【时间序列聚类】Time-Series Clustering Based on the Characterization of Segment Typologies(基于分段类型特征的时间序列聚类)
时间序列聚类旨在根据相似性或特征对时间序列进行分组。传统方法结合特定距离测量和标准聚类技术,但未充分考虑不同子序列的相似性。本文提出一种两阶段时间序列聚类技术。第一阶段通过最小二乘多项式分割程序生成片段,并基于近似线段模型系数和统计特征将片段投影到一维空间。随后,进行第一次分层聚类以提取片段组。第二阶段定义特定映射过程,在同一维空间中表示所有时间序列并最终分组。算法自动调整主要参数,即误差阈值,考
文章目录
1.文章介绍

-
论文出处:IEEE TRANSACTIONS ON CYBERNETICS 2021
(SCI 1区,CCF-B) -
暂无代码
-
【摘要】:时间序列聚类是根据时间序列的相似性或特征对其进行分组的过程。以往的方法通常将时间序列的特定距离测量和标准聚类方法结合起来。然而,这些方法并没有考虑每个时间序列的不同子序列的相似性,而这种相似性可以用来更好地比较数据集的时间序列对象。在本文中,我们提出了一种由两个聚类阶段组成的新型时间序列聚类技术。第一步,对每个时间序列应用最小二乘多项式分割程序,该程序基于增长窗口技术,可返回不同长度的片段。然后,根据近似线段模型的系数和一组统计特征,将所有线段投影到同一维空间。映射完成后,第一个分层聚类阶段将应用于所有映射的片段,返回每个时间序列的片段组。在定义另一个特定的映射过程后,这些聚类用于在同一维空间中表示所有时间序列。在第二个也是最后一个聚类阶段,对所有时间序列对象进行分组。我们考虑内部聚类质量,自动调整算法的主要参数,即分割的误差阈值。在 UCR 时间序列分类档案中的 84 个数据集上获得的结果已经过比较。
2.问题背景
- 以前的方法并没有考虑每个时间序列的不同子序列的相似性,然而这可以用来更好地比较数据集的时间序列对象
3.拟解决的问题
- 将每个时间序列的子序列的差异引入聚类算法中
4.主要贡献
- 使用了一种新的时间序列特征提取来减少这些时间序列的大小,同时又不丢失太多信息。
5.提出的方法
5.1算法伪代码

5.2两阶段统计分段聚类时间序列方法
5.2.1第一阶段
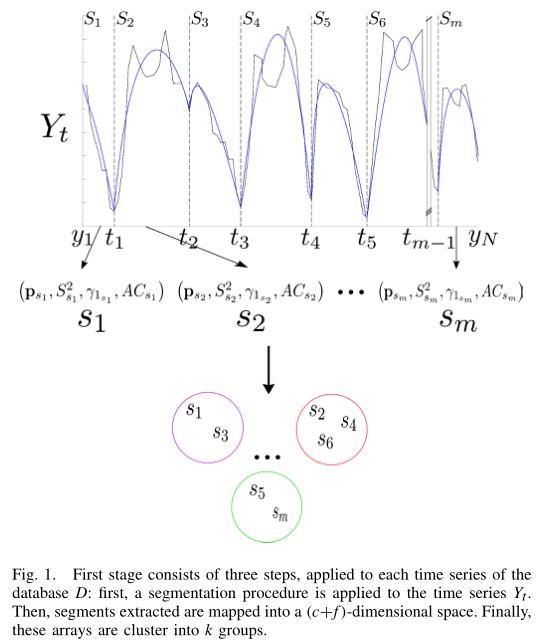
时间序列分割
-
定义:给定一个长度为 N i N_i Ni的给定时间序列,分割由 t = { t s } s = 1 m t = \{t_s\}_{s=1}^m t={ts}s=1m个切点定义的 m m m段。这样,分段 S S S的集合= { s 1 , s 2 , … , s m } \{s_1, s_2,…, s_m\} {s1,s2,…,sm},其中 s 1 = { y 1 , … , y t 1 } s_1 = \{y_1,…, y_{t_1}\} s1={y1,…,yt1}, s 2 = { y t 1 , … , y t 2 } s_2 = \{y_{t_1},…, y_{t_2}\} s2={yt1,…,yt2},…, s m = { y t m − 1 , … , y N i } s_m = \{y_{t_{m-1}},…, y_{N_i}\} sm={ytm−1,…,yNi}
-
本文中采用的是SwiftSeg,该算法迭代地将时间序列中的点引入一个不断增长的窗口中,同时更新相应的分段的最小二乘多项式近似及其误差。窗口不断增长,直到超过error阈值,引入一个切点( t s t_s ts),分割结束。这个过程一直重复,直到到达时间序列的末尾。
-
错误函数SEP(standard error of prediction):

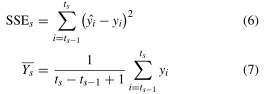
式中, y i y_i yi 为第 i i i 时刻的时间序列值, y i ^ \hat{y_i} yi^ 为其对应的最小二乘多项式近似。这个误差函数的优点是它不考虑每个段的值的规模。
片段映射
-
每个片段被映射到一个数组中,包括段的最小二乘近似的多项式系数和一组统计特征,故每个线段被映射到I维空间,其中I为映射线段的长度
-
统计特征
-
方差:
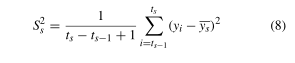
-
偏态

-
自回归系数
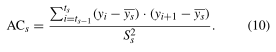
- 每个段被映射到一个 l l l 维数组 ( l = c + f l = c + f l=c+f),用作片段表示,其中 c c c 是多项式的次数, f f f 是统计特征的数量, f = 3 f = 3 f=3
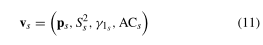
其中 p s p_s ps是近似于片段 s s s的多项式近似的参数
片段聚类
- 使用agglomerative的层次聚类,相似性度量采用的是Ward距离,聚类类别数设置2,
5.2.2第二阶段
时间序列映射
- 对于每个时间序列 Y i \mathbf{Y}_{i} Yi, 提取相应的质心,其中 i ∈ { 1 , … , T } i \in \{1, \dots, T\} i∈{1,…,T}, j ∈ { 1 , … , k } j \in \{1, \dots, k\} j∈{1,…,k},其中 k k k 为簇的个数, T T T 为时间序列的个数。对于每个 cluster,提取以下信息:
-
质心 c i j ^ \hat{c_{ij}} cij^
-
方差较大的片段的映射 X C i j X_{C_{ij}} XCij
-
映射结果为:
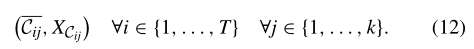
-
映射的时间序列的长度为 ( w × k ) + v (w \times k) + v (w×k)+v,其中 k k k为集群的数量, v v v为时间序列的额外信息的数量,这里设置为2。
时间序列聚类
- 采用agglomerative的层次聚类
5.3参数设置
-
TS3C算法的参数只涉及分割过程的错误阈值SEPmax
-
错误阈值SEPmax的设置可以通过以下两种方式进行设置
-
选择SEPmax能够获得最佳的CH指数
-
选择能获得最多内部测量数的最佳值的SEPmax,即多数表决
6.实验
6.1模型设置
-
数据集:


-
评价指标:
- RI
- 执行时间
6.2实验结果
-
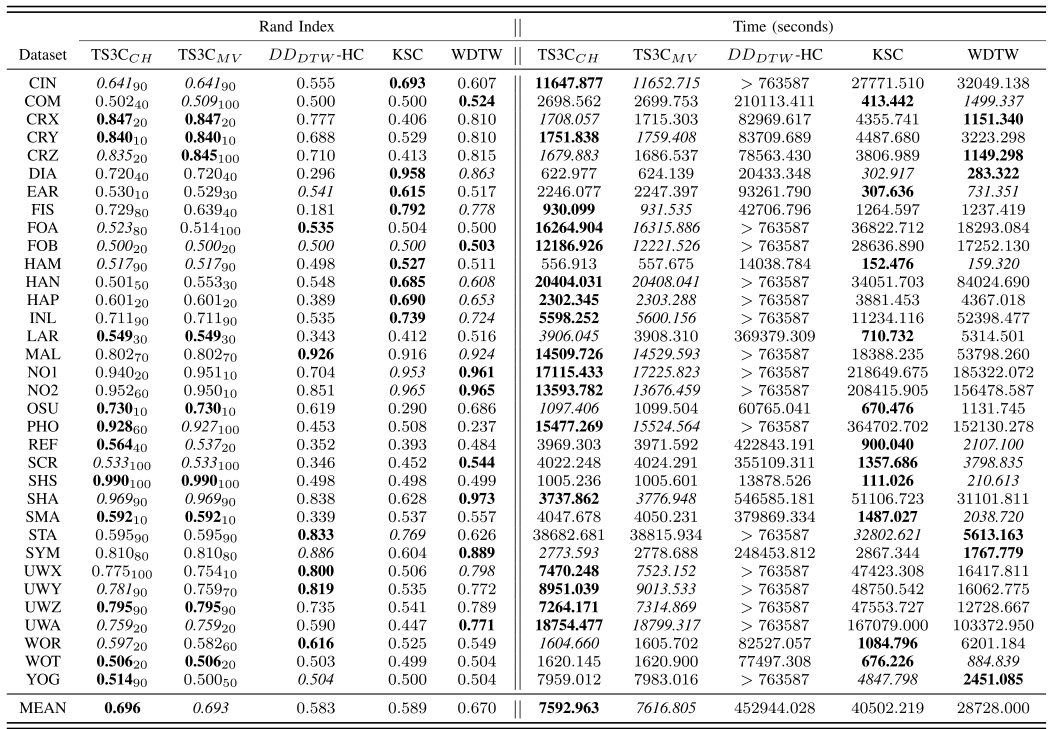
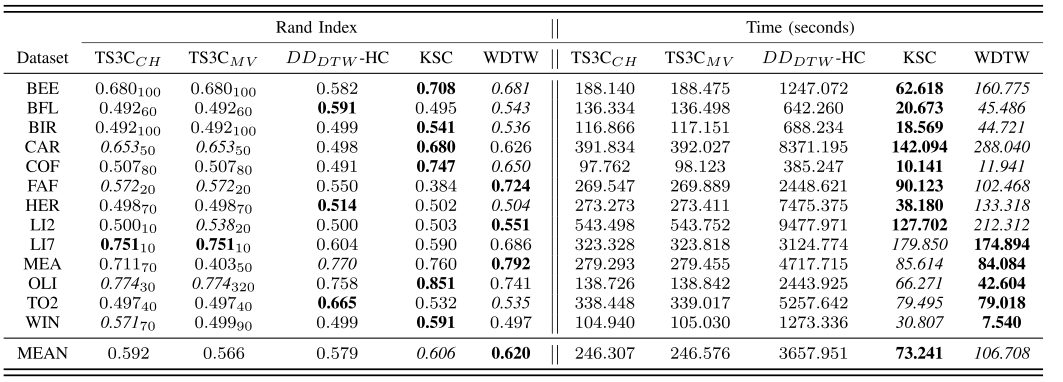
Group1数据集上的实验结果
-
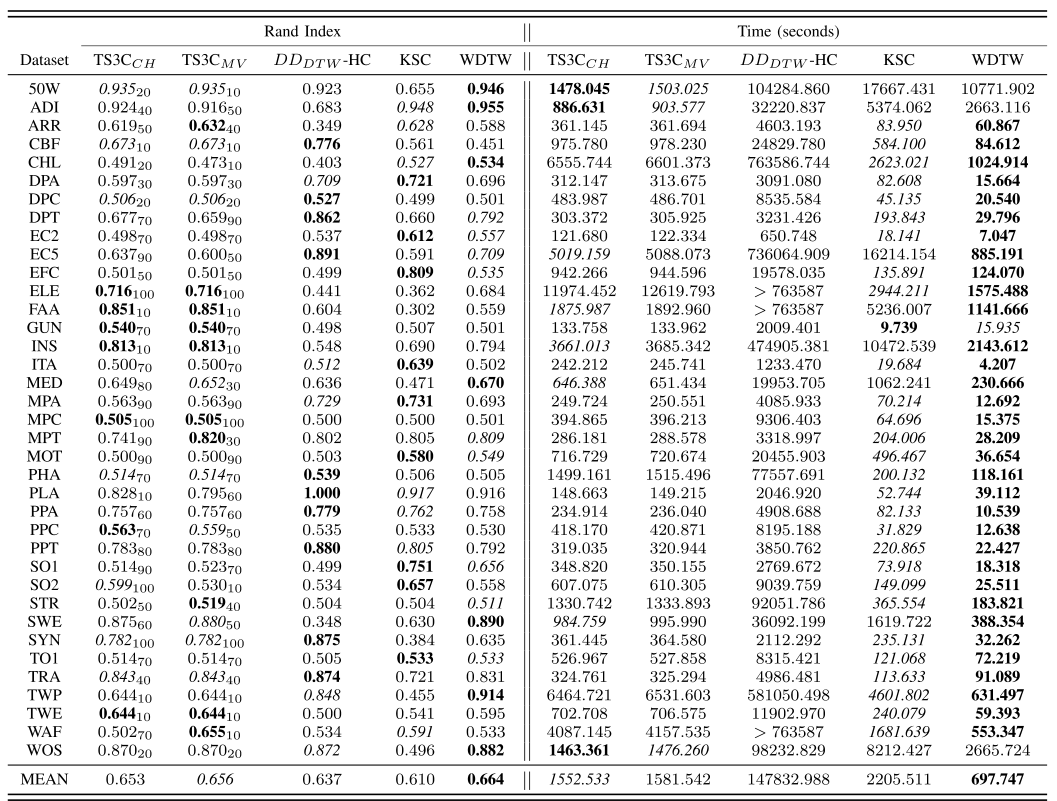
Group2数据集上的实验结果
-
Group3数据集上的实验结果
-
每个数据组的平均排名
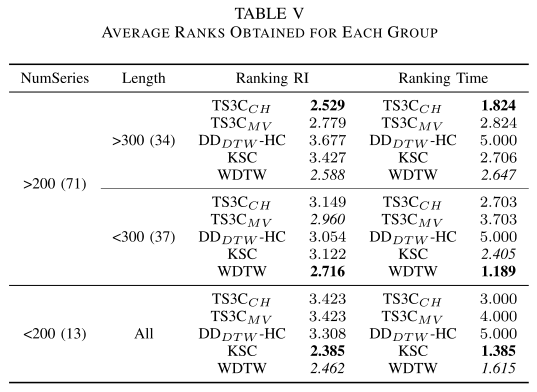
-
假设检验
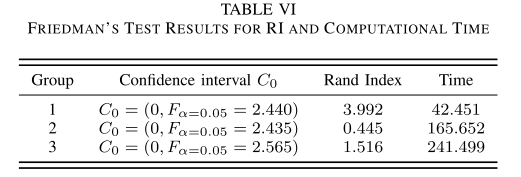
-
由于Friedman检验没有发现组2和组3的RI有显著的统计学差异,使用Holm检验,通过比较第i和第j个算法,计算以下统计量:

其中 J J J 表示算法的数量, T T T 表示数据集的数量, R i R_i Ri 是第 i i i 种方法的排名, R j R_j Rj 是第 j j j 种方法的排名。 -
显著性检验
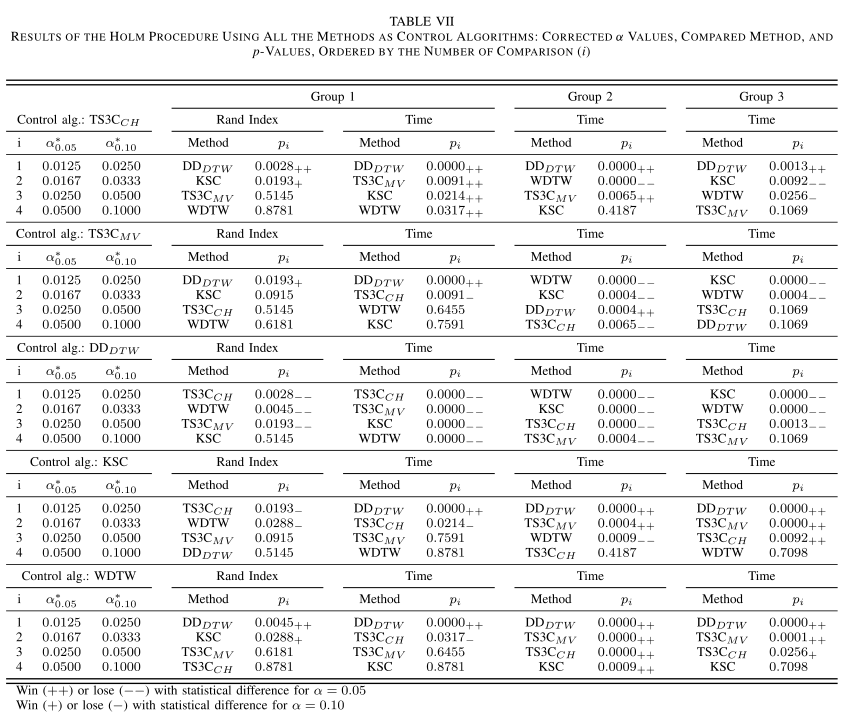
7.结论
- 本文使用了以下方法:
-
最小二乘多项式分割过程,使用增长窗口法
-
提取每个时间序列片段的特征(多项式趋势系数、方差、偏度和自相关系数)
-
使用分层聚类对这些特征进行聚类
-
每个聚类的质心、方差较大的时间序列片段、均方误差的差值和段数的表示
-
利用时间序列簇的信息对时间序列进行映射
-
最后的聚类阶段使用映射的数据集作为输入,内部性能度量用于调整唯一的参数值。
8.个人观点
-
对原始时间序列的分割方式为SwiftSeg,即迭代地将时间序列中的点引入一个不断增长的窗口中,同时更新相应的分段的最小二乘多项式近似及其误差。窗口不断增长,直到超过error阈值,引入一个切点(ts),分割结束
-
对原始时间序列进行分割后,计算每个时间序列片段的统计特征,如方差、偏度、自回归系数,将这些统计特征用于层次聚类

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)