哈夫曼编码(Huffman Coding)
在 1952 年提出,被广泛应用于文件压缩(如 ZIP)、图像压缩(如 JPEG)、视频编码(如 H.264)等领域。我们在发送消息的时候我们都会将信息先利用二进制编码,再将最少的二进制数编码信息传递至接受的一方,通过解码来接受信息。它由**克劳德·香农(Claude Shannon)**在 1948 年的信息理论中提出,因此也称为。,则它包含的信息量也越大,信息熵也就越高。的编码方法,即哈夫曼编
一、背景介绍
哈夫曼编码由 David A. Huffman 在 1952 年提出,被广泛应用于文件压缩(如 ZIP)、图像压缩(如 JPEG)、视频编码(如 H.264)等领域。1952 年,麻省理工学院(MIT)的一名研究生 David A. Huffman 在期末考试选择参加考试还是写一篇期末论文时,解决了信息编码最优化问题,提出了一种基于贪心算法的编码方法,即哈夫曼编码。(如何用最少的二进制数来表示信息)
二、信息论的基本概念和现代信息压缩技术的基本思想
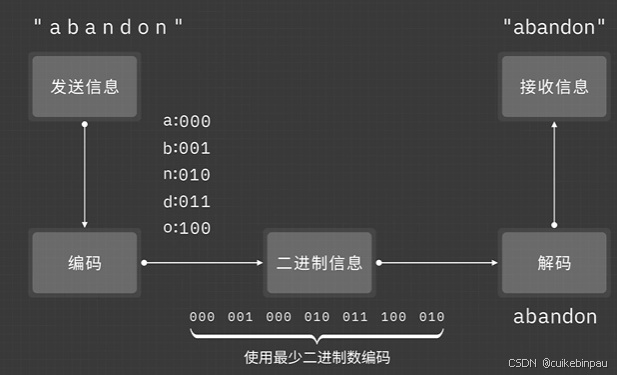
我们在发送消息的时候我们都会将信息先利用二进制编码,再将最少的二进制数编码信息传递至接受的一方,通过解码来接受信息。
编码所需要满足的条件
1、每单个字符都必须映射到一个唯一的二进制编码
2、保证解码七能够进行唯一的解码(无损压缩)
无损压缩的选择
使用尽量少的比特数(二进制长度bits)进行压缩

衡量信息——信息量与不确定性有关,信息量与发生概率成反比
三、信息熵
信息熵(Entropy)是信息论中的一个核心概念,用来衡量信息的不确定性或平均信息量。它由**克劳德·香农(Claude Shannon)**在 1948 年的信息理论中提出,因此也称为 香农熵(Shannon Entropy)。
信息熵反映了一个消息源的平均信息量,如果某个系统的不确定性越大,则它包含的信息量也越大,信息熵也就越高。相反,如果某个系统的确定性越高(比如某个事件总是发生),那么它的信息熵就越低。
信息熵的数学公式

信息熵的直观理解
- 如果一个系统的所有状态都等可能发生(比如抛一枚公平的硬币),则信息熵最大,因为我们无法预先确定它的结果。
- 如果某个状态的概率非常高(比如天气预报说 99% 明天是晴天),那么信息熵会很低,因为我们几乎可以确定它的结果。
- 如果一个事件是确定的(概率是 1),那么信息熵为 0,因为没有不确定性,不需要额外的信息来描述它。
信息熵与哈夫曼编码的关系
在哈夫曼编码中,我们的目标是用最少的比特数来编码数据,也就是设计一个最优编码方案。信息熵在其中起到了指导作用:
-
信息熵是理论上的最优压缩极限
- 任何编码的平均比特长度不可能小于信息熵,即: 平均编码长度≥H(X)\text{平均编码长度} \geq H(X)平均编码长度≥H(X)
- 也就是说,信息熵是我们最理想的压缩目标,哈夫曼编码能够接近这个最优极限。
-
字符出现的概率影响编码长度
- 在哈夫曼编码中,频率高的字符用短编码,频率低的字符用长编码,从而减少整体编码的平均长度。
- 这正是利用了信息熵的性质——如果某个符号的概率高,它所包含的信息量少,我们应该用更少的比特来表示它。
四、哈夫曼树
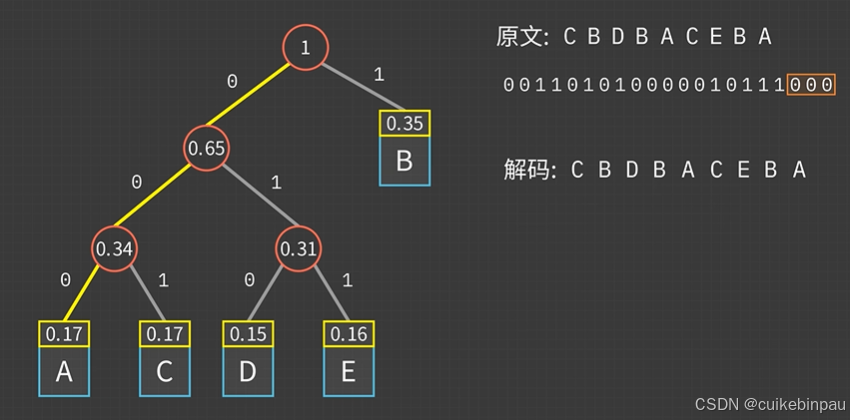
哈夫曼树的构建过程如下:
- 统计字符频率:首先,计算每个字符在文本中出现的次数。
- 创建节点并构建最小堆:将每个字符视为一个单独的树节点,节点的权重为该字符的频率。然后,使用最小堆(优先队列)存储这些节点,使得频率最低的节点始终位于最前。
- 合并最小的两个节点:从最小堆中取出两个最小频率的节点,创建一个新的父节点,其权重等于两个子节点的权重之和。这个新节点没有字符值,它仅仅是两个子节点的父节点。
- 重复合并,直到只剩下一个根节点:重复此过程,直到所有节点合并成一棵完整的二叉树,即哈夫曼树。
- 生成哈夫曼编码:从根节点出发,规定左子树路径记为 0,右子树路径记为 1,这样每个叶子节点(字符)都有一个唯一的二进制编码。
哈夫曼树的特点:
- 前缀无冲突:生成的编码不会有前缀重叠,确保解码时不会产生歧义。
- 最优编码:在已知字符频率的情况下,哈夫曼树生成的编码是最短的。
- 贪心算法应用:构建过程采用了贪心策略,每次合并最小的两个节点,保证了整体的最优解。
五、算法实践
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_NODES 256 // 最大字符种类
#define MAX_TREE_NODES (MAX_NODES * 2 - 1)
typedef struct {
char ch;
int freq;
char code[MAX_NODES];
} HuffmanNode;
typedef struct {
int weight;
int parent, left, right;
} TreeNode;
TreeNode huffmanTree[MAX_TREE_NODES]; // 哈夫曼树
HuffmanNode huffmanCode[MAX_NODES]; // 哈夫曼编码表
int totalNodes = 0; // 节点总数
// **1. 统计字符频率**
void calculateFrequency(const char *str, int freq[]) {
while (*str) {
freq[(unsigned char)(*str)]++;
str++;
}
}
// **2. 选择两个最小权重的节点**
void selectMin(int n, int *s1, int *s2) {
int min1 = -1, min2 = -1;
for (int i = 0; i < n; i++) {
if (huffmanTree[i].parent == -1) { // 仅选择尚未加入树的节点
if (min1 == -1 || huffmanTree[i].weight < huffmanTree[min1].weight) {
min2 = min1;
min1 = i;
} else if (min2 == -1 || huffmanTree[i].weight < huffmanTree[min2].weight) {
min2 = i;
}
}
}
*s1 = min1;
*s2 = min2;
}
// **3. 构建哈夫曼树**
void buildHuffmanTree(int freq[]) {
int n = 0;
// 初始化叶子节点
for (int i = 0; i < MAX_NODES; i++) {
if (freq[i] > 0) {
huffmanTree[n].weight = freq[i];
huffmanTree[n].parent = -1;
huffmanTree[n].left = -1;
huffmanTree[n].right = -1;
huffmanCode[n].ch = i;
huffmanCode[n].freq = freq[i];
n++;
}
}
totalNodes = n;
// 创建非叶子节点
for (int i = n; i < 2 * n - 1; i++) {
int s1, s2;
selectMin(i, &s1, &s2);
huffmanTree[i].weight = huffmanTree[s1].weight + huffmanTree[s2].weight;
huffmanTree[i].left = s1;
huffmanTree[i].right = s2;
huffmanTree[i].parent = -1;
huffmanTree[s1].parent = i;
huffmanTree[s2].parent = i;
}
}
// **4. 生成哈夫曼编码**
void generateHuffmanCodes() {
char tempCode[MAX_NODES];
int index = 0;
for (int i = 0; i < totalNodes; i++) {
if (huffmanTree[i].left == -1 && huffmanTree[i].right == -1) {
int current = i, parent;
index = 0;
while (huffmanTree[current].parent != -1) {
parent = huffmanTree[current].parent;
if (huffmanTree[parent].left == current) {
tempCode[index++] = '0';
} else {
tempCode[index++] = '1';
}
current = parent;
}
tempCode[index] = '\0';
// 反转编码
for (int j = 0; j < index; j++) {
huffmanCode[i].code[j] = tempCode[index - j - 1];
}
huffmanCode[i].code[index] = '\0';
}
}
}
// **5. 打印哈夫曼编码表**
void printHuffmanCodes() {
printf("\nHuffman Codes:\n");
for (int i = 0; i < totalNodes; i++) {
if (huffmanTree[i].left == -1 && huffmanTree[i].right == -1) {
printf("Character: %c | Frequency: %d | Code: %s\n",
huffmanCode[i].ch, huffmanCode[i].freq, huffmanCode[i].code);
}
}
}
// **6. 编码输入字符串**
void encodeString(const char *str, char *encodedStr) {
encodedStr[0] = '\0';
while (*str) {
for (int i = 0; i < totalNodes; i++) {
if (huffmanTree[i].left == -1 && huffmanTree[i].right == -1 && huffmanCode[i].ch == *str) {
strcat(encodedStr, huffmanCode[i].code);
break;
}
}
str++;
}
}
// **7. 解码哈夫曼编码**
void decodeString(const char *encodedStr, char *decodedStr) {
int index = 0;
int current = totalNodes - 1;
while (*encodedStr) {
if (*encodedStr == '0') {
current = huffmanTree[current].left;
} else {
current = huffmanTree[current].right;
}
if (huffmanTree[current].left == -1 && huffmanTree[current].right == -1) {
decodedStr[index++] = huffmanCode[current].ch;
current = totalNodes - 1;
}
encodedStr++;
}
decodedStr[index] = '\0';
}
// **8. 主函数**
int main() {
char input[] = "hello huffman";
int freq[MAX_NODES] = {0};
calculateFrequency(input, freq);
buildHuffmanTree(freq);
generateHuffmanCodes();
printHuffmanCodes();
// 编码字符串
char encodedStr[1024];
encodeString(input, encodedStr);
printf("\nEncoded String: %s\n", encodedStr);
// 解码字符串
char decodedStr[1024];
decodeString(encodedStr, decodedStr);
printf("\nDecoded String: %s\n", decodedStr);
return 0;
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)