最详细的Transformer讲解,Attention Is All You Need
前言Attention Is All You NeedGoogle Brain 引用量:30255(1/3 ResNet)贡献:Transformer 是第一个完全依赖自注意力来计算其输入和输出表示而不是使用序列对齐的RNN和CNN。一直听别人说Transformer,搞不清楚是什么。可以不用,但是需要理解。但现有的博客,感觉大多轻飘飘的,甚至没讲清楚 attention 和 self-atten
前言
Attention Is All You Need
Google Brain 引用量:30255(1/3 ResNet)
贡献:Transformer 是第一个完全依赖自注意力来计算其输入和输出表示而不是使用序列对齐的RNN和CNN。
一直听别人说Transformer,搞不清楚是什么。可以不用,但是需要理解。
但现有的博客,感觉大多轻飘飘的,甚至没讲清楚 attention 和 self-attention的区别,q,k,v表示什么意义,怎么引入等等。
我这里做了一点小总结,PPT 下载链接在最下面,麻烦点赞,感谢阅读。
建议学习路线:李宏毅课程(宏观理解)--->原文阅读(细节阅读)--->结合我下面PPT的讲义(串讲+总结+引申)。 当然先看我的讲义有个初步理解也OK,食用顺序取决于大家。
李宏毅课程:李宏毅2020机器学习深度学习(完整版)国语_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1JE411g7XF?p=54
https://www.bilibili.com/video/BV1JE411g7XF?p=54
Transformer原文:
https://arxiv.org/abs/1706.03762https://arxiv.org/abs/1706.03762
一、Transformer背景

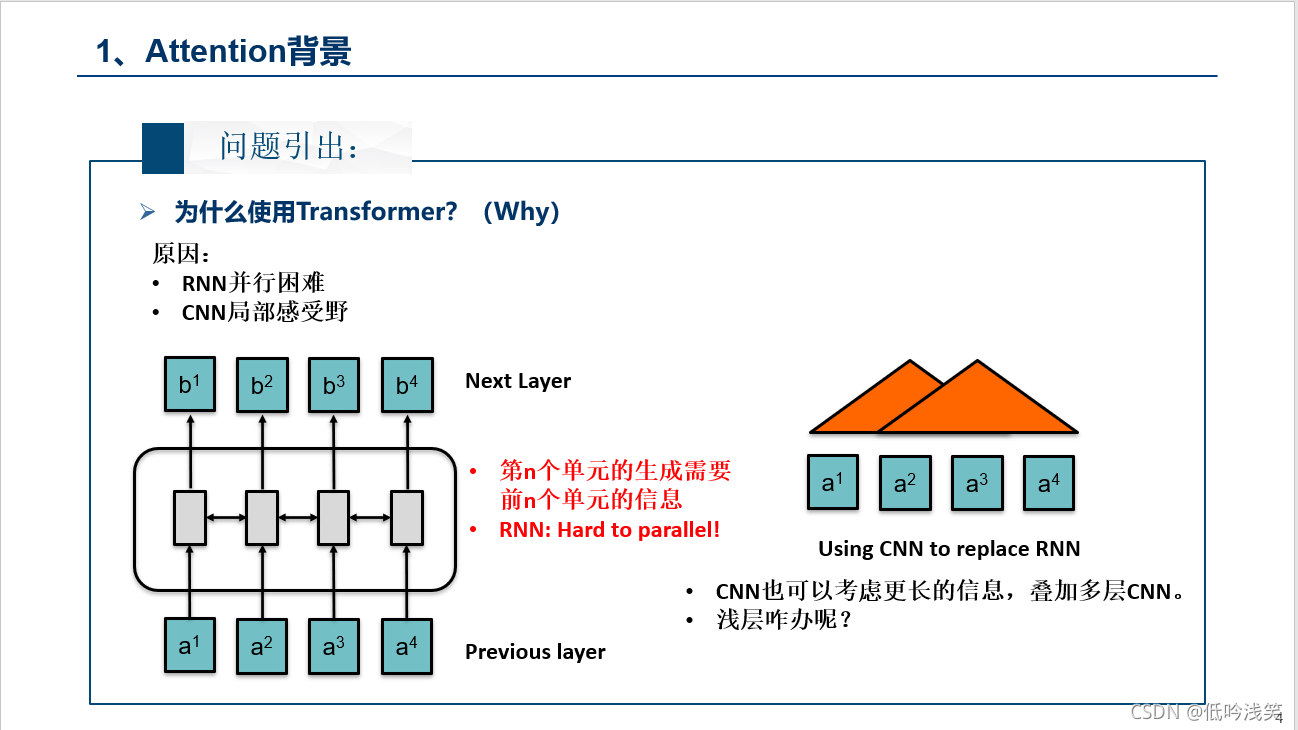

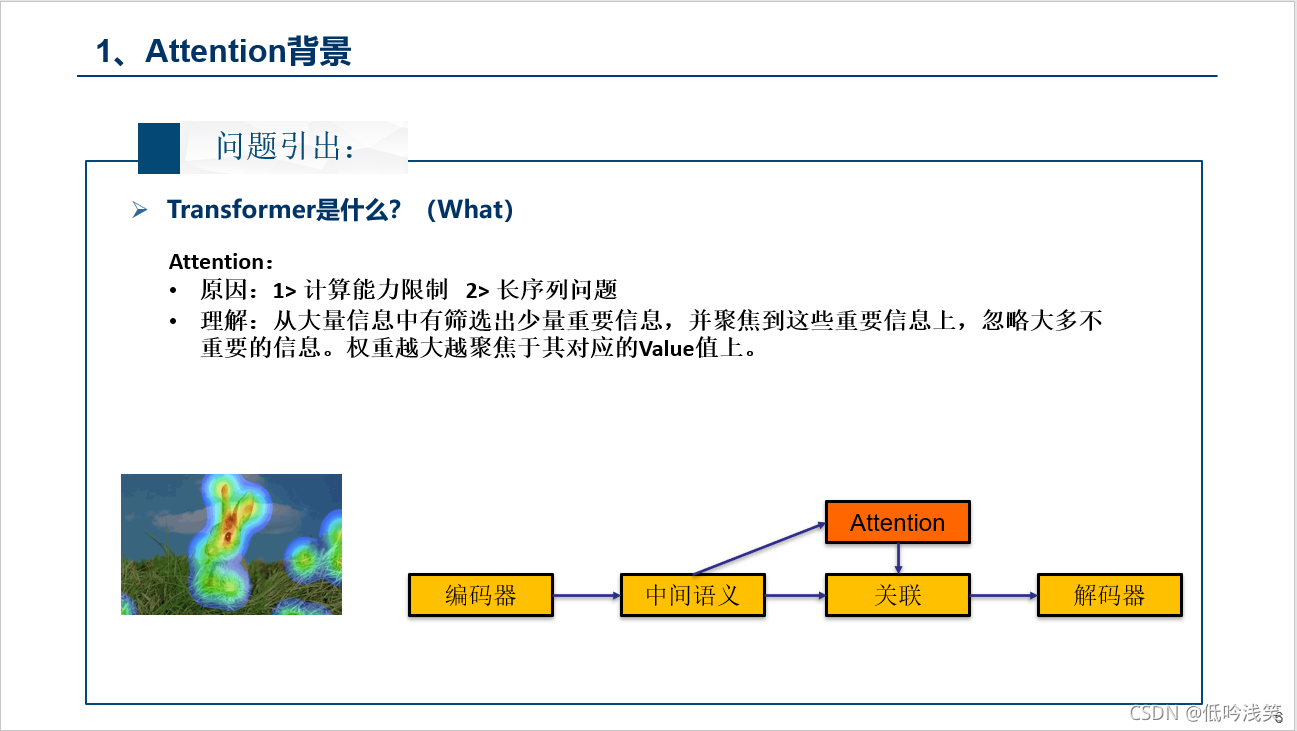
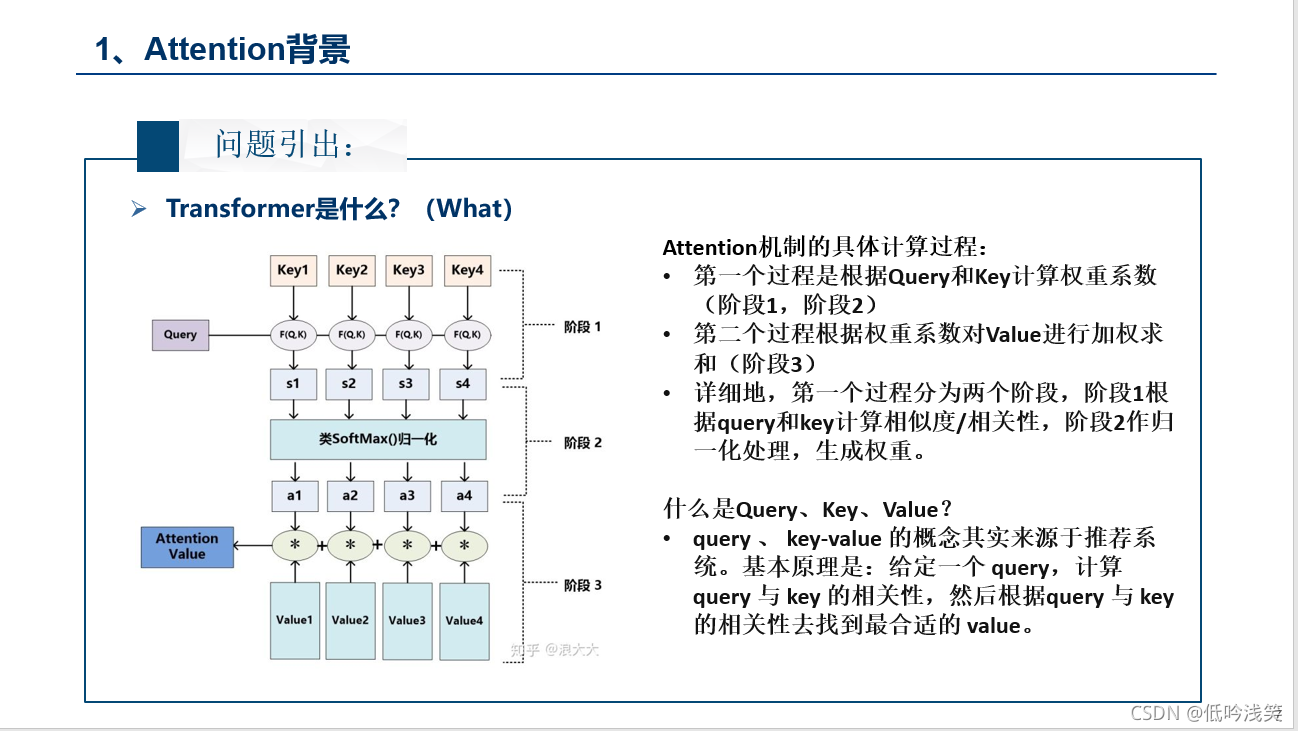
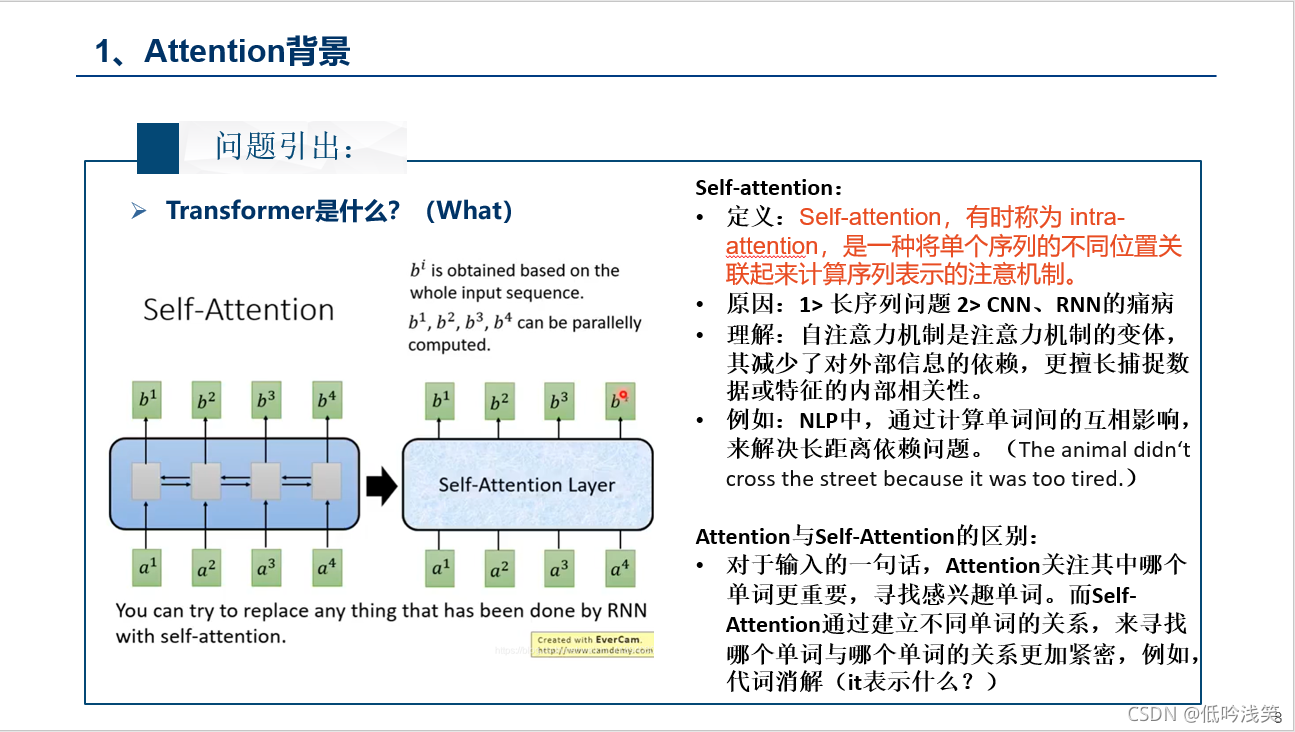
二、Transformer内容介绍
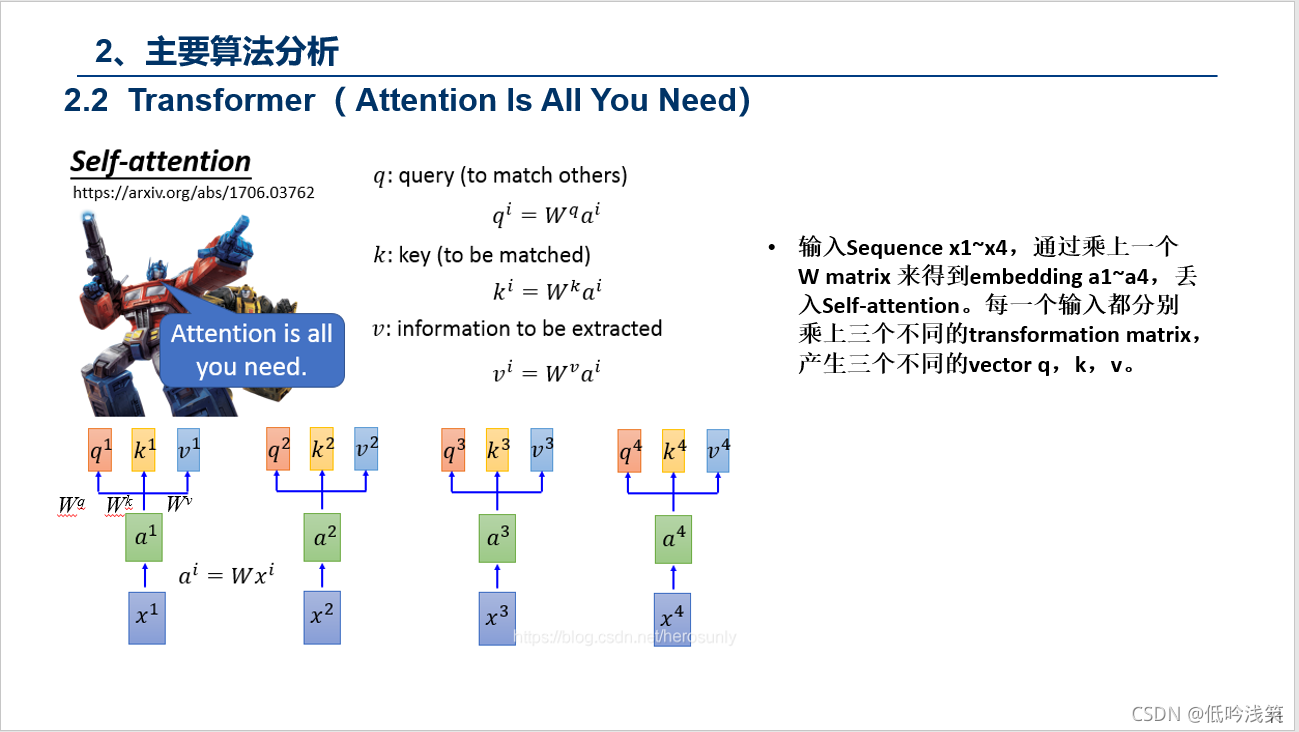
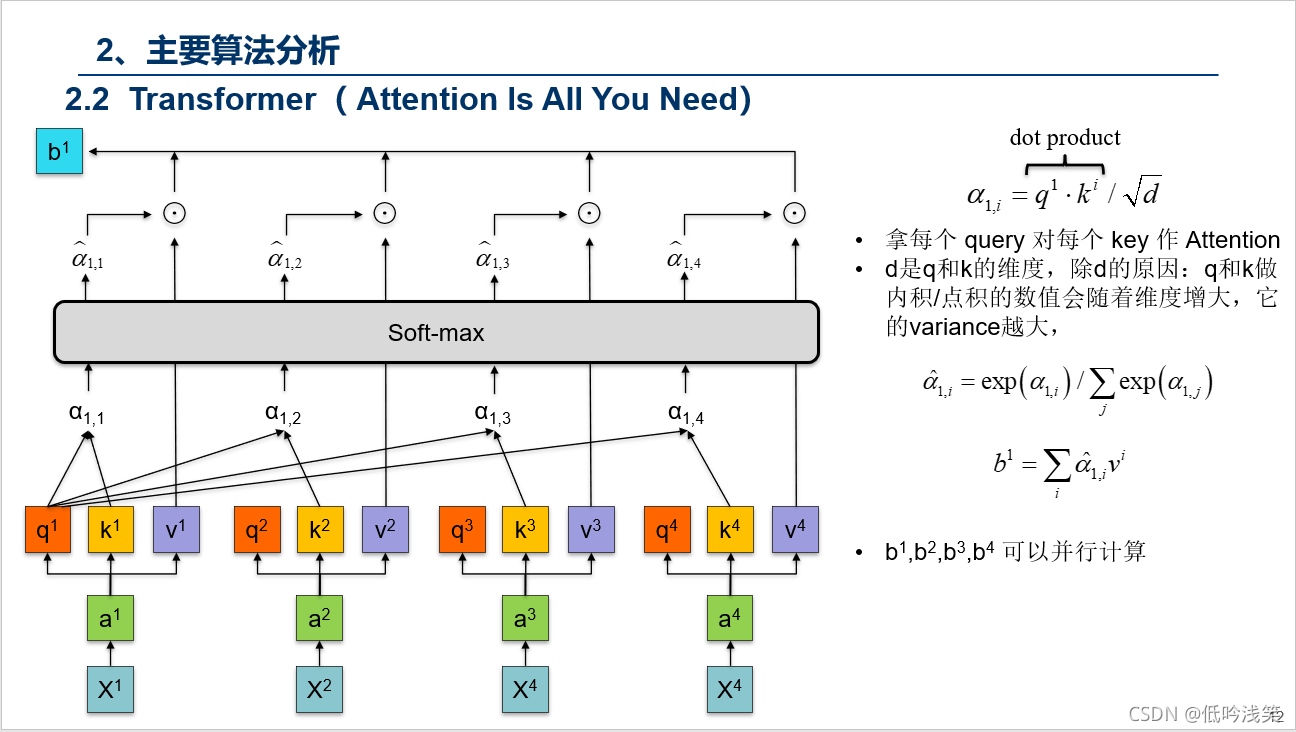

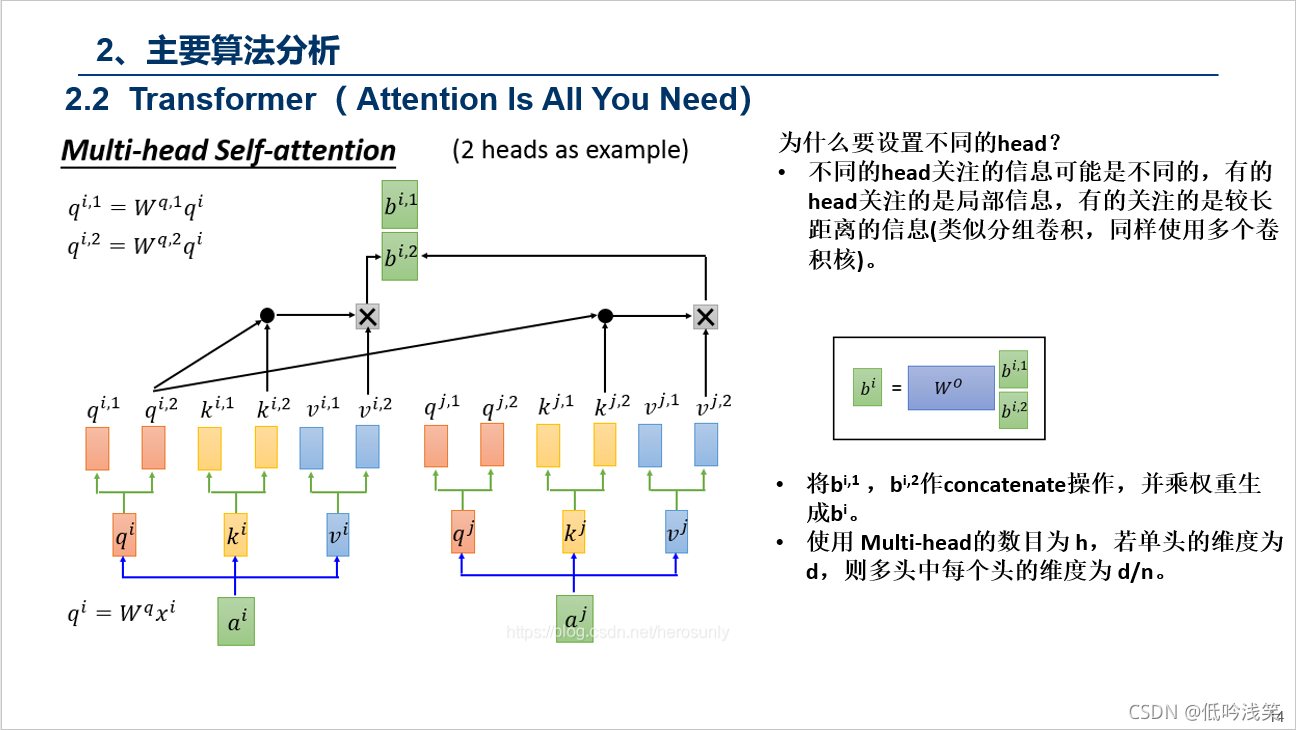
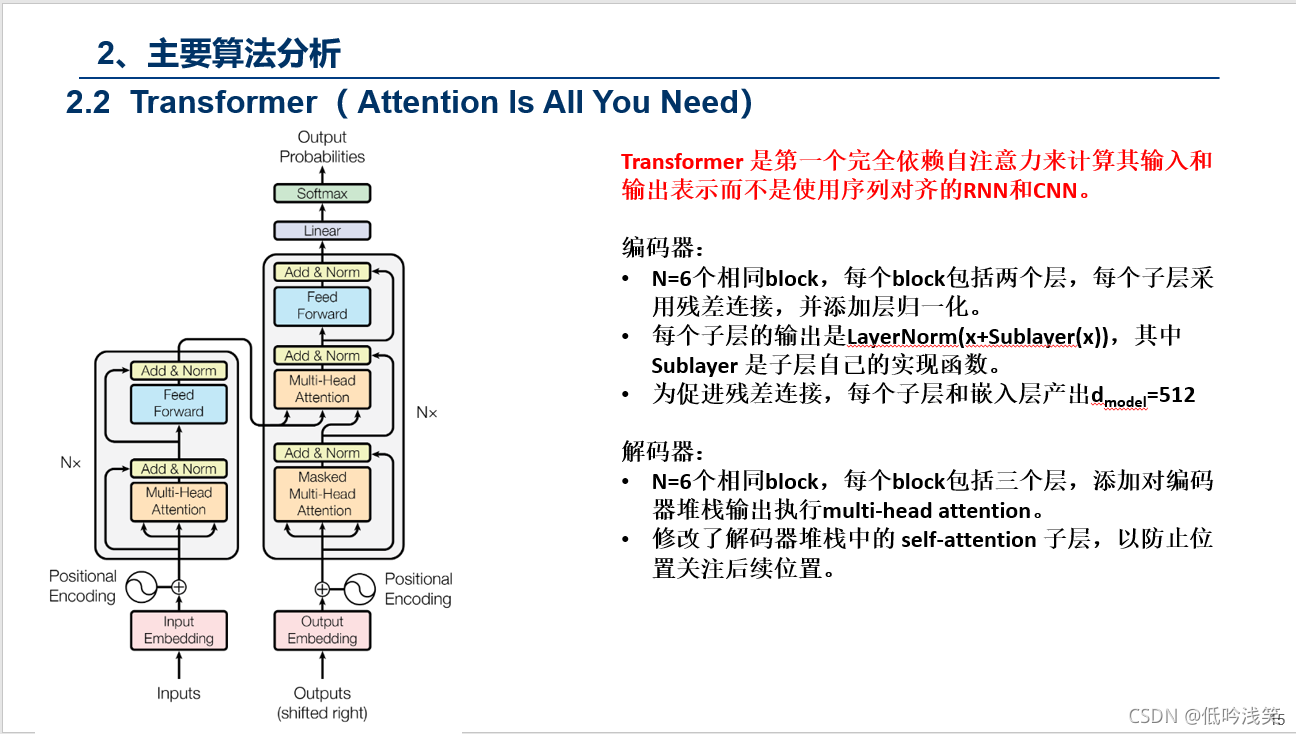
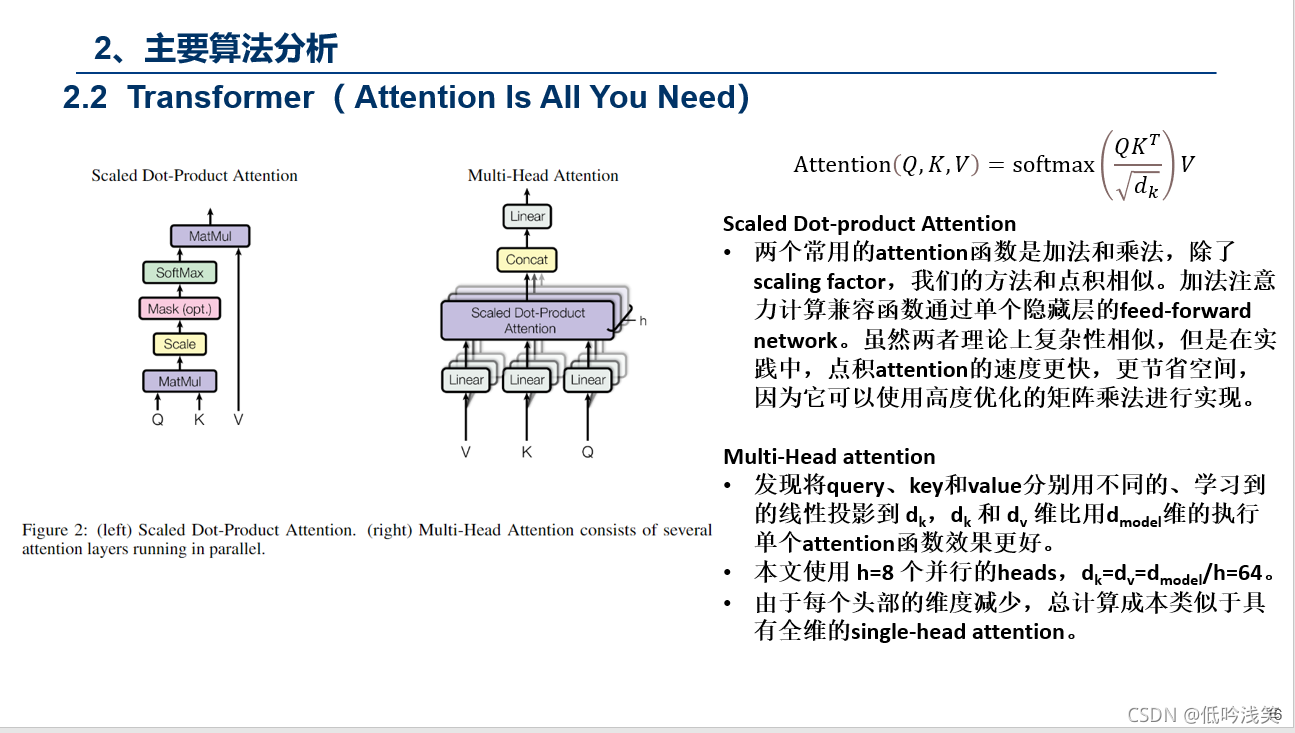
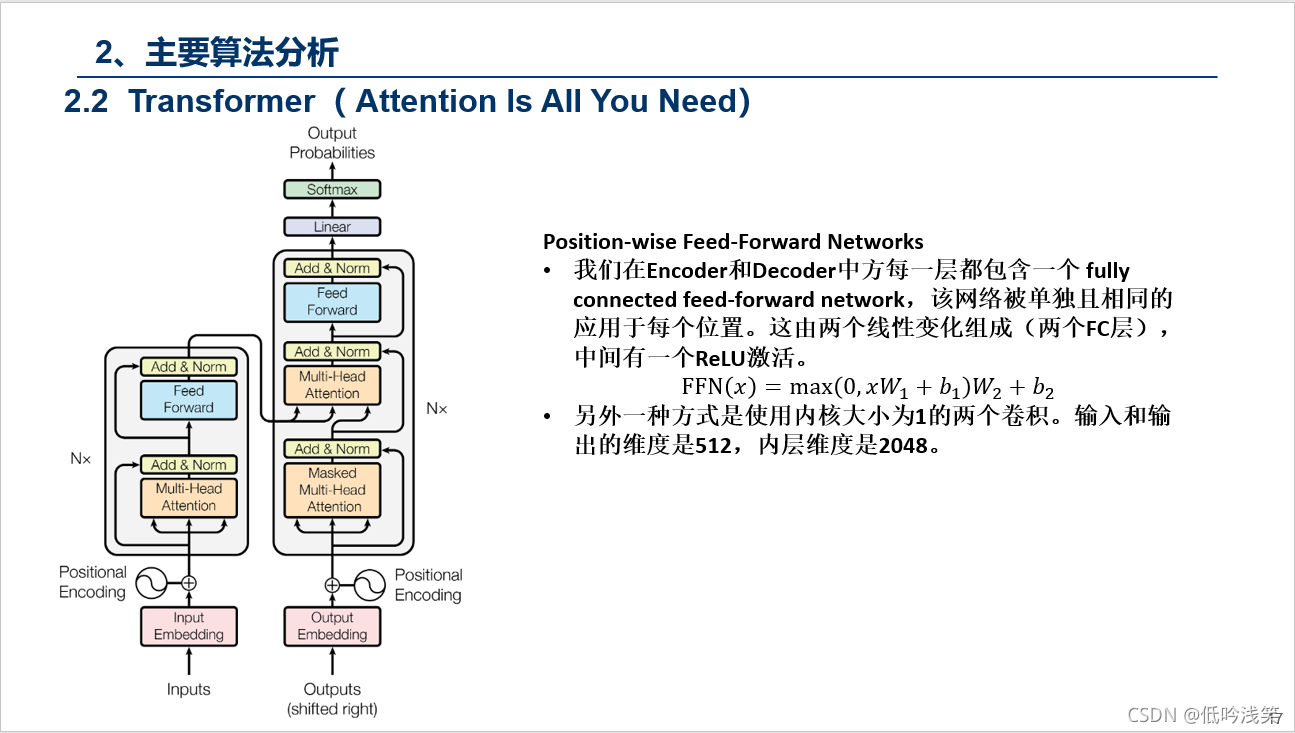



PS:这个动图详细的解释了所有的过程,这里我用语言总结下,Encoder包含1,2,3层,Decoder同样,首先Encoder不同之间相互作用,这个很好理解,对于Decoder,Decoder2在解析的过程中,需要用到Decoder2之前的中间信息,以及Input通过Encoder后的信息,但是不会用到Decoder1和Decoder3的信息。图建议仔细看三次,对整个Transformer的过程有个理解。
三、Transformer Result






最后附加PPT下载链接,感谢大家,希望多点赞👍
链接: https://pan.baidu.com/s/1TAOdOilXAxA8_5vE9_849g?pwd=gje4 提取码: gje4
--来自百度网盘超级会员v5的分享
CSDN 0 积分下载:
https://download.csdn.net/download/qq_37424778/88541190?spm=1001.2014.3001.5501

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 56
56 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)