GMLP【Pytorch实现 超详细】
GMLP 的出现背景与Transformer模型及其核心组件——自注意力机制(Self-Attention)有关。Transformer在自然语言处理等领域取得了显著成功,但其自注意力机制存在计算复杂度高、内存消耗大等问题,尤其是在处理长序列时。
·
 GMLP 的出现背景与Transformer模型及其核心组件——自注意力机制(Self-Attention)有关。Transformer在自然语言处理等领域取得了显著成功,但其自注意力机制存在计算复杂度高、内存消耗大等问题,尤其是在处理长序列时。
GMLP 的出现背景与Transformer模型及其核心组件——自注意力机制(Self-Attention)有关。Transformer在自然语言处理等领域取得了显著成功,但其自注意力机制存在计算复杂度高、内存消耗大等问题,尤其是在处理长序列时。
背景
研究者开始探索替代自注意力机制的方法,以降低计算复杂度和内存消耗,同时保持或提升模型性能。
GMLP基于多层感知机,通过门控机制增强模型表达能力,主要特点包括:
-
门控机制:引入门控单元,动态调整信息流动,提升模型灵活性。
-
简化结构:相比Transformer,GMLP结构更简单,计算复杂度更低。
-
长序列处理:GMLP在处理长序列时具有优势,计算复杂度为O(n),适合长序列任务。
整体流程
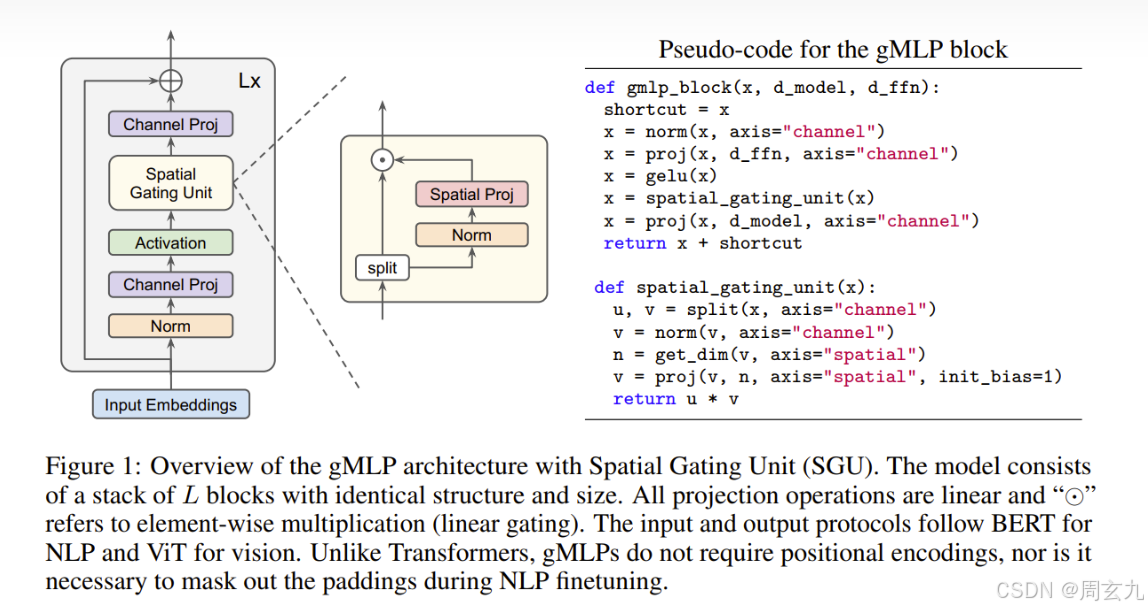
GMLP本质上是Transformer的一种低复杂度替代,我们看整体流程:
输出的句子被整理成embedding,形状为(batch_size,seq_len,d_model)
- 经过一层线性层提取特征,得到隐空间向量Z (batch_size,seq_len,d_ffn)
- 将Z等分成两块,Z1,Z2,对Z2进行一次线性变换,得到提取的更高级特征(门控信号)
- 对Z1,Z2进行逐元素点乘,得到两者交互后的结果
- 将第三步结果过一层线形层,映射出关注全局后的表示
思考:特征向量的交互方式
- add,直接将两个向量加和,计算复杂度最小,适用于两个信息特征很类似,可以抛却其中的很多信息
- concat:多用于多模态信息融合,旨在保留尽可能多的信息,计算复杂度很大
- 逐元素乘:参考attention,一般是为了得到特征对全局进行关注后的表示,用于提取增强的特征。
SGU代码实现
class SpacialGatingUnit(nn.Module):
def __init__(self,d_z:int,seq_len:int):
super().__init__()
#d_z为啥不叫d_ffn,就是经过前馈神经网络后,seq_len则为序列长度
#LayerNorm后边参数加括号指的是可能多个维度,从后往前算起,这里只有一个维度,所以加不加其实一样
self.norm=nn.LayerNorm([d_z//2])
#创建自定义参数,nn.Linear()包含下边俩个成分
self.weight=nn.Parameter(torch.zeros(seq_len,seq_len).uniform_(-0.01,0.01),requires_grad=True)
self.bias=nn.Parameter(torch.ones(seq_len),requires_grad=True)
def forward(self, z: torch.Tensor, mask: Optional[torch.Tensor] = None):
batch_size, seq_len, _ = z.shape
z1, z2 = torch.chunk(z, 2, dim=-1)
if mask is not None:
assert mask.shape == (batch_size, seq_len, seq_len) # 检查掩码形状
weight = self.weight[:seq_len, :seq_len]
weight = weight[None, :, :] # 扩展权重矩阵以匹配掩码的形状
weight = weight * mask # 逐元素相乘
else:
weight = self.weight[:seq_len, :seq_len]
z2 = self.norm(z2)
z2 = torch.einsum('bij,bjd->bid', weight, z2) + self.bias[:seq_len, None, None]
#有三种特征交互方式: z1+z2 :用于两个特征相近的时候融合特征,concat(z1,z2):用于z1,z2来自不同来源,需要尽量保留原始信息的时候,
# z1*z2 :类似于注意力机制,用于门控得出一个增强的表示
return z1 * z2GMLP总体代码实现
class GMLPBlock(nn.Module):
def __init__(self,d_model: int,d_ffn: int,seq_len):
super().__init__()
self.norm=nn.LayerNorm(d_model)
self.activation=nn.GELU()
#nn.Linear()改变的是最后一个维度,nn.Linear的输入可以是任意维度
self.proj1=nn.Linear(d_model,d_ffn)
self.sgu = SpacialGatingUnit(d_ffn, seq_len)
self.proj2=nn.Linear(d_ffn//2,d_model)
self.size=d_model
def forward(self,x, mask: Optional[torch.Tensor] = None):
shortcut=x
x=self.norm(x)
z=self.activation(self.proj1(x))
#(batch_size,seq_len,d_model)
z=self.sgu(z,mask)
z=self.proj2(z)
return z + shortcut
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)