图解最长公共子串问题:动态规划
文章深入探讨了最长公共子串问题的动态规划解法及优化拓展。从问题定义出发,清晰区分了子串与子序列的区别。核心介绍了动态规划法,利用二维数组记录以两个字符结尾的最长公共子串长度,状态转移方程根据字符是否匹配决定。重点图文讲解了填充二维数组的过程,使动态规划的原理更易理解。此外,给出了空间优化技巧,附代码实现详细说明。最后,提供拓展思路。
一、问题介绍
在字符串处理中,最长公共子串(Longest Common Substring)问题是一个经典且实用的问题。它广泛应用于文本比对、生物信息学(如 DNA 序列比对)等领域。
问题要求找出两个或多个字符串中最长的连续公共子串。
子串(Substring)与子序列(Subsequence)不同。子串要求字符是连续的,而子序列不要求连续。
例如,对于字符串 S = "abcde" 和 T = "abfde":
- 最长公共子串是 "ab" 和 "de"(长度为 2)。
- 最长公共子序列是 "abde"(长度为 4)。
二、算法步骤
1. 核心思想
利用二维数组 dp[i][j] 记录以字符串A的第 i 个字符和字符串B的第 j 个字符结尾的最长公共子串长度。
2. 重点
状态转移方程:
- 若 A[i-1] == B[j-1],则 dp[i][j] = dp[i-1][j-1] + 1;
- 否则,dp[i][j] = 0。
3. 步骤
- 初始化二维数组 dp,大小为 (m+1) x (n+1),初始值为0。
- 遍历字符串A和B,填充 dp 数组。
- 记录遍历过程中的最大值及其位置,得到最长公共子串。
4. 空间优化
优化思路:由于 dp[i][j] 仅依赖前一行的 dp[i-1][j-1],可将空间复杂度优化为 O(n)。
步骤:
- 使用一维数组 dp 代替二维数组。
- 从右向左遍历B,避免覆盖未使用的上一行数据。
- 通过变量 prev 保存左上角的值。
三、原理图解
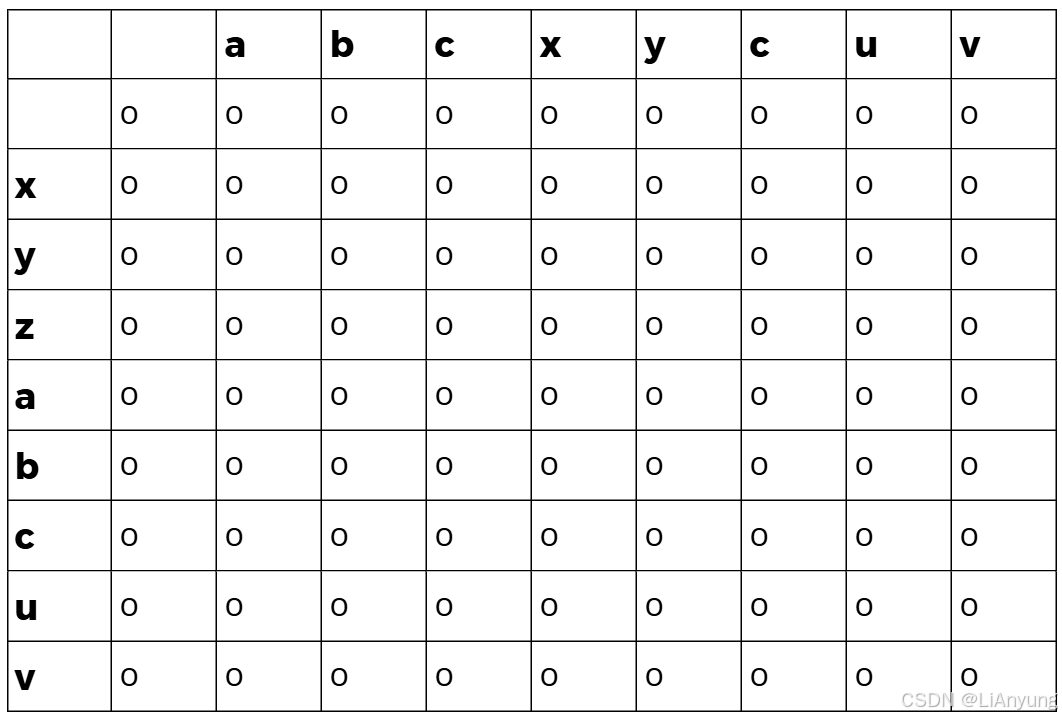
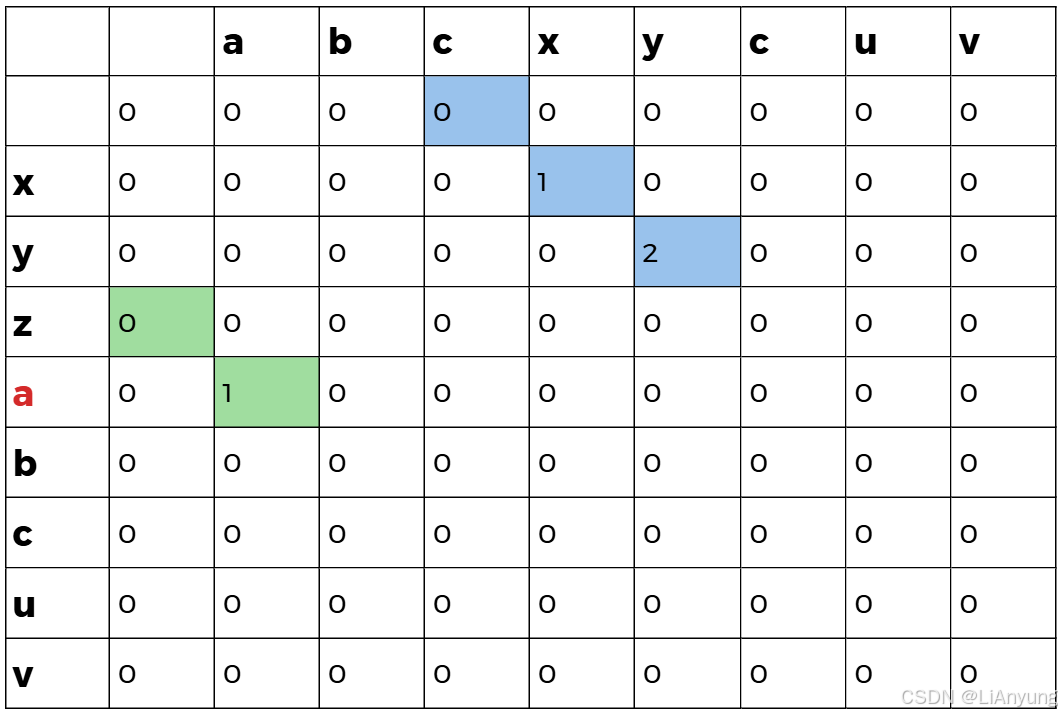
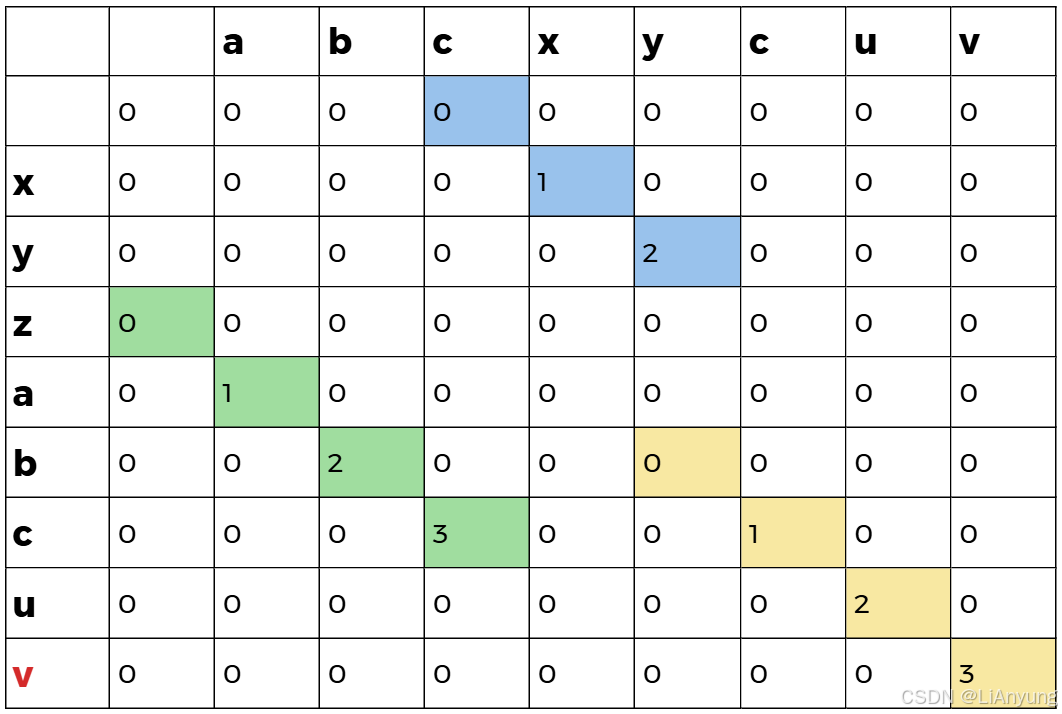
假设现在有两个字符串A = "xyzabcuv"和B = "abcxycuv",初始化9x9全为0的dp数组,如下图所示:
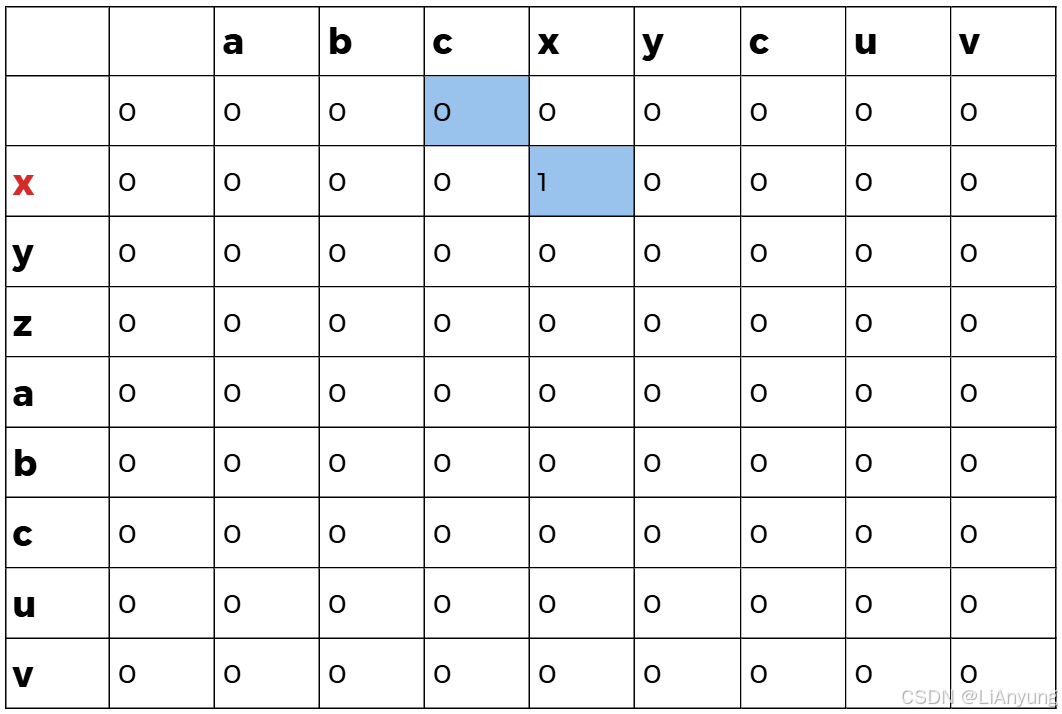
将A字符串的首个字符 'x' 依次与B字符串的每个字符比较,如果相同,令dp[1][j] = dp[0][j] + 1,即将左上角中的值加一填入当前位置;如果不同,dp[1][j] = 0,即当前位置为0 。
'x' 与B中第四位字符相同,取左上值0加上1得1,填入1。第一轮遍历后得到如下图表:
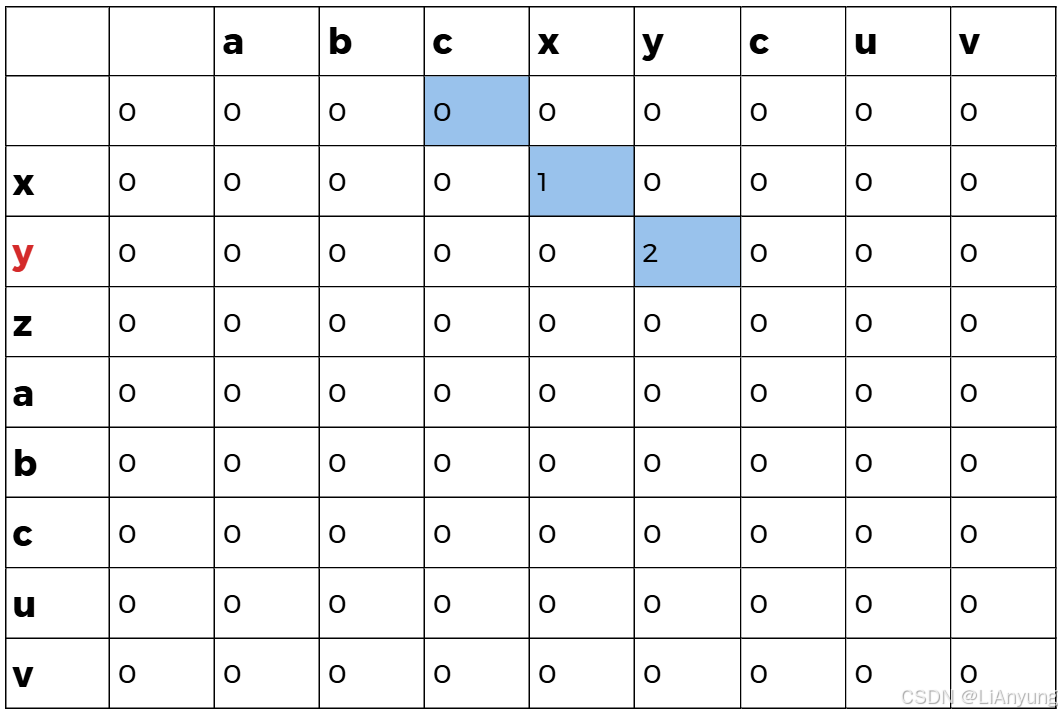
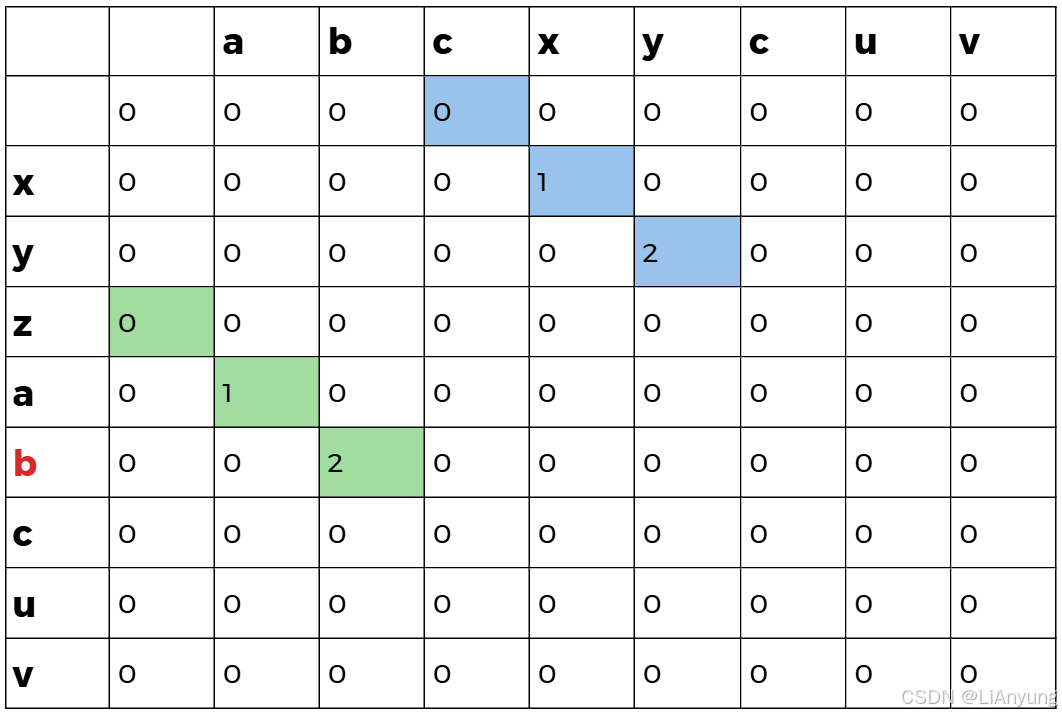
同样的,将第二个字符 'y' 与B中的每个字符比较,'y' 与B中第五个字符相同,取左上值1加上1得2,填入2。第二轮遍历后得到如下图表:
第三轮遍历后,无相同的匹配字符,因此全为0 。
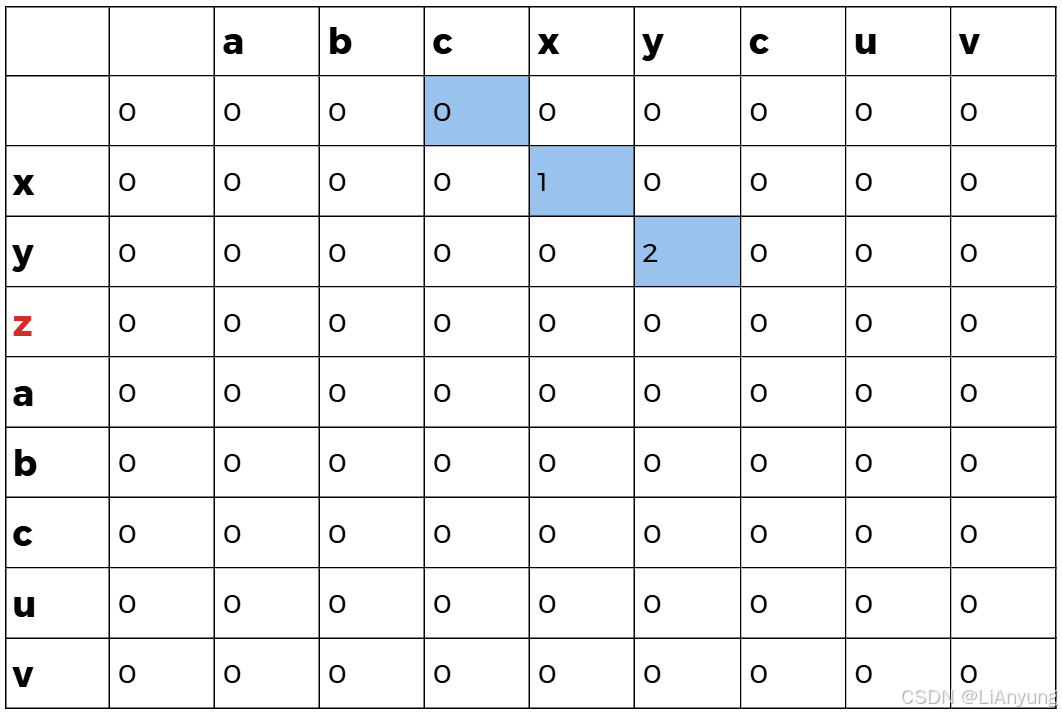
继续遍历。
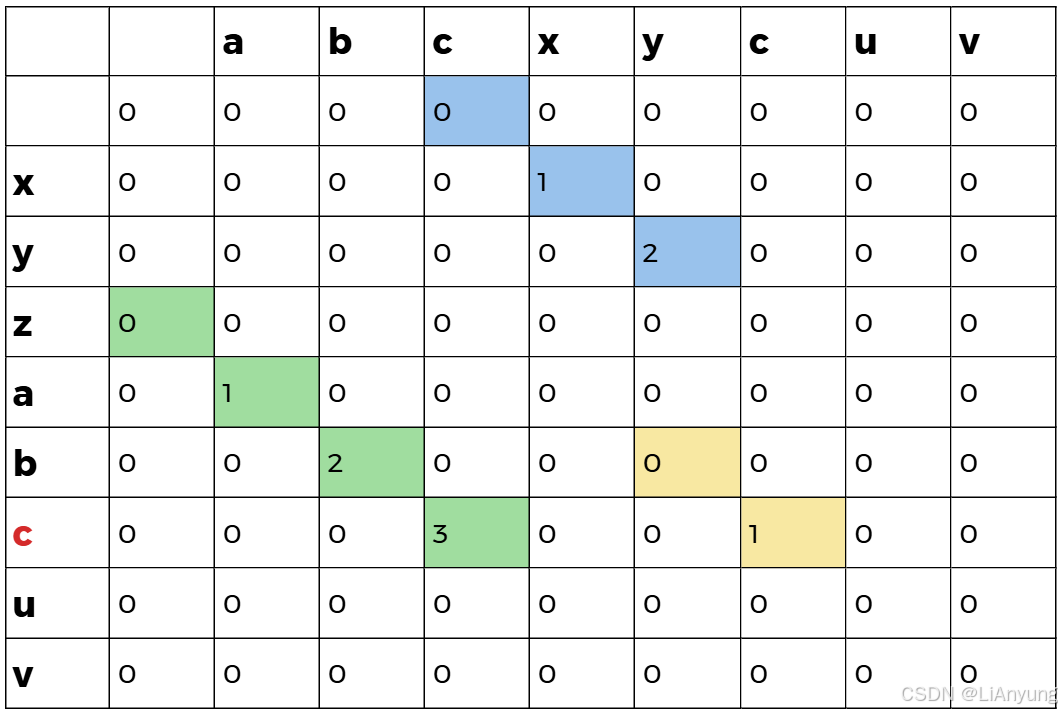
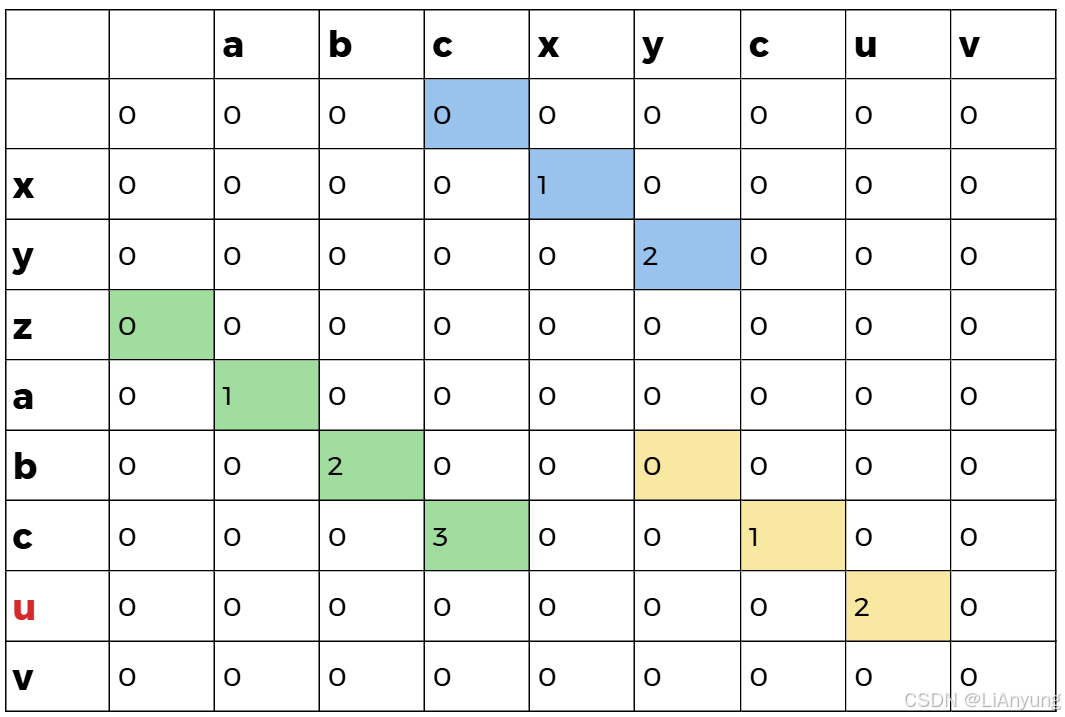
最后A字符串中的 'v' 遍历结束,整个dp数组中最大为3,表示最长公共子串长度为3,最终得到的最长公共子串为 'abc' 和 'cuv'。
四、代码实现
1. 基础代码
def longest_common_substring(s: str, t: str) -> str:
m, n = len(s), len(t)
# 创建 DP 表,初始化为 0
dp = [[0] * (n + 1) for _ in range(m + 1)]
max_length = 0 # 记录最长公共子串的长度
end_index = 0 # 记录最长公共子串在 s 中的结束位置
# 填充 DP 表
for i in range(1, m + 1):
for j in range(1, n + 1):
if s[i - 1] == t[j - 1]: # 如果字符匹配
dp[i][j] = dp[i - 1][j - 1] + 1
if dp[i][j] > max_length: # 更新最大长度和结束位置
max_length = dp[i][j]
end_index = i
else:
dp[i][j] = 0 # 不匹配时,子串长度为 0
return s[end_index - max_length:end_index]
# 测试
s = "xyzabcuv"
t = "abcxycuv"
result = longest_common_substring(s, t)
print("最长公共子串是:", result) # 输出: abc2. 空间优化
下方为经过空间优化后的代码,将空间复杂度从m*n降至n,同时,新添max_dp数组记录字符串每个字符位所出现的最大长度,对应读取字符串可以实现将所有最长公共子串输出。
def longest_common_substring(s: str, t: str) -> str:
m, n = len(s), len(t)
# 创建 DP 表,初始化为 0
dp = [0] * (n + 1)
max_length = 0 # 记录最长公共子串的长度
end_index = 0 # 记录最长公共子串在 s 中的结束位置
max_dp = [0] * (n + 1) # 记录t字符串中每个字符位最大数
# 填充 DP 表
for i in range(1, m + 1):
for j in range(n, 0, -1): # 从右向左遍历字符串t
if s[i - 1] == t[j - 1]:
dp[j] = dp[j - 1] + 1
if dp[j] > max_dp[j]:
max_dp[j] = dp[j]
if dp[j] > max_length:
max_length = dp[j]
end_index = j
else:
dp[j] = 0
print(max_dp) # [0, 1, 2, 3, 1, 2, 1, 2, 3]
return t[end_index - max_length:end_index]
# 测试
s = "xyzabcuv"
t = "abcxycuv"
result = longest_common_substring(s, t)
print("最长公共子串是:", result) # 输出: abc五、拓展延伸
后续可学习滑动窗口、后缀结构或扩展状态设计相关知识。
以下为变形问题及解决思路。
1. 多个最长公共子串
目标:找出所有相同长度的最长公共子串。
方法:在动态规划中维护一个列表,记录所有达到最大长度的结束位置,最后提取子串并去重。
2. 允许k次不匹配的最长公共子串
目标:允许最多k个字符不匹配,求最长子串。
方法:
- 动态规划:扩展状态为 dp[i][j][k],记录允许k次不匹配时的最长长度(空间复杂度高)。
- 滑动窗口+二分查找:二分猜测长度L,用滑动窗口验证是否存在允许k次不匹配的L长度子串。
3. 多个字符串的最长公共子串
目标:在多个字符串中找最长公共子串。
方法:
- 后缀自动机/广义后缀树:高效处理多字符串的公共子串。
- 暴力枚举:取最短字符串的子串,逐一验证是否存在于其他字符串。
4. 最长公共子串的出现次数
目标:统计最长公共子串在两个字符串中的出现次数。
方法:通过KMP算法或后缀数组统计子串出现次数。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)