认识一下ollvm的三种混淆(指令替换,虚假的控制流程,控制流平坦化)
描述这种混淆技术的目标只是将标准的二进制运算符(如加法、减法或布尔运算符)替换为功能等效但更复杂的指令序列。当有多个等效的指令序列可用时,随机选择一个。这种混淆相当简单,并且不会增加很多安全性,因为可以通过重新优化生成的代码来轻松删除它。但是,如果伪随机生成器的种子具有不同的值,则指令替换会带来生成的二进制的多样性。目前,只有整数运算符可用,因为替换浮点值的运算符会带来舍入误差和不必要的数值不准确
一:先介绍一下ollvm
LLVM(Low Level Virtual Machine)是一个开源的编译器基础设施项目,旨在提供一个可重用的编译器和工具链框架。它最初由克里斯·拉特纳(Chris Lattner)于2000年开发,现已发展成为一个广泛使用的项目,支持多种编程语言和平台。下面对 LLVM 的笼统介绍,包括其架构、组件、功能和应用场景。大家先有个了解,后面会分开详细介绍。
关键点1:
OLLVM 使用的就是 LLVM IR 来处理源代码,它能够获取到程序的结构和控制流信息,通过对这些信息的处理增强代码混淆的效果。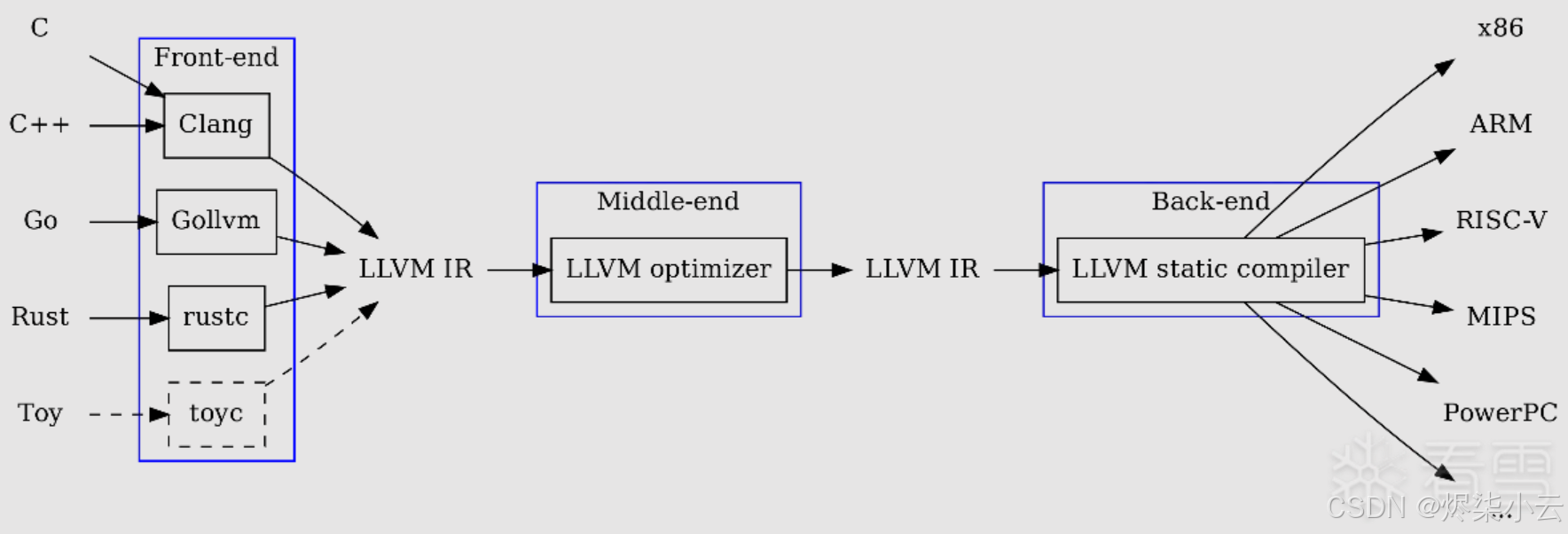
1.1. LLVM 的架构
LLVM 的架构主要由以下几个部分组成:
- 前端(Frontend): 负责将源代码转换为中间表示(IR)。LLVM 支持多种语言的前端,包括 C、C++、Rust、Swift 等。每种语言都有自己的前端,将源代码解析为 LLVM IR。
- 中间表示(Intermediate Representation, IR): LLVM 使用一种类型安全的中间表示,通常称为 LLVM IR。它是一种低级的、类似于汇编语言的表示,具有平台无关性。LLVM IR 可以在不同的硬件架构上进行优化和生成目标代码。
- 优化器(Optimizer): LLVM 提供了一系列优化工具,可以对 LLVM IR 进行各种优化,包括循环优化、内联、死代码消除等。这些优化可以在编译时、链接时或运行时进行。
- 后端(Backend): 负责将优化后的 LLVM IR 转换为目标机器代码。LLVM 支持多种目标架构,包括 x86、ARM、RISC-V 等。
- 工具链(Toolchain): LLVM 还提供了一些工具,如
clang(C/C++/Objective-C 编译器)、llc(将 LLVM IR 转换为机器代码的工具)、llvm-link(链接多个 LLVM IR 文件)等。
1.2. LLVM 的主要组件
- Clang: LLVM 的 C/C++/Objective-C 前端,提供高效的编译和丰富的错误信息。Clang 还支持 C++11、C++14、C++17 等现代 C++ 特性。
- LLVM IR: 一种中间表示,具有三种形式:文本形式(.ll 文件)、字节码形式(.bc 文件)和内存形式。LLVM IR 是一种强类型的、低级的表示,适合进行各种优化。
- LLVM Passes: 优化和分析的单元。LLVM 提供了多种预定义的 Pass,可以用于不同的优化任务。用户也可以自定义 Pass。
- Linker: LLVM 提供了
llvm-link工具,用于链接多个 LLVM IR 文件。 - Debugger: LLVM 支持调试信息的生成,可以与 GDB 等调试器集成。
1.3. LLVM 的功能
- 跨平台支持: LLVM 支持多种硬件架构和操作系统,使得编译器可以生成针对不同平台的代码。
- 优化能力: LLVM 提供了丰富的优化功能,可以在编译时、链接时和运行时进行优化,提升程序性能。
- 可扩展性: LLVM 的设计允许用户添加新的语言前端、优化 Pass 和后端,具有很好的可扩展性。
- 工具链集成: LLVM 可以与其他工具(如调试器、分析工具)集成,形成完整的开发工具链。
1.4. 应用场景
- 编译器开发: LLVM 被广泛用于开发新的编程语言和编译器,许多现代语言(如 Rust、Swift)都基于 LLVM。
- 代码分析: LLVM 提供了强大的分析工具,可以用于静态分析、性能分析等。
- 动态编译: LLVM 可以用于 JIT(即时编译)编译器,支持动态生成和执行代码。
- 教育和研究: LLVM 是编译原理和计算机体系结构课程中的重要工具,广泛用于学术研究。
目前github公开的ollvm已经停更,版本停留在4.0,下面是项目链接,大家感兴趣的话阔以自己配置到电脑上,我们这里先跳过配置这部分,主要讲解怎么用和部分原理。
功能 ·obfuscator-llvm/obfuscator 维基 (github.com)
以下是当前可用的不同功能的列表:
关键点2:
LLVM IR有两种文件格式.ll和.bc,.ll 文件和 .bc 文件都是 LLVM 中间表示的不同表示形式,.ll 文件是文本形式的可读表示,方便分析和调试;.bc 文件是二进制形式的紧凑表示,用于编译过程中的处理和优化,所以主要看.ll格式文件内容。
2.1LLVM IR 的结构
LLVM IR 由一系列指令组成,每条指令通常由操作符和操作数构成。以下是 LLVM IR 的基本结构:
- 模块(Module): LLVM IR 的顶层结构,包含全局变量、函数和其他模块级别的信息。
- 函数(Function): 由一系列基本块(Basic Block)组成,表示程序中的一个函数。
- 基本块(Basic Block): 一组顺序执行的指令,基本块以标签开始,最后以控制流指令(如
br)结束。 - 指令(Instruction): LLVM IR 的基本操作单位,包括算术运算、逻辑运算、内存操作等。
2.2.LLVM IR 的类型
LLVM IR 支持多种数据类型,包括:
- 标量类型:
iN:N 位整数(如i32表示 32 位整数)。float:单精度浮点数。double:双精度浮点数。
- 复合类型:
- 数组:如
[N x i32]表示包含 N 个 32 位整数的数组。 - 结构体:如
{ i32, float }表示包含一个 32 位整数和一个浮点数的结构体。 - 指针:如
i32*表示指向 32 位整数的指针。
- 数组:如
- 函数类型: 表示函数的参数类型和返回类型,如
i32 (i32, i32)表示接受两个 32 位整数并返回一个 32 位整数的函数。
2.3LLVM IR 的优化
LLVM IR 允许进行多种优化,主要包括:
- 局部优化: 在单个基本块内进行的优化,如常量折叠、死代码消除等。
- 全局优化: 跨多个基本块和函数进行的优化,如内联、循环优化等。
- 目标特定优化: 针对特定目标架构的优化,如寄存器分配、指令选择等。
LLVM 提供了多种预定义的优化 Pass,用户也可以自定义 Pass 以满足特定需求。
再介绍一些IR相关的概念(简化)
1.Pass是用于处理IR的关键组成部分,LLVM中自带的Pass主要是lib/Transforms中的.cpp文件
2.IR结构,Module->Function->Basic Block->Instruction,这些是IR的不同层次结构从左到右是一对多的包含关系,而且从命名来看也比较好理解,Module对应.c文件内的整个源码,Function就是函数,Basic Block是基本块,每个基本块以一个终止指令(例如 ret、br 等)结尾,或者以一个无条件分支(如 br 指令)指向其他基本块,Instruction就是指令了,看一个ll文件内容:
define dso_local i32 @main(i32 %argc, i8** %argv) #0 函数 {
...
first: ; preds = %loopEnd
%.reload = load volatile i32, i32* %.reg2mem 指令
%cmp = icmp eq i32 %.reload, 2
%1 = select i1 %cmp, i32 769163483, i32 -1060808858
store i32 %1, i32* %switchVar
br label %loopEnd
first就是一个名为first的基本块以br结尾
if.then: S ; preds = %loopEnd2
%2 = load i8*, i8** %str, align 8
%3 = load i8*, i8** @globalString, align 8
%call = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([13 x i8], [13 x i8]* @.str.5, i64 0, i64 0), i8* %2, i8* %3)
store i32 -1907967449, i32* %switchVar
br label %loopEnd2
if.else: ; preds = %loopEnd
%4 = load i32, i32* %argc.addr, align 4
%cmp1 = icmp eq i32 %4, 3
%5 = select i1 %cmp1, i32 1950105811, i32 1575411630
store i32 %5, i32* %switchVar
br label %loopEnd
...
}
二:指令替换,虚假的控制流程,控制流平坦化介绍
1.指令替换-mllvm -sub
描述
这种混淆技术的目标只是将标准的二进制运算符(如加法、减法或布尔运算符)替换为功能等效但更复杂的指令序列。当有多个等效的指令序列可用时,随机选择一个。
这种混淆相当简单,并且不会增加很多安全性,因为可以通过重新优化生成的代码来轻松删除它。但是,如果伪随机生成器的种子具有不同的值,则指令替换会带来生成的二进制的多样性。
目前,只有整数运算符可用,因为替换浮点值的运算符会带来舍入误差和不必要的数值不准确。
可用的编译器选项
-
mllvm -sub:激活指令替换
-
mllvm -sub_loop=3:如果通道已激活,则将其应用于函数 3 次。默认值 : 1.
实施的技术
目前,有以下替代品可供选择:
- 加法
a = b - (-c)
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 0, %1
%3 = sub nsw i32 %0, %2
a = -(-b + (-c))
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 0, %0
%3 = sub i32 0, %1
%4 = add i32 %2, %3
%5 = sub nsw i32 0, %4
r = rand (); a = b + r; a = a + c; a = a - r
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = add i32 %0, 1107414009
%3 = add i32 %2, %1
%4 = sub nsw i32 %3, 1107414009
r = rand (); a = b - r; a = a + b; a = a + r
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 %0, 1108523271
%3 = add i32 %2, %1
%4 = add nsw i32 %3, 1108523271
- 减法
a = b + (-c)
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 0, %1
%3 = add nsw i32 %0, %2
r = rand (); a = b + r; a = a - c; a = a - r
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = add i32 %0, 1571022666
%3 = sub i32 %2, %1
%4 = sub nsw i32 %3, 1571022666
r = rand (); a = b - r; a = a - c; a = a + r
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 %0, 1057193181
%3 = sub i32 %2, %1
%4 = add nsw i32 %3, 1057193181
- 和
a = b & c=>a = (b ^ ~c) & b
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = xor i32 %1, -1
%3 = xor i32 %0, %2
%4 = and i32 %3, %0
- 或
a = b | c=>a = (b & c) | (b ^ c)
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = and i32 %0, %1
%3 = xor i32 %0, %1
%4 = or i32 %2, %3
- 异或
a = a ^ b=>a = (~a & b) | (a & ~b)
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = xor i32 %0, -1
%3 = and i32 %1, %2
%4 = xor i32 %1, -1
%5 = and i32 %0, %4
%6 = or i32 %3, %5
2.虚假的控制流程-mllvm -bcf
描述
该方法通过在当前 basic 块之前添加 basic 块来修改函数调用图。这个新的 basic 块包含一个不透明的谓词,然后有条件地跳转到原始的 basic 块。
原始的基本块也被克隆并填充了随机选择的垃圾指令。
可用的编译器选项
-
mllvm -bcf:激活 Bogus Control Flow Pass
-
mllvm -bcf_loop=3:如果通道已激活,则将其应用于函数 3 次。默认值:1
-
mllvm -bcf_prob=40:如果激活了通行证,则基本块将以 40% 的概率进行混淆。默认值:30
实施的技术
下面是一个示例:以下 C 代码片段
#include <stdlib.h>
int main(int argc, char** argv) {
int a = atoi(argv[1]);
if(a == 0)
return 1;
else
return 10;
return 0;
}
转换为以下中间表示形式: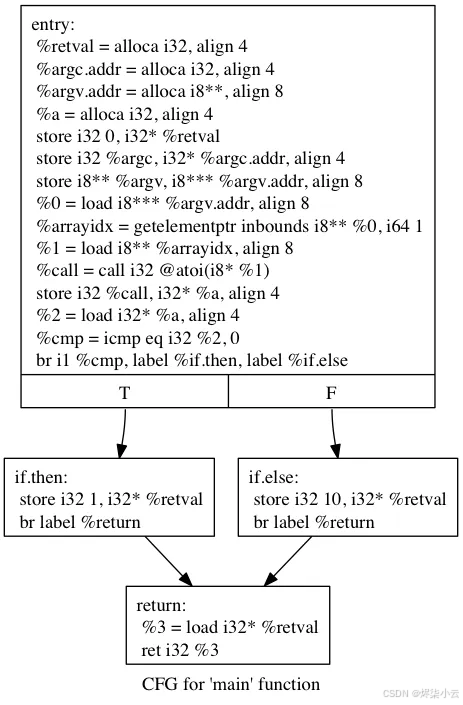
在伪造的 controlflow 传递之后,我们可能会得到以程图: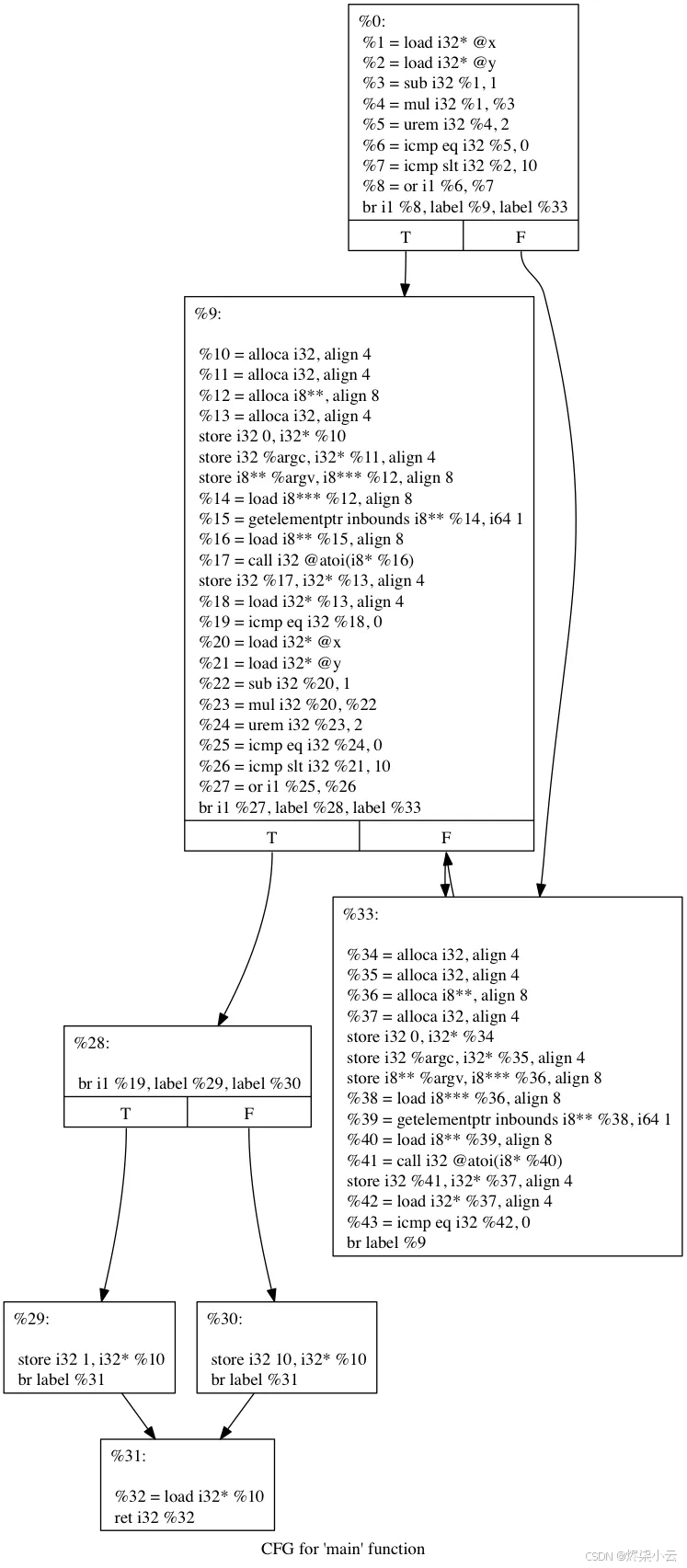
3.控制流平坦化 -mllvm -fla
描述
此通道的目的是完全展平程序的控制流图。
有关控制流展平技术的详细说明,请参见 T László 和 Á Kiss 的论文,通过控制流展平化混淆 C++ 程序,布达佩斯大学科学年鉴,Sect.Comp. 30 (2009) 3-19。
但请注意,我们的算法完全扁平化了控制流,而 László 和 Kiss 的情况并非如此。
可用的编译器选项
-
mllvm -fla:激活控制流展平
-
mllvm -split:激活基本块拆分。一起应用时改善拼合效果。
-
mllvm -split_num=3:如果通行证已激活,则在每个基本块上应用 3 次。默认值:1
实施的技术
下面是一个示例。考虑这个非常简单的 C 程序:
#include <stdlib.h>
int main(int argc, char** argv) {
int a = atoi(argv[1]);
if(a == 0)
return 1;
else
return 10;
return 0;
}
展平过程会将此代码转换为以下代码:
#include <stdlib.h>
int main(int argc, char** argv) {
int a = atoi(argv[1]);
int b = 0;
while(1) {
switch(b) {
case 0:
if(a == 0)
b = 1;
else
b = 2;
break;
case 1:
return 1;
case 2:
return 10;
default:
break;
}
}
return 0;
}
如您所见,所有基本块都被拆分并放入无限循环中,并且 程序流由 a 和变量 控制。switchb
下面是 flattenizing 之前生成的 control flow 的样子:
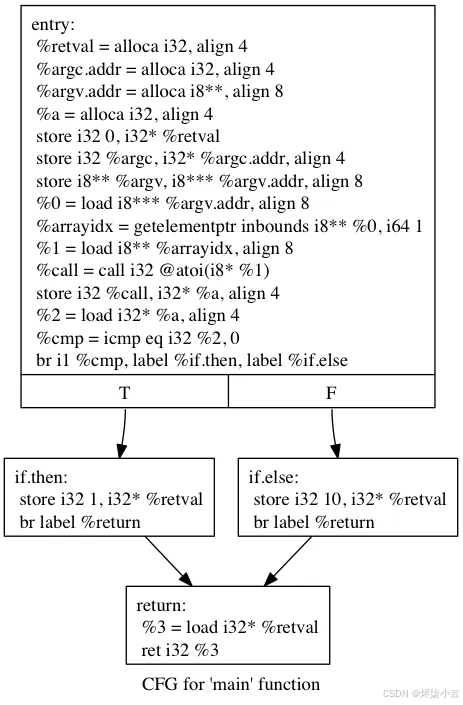
扁平化后,我们得到以下指令流: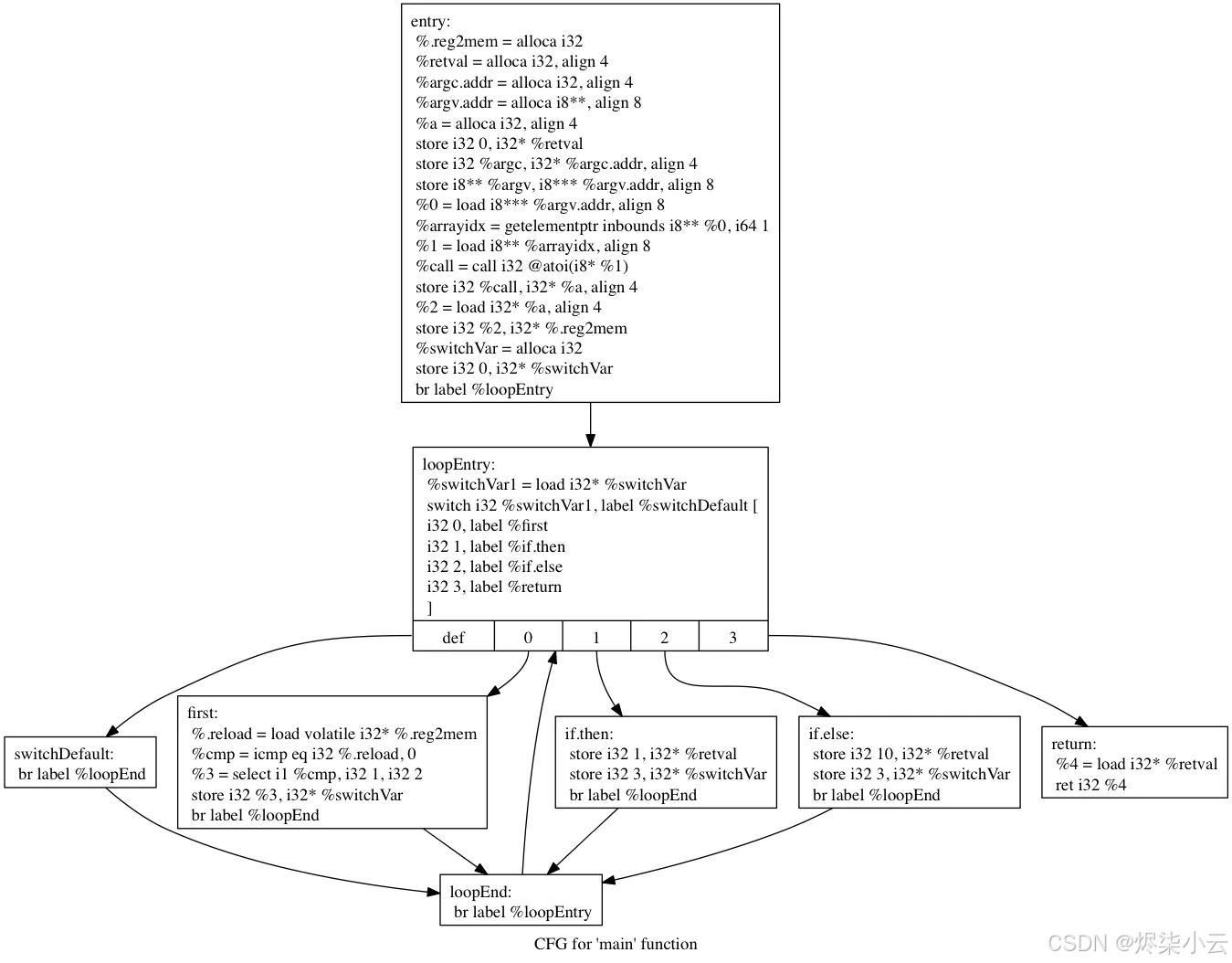
如您所见,纯 C 语言中示例之间的主要区别是 IR 版本完全展平。
控制流平坦化的实现原理:
bool Flattening::runOnFunction(Function &F) {
Function *tmp = &F;
// Do we obfuscate
// if (toObfuscate(flag, tmp, "fla")) {
if (flatten(tmp)) {
++Flattened;
}
// }
return false;
}
首先运行的是runOnFunction,主要调用了faltten函数
vector<BasicBlock *> origBB;
BasicBlock *loopEntry;
BasicBlock *loopEnd;
LoadInst *load;
SwitchInst *switchI;
AllocaInst *switchVar;
// SCRAMBLER
char scrambling_key[16];
llvm::cryptoutils->get_bytes(scrambling_key, 16);
// END OF SCRAMBLER
// Lower switch
FunctionPass *lower = createLowerSwitchPass();
lower->runOnFunction(*f);
这一段代码用于生成加密所需的密钥,并运行 LowerSwitch 函数,以优化 Switch 语句。LowerSwitch 函数将 Switch 语句转换为更基础的控制流结构,例如一系列条件分支或跳转指令。简而言之,它通过改变逻辑结构使代码的执行结果变得更加复杂。这是 LLVM 自带的一个 Pass,属于代码混淆的一种形式。
// Save all original BB
for (Function::iterator i = f->begin(); i != f->end(); ++i) {
BasicBlock *tmp = &*i;
origBB.push_back(tmp);
BasicBlock *bb = &*i;
if (isa<InvokeInst>(bb->getTerminator())) {
return false;
}
}
// Nothing to flatten
if (origBB.size() <= 1) {
return false;
}
// Remove first BB
origBB.erase(origBB.begin());
// Get a pointer on the first BB
Function::iterator tmp = f->begin(); //++tmp;
BasicBlock *insert = &*tmp;
// If main begin with an if
BranchInst *br = NULL;
if (isa<BranchInst>(insert->getTerminator())) {
br = cast<BranchInst>(insert->getTerminator());
}
if ((br != NULL && br->isConditional()) ||
insert->getTerminator()->getNumSuccessors() > 1) {
BasicBlock::iterator i = insert->end();
--i;
// 指令多大于一可能还有cmp指令所以要和跳转指令一起分割
if (insert->size() > 1) {
--i;
}
BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");
origBB.insert(origBB.begin(), tmpBB);
}
// Remove jump 移除掉splitBasicBlock函数分割后第一个块跳转到frist块的指令。
insert->getTerminator()->eraseFromParent();
这一段代码的主要目的是保存所有原始代码块的副本,以便在原始代码块被修改时方便取用。接下来,将原始代码块中的第一个入口代码块与后续代码分割开。这样做的目的是为了入 loopEntry 这个用于分发的代码块。然后,通过 loopEntry 将其与后面的代码块连接起来,并将入口块中的跳转指令独立分割成一个名为 first 的块,加入到 loopEntry 的分发中。
具体来说,entry 作为入口代码块被平坦化后,将设置 switchVar 为与 first 对应的 switchVar。随后,通过 first 进入第二个代码块,这样就无法直接看出在正常逻辑中,entry 之后应执行的真实代码块是哪个。
// Create switch variable and set as it 创建switchVar变量并设置一个随机生成的值
switchVar =
new AllocaInst(Type::getInt32Ty(f->getContext()), 0, "switchVar", insert);
new StoreInst(
ConstantInt::get(Type::getInt32Ty(f->getContext()),
llvm::cryptoutils->scramble32(0, scrambling_key)),
switchVar, insert);
// Create main loop 第三个参数是插入在哪个块之前
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar, "switchVar", loopEntry);
// Move first BB on top
insert->moveBefore(loopEntry);
BranchInst::Create(loopEntry, insert);
// loopEnd jump to loopEntry
BranchInst::Create(loopEntry, loopEnd);
BasicBlock *swDefault =
BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
// Create switch instruction itself and set condition
switchI = SwitchInst::Create(&*f->begin(), swDefault, 0, loopEntry);
switchI->setCondition(load);
// Remove branch jump from 1st BB and make a jump to the while
f->begin()->getTerminator()->eraseFromParent();
BranchInst::Create(loopEntry, &*f->begin());
// Put all BB in the switch
for (vector<BasicBlock *>::iterator b = origBB.begin(); b != origBB.end();
++b) {
BasicBlock *i = *b;
ConstantInt *numCase = NULL;
// Move the BB inside the switch (only visual, no code logic)
i->moveBefore(loopEnd);
// Add case to switch
//llvm::cryptoutils->scramble32这个函数的第一个参数是加密字段,第二个是key,switchI->getNumCases的值是从0开始递增那这里生成的跳转条件就和llvm::cryptoutils->scramble32(0, scrambling_key)是一样的
numCase = cast<ConstantInt>(ConstantInt::get(
switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key)));
switchI->addCase(numCase,i);
}
这一段是用于生成loopEntry,loopEnd,switchDefault三个代码块,在loopEntry中添加一个switch语句,并以SwitchVar存储条件值,原始代码块通过赋值这个变量即可完成跳转,并遍历所有原始代码块,以switch结构中目前case的个数进行加密得到的数字作为case的条件,就是0,1,2,3…挨个加密所以不会出现重复的case条件,再把跳转原始基本块的条件加入到switch语句中。
// Recalculate switchVar 这里开始遍历所有块去除块中最后的br
for (vector<BasicBlock *>::iterator b = origBB.begin(); b != origBB.end();
++b) {
BasicBlock *i = *b;
ConstantInt *numCase = NULL;
// Ret BB
if (i->getTerminator()->getNumSuccessors() == 0) {
continue;
}
if (i->getTerminator()->getNumSuccessors() == 1) {//1个的类似if{} 判断是一个block条件为真后的代码是一个代码块
// Get successor and delete terminator
BasicBlock *succ = i->getTerminator()->getSuccessor(0);
i->getTerminator()->eraseFromParent();
// Get next case
numCase = switchI->findCaseDest(succ);
// If next case == default case (switchDefault)
if (numCase == NULL) {
numCase = cast<ConstantInt>(
ConstantInt::get(switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(
switchI->getNumCases() - 1, scrambling_key)));
}
// Update switchVar and jump to the end of loop
new StoreInst(numCase, load->getPointerOperand(), i);
BranchInst::Create(loopEnd, i);
continue;
}
// If it's a conditional jump
if (i->getTerminator()->getNumSuccessors() == 2) { //有两个的类似if(){}else{}
// Get next cases
ConstantInt *numCaseTrue =
switchI->findCaseDest(i->getTerminator()->getSuccessor(0));
ConstantInt *numCaseFalse =
switchI->findCaseDest(i->getTerminator()->getSuccessor(1));
// Check if next case == default case (switchDefault)
if (numCaseTrue == NULL) {
numCaseTrue = cast<ConstantInt>(
ConstantInt::get(switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(
switchI->getNumCases() - 1, scrambling_key)));
}
if (numCaseFalse == NULL) {
numCaseFalse = cast<ConstantInt>(
ConstantInt::get(switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(
switchI->getNumCases() - 1, scrambling_key)));
}
// Create a SelectInst
BranchInst *br = cast<BranchInst>(i->getTerminator());
SelectInst *sel =
SelectInst::Create(br->getCondition(), numCaseTrue, numCaseFalse, "",
i->getTerminator());
// Erase terminator
i->getTerminator()->eraseFromParent();
// Update switchVar and jump to the end of loop
new StoreInst(sel, load->getPointerOperand(), i);
BranchInst::Create(loopEnd, i);
continue;
}
}
fixStack(f);
return true;
最后这段代码完成收尾工作,之前已经把loopEntry中的switch跳转做好了,但是原始代码块的最后的跳转还是原来的逻辑,这一块还没有处理,主要做两点通过原来的跳转指令获取要跳转到的代码块,再通过switchI->findCaseDest获取到是对应哪个Case,把Case的条件赋值给switchVar,这里就可以移除原始跳转指令了,再添加一个跳转loopEnd的指令,loopEnd会跳转到loopEntry,这样进入Switch分发器了,最后修复PHI和堆栈,fixStack这一块和这次魔改没太大关系就不说了。
接下来开始实现之前说的两个改进,首先是不通过loopEntry分发loopEntry只作为入口,直接进入loopEnd,把分发流程做到loopEnd中,这里要做的是把switch生成到loopEnd中,然后把loopEnd跳转loopEntry的跳转指令删除掉,这样就可以实现loopEnd直接分发代码块。
LoadInst *load2 = new LoadInst(switchVar, "switchVar", loopEnd);
BasicBlock *swDefault =
BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
SwitchInst *switch2=SwitchInst::Create(load2, loopEnd2, 0, loopEnd);
//修改查找Case的switch为loopEnd里的switch
numCase = switch2->findCaseDest(succ)
生成的LR
loopEnd: ; preds = %for.end, %for.body, %if.else5, %if.else, %first, %loopEnd2, %switchDefault
%switchVar2 = load i32, i32* %switchVar
switch i32 %switchVar2, label %loopEnd2 [
i32 -256601636, label %first
i32 -1060808858, label %if.else
i32 1575411630, label %if.else5
i32 1213754259, label %for.body
i32 420055895, label %for.end
i32 -1907967449, label %if.end9
]
二是添加多个loopEnd,这里要改的部分比较多,因为不只一个分发块的情况下每个分发块的平分了所有代码块,这里就要保证当一个代码块进入了这个分发块的时候如果switchVar的条件值可以找到对应的Case,类似下图这样。
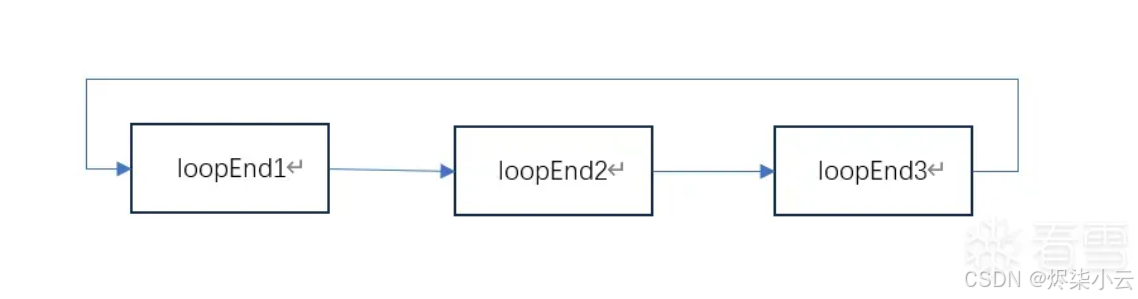
和只有一个分发块不同的就是要把switch的默认跳转设置成下一个loopEnd在最后一个loopEnd把默认跳转设置成第一个loopEnd,这次魔改我用了两个loopEnd,想多一点可以写成循环。
SwitchInst *switch2=SwitchInst::Create(load2, loopEnd2, 0, loopEnd);
SwitchInst *switch3=SwitchInst::Create(load3, loopEnd, 0, loopEnd2);
接下来是把所有代码块的跳转平分给两个loopEnd
int addCase_flag=1;
size_t count1=0;
for (vector<BasicBlock *>::iterator b = origBB.begin(); b != origBB.end();
++b,count1++) {
BasicBlock *i = *b;
ConstantInt *numCase = NULL;
// Move the BB inside the switch (only visual, no code logic)
i->moveBefore(loopEnd);
//change
if(addCase_flag==1){
// Add case to switch
numCase = cast<ConstantInt>(ConstantInt::get(
switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(count1, scrambling_key)));
switch2->addCase(numCase, i);
addCase_flag=0;
}
else{
// Add case to switch
numCase = cast<ConstantInt>(ConstantInt::get(
switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(count1, scrambling_key)));
switch3->addCase(numCase, i);
addCase_flag=1;
}
//change
// switch2->addCase(numCase, i);
}
以及最后去除原始代码块跳转添加判断跳转Case值的修改,这里用了一个判断,来判断这个分发块中是否包含了Case条件值没有就查找下一个分发块。
看下效果: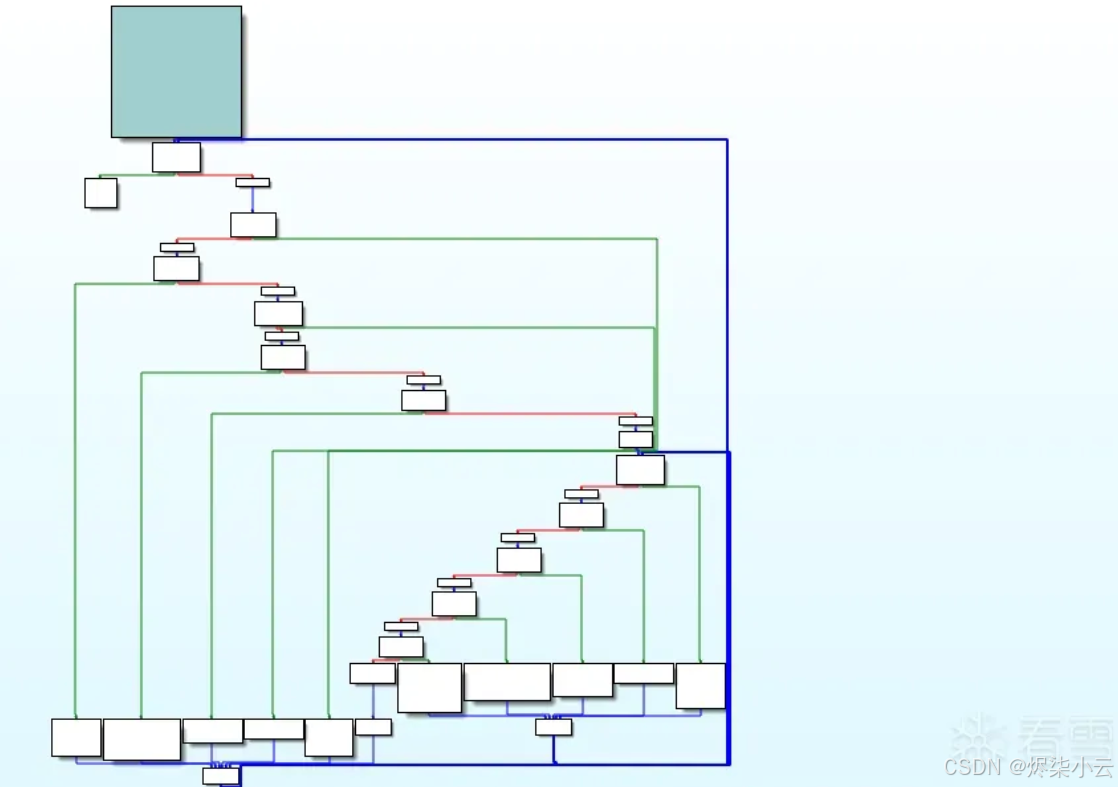
可以看到现在有两个loopEnd分发块且入度基本相同,并且由于是直接跳转到基本块,流程图里的两个loopEnd各会有一条不同的路径返回到不同的块,这样通过LoopEntry的前继也获取不到所有的loopEnd了。
不过对于OLLVM来说控制流平坦化只是其中的一环,配合OLLVM中的其他模块或一些的新型混淆Pass才能发挥最大的作用。
三:OLLVM混淆源码解读(借鉴大佬文章)
基础知识
IR(intermediate representation)是前端语言生成的中间代码表示,也是Pass操作的对象,它主要包含四个部分:
- Module:一个源代码文件被编译后生成的IR代码。
- Function:源代码文件中的函数。
- BasicBlock:BasicBlock有且仅有一个入口点和一个出口点。入口点是指BasicBlock的第一个指令,而出口点是指BasicBlock的最后一个指令。BasicBlock中的指令是连续执行的,没有分支或跳转指令直接将控制流传递到BasicBlock内部以外的位置。
- Instruction:指令。
它们之间的关系如下图所示: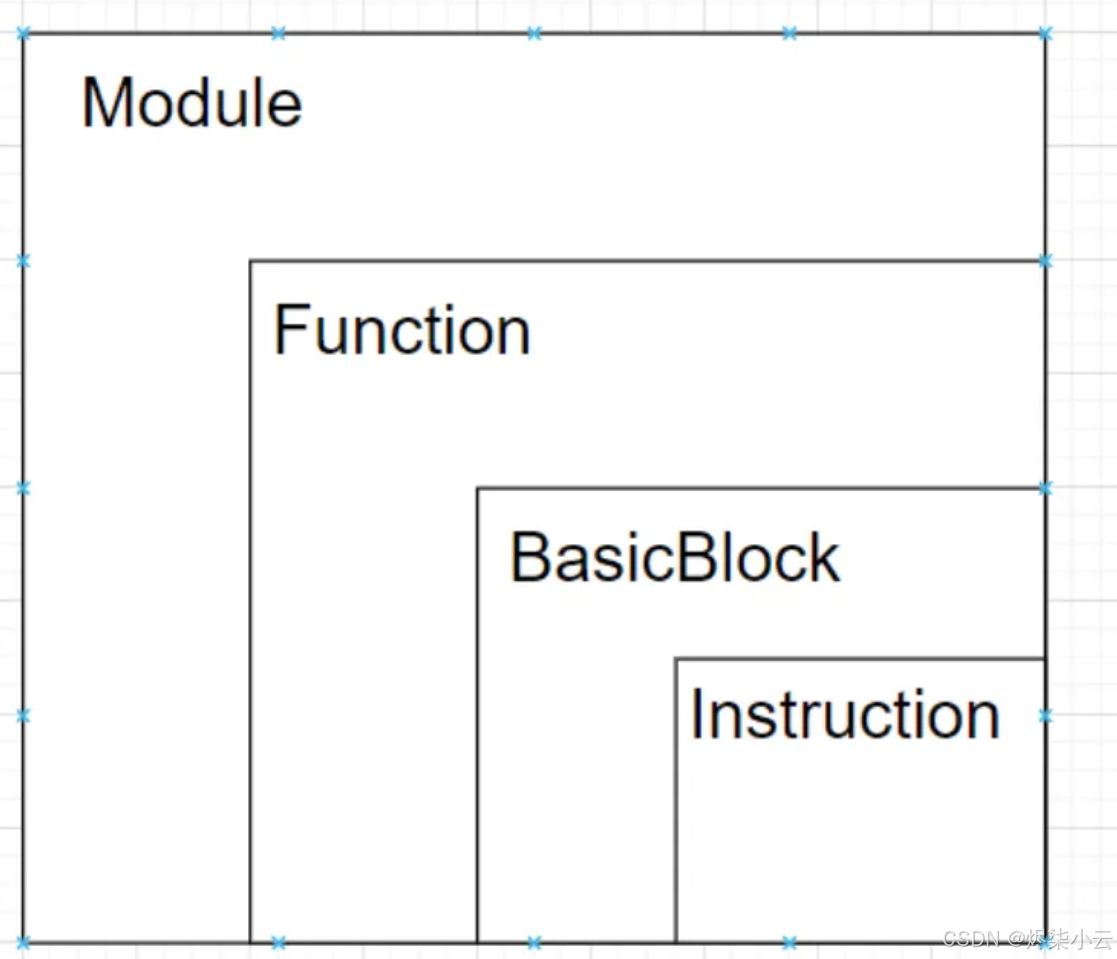
1.Substitution混淆源码解读
1.1 runOnFunction函数
bool Substitution::runOnFunction(Function &F) {
// 检查sub混淆次数
if (ObfTimes <= 0) {
errs()<<"Substitution application number -sub_loop=x must be x > 0";
return false;
}
Function *tmp = &F;
// 先通过toObfuscate函数检查是否需要进行混淆
if (toObfuscate(flag, tmp, "sub")) {
//混淆的具体操作
substitute(tmp);
return true;
}
return false;
}
检查是否能够进行Substitution混淆,混淆的具体操作主要通过调用substitute函数进行的。
1.2 substitute函数
bool Substitution::substitute(Function *f) {
Function *tmp = f;
// 混淆次数
int times = ObfTimes;
do {
// 遍历函数中的基本块
for (Function::iterator bb = tmp->begin(); bb != tmp->end(); ++bb) {
// 遍历基本块中的每条指令
for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst) {
// 判断指令是否是二进制运算
if (inst->isBinaryOp()) {
//获取指令的操作码进行case判断
switch (inst->getOpcode()) {
case BinaryOperator::Add:
// 随机选择add混淆中的一个方案
(this->*funcAdd[llvm::cryptoutils->get_range(NUMBER_ADD_SUBST)])(
cast<BinaryOperator>(inst));
++Add;
break;
case BinaryOperator::Sub:
// 随机选择sub混淆中的一个方案
(this->*funcSub[llvm::cryptoutils->get_range(NUMBER_SUB_SUBST)])(
cast<BinaryOperator>(inst));
++Sub;
break;
...
} // End switch
} // End isBinaryOp
} // End for basickblock
} // End for Function
} while (--times > 0); // for times
return false;
}
整个函数的功能主要是根据运算指令中的操作符进行相应的混淆操作,由于同一指令的混淆操作有很多种,因此通过llvm::cryptoutils->get_range获取随机数来指定某种混淆操作。
由于这些运算混淆都大同小异,所以接下来以一个例子来进行Substitution混淆的介绍。
1.3 addNeg混淆函数
// Implementation of a = b - (-c)
void Substitution::addNeg(BinaryOperator *bo) {
BinaryOperator *op = NULL;
// Create sub
if (bo->getOpcode() == Instruction::Add) {
//创建一个取反指令,生成bo指令中第二个操作数的负数,插入到bo指令的前面,返回创建的指令
op = BinaryOperator::CreateNeg(bo->getOperand(1), "", bo);
//创建一个sub指令,第一个操作数是bo指令中的第一个操作数,第二个操作数是刚才生成的op,然后插入到bo指令的前面,返回创建的指令
op = BinaryOperator::Create(Instruction::Sub, bo->getOperand(0), op, "", bo);
//用op指令来替换原来的bo指令
bo->replaceAllUsesWith(op);
}
}
主要是创建一个取反指令和一个整型减法指令来替换原有的指令。
一开始我不理解这些操作具体体现是什么,于是为了探究这些代码对IR进行了什么操作,因此在源码上进行打印调试,打印更改前后的IR。主要修改如下:
//打印基本块中的指令
void printBasicBlockInfo(BasicBlock* bb){
for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst){
inst->print(errs());
errs() << "\n";
}
}
void Substitution::addNeg(BinaryOperator *bo) {
BinaryOperator *op = NULL;
if (bo->getOpcode() == Instruction::Add) {
//新增
//current instruction
errs() << "current BinaryOperator:";
bo->print(errs());
errs() << "\n";
//get BasicBlock that current instruction located
BasicBlock* bb = bo->getParent();
//print Instruction in BasicBlock before CreateNeg
errs() << "BasicBlock before CreateNeg: " << "\n";
printBasicBlockInfo(bb);
op = BinaryOperator::CreateNeg(bo->getOperand(1), "", bo);
//新增
//print Instruction in BasicBlock after CreateNeg and before Create
errs() << "BasicBlock after CreateNeg and before Create: " << "\n";
printBasicBlockInfo(bb);
op = BinaryOperator::Create(Instruction::Sub, bo->getOperand(0), op, "", bo);
//新增
//print Instruction in BasicBlock after Create and before replaceAllUsesWith
errs() << "BasicBlock after Create and before replaceAllUsesWith: " << "\n";
printBasicBlockInfo(bb);
bo->replaceAllUsesWith(op);
//新增
//print Instruction in BasicBlock after replaceAllUsesWith
errs() << "BasicBlock after replaceAllUsesWith: " << "\n";
printBasicBlockInfo(bb);
}
}
打印结果如下:
current Function: main//混淆操作
current BinaryOperator: %7 = add nsw i32 %5, %6 //在substitute函数中被选中要进行sub混淆的指令
BasicBlock before CreateNeg:
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %3, align 4
store i32 2, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
%7 = add nsw i32 %5, %6
store i32 %7, i32* %2, align 4
ret i32 0
BasicBlock after CreateNeg and before Create:
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4 // a
store i32 1, i32* %3, align 4 // b
store i32 2, i32* %4, align 4 // c
%5 = load i32, i32* %3, align 4 // %5 = b
%6 = load i32, i32* %4, align 4 // %6 = c
%7 = sub i32 0, %6// CreateNeg新增指令,对源指令中第二个操作数(c)进行取反指令
%8 = add nsw i32 %5, %6 // 源指令,%7变成%8
store i32 %8, i32* %2, align 4 // %7变成%8
ret i32 0
BasicBlock after Create and before replaceAllUsesWith:
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %3, align 4
store i32 2, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
%7 = sub i32 0, %6 // CreateNeg新增指令
%8 = sub i32 %5, %7 // Create新增指令,源指令中第一个操作数(b)与CreateNeg新增指令的结果相加
%9 = add nsw i32 %5, %6 // 源指令, %8变成%9
store i32 %9, i32* %2, align 4 // %8变成%9
ret i32 0
BasicBlock after replaceAllUsesWith:
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %3, align 4
store i32 2, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
%7 = sub i32 0, %6
%8 = sub i32 %5, %7
%9 = add nsw i32 %5, %6
store i32 %8, i32* %2, align 4 // 这里发生更改,原本存储%9 (b+c),先在存储%8 (b-(-c))
ret i32 0
从结果上看,Create***等指令创建函数会影响后面的IR代码,即后续代码会进行相应的调整以保证IR代码的正确性,至于其具体过程,本篇博客不进行介绍。replaceAllUsesWith函数并不是真正的将源指令替换或删除,仅仅只是让后续IR代码中对源指令的结果的引用转变成对新指令的结果的引用,也就是说,源指令对后续的操作无任何作用,这样之后的优化应该会删除这种无效IR代码(如果指定了优化等级的话)。
至于其他的运算混淆,通过这个例子可以知其一而知其二。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 33
33 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)