【多视图聚类】Deep Multiview Clustering by Contrasting Cluster Assignments(通过对比聚类分配进行深度多视图聚类)
多视图聚类(MVC)旨在揭示多视图数据的潜在结构,但现有深度学习方法在探索多视图不变表示方面仍具挑战性。本文提出了一种跨视图对比学习(CVCL)方法,通过对比分析多个视图间的聚类分配来学习不变表征并生成聚类结果。该方法采用深度自动编码器提取与视图相关的特征,并在微调阶段引入聚类级别的CVCL策略以探索多视图间的一致语义信息。实验表明,所提出的CVCL方法通过软聚类赋值对齐策略显著提高了聚类区分度,
文章目录
1.文章介绍

-
论文出处:ICCV 2023 (oral,CCF-A)
-
【摘要】:多视图聚类(MVC)旨在通过将数据样本归类为聚类,揭示多视图数据的潜在结构。基于深度学习的方法在大规模数据集上表现出强大的特征学习能力。对于大多数现有的深度 MVC 方法来说,探索多视图的不变表示仍然是一个难以解决的问题。在本文中,我们提出了一种跨视图对比学习(CVCL)方法,通过对比多个视图之间的聚类分配,学习视图不变表示并生成聚类结果。具体来说,我们首先在预训练阶段使用深度自动编码器提取与视图相关的特征。然后,我们提出了一种聚类级别的 CVCL 策略,以在微调阶段探索多个视图之间一致的语义标签信息。因此,通过这种学习策略,所提出的 CVCL 方法能够产生更具区分度的聚类分配。此外,我们还对软聚类赋值对齐进行了理论分析。在多个数据集上获得的大量实验结果表明,所提出的 CVCL 方法优于几种最先进的方法。
2.问题背景
-
多视图数据:通常是由不同类型的特征表示或从多个来源(图像、文本)收集得到的数据,多视图数据中包含的相同语义信息和互补的信息
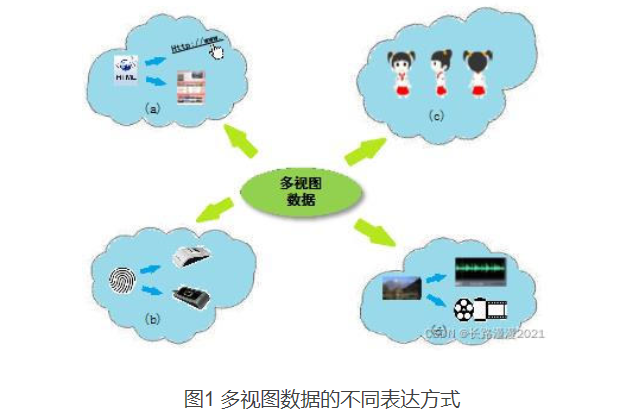
-
多视图学习:在实际应用问题中,对于同一事物可以从多种不同的途径或不同的角度进行描述,这些不同的描述构成了事物的多个视图,而多视图学习就是要对由多个不同特征集表示的数据进行学习
-
准则:(1)consensus principle (共识准则),(2)complementary principle (互补准则)
3.拟解决的问题
- 学习多视图学习中的视图不变表示,得到从各个视图获得的一致语义标签(聚类分配)
4.主要贡献
-
通过对比多个视图之间的类簇分配,来探索各视图之间一致的语义标签信息,以端到端的方式学习视图不变表示
-
对生成的视图不变表示之间的对齐进行理论分析,从理论的角度解释了模型的有效性
5.方法
5.1问题定义
给定一个具有 n v n_v nv个视图, N N N个样本的多视图数据 χ = { X ( v ) ∈ R d v × N } v = 1 n v \chi = \{X^{(v)} \in \mathbb{R}^{d_v \times N}\}^{n_v}_{v=1} χ={X(v)∈Rdv×N}v=1nv,其中每一个视图 X ( v ) = [ x 1 ( v ) , x 2 ( v ) , . . . x N ( v ) ] X^{(v)}=[x^{(v)}_1,x^{(v)}_2,...x^{(v)}_N] X(v)=[x1(v),x2(v),...xN(v)]有 N N N个实例, x i ( v ) ( 1 ≤ i ≤ N ) x_i^{(v)}(1\leq i \leq N) xi(v)(1≤i≤N)表示 d v d_v dv维的实例。K为类别数。
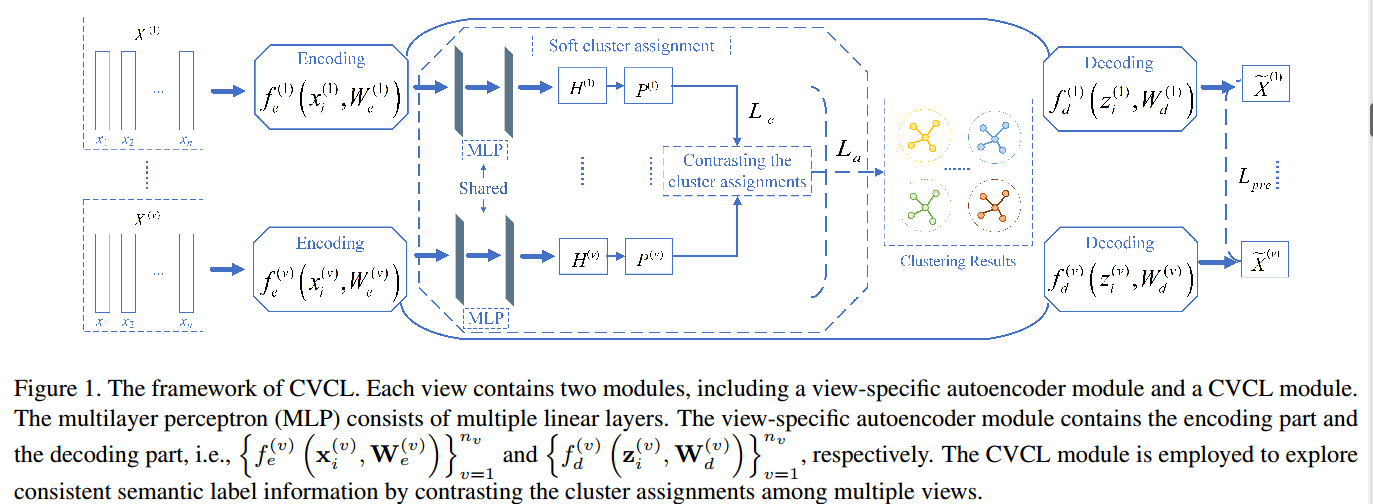
5.2模型结构
模型由两个主要模块组成,即视图自编码器模块和跨视图对比学习模块;其中特定于视图的自编码器模块在无监督表示学习下单独学习多个视图之间的聚类友好特征。跨视图对比学习模块通过对比聚类分配来获得最终的聚类结果。
-
模型首先通过自编码器获得多个视图的表示 Z ( v ) Z^{(v)} Z(v)
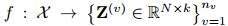
-
然后通过两个线性层和 s o f t m a x softmax softmax函数产生聚类分配概率
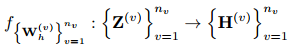
-
为了增加聚类分配之间的差异,对目标分布进行归一化
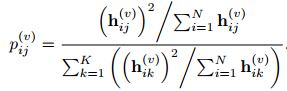
其中, p j ( v ) p^{(v)}_j pj(v)为 P ( v ) P^{(v)} P(v)的第 j 列。 p j ( v ) p^{(v)}_j pj(v)中的每个元素 p i j ( v ) p^{(v)}_{ij} pij(v)表示属于聚类j的样本i的软聚类分配。 p j ( v ) p^{(v)}_j pj(v)表示相同语义簇的簇分配。 -
不同类簇分配之间的表示相似性由以下公式进行度量:
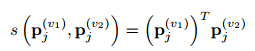
-
最终的聚类结果由多个视图的聚类表示进行平均得到:
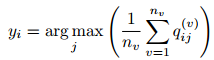
5.3损失函数
-
视图自编码器模块通过预训练进行优化,优化过程采用重构损失:
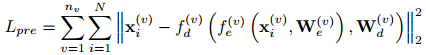
-
不同视图之间的实例的聚类分配概率应该相似,因为这些实例表征相同的样本。而多个视图中的实例用于表征不同的样本,则它们彼此无关,因此可以得到多视图对比损失:
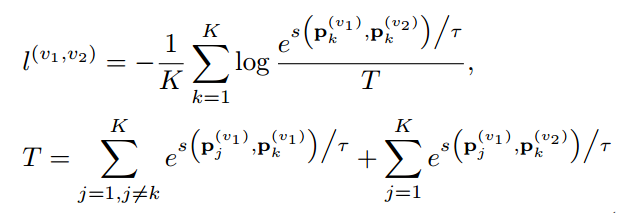
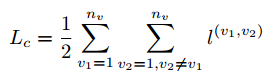
-
为了防止所有实例被分配到相同的类簇,引入了正则化项
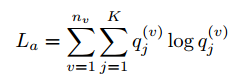
-
总的损失:
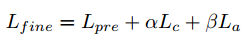
5.4算法流程

6.实验结果
6.1数据集
-
MSRC-v1 数据集:包含属于 7 个类别的 210 个场景识别图像,每幅图像由 5 种不同类型的特征描述
-
COIL-20 数据集:由属于 20 个类别的 1,440 张图像组成,每个图像由 3 种不同类型的特征描述
-
手写数据集:由 2,000 个数字 0 到 9 的手写图像组成,每幅图像由 6 种不同类型的特征描述
-
BDGP 数据集:包含 2,500 个果蝇胚胎样本每个样本都由视觉和文本特征表示
-
Scene-15 数据集:由属于 15 个类别的 4,485 个场景图像组成 ,每个图像由 3 种不同类型的特征表示。
-
MNIST-USPS 数据集:包含 5,000 个样本,具有两种不同风格的数字图像
-
Fashion 数据集:包含 10, 000 张产品图像,每个图像都由三种不同的风格表示。
6.2对比试验
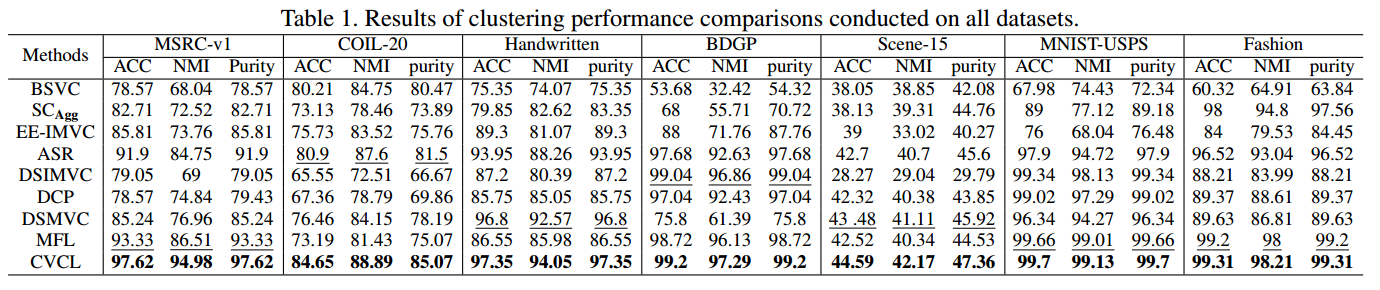
6.3消融实验

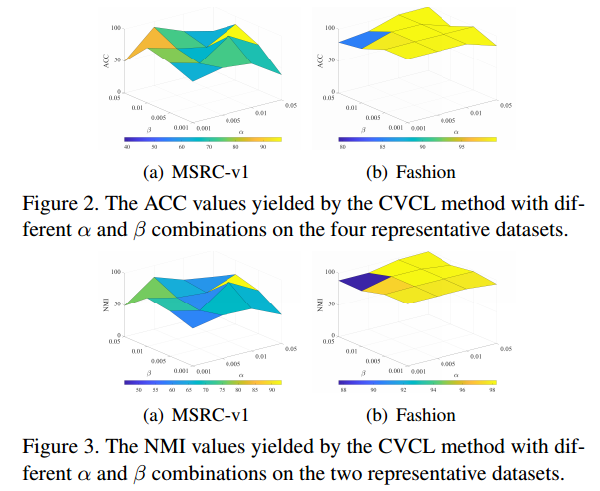
6.4参数分析
6.5收敛性分析

7.结论
-
这篇文章为什么能中? 文章提出了一种新的端到端的多视图聚类框架,从实验和理论角度证明了模型的有效性,依据“表示即聚类”的思想,通过对比多个视图之间的聚类分配,探索各个视图之间一致的语义标签信息。
-
存在什么问题? 方法探索了视图之间的互补性和一致性信息,但是没有充分利用特定于视图的表示。
-
启发:本文提出的多视图聚类架构可以扩展到其他的领域中,比如时间序列聚类,但是存在以下几个难点:(1)如何生成不同的视图数据,(2)编码器该如何设计,需要考虑时间序列的特性,(3)如何衡量不同视图的重要性…

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)