人工智能图像识别 Pytorch实现cifar10多分类2
Pytorch实现cifar10多分类2
一、训练模型
dataiter = iter(testloader)
for i, (imags, labels) in enumerate(dataiter):
#images, labels = images.to(device), labels.to(device)
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruch: ',' '.join('%5s' % classes[labels[j]] for j in range(4)))

images, labels = images.to(device), labels.to(device)
outputs = net(images)
_,predicted = torch.max(outputs, 1)
print('Predicted: ',' '.join('%5s' % classes[predicted[j]]for j in range(4)))

二、测试模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_,predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' %(
100 * correct / total))

class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch. no_grad():
for data in testloader:
images, labels = data
images, labels = images. to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c=(predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))

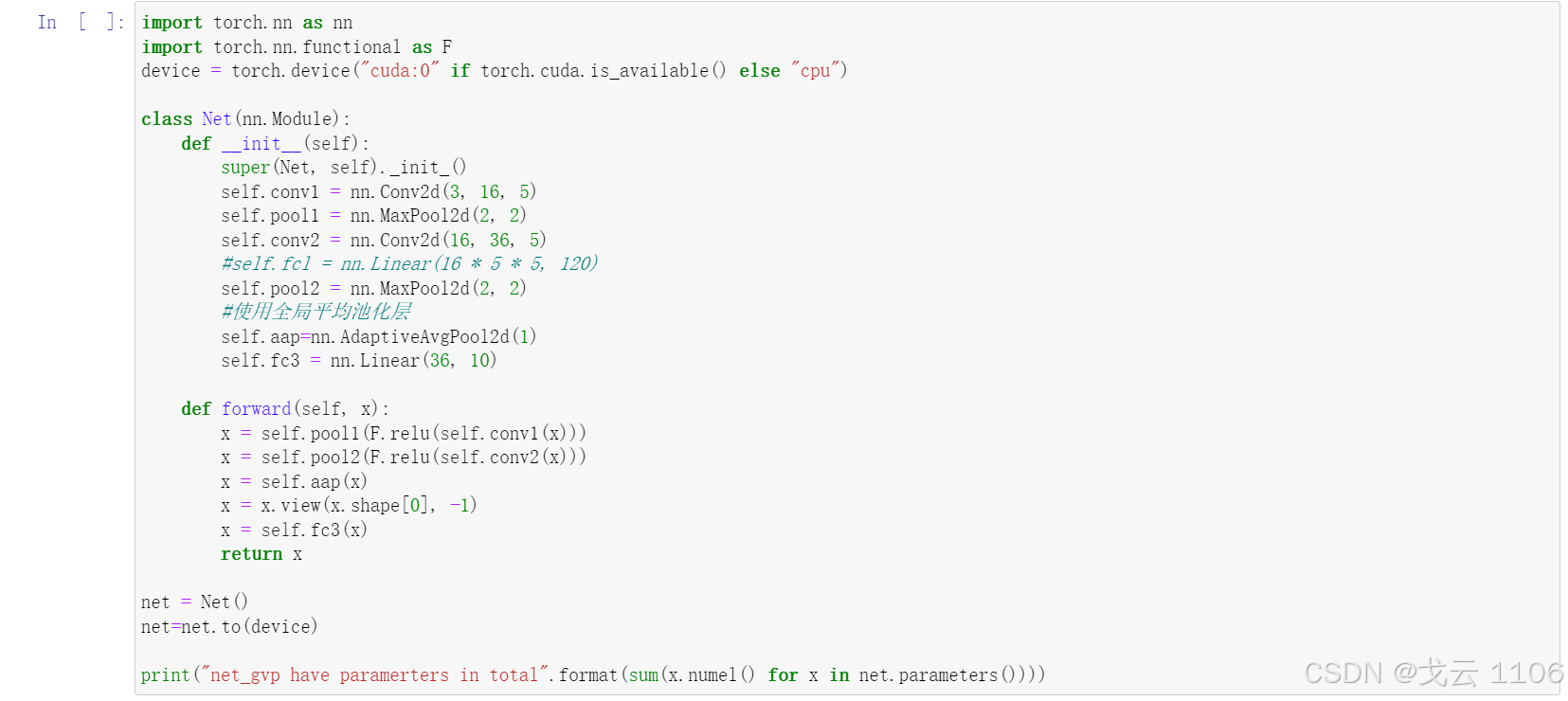
三、采用全局平均池化
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Net(nn.Module):
def __init__(self):
super(Net, self)._init_()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 36, 5)
#self.fcl = nn.Linear(16 * 5 * 5, 120)
self.pool2 = nn.MaxPool2d(2, 2)
#使用全局平均池化层
self.aap=nn.AdaptiveAvgPool2d(1)
self.fc3 = nn.Linear(36, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.aap(x)
x = x.view(x.shape[0], -1)
x = self.fc3(x)
return x
net = Net()
net=net.to(device)
print("net_gvp have paramerters in total".format(sum(x.numel() for x in net.parameters())))
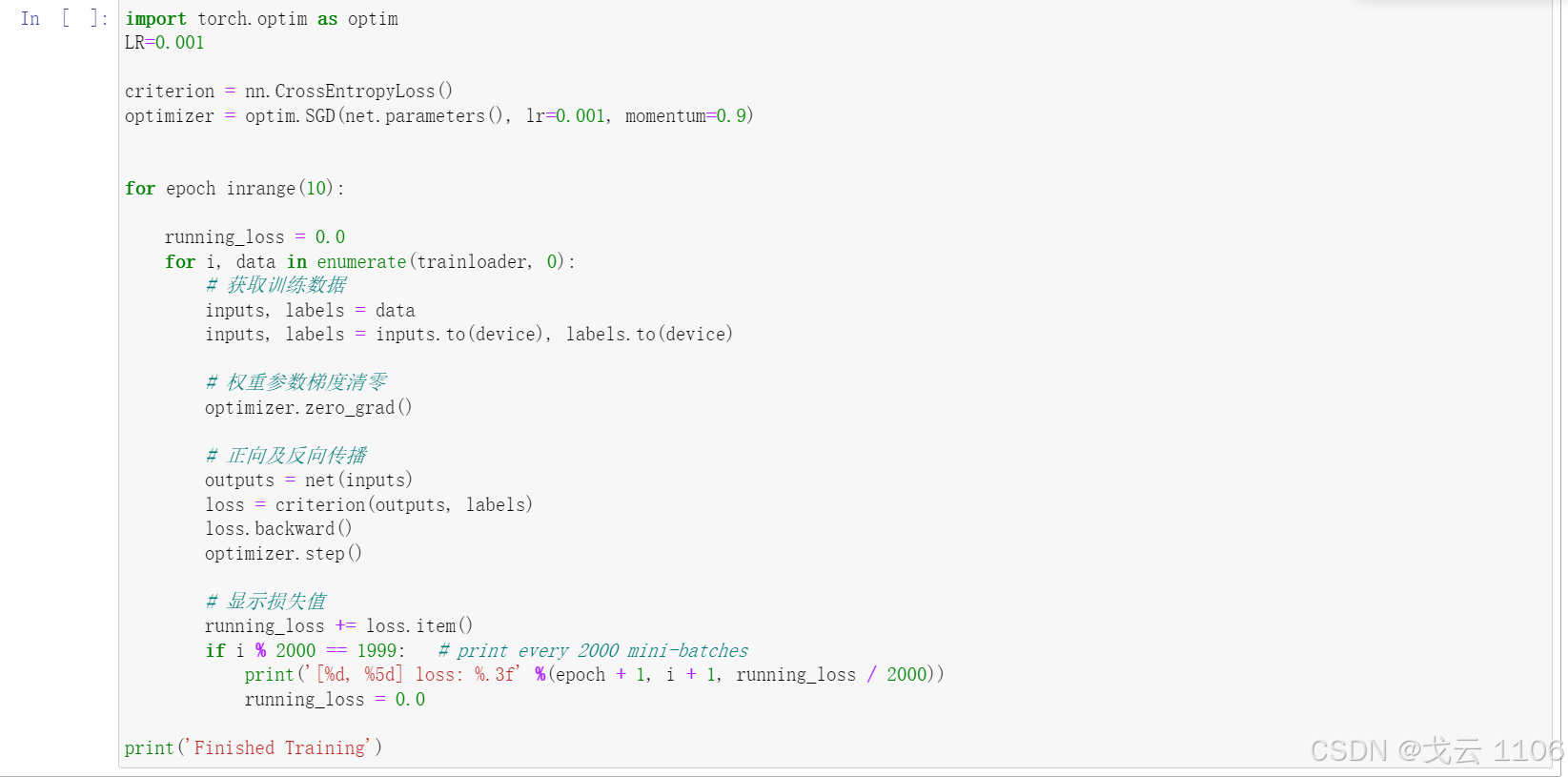
import torch.optim as optim
LR=0.001
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch inrange(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取训练数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# 权重参数梯度清零
optimizer.zero_grad()
# 正向及反向传播
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 显示损失值
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
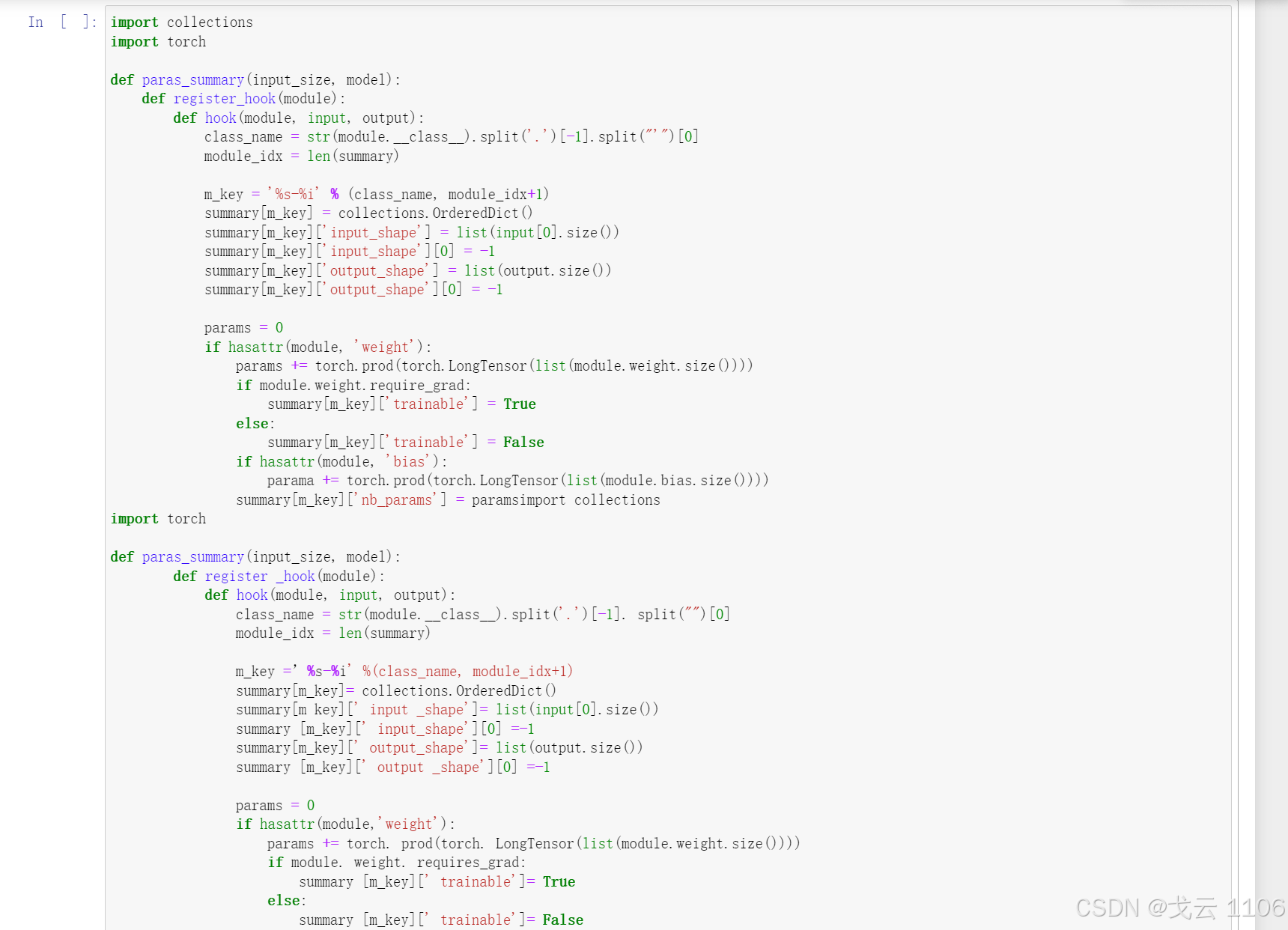
四、像keras一样显示各层参数
import collections
import torch
def paras_summary(input_size, model):
def register_hook(module):
def hook(module, input, output):
class_name = str(module.__class__).split('.')[-1].split("'")[0]
module_idx = len(summary)
m_key = '%s-%i' % (class_name, module_idx+1)
summary[m_key] = collections.OrderedDict()
summary[m_key]['input_shape'] = list(input[0].size())
summary[m_key]['input_shape'][0] = -1
summary[m_key]['output_shape'] = list(output.size())
summary[m_key]['output_shape'][0] = -1
params = 0
if hasattr(module, 'weight'):
params += torch.prod(torch.LongTensor(list(module.weight.size())))
if module.weight.require_grad:
summary[m_key]['trainable'] = True
else:
summary[m_key]['trainable'] = False
if hasattr(module, 'bias'):
parama += torch.prod(torch.LongTensor(list(module.bias.size())))
summary[m_key]['nb_params'] = paramsimport collections
import torch
def paras_summary(input_size, model):
def register _hook(module):
def hook(module, input, output):
class_name = str(module.__class__).split('.')[-1]. split("")[0]
module_idx = len(summary)
m_key =’%s-%i' %(class_name, module_idx+1)
summary[m_key]= collections.OrderedDict()
summary[m key][' input _shape']= list(input[0].size())
summary [m_key][' input_shape'][0] =-1
summary[m_key][' output_shape']= list(output.size())
summary [m_key][' output _shape'][0] =-1
params = 0
if hasattr(module,'weight'):
params += torch. prod(torch. LongTensor(list(module.weight.size())))
if module. weight. requires_grad:
summary [m_key][' trainable']= True
else:
summary [m_key][' trainable']= False
if hasattr(module,'bias'):
params += torch. prod(torch. LongTensor(list(module.bias.size())))
summary [m_key]['nb_params']= params
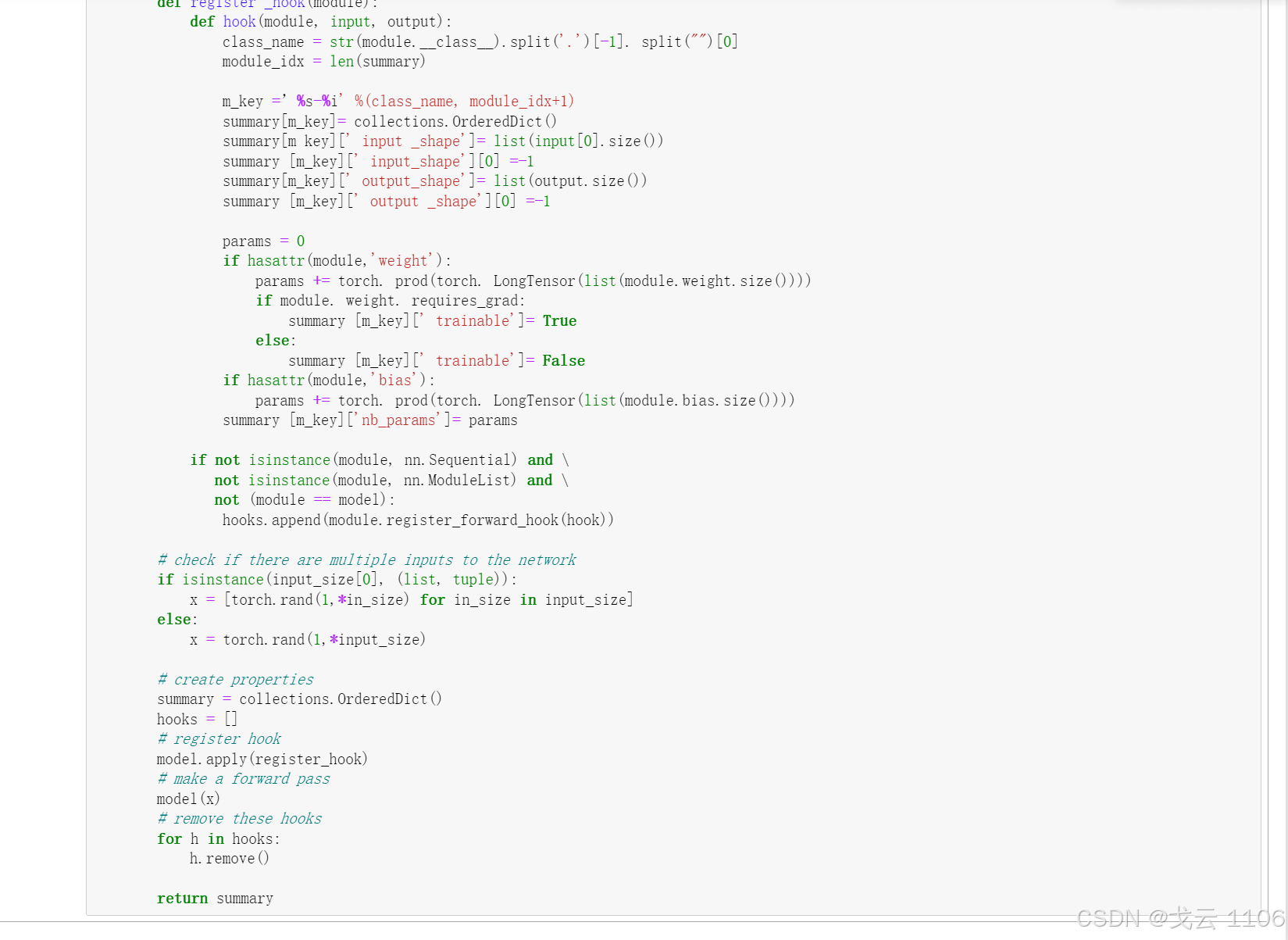
if not isinstance(module, nn.Sequential) and \
not isinstance(module, nn.ModuleList) and \
not (module == model):
hooks.append(module.register_forward_hook(hook))
# check if there are multiple inputs to the network
if isinstance(input_size[0], (list, tuple)):
x = [torch.rand(1,*in_size) for in_size in input_size]
else:
x = torch.rand(1,*input_size)
# create properties
summary = collections.OrderedDict()
hooks = []
# register hook
model.apply(register_hook)
# make a forward pass
model(x)
# remove these hooks
for h in hooks:
h.remove()
return summary

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)