【AAAI2024】SCTNet:具有Transformer语义信息的单分支CNN用于实时分割
| 标 题 | SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation |
|---|---|
| 作者 | Zhengze Xu*, Dongyue Wu, Changqian Yu, Xiangxiang Chu, Nong Sang, Changxin Gao |
| 机构 | National Key Laboratory of Multispectral Information Intelligent Processing Technology, School of Artificial Intelligence and Automation, Huazhong University of Science and Technology |
| 论文 | https://arxiv.org/pdf/2312.17071 |
| 代码 | https://github.com/xzz777/SCTNet |
摘要
最近的实时语义分割方法通常采用额外的语义分支来获取丰富的长距离上下文信息。然而,这一额外的分支会带来不必要的计算开销,并降低推理速度。为了消除这一困境,我们提出了SCTNet,一种单分支CNN结合变压器语义信息的实时分割网络。SCTNet在保持轻量级单分支CNN高效性的同时,享有无需推理的语义分支的丰富语义表示能力。SCTNet在训练时使用变压器作为仅训练的语义分支,利用其卓越的长距离上下文提取能力。借助所提出的类变压器CNN模块CFBlock和语义信息对齐模块,SCTNet能够在训练过程中从变压器分支捕获丰富的语义信息。在推理阶段,仅需要部署单分支的CNN。我们在Cityscapes、ADE20K和COCO-Stuff10K上进行了广泛的实验,结果表明,我们的方法达到了新的最先进性能。代码和模型可在GitHub - xzz777/SCTNet: Official implementation of SCTNet (AAAI2024)获得。
引言
作为计算机视觉中的一项基础任务,语义分割旨在为输入图像中的每个像素赋予语义类别标签。它在自动驾驶、医学图像处理、移动应用等众多领域中起着至关重要的作用。为了获得更好的分割性能,近年来的语义分割方法都在追求丰富的长距离上下文信息。为捕获和编码丰富的上下文信息,已提出了不同的方法,包括大感受野(Chen等人,2014, 2017, 2018)、多尺度特征融合(Ronneberger, Fischer, 和 Brox 2015;Zhao等人,2017)、自注意机制(Fu等人,2019;Huang等人,2019;Yuan等人,2018;Zhao等人,2018b;Dosovitskiy等人,2020)等。自注意机制作为Transformer的重要组成部分,已被证明在建模长距离上下文方面表现出色。尽管这些工作显著提升了性能,但通常也带来了高昂的计算成本。需要注意的是,基于自注意机制的工作,其计算复杂度与图像分辨率呈平方关系,在处理高分辨率图像时,极大地增加了延迟。这些限制阻碍了其在实时语义分割中的应用。
许多最近的实时分割方法采用==双分支架构==,以较快的速度提取高质量的语义信息。BiSeNet(Yu等人,2018)提出了一种双边网络,在早期阶段分离出详细的空间特征和充足的上下文信息,并以并行方式处理,如**图2(a)所示。继BiSeNet(Yu等人,2018)之后,BiSeNetV2(Yu等人,2021)和STDC(Fan等人,2021)进一步增强了提取丰富长距离上下文的能力,或减少了空间分支的计算成本。为了在推理速度和精度之间取得平衡,DDRNet(Pan等人,2022)、RTFormer(Wang等人,2022)和SeaFormer(Wan等人,2023)在较深的阶段采用了特征共享架构,如图2(b)**所示。然而,这些方法在两个分支之间引入了密集融合模块,以提升提取特征的语义信息。因此,这些双分支方法都在推理速度和高计算成本上遇到了瓶颈,因为它们引入了额外的分支和多个融合模块。
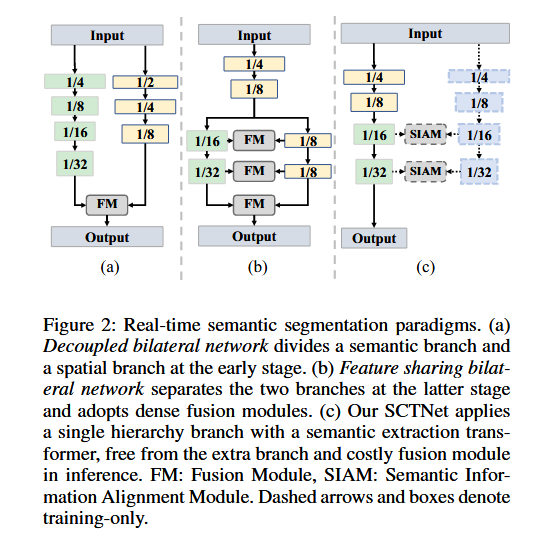
image-20241011180845926
图2:实时语义分割范式。(a)解耦的双分支网络在早期阶段将语义分支和空间分支分开。(b)特征共享的双分支网络在后期阶段将两个分支分离,并采用密集融合模块。(c)我们的SCTNet应用了单层次分支,并结合了语义提取变压器,推理过程中无需额外分支和昂贵的融合模块。FM:融合模块,SIAM:语义信息对齐模块。虚线箭头和框表示仅在训练时使用。
为了解决上述问题,我们提出了一种带有Transformer语义信息的单分支CNN用于实时分割(SCTNet)。该方法==能够在不依赖双分支网络的情况下高效提取语义信息,避免了双分支网络带来的重计算负担==。具体来说,SCTNet通过训练时使用Transformer语义分支,将长距离上下文信息从Transformer分支传递到CNN分支中。为了减少Transformer和CNN之间的语义差距,我们精心设计了==Conv-Former Block(CFBlock)==,并在对齐之前使用共享的解码头。通过训练中的语义信息对齐,单分支CNN能够同时编码语义信息和空间细节。因此,SCTNet能够在保持轻量级单分支CNN架构高效推理的同时,利用Transformer架构的大感受野对齐语义表示。整体架构**如图2(c)**所示。==我们在三个具有挑战性的数据集上进行了广泛的实验结果表明,SCTNet比现有的实时语义分割方法在精度和速度之间取得了更好的平衡。==图1直观地展示了SCTNet与其他实时分割方法在Cityscapes验证集上的对比。
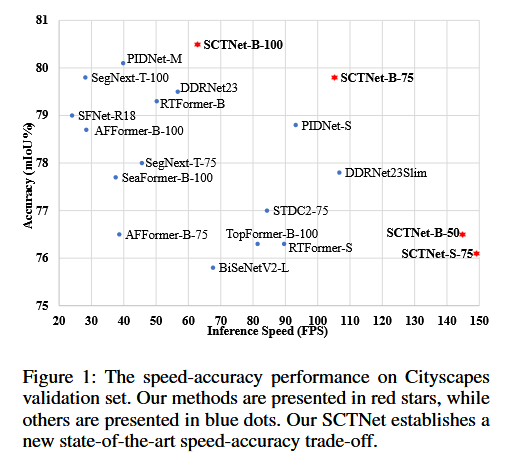
image-20241011181036435
图1:在Cityscapes验证集上的速度-准确性表现。我们的方法以红色星形标记表示,其他方法以蓝色圆点表示。我们的SCTNet在速度和准确性的权衡上建立了新的最先进水平。
本文提出的SCTNet的主要贡献可归纳为以下三个方面:
-
我们提出了一种新的单分支实时分割网络SCTNet。通过学习利用Transformer对CNN进行语义信息对齐,SCTNet在保持轻量级单分支CNN快速推理的同时,享有Transformer的高精度。
-
为了减轻CNN特征与Transformer特征之间的语义差距,我们设计了CFBlock(Conv-Former Block),它能够通过卷积操作捕获类似Transformer模块的长距离上下文。此外,我们还提出了SIAM(语义信息对齐模块),以更有效地对齐特征。
-
大量实验结果表明,SCTNet在Cityscapes、ADE20K和COCO-Stuff-10K上超越了现有的最先进的实时语义分割方法。==SCTNet为提升实时语义分割的速度和性能提供了新视角==。
相关工作
语义分割
自从FCN(Long, Shelhamer, 和 Darrell 2015)提出以来,利用CNN进行语义分割成为了主流趋势。FCN之后,提出了一系列改进的基于CNN的语义分割方法。DeepLab(Chen等人,2017)通过膨胀卷积扩大了感受野。PSPNet(Zhao等人,2017)、U-Net(Ronneberger, Fischer, 和 Brox 2015)以及RefineNet(Lin等人,2017)融合了不同层次的特征表示,以捕获多尺度上下文。一些方法(Fu等人,2019;Huang等人,2019;Yuan等人,2018;Zhao等人,2018b)提出了各种注意力模块来提升分割性能。近年来,Transformer被引入语义分割中,表现出了极具前景的性能。SETR(Zheng等人,2021)首次直接将视觉Transformer应用于图像分割。PVT(Wang等人,2021)将典型的CNN层次结构引入了基于Transformer的语义分割模型中。SegFormer(Xie等人,2021)提出了一种高效的多尺度Transformer分割模型。
实时语义分割
早期的实时语义分割方法(Paszke等人,2016;Wu, Shen, 和 Hengel 2017)通常通过==压缩通道数或快速降采样来加速推理==。ICNet(Zhao等人,2018a)首次引入了一个多分辨率图像级联网络,以加速分割速度。BiSeNetV1(Yu等人,2018)和BiSeNetV2(Yu等人,2021)采用了双分支架构和特征融合模块,在速度和精度之间取得了更好的平衡。STDC(Fan等人,2021)重新思考了BiSeNet的双分支网络,去除了空间分支,并添加了详细的引导模块。DDRNet(Pan等人,2022)通过在早期阶段共享分支,实现了更好的速度与精度平衡。最近提出了一些基于Transformer的高效实时分割方法,但它们仍然存在一些未解决的问题。TopFormer(Zhang等人,2022)仅在特征图的1/64尺度上使用Transformer,导致精度较低。RTFormer(Wang等人,2022)和SeaFormer(Wan等人,2023)需要两个分支之间频繁的交互,增加了额外的计算,降低了推理速度。此外,也有一些单分支和多分支方法用于实时分割。
注意力机制
近年来,注意力机制在计算机视觉中得到了广泛应用。许多方法致力于提升注意力机制的线性复杂度。经典的线性注意力机制如Swin(Liu等人,2021)和MSG(Fang等人,2022)包含了频繁的移动或重组操作,这些操作带来了大量的延迟。MSCA(Guo等人,2022b)展示了出色的性能,但其大核卷积并不适合移动设备,且其多尺度注意力设计进一步增加了推理速度的负担。外部注意力(Guo等人,2022a)采用了非常简单的形式,它使用外部参数作为key和value,并通过两个线性层实现注意力机制。GFA(GPU-Friendly Attention)(Wang等人,2022)通过用组双归一代替外部注意力中的头部分裂,提升了GPU的友好性。
总结
该部分介绍了论文中所涉及的三大领域的相关工作:语义分割、实时语义分割以及注意力机制,分别总结了经典方法的创新之处及其局限性,并展示了当前最先进的工作。SCTNet的提出正是为了应对这些现有方法中的挑战,如==推理速度与精度之间的平衡问题、额外计算开销、以及如何高效捕获长距离语义信息==。
方法论
1. 动机
移除双分支网络中的语义分支可以显著加快推理速度。然而,这会导致浅层单分支网络缺乏长距离语义信息,从而降低准确性。虽然使用深度编码器、强大的解码器或复杂的增强模块可以恢复准确性,但这些方法会减慢推理速度。为了解决这一问题,我们提出了一种只在训练时对齐语义信息的方法,这种方法在不牺牲推理速度的情况下丰富了语义信息。具体来说,我们提出了一种带有训练时语义提取Transformer的单分支卷积网络SCTNet,它结合了Transformer的高精度和CNN的快速推理速度。SCTNet的整体架构如图3所示。
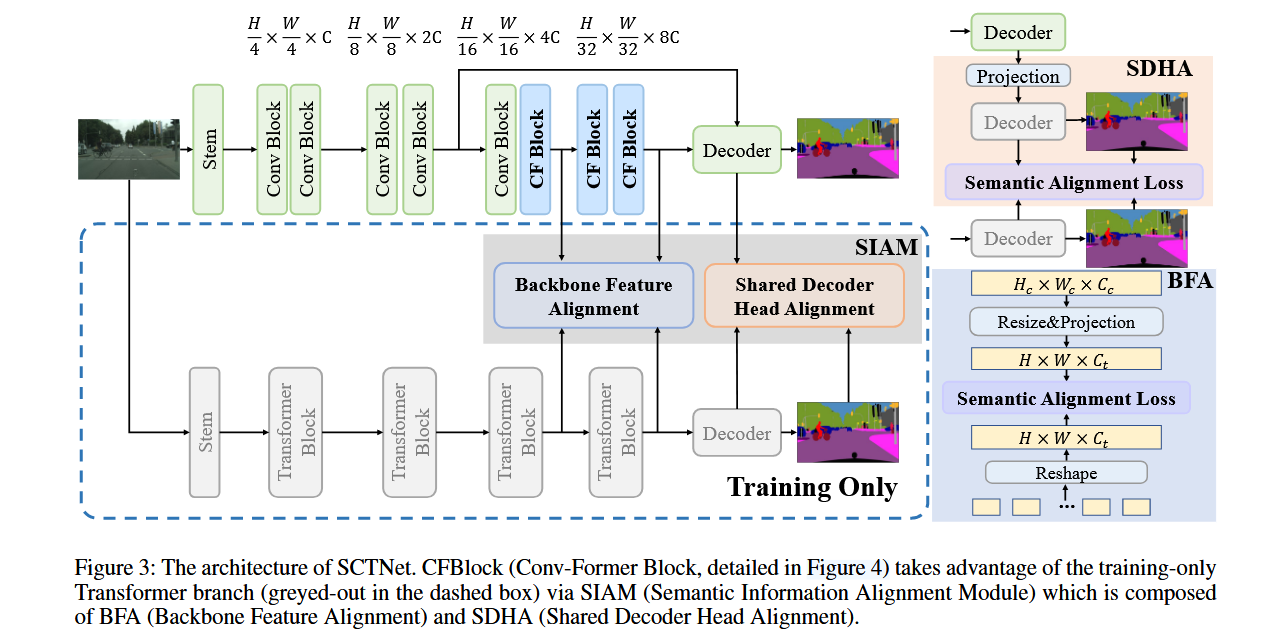
image-20241011181434516
图3:SCTNet的架构。CFBlock(卷积-变压器块,详见图4)通过SIAM(语义信息对齐模块)利用了仅在训练时使用的变压器分支(虚线框中的灰色部分),SIAM由BFA(骨干特征对齐)和SDHA(共享解码头对齐)组成。
2. Conv-Former Block(卷积-变压器块)
由于CNN和Transformer是不同类型的网络,它们==提取的特征表示差异很大==。直接对齐CNN与Transformer之间的特征会导致学习过程变得困难,进而限制了性能的提升。为了让CNN分支更容易从Transformer分支中学习如何提取高质量的语义信息,我们设计了Conv-Former Block。Conv-Former Block尽可能地模拟Transformer块的结构,以便更好地学习Transformer分支的语义信息。同时,Conv-Former Block仅使用高效的卷积操作来实现注意力功能。
Conv-Former Block的结构类似于典型的Transformer编码器(Vaswani等人,2017),如图 4 左侧所示。其过程如下所示:
其中,Norm(·)表示批归一化(Ioffe和Szegedy 2015),x、f、y分别表示输入、隐藏特征和输出。
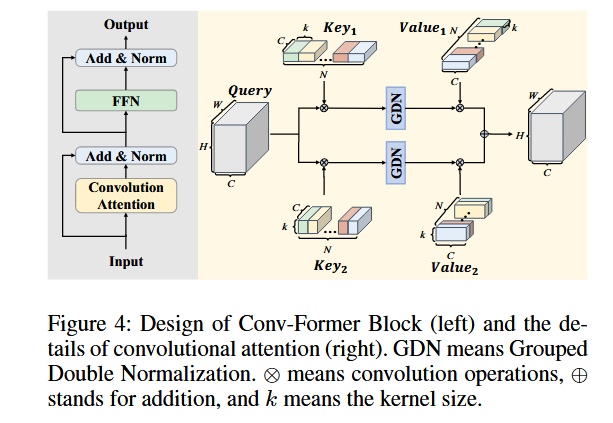
image-20241011181810403
图4:卷积-变压器块(左)的设计和卷积注意力的详细结构(右)。GDN表示分组双归一化。⊗ 表示卷积操作,⊕ 表示加法,k 表示卷积核的大小。
2.1 卷积注意力机制
用于实时分割的注意力机制应具有低延迟和强大的语义提取能力。我们认为GFA是一种潜在的候选者。我们提出的卷积注意力是从GFA派生的。
与GFA相比,卷积注意力机制有两个主要区别。首先,我们用像素级卷积操作代替了GFA中的矩阵乘法。点卷积等价于像素到像素的乘法,但无需特征展平和重组操作。这些操作不利于保持内在的空间结构,并且增加了额外的推理延迟。此外,卷积提供了一种更灵活的方式来扩展外部参数。其次,鉴于Transformer与CNN之间的语义差距,仅通过计算可学习向量与每个像素之间的相似度并根据相似度图增强像素是不够的。为了更好地对齐Transformer的语义信息,我们将可学习向量扩大为可学习卷积核。这样做既转换了像素与可学习向量之间的相似度计算为像素块与可学习卷积核之间的相似度计算,也在某种程度上通过卷积操作保留了更多的局部空间信息。
卷积注意力的操作可以总结为以下公式:
在这里,、、分别表示输入图像以及可学习的查询和键。、、 分别表示特征图的通道数、高度和宽度, 表示可学习参数的数量, 表示可学习参数的卷积核大小。符号 代表分组双归一化,它在 维度上应用 softmax,在 维度上应用分组的L2归一化。符号 表示卷积操作。
为了兼顾效率,我们使用条纹卷积代替标准卷积操作,具体来说,我们利用1×k和k×1卷积来近似k×k卷积层。卷积注意力机制的详细实现如图4所示。
2.2 前馈网络(FFN)
典型的FFN在提供位置编码和嵌入通道方面发挥了至关重要的作用。在最近的Transformer模型中,典型的FFN由扩展点卷积、深度3×3卷积和压缩点卷积组成。不同于典型的FFN,我们的FFN由两个标准的3×3卷积层组成。与典型的FFN相比,我们的FFN更高效,并提供了更大的感受野。
3. 语义信息对齐模块
我们提出了一个简单而有效的对齐模块,用于在训练过程中进行特征学习,如图3所示。它可以分为骨干特征对齐和共享解码头对齐两个部分。
3.1 骨干特征对齐
得益于Conv-Former Block的Transformer风格架构,特征对齐损失能够轻松对齐Conv-Former Block的特征与Transformer的特征。简而言之,骨干特征对齐首先对Transformer和CNN分支的特征进行下采样或上采样以进行对齐,然后将CNN的特征投影到Transformer的维度上。投影有两个目的:1)统一通道数;2)避免直接对齐特征,防止在训练过程中损坏CNN的监督信号。最后,将语义对齐损失应用于投影后的特征以对齐语义表示。
3.2 共享解码头对齐
Transformer解码器通常使用多个阶段的特征进行复杂解码,而SCTNet解码器仅使用第2和第4阶段的特征。考虑到解码空间的巨大差异,直接对齐解码特征和输出结果只能带来有限的改进。因此,我们提出了共享解码头对齐。具体来说,将单分支CNN的第2和第4阶段的特征进行级联,然后输入到一个点卷积中以扩展维度。接着,将高维特征通过Transformer解码器,计算解码器的新输出特征和结果与其原始输出之间的对齐损失。
4. 整体架构
为了在获得丰富语义信息的同时降低计算成本,我们简化了流行的双分支架构,仅在推理时使用一个单一的CNN分支,在训练时则使用Transformer分支进行语义对齐。
4.1 骨干网络
为了提升推理速度,SCTNet采用了典型的层次化CNN骨干网络。SCTNet从一个由两个连续的3×3卷积层组成的起始块开始。前两个阶段由堆叠的残差块组成(He等人,2016),而后两个阶段则包括我们提出的类变压器块,称为卷积-变压器块(CFBlock)。CFBlock使用一些精心设计的卷积操作来执行类似于变压器块的长距离上下文捕捉功能。在第2至第4阶段的开始,我们应用了一个convdown层,该层由一个带有批量归一化和ReLU激活的步幅卷积组成,用于下采样。为了简洁,图3中省略了这一部分。
4.2 解码头
解码头由一个DAPPM(Pan等人,2022)和一个分割头组成。为了进一步丰富上下文信息,我们在第4阶段的输出之后添加了一个DAPPM模块。然后,将该输出与第2阶段的特征图进行级联。最后,将该输出特征传递到一个分割头中。具体来说,分割头由一个3×3卷积-BN-ReLU运算符组成,后接一个1×1卷积分类器。
4.3 训练阶段
众所周知,Transformer在捕捉全局语义上下文方面表现出色,而CNN已被广泛证明在建模层次化的局部信息方面优于Transformer。受Transformer和CNN各自优势的启发,我们探讨了如何为实时分割网络同时引入这两者的优点。我们提出了一种单分支CNN,该CNN通过对齐其特征与强大的Transformer的特征,学习如何提取丰富的全局上下文和详细的空间信息。具体来说,在训练阶段,SCTNet采用了一个仅用于训练的Transformer作为语义分支,以提取强大的全局语义上下文。语义信息对齐模块监督卷积分支对齐来自Transformer的高质量全局上下文。
4.4 推理阶段
为了避免双分支网络的高计算成本,推理阶段只部署CNN分支。利用与Transformer对齐的语义信息,单分支CNN可以生成准确的分割结果,而无需额外的语义提取或高成本的密集融合操作。具体来说,输入图像被输入到单分支分层卷积骨干网络中,然后解码头从骨干网络中提取特征,并进行简单的级联,随后进行像素级分类。
5. 对齐损失(Alignment Loss)
为了更好地对齐语义信息,需要一种专注于语义信息而非空间信息的对齐损失。在具体实现中,我们使用了CWD损失(channel-wise distillation loss, 通道级蒸馏损失)(Shu等人,2021)作为对齐损失,它比其他损失函数表现得更好。CWD损失可以总结为如下公式:
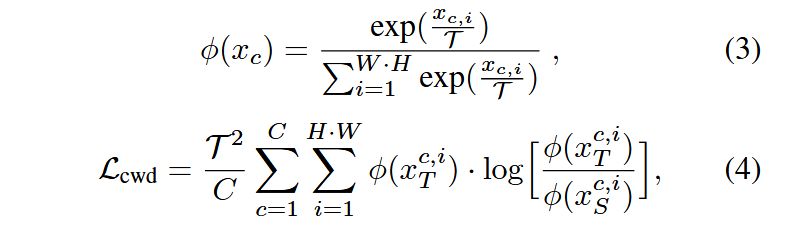
image-20241011182855491
其中, 表示通道索引, 表示空间位置, 和 分别是变压器分支和CNN分支的特征图。 将特征激活转换为按通道的概率分布,去除变压器和紧凑型CNN之间的尺度影响。为了最小化 ,当 大时, 也应该大。但当 小时, 的值无关紧要。这样可以迫使CNN学习前景显著性分布,其中包含语义信息。 是一个超参数,称为温度。 越大,概率分布越平滑。
( \phi(x_{c,i}^S) )
实验
1数据集与实现细节
我们在三个数据集上对SCTNet进行了实验,即Cityscapes(Cordts等人,2016)、ADE20K(Zhou等人,2017)和COCO-Stuff-10K(Caesar, Uijlings, 和 Ferrari 2018),以证明我们方法的有效性。为了公平比较,我们将我们的基础模型SCTNet-B的规模与RTFormer-B、DDRNet-23和STDC2相当。此外,我们还引入了一个较小的变体,称为SCTNet-S。我们首先在ImageNet(Deng等人,2009)上预训练我们的CNN骨干网络,然后在语义分割数据集上进行微调。在训练阶段使用的语义Transformer分支可以是任何层次化的Transformer网络。在我们的实现中,所有实验中都选择SegFormer作为Transformer分支。我们在单个NVIDIA RTX 3090上测量所有方法的推理速度。除非特别说明,所有报告的FPS结果都在相同的输入分辨率下获得,以进行公平的性能比较。对于Cityscapes,我们在Torch和TensorRT实现下测量了推理速度。
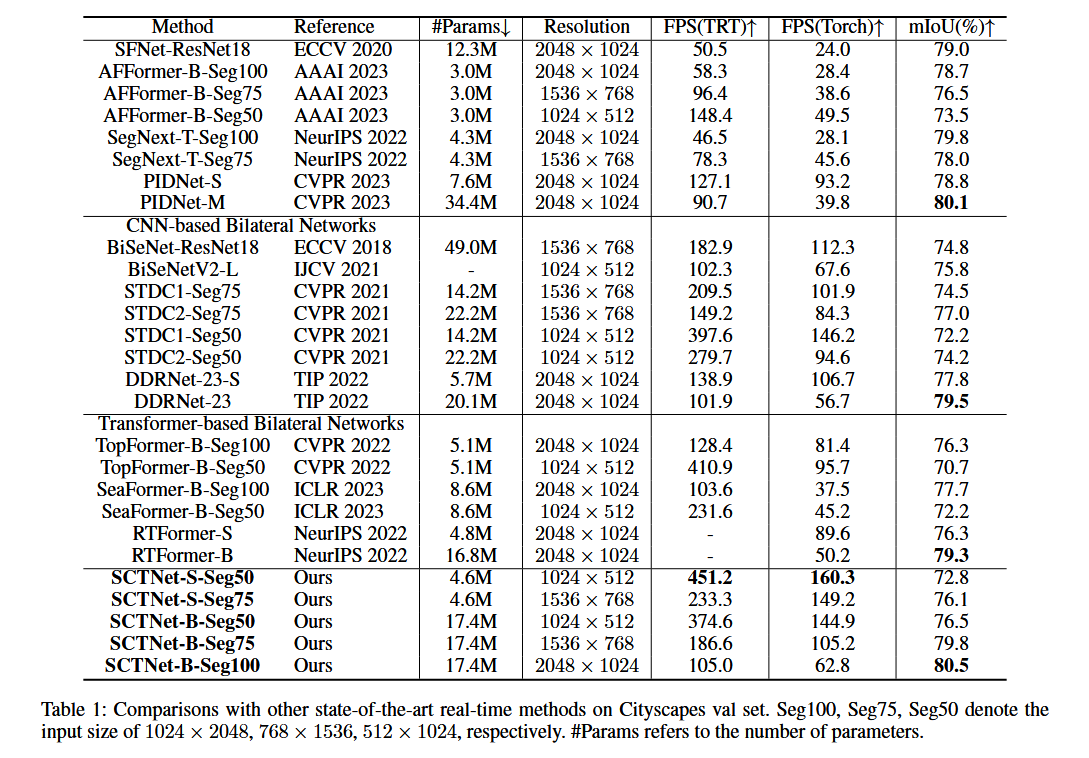
image-20241011183407189
表1:与其他最先进的实时方法在Cityscapes验证集上的比较。Seg100、Seg75、Seg50分别表示输入尺寸为1024 × 2048、768 × 1536、512 × 1024。#Params表示参数的数量。
2 与最先进方法的比较
Cityscapes上的结果:Cityscapes(Cordts等人,2016)上的相应结果如表1所示。我们的SCTNet比其他实时方法有了很大的改进,并且在TensorRT和Torch实现中都达到了新的最佳速度-准确性权衡。例如,我们的SCTNet-B-Seg100在62.8 FPS的速度下实现了80.5%的mIoU,成为新的实时分割性能的最先进方法。我们的SCTNet-B-Seg75达到了79.8%的mIoU,准确率优于最先进的Transformer双分支网络RTFormer-B和基于CNN的双分支网络DDRNet-23,并且速度提高了两倍。我们的SCTNet-B在所有输入分辨率下的速度比所有其他方法更快,且mIoU结果更好。此外,我们的SCTNet-S在与STDC2(Fan等人,2021)、RTFormer-S(Wang等人,2022)、SeaFormer-B(Wan等人,2023)和TopFormer-B(Zhang等人,2022)的对比中,也取得了更好的权衡。
ADE20K上的结果:在ADE20K(Zhou等人,2017)上,我们的SCTNet以最快的速度实现了最佳的准确性。例如,我们的SCTNet-B在145.1 FPS的超高速度下实现了43.0%的mIoU,比RTFormer-B(Wang等人,2022)的准确率高出0.9%,速度却快了1.6倍。我们的SCTNet-S在保持所有其他方法中最高的FPS的同时,达到了37.7%的mIoU。考虑到ADE20K(Zhou等人,2017)中图像种类繁多且语义类别多样,这一出色的结果进一步证明了SCTNet的泛化能力。
COCO-Stuff-10K上的结果:COCO-Stuff-10K上的相应结果如表3所示。SCTNet展示了SOTA(最先进)性能,并在COCO-Stuff-10K中保持了实时语义分割方法的最高推理速度。输入尺寸为640×640时,SCTNet-B以141.5 FPS的速度实现了35.9%的mIoU,准确率比RTFormer-B高出0.6%,速度快了约1.6倍。
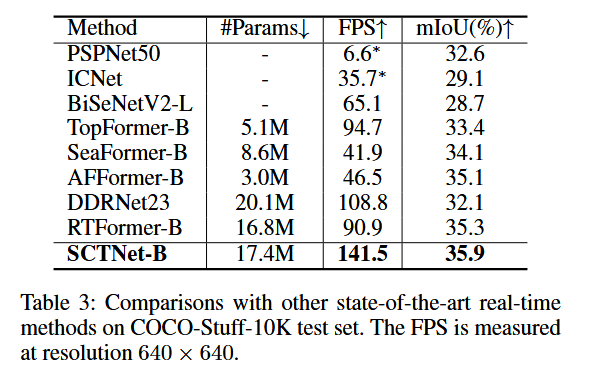
image-20241011183523480
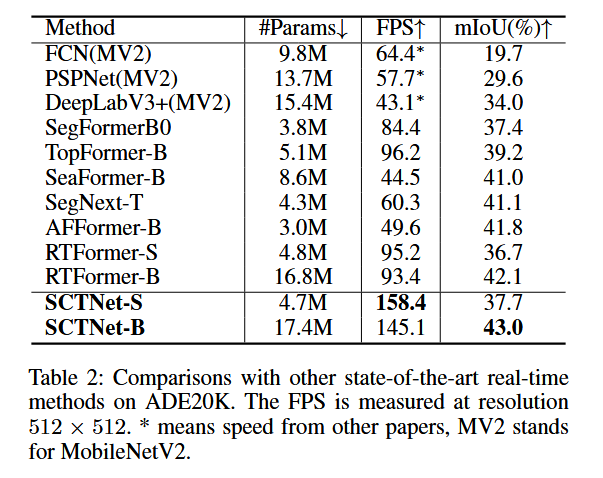
image-20241011183445668
==表2在原论文中的内容中没有提及==
3 消融研究(Ablation Study)
3.1 不同类型块的比较
为了验证我们提出的CFBlock的有效性,我们将CFBlock替换为其他类型的卷积块和Transformer块进行实时分割的快速评估。表4列出了这些结果,所有这些结果均未在ImageNet上进行预训练。我们选择了四种块进行比较。如表4所示,我们的CFBlock在mIoU上超越了典型的ResBlock,并且在速度和准确率之间取得了显著的改进。此外,与最先进的GFABlock(Wang等人,2022)和来自SegNext的MSCANBlock(Guo等人,2022b)相比,我们的CFBlock在速度和准确性权衡上表现得更好。CFBlock的mIoU比GFABlock高出0.9%,同时在参数更少和速度更快的情况下,保持了与MSCANBlock相似的性能。这也表明,我们的SCTNet能够更好地缓解CNN与Transformer之间的语义信息差距,同时避免高计算成本。
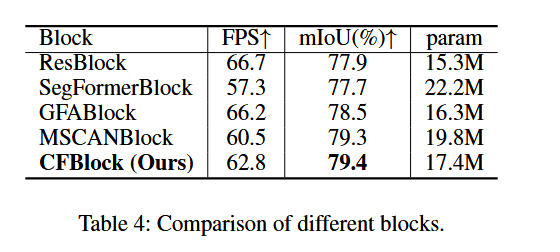
image-20241011183652450
3.2 语义信息对齐模块的有效性
虽然我们的SIAM(语义信息对齐模块)与精心设计的SCTNet紧密相关,但它也能够提升其他CNN和Transformer分割方法的性能。表5展示了采用SIAM在SegFormer、SegNext、SeaFormer和DDRNet上的一致性改进,证明了我们提出的SIAM的有效性和泛化能力。同时,作为双分支Transformer和双分支CNN网络的代表,SeaFormer和DDRNet的改进相对较小。这可能归因于它们的双分支网络结构已经受益于额外的语义分支。此外,这也证实了我们SIAM与仅训练用的Transformer协同作用,确实充当了双分支网络中的语义分支,从而提高了单分支网络的准确性。
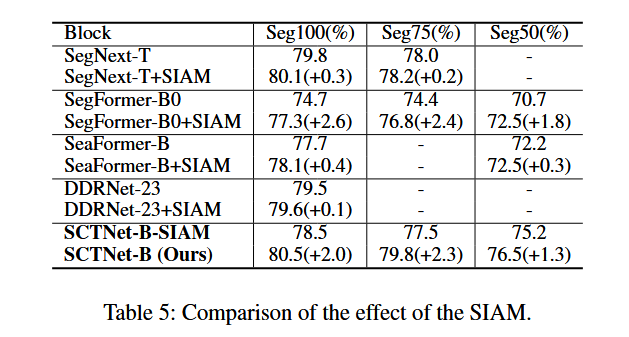
image-20241011183814914
3.3 组件消融
我们探索了所提组件的效果,如表6所示。以Seg100为例,单纯将ResBlock替换为我们的CFBlock使mIoU提升了2.1%,且速度损失很小。BFA(骨干特征对齐)使mIoU提高了1.2%,而SDHA(共享解码头对齐)进一步使mIoU提升了0.8%,且不牺牲速度。
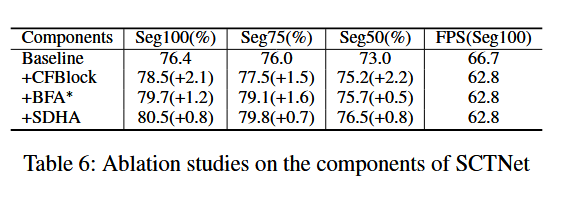
image-20241011183831233
4. 可视化结果(Visualization Results)
图5展示了在Cityscapes(Cordts等人,2016)验证集上的可视化结果。与DDRNet和RTFormer相比,我们的SCTNet-B生成了更细致的掩码,如浅蓝框所示,并且对大区域的预测更加准确,如黄色框所示。这表明SCTNet在提取高质量的长距离上下文的同时,保留了细微的细节。
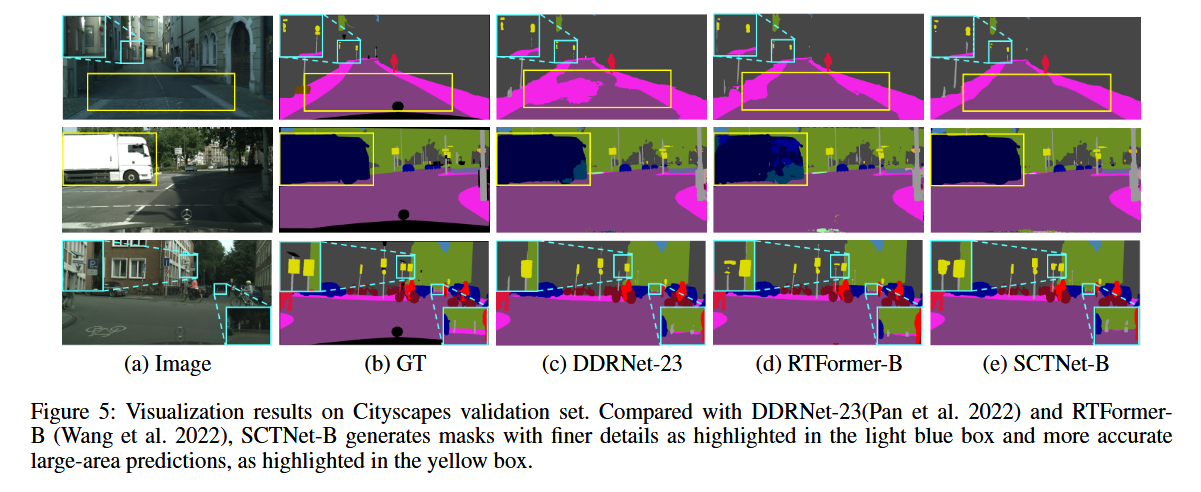
image-20241011183933446
结论(Conclusion)
在本文中,我们提出了SCTNet,一种新颖的单分支架构,可以在不增加额外推理计算成本的情况下提取高质量的长距离上下文信息。大量实验表明,SCTNet达到了新的最先进结果。此外,通过展示SCTNet的高效性,我们为双分支网络中的语义分支提供了一种新的视角,并为实时分割领域提供了一种新的提升速度和性能的方法,不仅采用了Transformer的结构,还利用了其知识。
批量大小怎么确定?
pareto optimal

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)