据分成小批量,并将其提供给我们的模型在每个 epoch 进行训练,当您拥有大型数据集时,这非常有用,因为它减少了机器上的 RAM 和 CPU 消耗。就像你有不同的列,在 1 列中,你的值范围是 1-10,但在另一列中,它的范围是 100-1000,建议首先将所有列缩放到相同的范围以获得更好的性能。在本文中,我们无法深入讨论激活函数,但基本
深度学习在这十年中一直在兴起,其应用是如此广泛和惊人,以至于几乎很难相信它的进步仅仅短短几年。深度学习的核心是一个基本的“单元”,它支配着它的架构,是的,就是神经网络。
神经网络架构由许多神经元或我们所说的激活单元组成,这个单元回路的作用是寻找数据中的潜在关系。数学证明,神经网络可以找到任何类型的关系/函数,无论其复杂性如何,只要它足够深入/优化,这就是它的潜力。
现在,我们来学习如何使用 TensorFlow 实现神经网络
安装 Tensorflow
Tensorflow 是由 Google 创建并开源的库/平台。它是深度学习应用程序中最常用的库。现在,创建神经网络可能不是 TensorFlow 库的主要功能,但它经常用于此目的。因此,在继续之前,让我们安装并导入 TensorFlow 模块。
使用 pip/conda 命令在系统中安装 TensorFlow
# terminal/zsh/cmd command
# pip
pip install tensorflow --upgrade
# conda
conda install -c conda-forge tensorflow
%tensorflow_version 2.x
下载并读取数据
您可以使用任何您想要的数据集,这里我使用了 Kaggle 的红葡萄酒质量数据集。这是一个分类问题,当然,你可以学习将这个概念应用到其他问题中。首先,在您的工作目录中下载数据集。现在数据已下载,让我们将数据加载为数据帧。
- Python3 语言
import numpy as np
import pandas as pd
# be sure to change the file path
# if you have the dataset in another
# directly than the working folder
df = pd.read_csv('winequality-red.csv')
df.head()
|
输出:

数据预处理/拆分为 Train/Valid/Test Set
有多种方法可以拆分数据,您可以定义自定义函数或使用时间戳(如果存在),也可以使用预定义函数,例如 train_test_split in scikit-learn。
在这里,我们使用 sample 函数获取 75% 的数据来创建训练集,然后将其余数据用于验证集。您也可以而且应该创建一个测试集,但这里我们有一个非常小的数据集,我们在这里的主要重点是熟悉该过程并训练神经网络,对吗?
现在让我们划分数据集。
- Python3 语言
import tensorflow as tf
# 75% of the data is selected
train_df = df.sample(frac=0.75, random_state=4)
# it drops the training data
# from the original dataframe
val_df = df.drop(train_df.index)
|
需要注意的是,神经网络通常对相同范围内的数据执行得更好。就像你有不同的列,在 1 列中,你的值范围是 1-10,但在另一列中,它的范围是 100-1000,建议首先将所有列缩放到相同的范围以获得更好的性能。
现在,最简单的方法是:
值 — (列的最小值)/(列的范围)
- Python3 语言
# calling to (0,1) range
max_val = train_df.max(axis= 0)
min_val = train_df.min(axis= 0)
range = max_val - min_val
train_df = (train_df - min_val)/(range)
val_df = (val_df- min_val)/range
|
既然我们已经完成了扩展数据并创建训练和验证数据集,那么让我们将其分为特征,即输入和目标,因为这就是我们将其传递给模型的方式。
- Python3 语言
# now let's separate the targets and labels
X_train = train_df.drop('quality',axis=1)
X_val = val_df.drop('quality',axis=1)
y_train = train_df['quality']
y_val = val_df['quality']
# We'll need to pass the shape
# of features/inputs as an argument
# in our model, so let's define a variable
# to save it.
input_shape = [X_train.shape[1]]
input_shape
|
输出:
[11]
这意味着我们将 11 个特征作为输入传递到神经网络的第一层。
创建模型神经网络
Keras 模块构建在 TensorFlow 之上,为我们提供了创建各种神经网络架构的所有功能。我们将使用 Keras 中的 Sequential 类来构建我们的模型。首先,您可以尝试使用线性模型,因为神经网络基本上遵循与回归相同的“数学”,因此您可以使用神经网络创建线性模型,如下所示:
创建线性模型
- Python3 语言
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1,input_shape=input_shape)])
# after you create your model it's
# always a good habit to print out it's summary
model.summary()
|
输出:
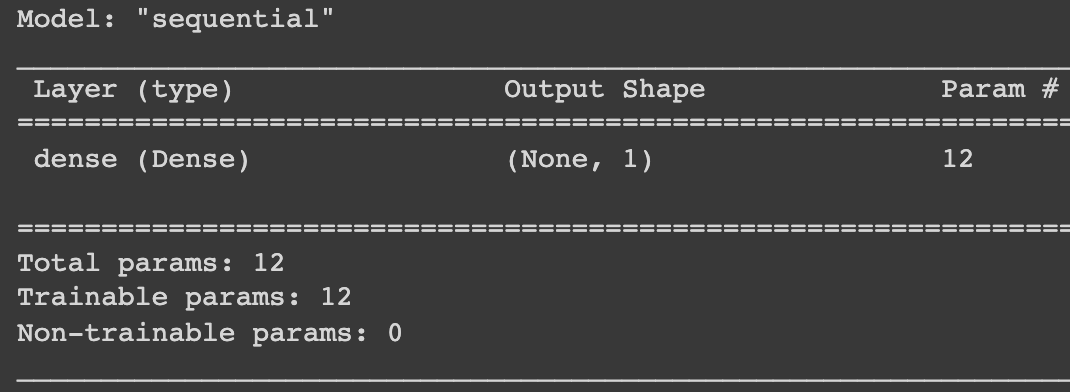
但这基本上是一个线性模型,如果你的数据集稍微复杂一些,特征之间的关系更加多样化,你想要一个非线性模型怎么办?您需要什么?答案是激活函数。这就是神经网络真正开始大放异彩的地方。在本文中,我们无法深入讨论激活函数,但基本上,这些函数为我们的模型添加/引入非线性,你使用它们的次数越多,我们的模型可以找到的模式就越复杂。
创建多层神经网络
我们将创建一个 3 层网络,其中包含 1 个输入层、1 个隐藏层 1(具有 64 个单元)和 1 个输出层。我们将在隐藏层中使用 'relu' 激活函数。我们将在 Keras 模块中使用 Sequential 方法,该方法通常用于创建多层神经网络。在 keras 中,我们有不同类型的神经网络层和/或转换层,你可以使用它们来构建各种类型的神经网络,但这里我们只使用了 3 个具有 relu 激活函数的 Dense 层(在 keras.layers 中)。
- Python3 语言
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=64, activation='relu',
input_shape=input_shape),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=1)
])
model.summary()
|
输出:
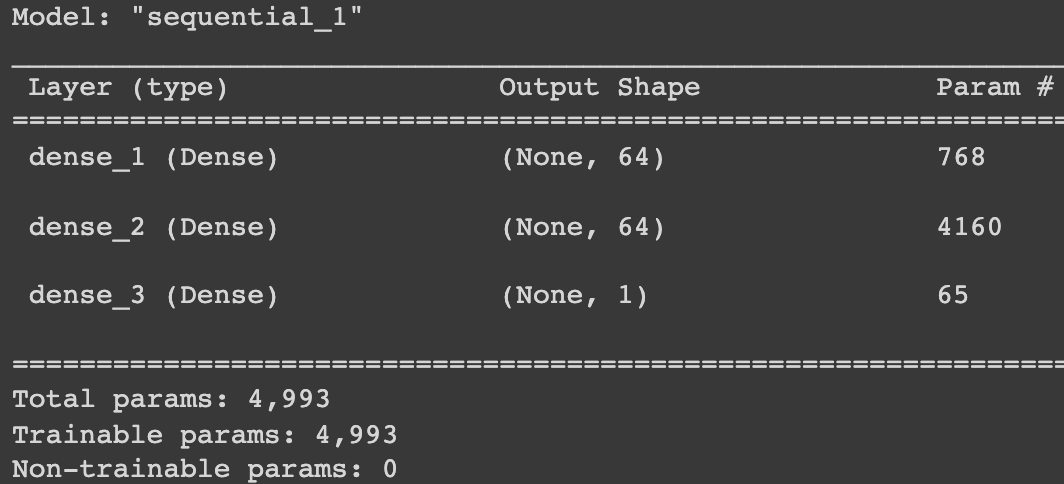
在 Keras 中创建模型后,您需要为其“编译”其他参数,如下所示。这有点像我们为模型设置所有参数。
- Python3 语言
# adam optimizer works pretty well for
# all kinds of problems and is a good starting point
model.compile(optimizer='adam',
# MAE error is good for
# numerical predictions
loss='mae')
|
因此,我们使用了 adam 优化器,并告诉模型计算 mae(平均绝对误差)损失。
训练模型
既然我们已经完成了模型的创建和实例化,现在是时候训练它了。我们将使用 fit 方法来训练我们的模型。这种方法以特征和目标为目标,我们也可以随之传递validation_data,它会自动在验证时尝试你的模型并记录损失指标。我们还提供了 batch_size,e 它的作用是将我们的数据分成小批量,并将其提供给我们的模型在每个 epoch 进行训练,当您拥有大型数据集时,这非常有用,因为它减少了机器上的 RAM 和 CPU 消耗。
现在,我们只训练了 15 个 epoch 的模型,因为我们的目的是熟悉过程,而不是准确性本身,但您必须增加或减少机器上的 epoch 数。您可以使用一些优化方法,例如提前停止,当模型开始过拟合时会自动停止训练,因此您也可以尝试使用这些方法,如果您想阅读它,我在底部提供了一个链接。
- Python3 语言
losses = model.fit(X_train, y_train,
validation_data=(X_val, y_val),
# it will use 'batch_size' number
# of examples per example
batch_size=256,
epochs=15, # total epoch
)
|
输出:

在这里,我们只训练了 15 个 epoch,但您绝对应该训练更多并尝试更改模型本身。
生成预测并分析准确性
既然我们已经完成了训练过程,那么让我们实际尝试使用它来预测 “葡萄酒质量”。为了进行预测,我们将使用 model 对象的 predict 函数。我们只给出 3 个示例作为输入,并尝试预测 3 个示例的葡萄酒质量。
- Python3 语言
# this will pass the first 3 rows of features
# of our data as input to make predictions
model.predict(X_val.iloc[0:3, :])
|
输出:
array([[0.40581337],
[0.5295989 ],
[0.3883106 ]], dtype=float32)
现在,让我们将预测与目标值进行比较。
- Python3 语言
y_val.iloc[0:3]
|
输出:
0 0.4
9 0.4
12 0.4
Name: quality, dtype: float64
正如我们所看到的,我们的预测非常接近实际值,即在所有三种情况下都是 0.4。你可以定义另一个函数,将预测转换为整数,以 1 到 10 的等级预测质量,以便更好地理解,但这是一件微不足道的事情,主要是让你理解这里描述的整个过程。
可视化训练与验证损失
您可以分析损失并弄清楚它是否过度拟合或不容易,然后相应地采取适当的措施。
- Python3 语言
loss_df = pd.DataFrame(losses.history)
# history stores the loss/val
# loss in each epoch
# loss_df is a dataframe which
# contains the losses so we can
# plot it to visualize our model training
loss_df.loc[:,['loss','val_loss']].plot()
|
输出:
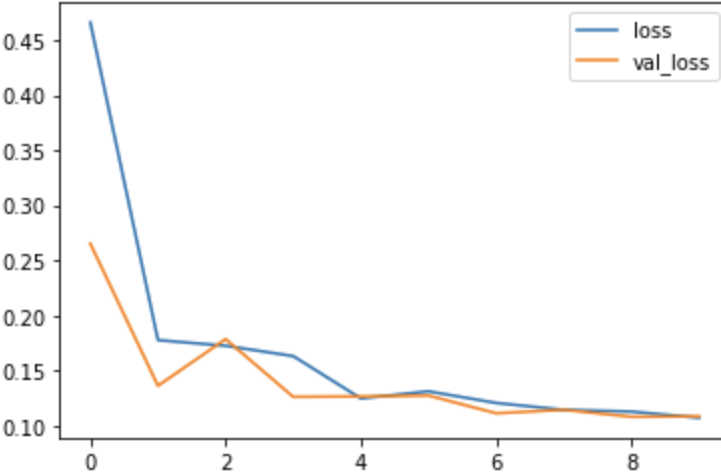
在分析模型的准确性/误差时,需要注意的关键点是:
显然,您的损失函数会不断减小,但验证数据集可能并非如此,在某些时候,您的模型将过度拟合数据,验证误差将开始增加而不是减少。因此,您可以在 validation loss 似乎正在增加的 epoch 停止。您还可以尝试一些其他优化算法,例如提前停止(Keras 中的 callback)。您可以在此处阅读相关信息。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)