图像融合+语义
1.引入语义信息:考虑到的需求,将引入融合网络中。2.联合训练:利用分割网络[52]产生的通过反向传播指导融合网络的训练,迫使融合图像包含更多语义信息。m 表示第 m 次迭代。随着训练的进行,β逐渐增大,这是因为随着迭代次数的增加,分割网络更好地拟合融合模型,并且语义损失可以更准确地指导融合网络训练。3.设计梯度残差密集块(GRDB):为了满足高级视觉任务的需求,开发了一种基于梯度残差密集块(GR
图像配准+融合+语义方法总结
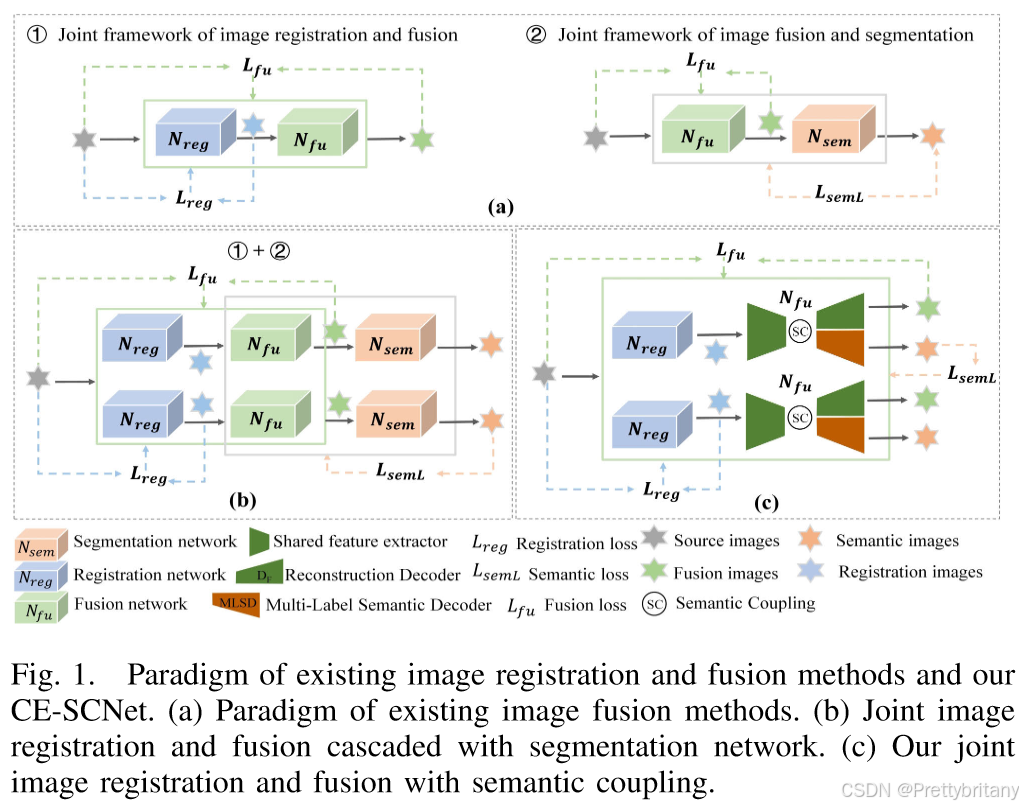
1.Joint framework of image registration and fusion
RFNet: Unsupervised Network for Mutually Reinforcing Multi-modal Image Registration and Fusion(2022CVPR)
Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration
Semantics lead all: Towards unified image registration and fusion from a semantic perspective(2023Inffus)
MURF: Mutually reinforcing multi-modal image registration and fusion(2023TPAMI)
2.Joint framework of image fusion and segmantation
SeAFusion:Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network(2022Inffus)
创新
1.引入语义信息:考虑到高级视觉任务的需求,将语义信息引入融合网络中。

2.联合训练:利用分割网络[52]产生的语义损失通过反向传播指导融合网络的训练,迫使融合图像包含更多语义信息。

m 表示第 m 次迭代。随着训练的进行,β逐渐增大,这是因为随着迭代次数的增加,分割网络更好地拟合融合模型,并且语义损失可以更准确地指导融合网络训练。
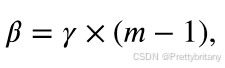

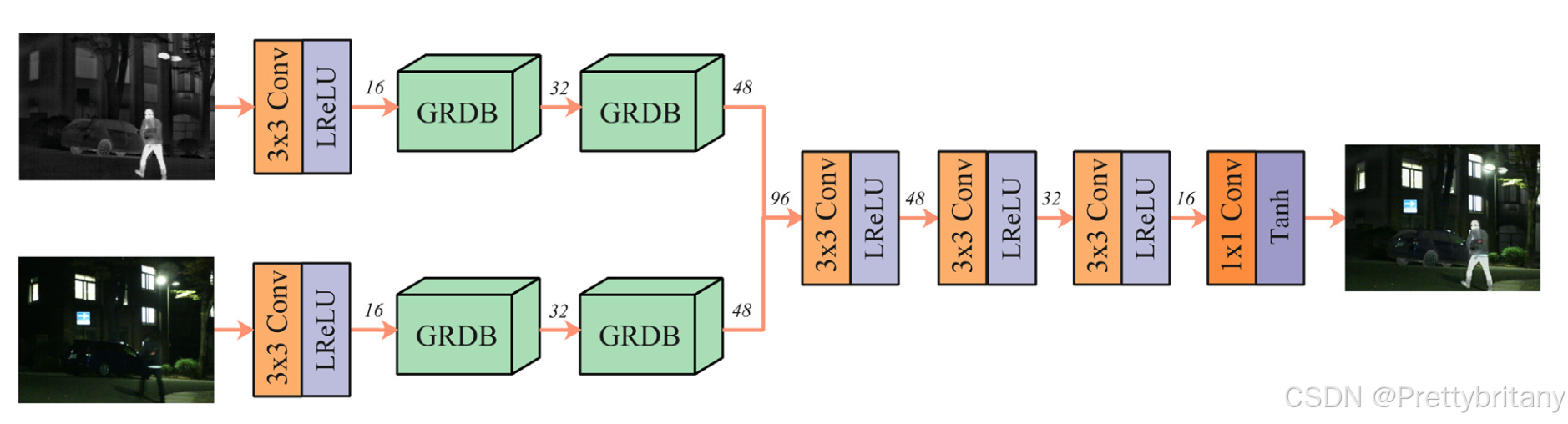
3.设计梯度残差密集块(GRDB):为了满足实时高级视觉任务的需求,开发了一种基于梯度残差密集块(GRDB)的轻量级网络。
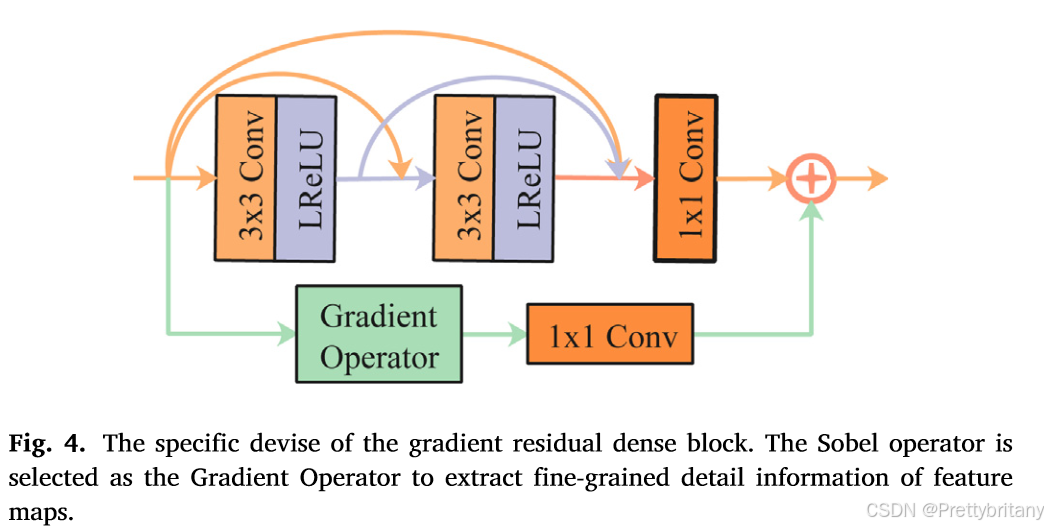
设计了梯度残差密集块(GRDB)来增强融合网络对细粒度空间细节的描述能力。
启发
1.将串联任务通过联合训练的方式结合起来。
2.将语义信息引入融合网络。
3.设计简单的网络实现功能,实时性。
TarDAL:target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection(2022CVPR)
创新
1.融合+检测:通过双层优化公式将图像融合和目标检测结合起来,产生高检测精度以及具有更好视觉效果的融合图像。

2.TarDAL网络:(weak 类似GAN方法)设计了一个目标感知的双重对抗学习网络(TarDAL),其参数较少,用于面向检测的融合。这种单生成器和双鉴别器网络“寻求共同点,同时从差异中学习”,保留了红外目标的信息和可见光的纹理细节。

引入了一种由一个生成器和两个判别器组成的对抗性游戏,以便将两种模式的共同特征和不同特征结合起来。鼓励生成器 G 提供逼真的融合图像以同时愚弄两个鉴别器。目标鉴别器 DT 评估红外目标与 G 给出的融合后的目标之间的强度一致性;细节鉴别器 DD 区分可见光的梯度分布和融合的梯度分布)。

采用预训练的显着性检测网络 [3] 从红外图像计算目标掩模 m,以便两个鉴别器可以在各自的区域(目标和背景)上执行。

3.(strong 数学求导实现联合训练)从双层公式中推导出协作训练方案,产生用于快速推理(融合和检测)的最佳网络参数。


4.(strong 数据集应用很广)构建了一个具有经过良好校准的红外和光学传感器的同步成像系统,并收集了一个多场景多模态数据集 (M3FD),其中包含 4, 177 个对齐的红外和可见光图像对以及 23, 635 个带注释的对象。该数据集涵盖了不同环境、光照、季节、天气的四大场景,像素变化范围较大。

启发
使用复合函数求导的方法将串联任务进行协作训练。
SegMiF:Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation(2023ICCV oral)
问题
1.一些研究[13,14,15,16]尝试通过级联融合网络和高级任务来设计基于多任务学习的损失函数。不幸的是,同时为任一任务寻求统一的适当特征仍然是一个难题。
2.探索多模态融合和分割需要全面收集带有像素级注释标签的对准图像对。此外,对于一幅图像,注释需要覆盖大范围的像素。不幸的是,现有的多模态数据集合要么专注于图像融合,要么缺乏完整图像注释的分割标签,这为探索融合和分割的相关性设置了障碍。
创新
1.框架:我们将图像融合和分割(segformer)两者结合起来,使语义和基于像素的特征可以相互交互。通过这种方式,这两个任务可以实现“两全其美”的效果,既生成视觉吸引人的融合图像,又能准确地解析场景。

2.模块(strong):引入分层交互注意力来弥合融合网络和分割网络之间的特征差距。在 HIA 中建立语义/模态多头注意力机制,同时保留了内在的模态特征,并更多地关注语义特征。
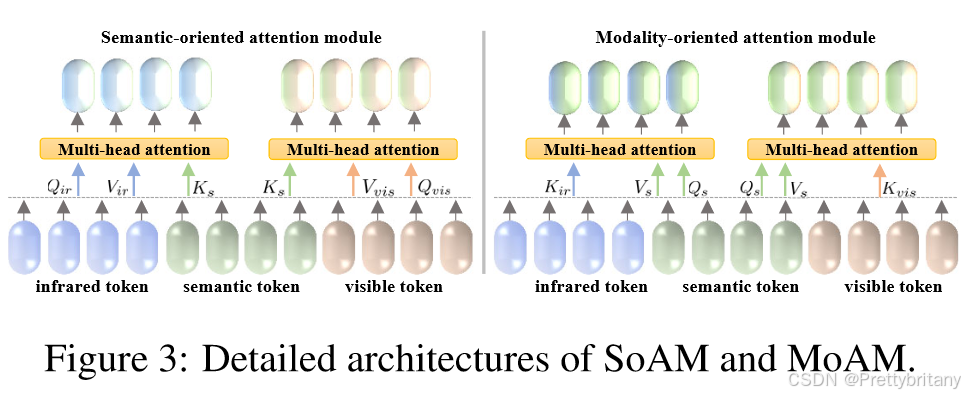
3.训练方式:提出一种交互式特征训练方案,以克服融合和分割之间特征交互不足的缺点。无缝集成动态权重因子可以自动探索每个任务的最佳参数。


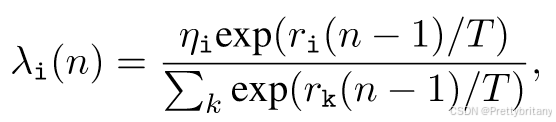
4.数据集(strong):构建了智能多波双目成像系统,并引入了全时多模态基准FMB,以促进图像融合和分割的研究。 FMB 包含 1500 个配准良好的红外和可见光图像对,以及 15 个带注释的像素级类别(参见图 1 的左侧部分)。此外,它还涵盖了广泛的像素变化和各种恶劣环境,例如浓雾、大雨和弱光条件。

启发:
1.提出了即插即用的HIA模块将语义信息注入融合网络,可以对该模块进行改进。
2.动态权重联合训练方式对级联网络的联合训练有一定参考性。
MRFS: Mutually Reinforcing Image Fusion and Segmentation(2024CVPR)
1.特征中和缺点和低光信息丢失。
通过显着信息集成(salient information integration)和弱化信息恢复(weakened information recovery)的能力增强图像融合,有效缓解特征中和缺点和低光信息丢失。因此,显着的对比度和丰富的纹理将有效地转移到融合图像。
salient information integration
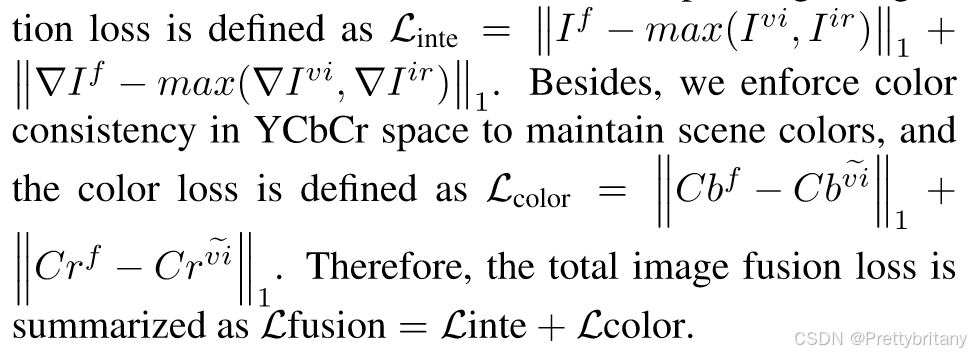
weakened information recovery
应用常见的数据增强策略(例如伽玛变换、对比度拉伸)来处理图像。
2.特征有效性得分不匹配;特征聚合不足。
设计了一个基于 CNN 的交互式门控混合注意力模块用于视觉补全,以及一个基于 Transformer 的渐进循环注意力模块用于语义补全。他们分别解决了特征有效性分数不匹配的问题并加强了特征聚合的充分性。
IGM-Att:将门控机制集成到传统的基于池的注意力中以实现视觉完成
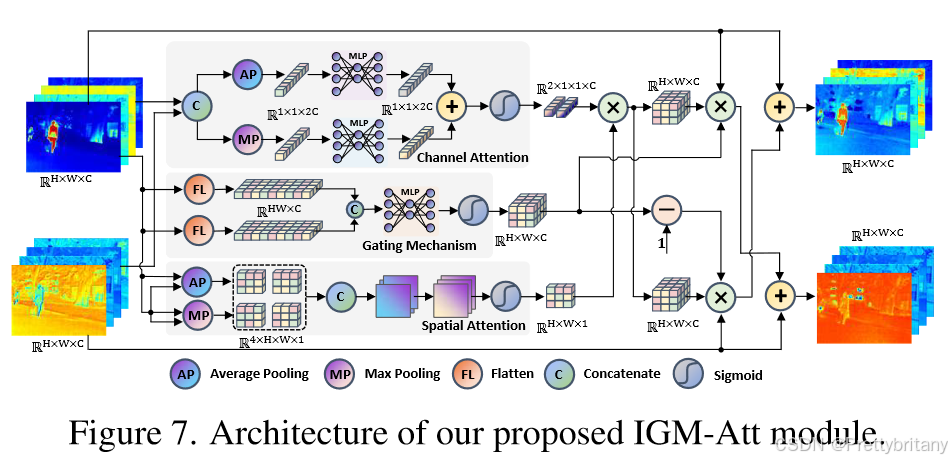
这种基于池化的注意力可能会导致特征有效性分数不匹配。为了解决这个问题,引入了门控机制来纠正获得的混合权重:


PC-Att

IGM-Att 模块利用基于 CNN 的注意力,强调局部视觉特征的细化。相比之下,语义分割需要全局场景理解能力。因此,我们开发了一个用于细化语义补全的PCAtt模块,如图8所示。在PC-Att模块中,我们采用两种信息强化策略,即单模态自我强化和跨模态相互补充。该过程将红外和可见光图像中的长距离完整语义信息无缝集成到生成的融合特征中。
4.视觉和语义之间的内在一致性。
图像融合和语义分割的策略耦合建立了相互促进的关系,导致其性能的双重提升。
MRFS 通过提出的 IGM-att 和 PC-Att 实现特征交互,将图像融合和语义分割任务优雅地耦合到一个统一的框架中

DetFusion: A detection-driven infrared and visible image fusion network
An interactively reinforced paradigm for joint infrared-visible image fusion and saliency object detection
3.Joint framework of image fusion、registration and segmentation
SuperFusion: A Versatile Image Registration and Fusion Network with Semantic Awareness(2022JAS)
解决的问题
1.现有的融合算法,无论是传统的还是基于深度学习的算法,都对源图像的未对准敏感。
2.现有的融合方法几乎没有考虑如何促进高级视觉任务。
创新
1.将图像配准、图像融合和高级语义要求统一建模到一个框架中。据我们所知,这是第一个充分考虑图像融合的先决条件(即图像配准)以及图像融合的后续应用的实用图像融合方法。

2.设计了一个对称双向图像配准模块,以有效地执行多模态图像对准。具体来说,对称性使我们的方法能够实现图像融合和图像配准的相互促进。
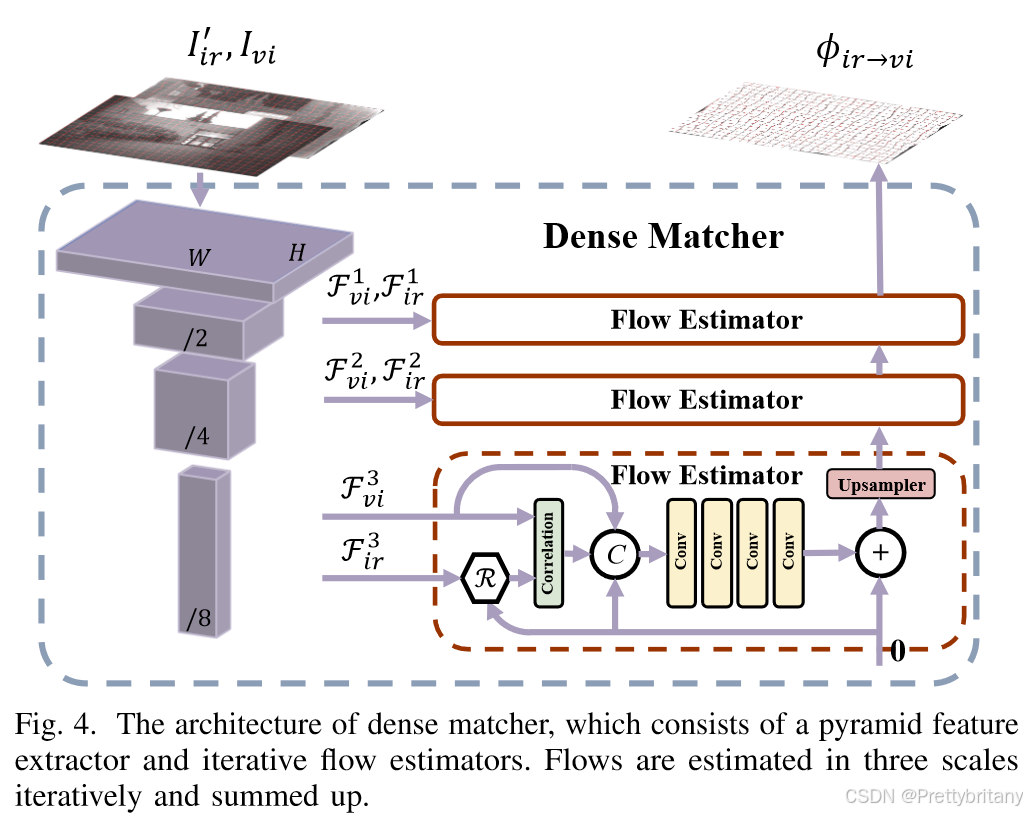
3.引入基于语义分割(使用了与seafusion相同的网络)的语义约束,促使融合网络响应高级视觉任务的需求。
并未发现各个模块之间的关系和反馈。
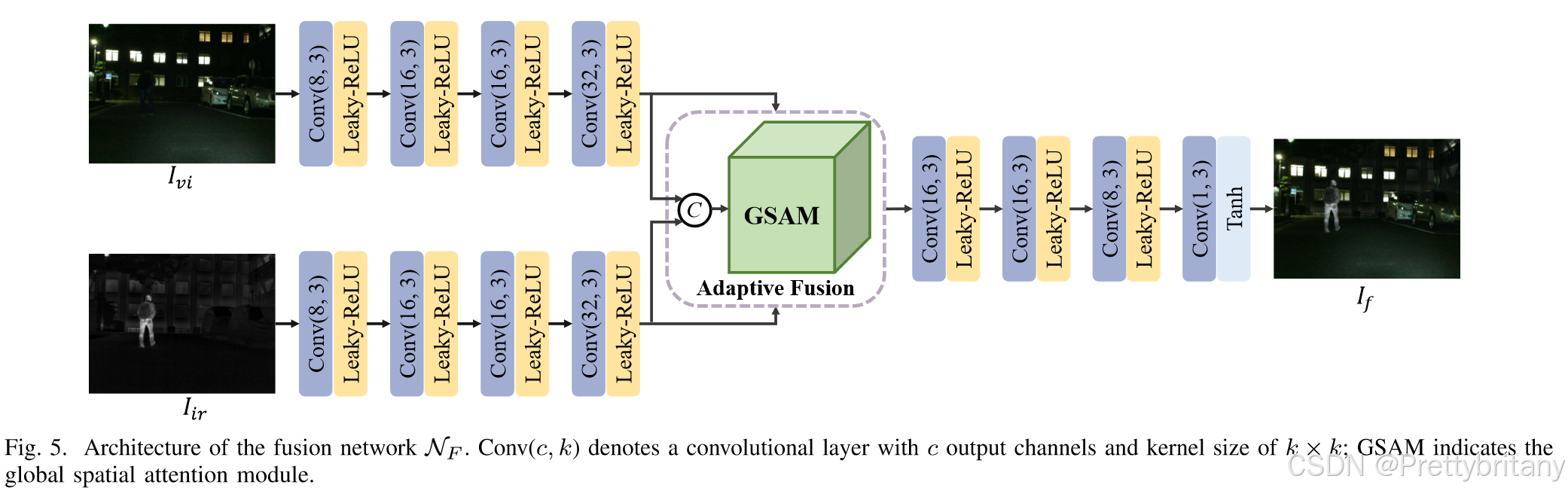
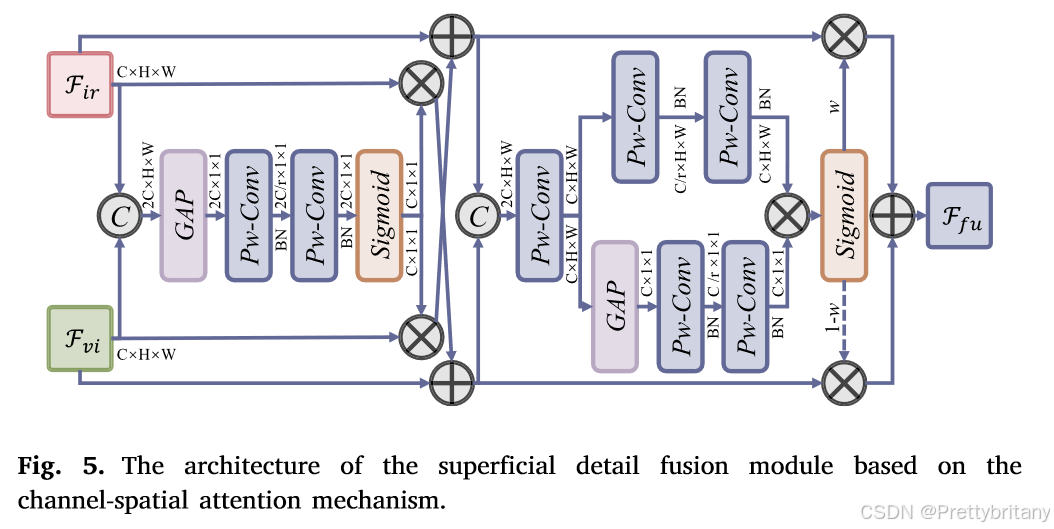
此外,融合网络中嵌入了全局空间注意力模块,以实现自适应特征融合。

启发
将融合、配准和语义统一到一个框架中。
不足
未将这三个任务进行很好的耦合,只是单纯的串联。
PSFsion:Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity(2023InfFus)
问题
尽管存在一些以语义驱动的方法来考虑下游应用的语义需求,但与特征级融合相比,这些方法都没有展现出图像级融合的潜力。特征级融合直接在多模态特征上执行高级视觉任务,而不是在融合图像上执行。
然而,这些方法利用特定的高级模型来约束融合结果,这可能会限制融合图像到其他模型的泛化。此外,SeAFusion仅依靠最大选择策略来约束融合图像的强度,这可能会限制在某些极端情况下图像融合的潜力。

创新
1.我们首次证明,对于高级视觉任务,多模态图像级融合可以以较低的计算负载实现与多模态特征级融合相当的性能。它证明了图像融合在高级视觉任务中的必要性。

2.我们在特征级别逐步将语义特征注入到融合网络中,从而确保具有丰富语义线索的融合结果对于任意高级骨干网都是友好且鲁棒的。此外,设计了与图像融合路径并行的场景保真度路径来约束融合模块保留源图像的完整信息。

训练策略
Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network(2022Inffus)

A semantic-driven coupled network for infrared and visible image fusion(2024Inffus)
Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection(2022CVPR)

Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation(2023ICCV oral)
提出一种交互式特征训练方案,以克服融合和分割之间特征交互不足的缺点。无缝集成动态权重因子可以自动探索每个任务的最佳参数。
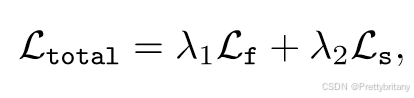


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)