【大模型】deepseek
DeepSeek系列模型包括DeepSeek LLM、DeepSeek-VL等,DeepSeek-R1和DeepSeek-R1-Zero是在DeepSeek-V3-Base的基础上训练得到的基准模型。
前言: DeepSeek系列模型包括DeepSeek LLM、DeepSeek-VL等,DeepSeek-R1和DeepSeek-R1-Zero是在DeepSeek-V3-Base的基础上训练得到的基准模型。
目录
1. DeepSeek-V3
1.1 模型整体架构
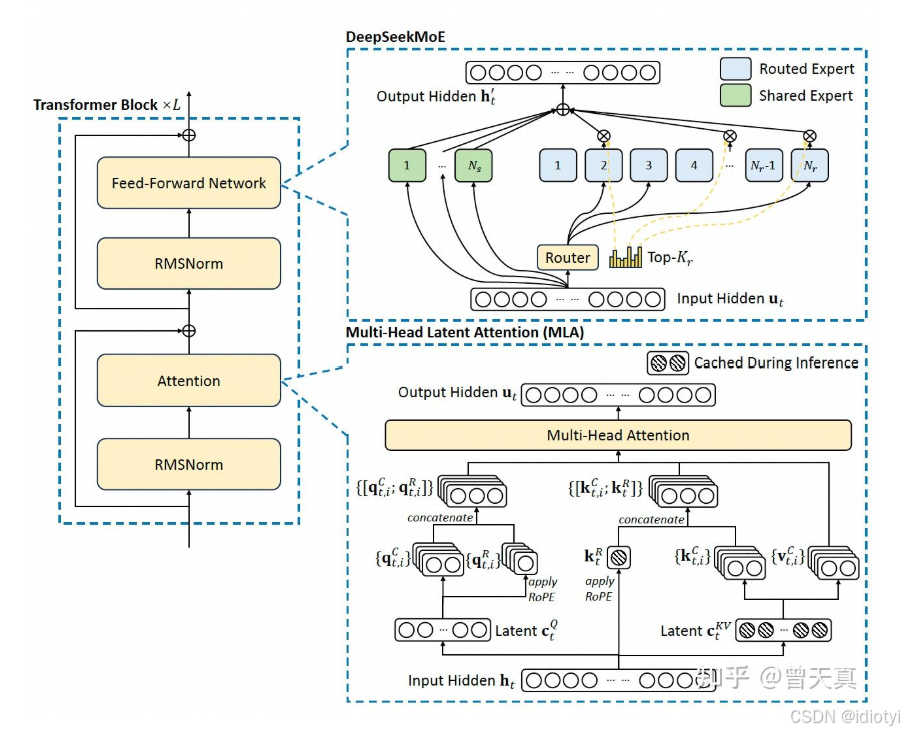
1.2 Multi-Head Latent Attention(MLA)
- 核心:对键、值和查询矩阵进行低秩压缩,并通过旋转位置编码引入位置信息,从而在高效推理的同时捕捉输入序列中的复杂特征。
- 压缩K和V
- 将原始token的嵌入向量 h t h_t ht压缩成低维向量 c t K V c_t^{KV} ctKV
- 重新生成低维向量 c t K V c_t^{KV} ctKV的k和v,即 k t C k_t^C ktC和 v t C v_t^C vtC
- 应用ROPE, 生成 h t h_t ht的位置编码 k t R k_t^R ktR
- 生成最终的k和v: k t = [ k t C ; k t R ] k_t=[k_t^C; k_t^R] kt=[ktC;ktR], v t = v t C v_t=v_t^C vt=vtC
- 压缩Q
- 将原始token的嵌入向量 h t h_t ht压缩成低维向量 c t Q c_t^{Q} ctQ
- 重新生成低维向量 c t Q c_t^{Q} ctQ的q,即 q t C q_t^C qtC
- 应用ROPE, 生成 c t Q c_t^Q ctQ的位置编码 q t C q_t^C qtC
- 生成最终的Q: q t = [ q t C ; q t R ] q_t=[q_t^C; q_t^R] qt=[qtC;qtR]
- 注意力计算
- 每个注意力头i的分数: o t , i = ∑ j = 1 t s o f t m a x ( q t , i T k j , i d h + d h R ) v j , i C o_{t,i}=\sum_{j=1}^t softmax(\frac{q_{t,i}^T k_{j,i}}{\sqrt{d_h+d_h^R}})v_{j,i}^C ot,i=∑j=1tsoftmax(dh+dhRqt,iTkj,i)vj,iC
- u t = W o [ o t , 1 ; o t , 2 ; … ; o t , n h ] u_t=W^o[o_{t,1}; o_{t,2};\dots;o_{t, n_h}] ut=Wo[ot,1;ot,2;…;ot,nh]
- d h d_h dh是每个注意力头的维度, d h R d_h^R dhR是ROPE中解耦键的维度
注意
- 将原始向量压缩成低维时,低维 d c d_c dc通常设置为原始嵌入维度 d d d的1/4到1/8
- K求ROPE时使用的原始向量嵌入,Q求ROPE时使用的压缩后的,Deepseek给出的答案是K保留完整的语义信息,Q强制模型聚焦核心特征
1.3 DeepSeekMoE
-
组成
MOE主要包含三部分:- 专家网络:前馈网络
- 门控网络:跟专家网络接收一样的输入,产出专家偏好的权重,指示不同专家的重要程度
- 选择器:根据专家权重做专家选择的策略
-
负载均衡-辅助损失
目的是为了解决大多数token流向少数专家导致的拥塞问题,并且其他专家会因此训练不充足。
每个MOE层都有一个负载均衡损失,形式如下所示:
l a u x = 1 E ∑ e = 1 E ( c e S ) × m e l_{aux}=\frac{1}{E}\sum_{e=1}^E(\frac{c_e}{S}) \times m_e laux=E1e=1∑E(Sce)×me
其中,E是专家数量, m e m_e me是每个专家的门控权重均值, c e c_e ce是第e个专家接受的token数, m e m_e me计算如下所示:
m e = 1 S ∑ s = 1 S g s , e m_e = \frac{1}{S}\sum_{s=1}^Sg_{s,e} me=S1s=1∑Sgs,e -
无辅助损失的负载均衡策略
辅助损失是传统的解决方案,但过大的损失会引入不可忽视的干扰梯度,损害模型性能。DeepSeek-V3中使用了一种无辅助损失的负载均衡策略,通过直接调整门控分数实现。DeepSeekMOE流程:

针对负载不均衡的问题,为每个专家引入一个偏置项 b i b_i bi,偏置项仅用于路由,与FFN输出相乘的门控值仍然是从原始亲和力分数导出的: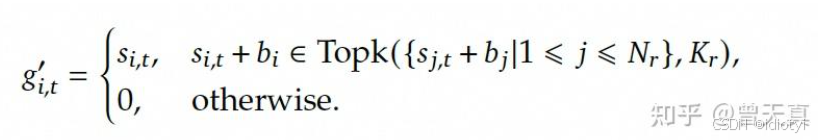
DeepSeek-V3:
- 采用了大量小专家的方法替代了少量大专家结构。
- 专用专家和共享专家结合。
- 支持多进程分布式训练,确保每个进程只负责一部分专家,提高并行计算能力。
2. DeepSeek-R1
2.1 分类
- 基础版DeepSeek-R1(6B)
- 满血版DeepSeek-R1(671B)
- 蒸馏版DeepSeek-R1
- DeepSeek-R1-Zero:R1-zero的参数规模与满血版R1保持相同体量,但在训练策略上有所创新。它采用了多阶段混合训练策略,通过逐步增加训练难度和复杂度,提高了模型的泛化能力和鲁棒性。
2.2 对比V3
V3主要是用于知识问答等,R1用于代码生成和数学建模。
- 核心架构
| 维度 | V3 | R1 |
|---|---|---|
| 注意力机制 | 非对称RoPE(Q压缩后的/K原始向量) | 对称ROPE |
| 参数规模 | 13B | 16B |
- 训练方法和策略
| 维度 | V3 | R1 |
|---|---|---|
| 训练 | 预训练+SFT+RL+知识蒸馏 | 纯RL(R1-Zero) + 冷启动数据微调 + 多阶段RL对齐人类偏好 |
| 奖励阶段 | 依赖传统监督数据与部分人类反馈 | 基于规则奖励(如准确性、格式奖励)和语言一致性奖励,避免神经网络奖励模型 |
- 部署特性
| 维度 | V3 | R1 |
|---|---|---|
| 量化 | 支持4bit量化 | 仅支持8bit |
| 热更新能力 | 支持模块级替换(无需全量重载) | 需完整模型加载 |
| 动态批处理 | 最大批处理量256 | 最大128 |
2.3 知识蒸馏
2.3.1 知识分类
- 基于响应的知识:教师模型最后一个输出层产生的神经响应。
- 基于特征的知识:使用中间层的特征表示来指导学生模型的训练。
- 基于关系的知识:基于关系的知识蒸馏方法通过最小化教师模型和学生模型特征对之间相似性损失函数来实现知识转移
2.3.2 蒸馏方案
- 离线蒸馏:最常见的知识蒸馏方法,通常用于从预训练的教师模型中提取知识,然后将其用于指导学生模型的训练。通常采用单向知识传递和两阶段训练程序。。优点是简单,缺点是学生模型过度依赖教师模型。
- 在线蒸馏:教师模型和学生模型同时更新。知识通过模型的参数更新过程从教师模型传递到学生模型。优势在于能够实时更新模型,适用于没有大容量高性能教师模型的场景,但缺点是计算复杂度较高。
- 自蒸馏:同一网络被用作教师和学生模型,将自己深层网络的知识蒸馏到浅层网络。优势在于能够有效地利用深层网络的知识和减少模型的复杂性,但缺点是可能会导致浅层网络过拟合。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)