JAVA加强02 ——集合框架-set集合、map集合、Stream流
特点:无序,不重复,无索引。无索引即没有get系列的方法public class setdemo1 {public static void main(String[] args) {//认识set家族集合的特点//1.创建一个set集合//set集合特点:无序,不重复,无索引Set<String> set = new HashSet<>();//经典代码set.add(&q
一.set框架
1.特点
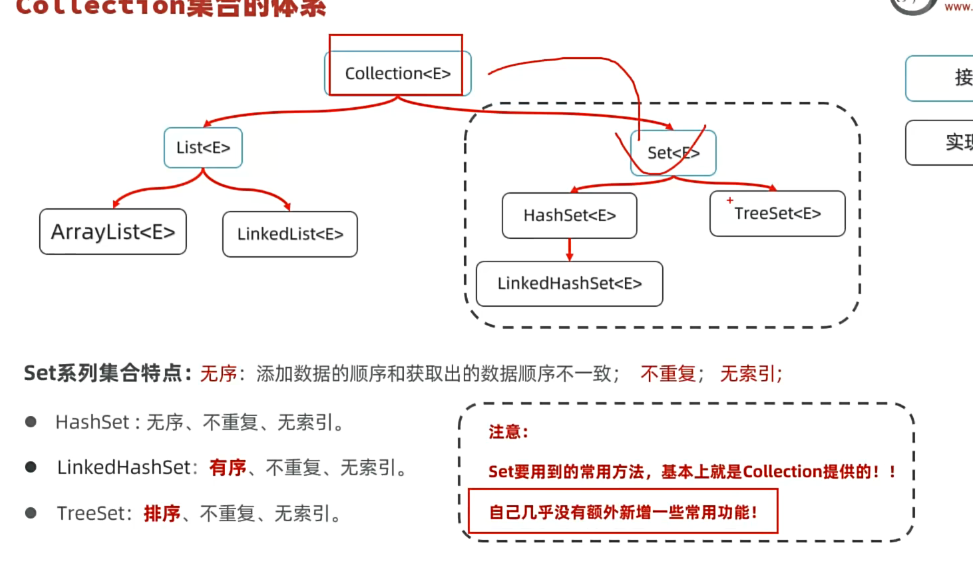
特点:无序,不重复,无索引。
无索引即没有get系列的方法
public class setdemo1 {
public static void main(String[] args) {
//认识set家族集合的特点
//1.创建一个set集合
//set集合特点:无序,不重复,无索引
Set<String> set = new HashSet<>();//经典代码
set.add("张三");
set.add("张三");
set.add("张三2");
set.add("张三3");
set.add("张三4");
System.out.println(set);
//[张三, 张三3, 张三4, 张三2]
}

如果是LinkedHanfSet:![]()
如果是Treeset:(默认一定要大小升序排序),不重复,无索引
//2,treeset:排序(默认一定要大小升序排序),不重复,无索引
Set<Double> set1 = new TreeSet<>();
set1.add(2.0);
set1.add(1.0);
set1.add(5.0);
set1.add(4.0);
set1.add(4.0);
System.out.println(set1);
}
}
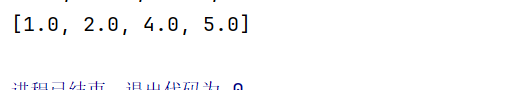
2.HashSet集合的底层原理
哈希值:就是一个int类型的随机值,java中每个对象都有一个哈希值。
java中所有对象,都可以调用object类提供的hashcode方法,返回该对象自己的哈希值。
对象哈希值的特点:
1.同一个对象多次调用hashcpde()方法返回的哈希值是相等的。
2.不同的对象,他们的哈希值大概率不相等,但也可能相等(哈希碰撞)。
哈希值相等的原因:int是有范围的(-21亿多~21亿多),只要对象够多就会出现重复
String s1 = "a";
String s2 = "b";
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());

为什么hashset集合中存储的数据是无序不重复无索引?
因为hashset集合是基于哈希表存储数据的。
jdk8之前:哈希表=数组+链表
在创建hashset集合对象的时候,第一次加数据会扩容,会在底层创建一个默认长度为16,默认加载因子为0.75,数组名为table的数组。
数据加载进数组时,会通过使用元素的哈希值对数组的长度做运算计算出应存入的位置。
判断当前位置是否为null.是的话直接存入
如果不为null,表示有元素,则调用equals方法比较,相等则不存,不相等则存入数组。
(jdk8之前:新元素存入数组,占老元素位置,老元素挂下面(形成;链表)
jdk8开始之后:新元素直接挂在老元素下面)

扩容机制:只要哈希表总长度为16*0.75=12就开始扩容,扩容为原先两倍,再将、重新将元素分配到新的哈希表。
jdk8开始,当链表长度超过8,且数组长度超过64时,自动将链表转成红黑树。
jdk8之后:哈希表=数组+链表+红黑树
红黑树: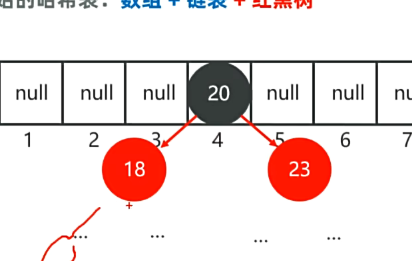
hashset集合底层原理之二叉查找树:
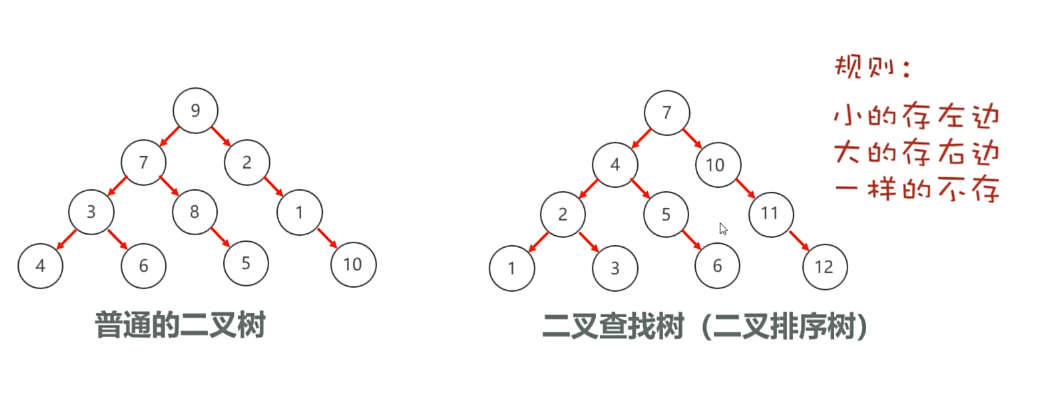
但二叉查找树存在问题:容易变成单链表
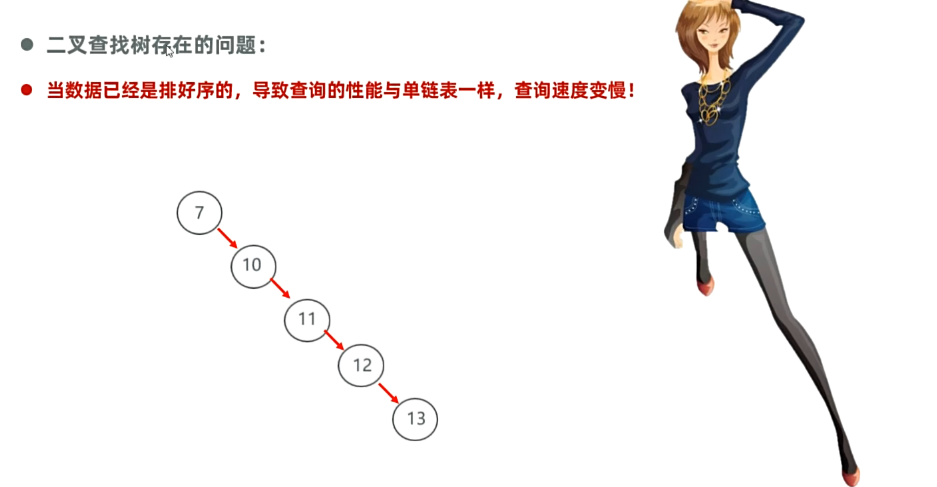
平衡二叉树: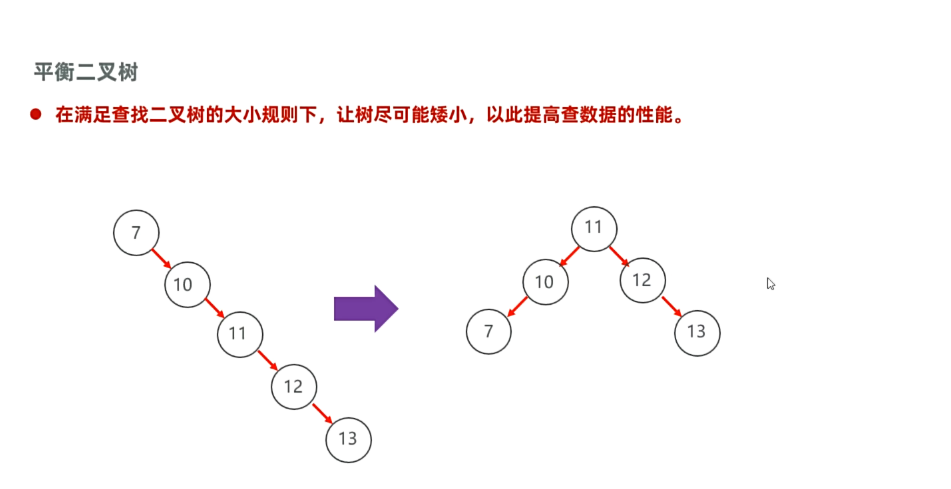
红黑树就是可以自平衡的二叉树:
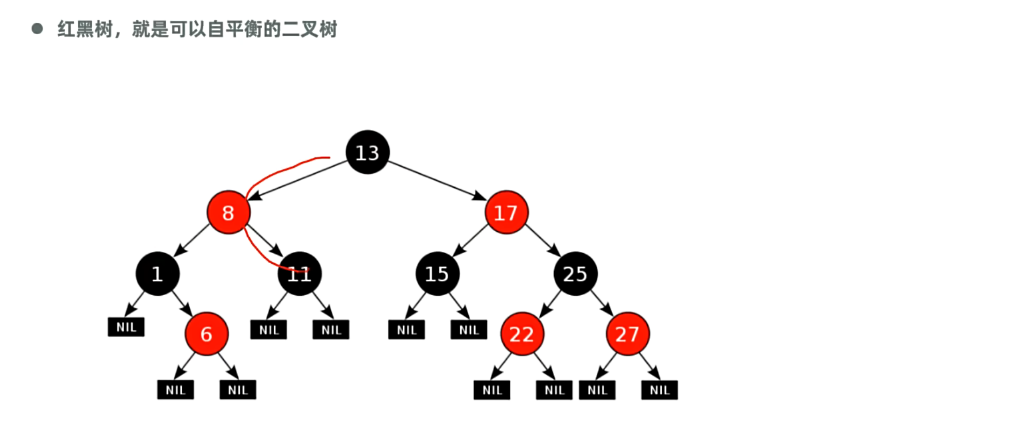
小数放左,大数放右
哈希表是一种增删改查数据,性能都较好的数据结构
3.Hashset集合元素的去重操作

public class student {
private String name;
private int age;
private String address;
private String phone;
@Override
public String toString() {
return "student{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", phone='" + phone + '\'' +
'}'+"\n";//重写方法显示出内容,“/n”为了让输出分行显得能看
}
}
public class setdemo2 {
public static void main(String[] args) {
//掌握hashset集合的去重操作
student s1 = new student("小王", 18, "北京", "123456");
student s2 = new student("小王3", 15, "点京", "122112");
student s3 = new student("小王", 18, "北京", "123456");
student s4 = new student("小王3", 15, "点京", "122112");
HashSet<student> hs = new HashSet<>();
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
System.out.println(hs);
} }
运行结果发现并未去重,因为这四个对象其实是不重复的!因为他们的哈希值其实并不一样
所以我应该做的就是定义内容一样的不同对象就是重复。所以必须重写hashcode()和rquals()方法
自动重写方法:在实体类中生成-equals and hashcode

//只要保证对象内容一样,结果一定是true
@Override
public boolean equals(Object o) {
if (this == o) return true;//这代码意思是自己与自己做对比
if (o == null || getClass() != o.getClass()) return false;
student student = (student) o;
return age == student.age && Objects.equals(name, student.name) && Objects.equals(address, student.address) && Objects.equals(phone, student.phone);
}
@Override
public int hashCode() {
//包装了不同学生对象,如果内容一样哈希值一定一样
return Objects.hash(name, age, address, phone);
}
运行结果:
4.linkhashset集合的底层原理
底层原理依然是基于哈希表(数组、链表、红黑树)实现的
但是它的每个元素都额外多一个双链表的机制记录它前后的位置。

5.treeset集合底层原理
底层是基于红黑树实现的:先加的元素作为根元素,再加的数据比根元素小放左边,大的放右边。
注意:对于数值类型:interger,double,默认按照数值本身大小进行升序排序。
对于字符串类型:默认按照首字母编号升序。
对于自定义类型,tessset默认是无法直接排序的。

自定义排序规则
Treeset集合存储自定义类型对象时,必须指定排序规则,支持以下两种方式;来指定比较规则。

如果正常排序,不指定规则则会报错。
public class Setdemo3 {
public static void main(String[] args) {
//搞清楚treeset集合对于自定义对象的排序
Set<teacher> set = new TreeSet<>();
set.add(new teacher("小王", 18, 3825.2));
set.add(new teacher("小达", 21, 6107.6 ));
set.add(new teacher("小伪", 28, 5825.2));
set.add(new teacher("小发", 18, 8140.2));
System.out.println( set);
}
}
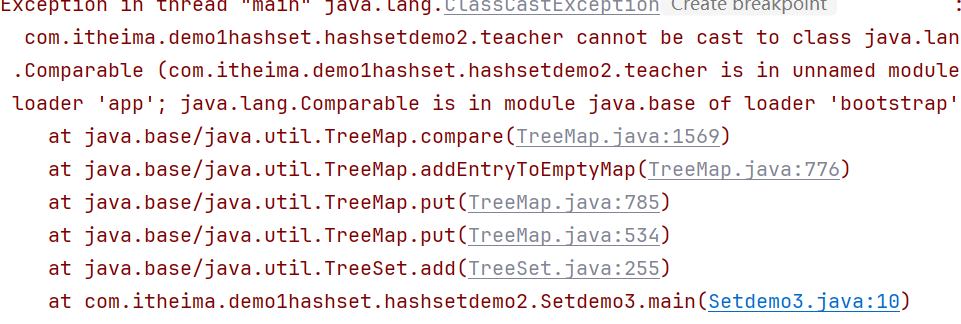
方案1:对象类实现一个comparable比较接口,重写compare方法,指定大小比较规则
public class teacher implements Comparable<teacher>{
private String name;
private int age;
private double salary;
@Override
public String toString() {
return "teacher{" +
"name='" + name + '\'' +
", age=" + age +
", salary=" + salary +
'}'+"\n";
}
//在这指定大小规则
//t2.compareTo(t1)
//t2 == this比较者
//t1 == o被比较者
//规定:如果你认为左边大于右边,请返回正整数,否则负整数,相等为0
@Override
public int compareTo(teacher o) {
//按照年龄升序
if(this.getAge()>o.getAge()) return 1;
if(this.getAge()<o.getAge()) return -1;
return 0;
}
}demo类不变
运行结果:
发现小发数据没有了,因为红黑树中数据相等会不存储
数据消失如何修改:将相等时返回值改为1,则可以得到相等数值。
@Override
public int compareTo(teacher o) {
//按照年龄升序
if(this.getAge()>o.getAge()) return 1;
if(this.getAge()<o.getAge()) return -1;
return 1;
}
}

但上面代码不够简洁,优化一下:
public int compareTo(teacher o) {
//按照年龄升序
if (this.getAge()==o.getAge()){
return 1; }
return this.getAge()-o.getAge();//降序就颠倒
}
}
方案2:public treeset(comparator c)集合自带比较器comparator对象,指定比较规则
也就是Set<teacher> set = new TreeSet<>();这行代码中,new TreeSet<>()中的()自带比较器
TreeSet源码中有这样一个构造器
public TreeSet(Comparator<? super E> comparator) {
//Comparator添加的比较器对象类型,加E或者E的父类
this(new TreeMap<>(comparator));
}
所以代码只在demo3中修改:
Set<teacher> set = new TreeSet<>(new Comparator<teacher>() {
@Override
public int compare(teacher o1, teacher o2) {//会两两两两的将对象进行大小比较
return o2.getAge()-o1.getAge();//在这指定规则,这样指定是降序
return 1;
}
});
如果使用薪水进行排序呢?这时会发现有一个问题,returno2.getdouble - o1.getdouble时出现的是小数不是整数,如果用int强转呢?理论可以但是不够精准可能出错,于是有了以下方法
如果用薪水不能这样,因为薪水是double,如果强转也不行,因为强转不够精准
if (o1.getSalary()>o2.getSalary()){
return 1;
}else if (o1.getSalary()==o2.getSalary()){
return -1;
}
return 0;
还有一个方法:调用api方法
return Double.compare(o1.getSalary(),o2.getSalary());//这是java包装好的方法: public //static int compare(double d1, double d2) {
//if (d1 < d2)
// return -1; // Neither val is NaN, thisVal is smaller
//if (d1 > d2)
// return 1;
使用Lambda表达式进行简化:
//Set<teacher> set = new TreeSet<>((o1, o2)->Double.compare(o1.getSalary(), o2.getSalary()))
完整demo3代码:
public class Setdemo3 {
public static void main(String[] args) {
//搞清楚treeset集合对于自定义对象的排序
Set<teacher> set = new TreeSet<>(new Comparator<teacher>() {
@Override
public int compare(teacher o1, teacher o2) {//会两两两两的将对象进行大小比较
return o2.getAge() - o1.getAge();//在这指定规则,这样指定是降序
}});
//Set<teacher> set = new TreeSet<>((o1, o2)->Double.compare(o1.getSalary(), o2.getSalary()))
set.add(new teacher("小王", 18, 3825.2));
set.add(new teacher("小达", 21, 6107.6 ));
set.add(new teacher("小伪", 28, 5825.2));
set.add(new teacher("小发", 18, 8140.2));
System.out.println( set);
//treeset集合默认不能给自定义对象进行排序。因为不知道大小规则
//有两种方案解决
//1.对象类实现一个comparable比较接口,重写compare方法,指定大小比较规则
//2.publictreeset(comparator c)集合自带比较器comparator对象,指定比较规则
}
}

二.Map集合
1.认识
1.1认识
map集合是双列集合
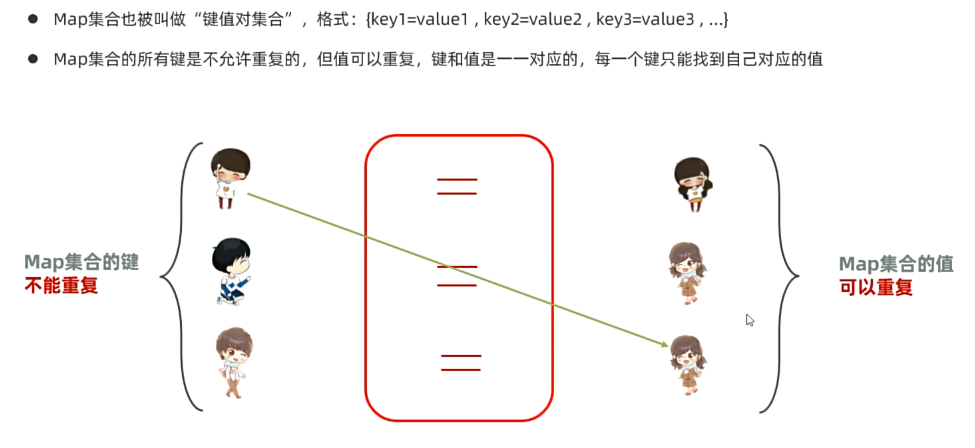
map集合也被称为“键值对集合”,格式:{key1=value1,key2=value2…}
map集合所有健是不允许重复的,但值可以重复,键和值是一一对应的,每一个健只能找到自己对应的值。
1.2在什么业务场景使用
需要存储一一对应的数据时,就可以考虑使用map集合
1.3map集合的体系
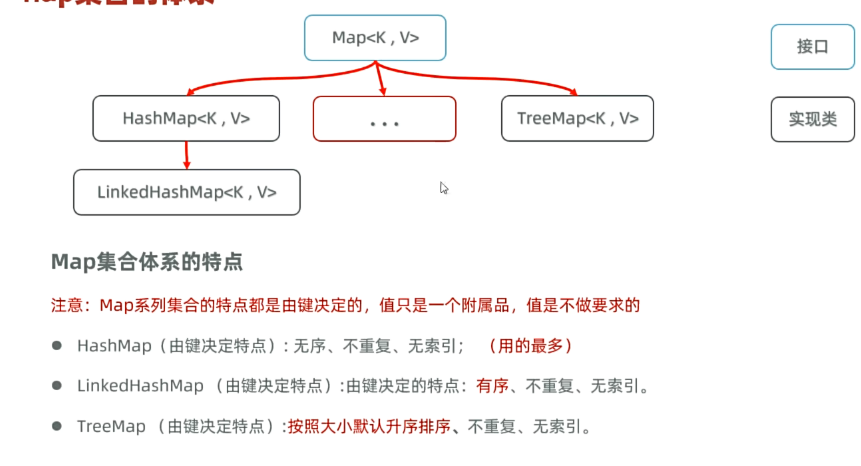
Map<K,V>
Map为根接口,K是声明键的类型,V是声明值的类型
1.4.特点
Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的。
HashMap:无序,不重复,无索引(用的最多)
LinkedHashMap:有序,不重复,无索引
TreeMap:按照大小默认升序排序,不重复,无索引
HashMap:
public class mapdemo1 {
public static void main(String[] args) {
//认识map集合的体系特点
//1,创建一个map集合
//hashmap特点:无序,不重复,无索引,键值对都可以是null,值不做要求(可以重复)
Map<String,Integer> map = new HashMap<>();//这是一行经典代码
//存数据
map.put("张三",18);
map.put("张四",18);//值重复没问题
map.put("张五",20);
map.put("张五",21);//发现张五的数字由20到21,只留下21,因为特点由键决定。重复的键会覆盖前面的数据
map.put("张六",21);
map.put("张七",null);
System.out.println( map);//{张四=18, 张三=18, 张六=21, 张七=null, 张五=21}
}
根据代码发现:值重复也没关系,键重复的话最新键的值会覆盖之前的值。
LinkedhashMap:有序,值可重复,键重复的话最新键的值会覆盖之前的值。
TreeMap:同上
2.Map集合的常用方式

public class mapdemo2 {
//掌握map集合常用方法
public static void main(String[] args) {
//1,创建一个map集合
Map<String,Integer> map = new HashMap<>();
//存数据
map.put("张三",18);//增加方法
map.put("张四",18);//值重复没问题
map.put("张五",20);
System.out.println(map.put("张五", 21));//输出为20,因为之前的张五键的值为20,put方法会返回值,即20
map.put("张六",21);
map.put("张七",null);
System.out.println( map);//{张四=18, 张三=18, 张六=21, 张七=null, 张五=21}
//LinkedHashMap:{张三=18, 张四=18, 张五=21, 张六=21, 张七=null}
//写代码演示常用方法
System.out.println(map.get("张三"));//根据键取值:18
System.out.println(map.get("张三2"));//没有键就没有值,取null
System.out.println(map.containsKey("张三"));//判断是否包含某个键:true
System.out.println(map.containsKey("张三2"));//判断是否包含某个键:false
System.out.println(map.containsValue(18));//判断是否包含某个值:true
System.out.println(map.containsValue(20.0));//判断是否包含某个值:false
System.out.println(map.remove("张四"));//根据键删除值对,返回值
System.out.println( map);//发现没有张四键
//map.clear();//清空
System.out.println(map.isEmpty());//判断是否为空: false
System.out.println(map.size());//获取元素个数: 4
//获取所有的键放到一个set集合返回
Set<String> keys = map.keySet();
System.out.println(keys);//[张三, 张四, 张五, 张六]
//获取所有的值放到一个集合返回
Collection<Integer> values = map.values();//因为值有可能重复,所以用collectio集合
for (Integer value : values){
System.out.println( value);
} }
}

3.map集合的遍历方式
3.1键找值
先获取Map集合全部的键,再通过遍历键来找值。

public class MapTraversedemo3 { public static void main(String[] args) { //掌握map集合遍历方式1:键找值 Map<String,Integer> map = new HashMap<>(); map.put("张三",18); map.put("张四",18); map.put("张四",22); map.put("张五",20); map.put("张六",21); System.out.println( map); //1.提取map集合的全部键到set集合中 Set<String> keys = map.keySet(); System.out.println( keys);//这一步用来看是不是获取全部的键,起保险作用不用写 //2.遍历set集合,得到每一个健 for(String key: keys){ //3.根据键去找值 Integer value = map.get(key); System.out.println(key+"="+value); } } }

3.2.键值对
把“键值对”看成一个整体进行遍历(难度较大)

将每一个数据当成一坨数据:正常说键是键,值是值,这里要想像“键=值”这才算一个数据。这样就可以用增强for遍历,但遇到一个问题:元素类型填什么?元素类型根本无法确定,所以要调用一个api进行转换。
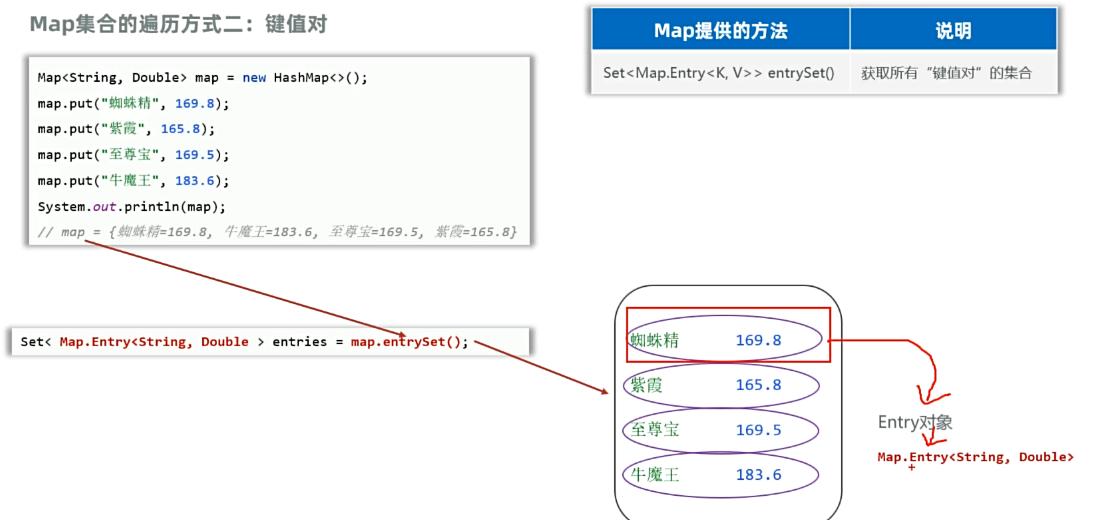
这个entryset()方法的底层会帮遍历这个map集合的每个数据,每遍历到一个数据会将数据的键和值封装成一个entry对象。
public class MapTraversedemo4 {
public static void main(String[] args) {
//掌握map集合遍历方式2:键值对
Map<String,Integer> map = new HashMap<>();
map.put("张三",18);
map.put("张四",18);
map.put("张四",22);
map.put("张五",20);
map.put("张六",21);
System.out.println( map);
//不能直接使用增强for
//1.把map集合转换成set集合,里面的元素都是键值对类型(Map.Entry<String,Integer>
/*
map = {张三=18,张四=22,张五=20,张六=21}
↓
map.entrySet()
↓
Set<Map.Entry<String,Integer>> entrys = [(张三=18),(张四=22),(张五=20),(张六=21)]
*/
Set< Map.Entry<String,Integer>> entrys = map.entrySet();
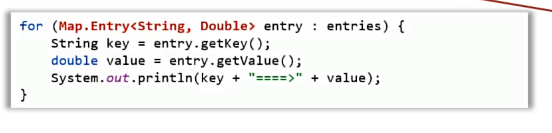
for (Map.Entry<String, Integer> entry : entrys) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + "=" + value);
}
}

3.3 Lambda

public class MapTraversedemo5 {
public static void main(String[] args) {
//掌握map集合遍历方式3:Lambda
Map<String,Integer> map = new HashMap<>();
map.put("张三",18);
map.put("张四",18);
map.put("张四",22);
map.put("张五",20);
map.put("张六",21);
System.out.println(map);
//1.直接调用Map集合的foreach 方法
// map.forEach(new BiConsumer<String, Integer>() {//这一步是创建一个匿名内部类,调用的接口名叫BiConsumer
// @Override
// public void accept(String key, Integer value) {
// System.out.println(key+"="+value);
// }
// });
//简化写法:
map.forEach((key,value)-> System.out.println(key+"="+value));
}
}
4.Map的实现类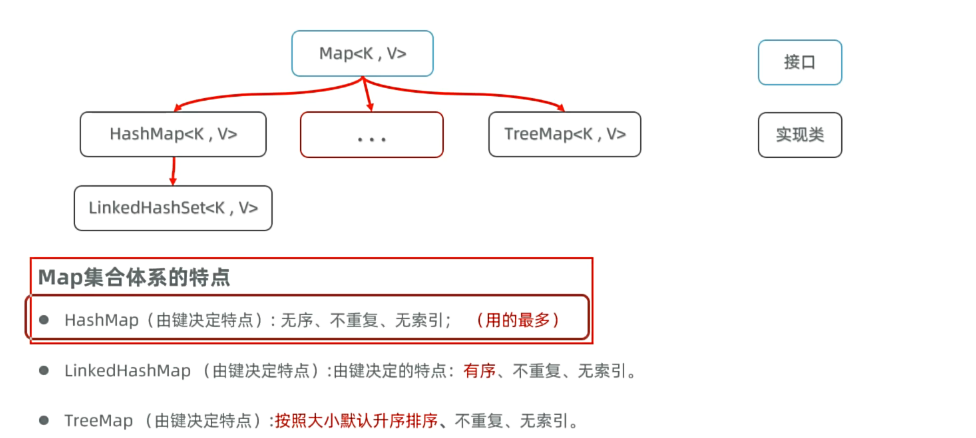
hashmap集合的底层原理:实际上原来学的set系列集合的底层就是基于map实现的,只是set集合中的元素只要键数据不要值数据而已。
hashMap原理和hashSet底层原理是一样的,都是基于哈希表实现。
LinkedHashMap底层原理:实际上学习的LinkedHsahSet集合底层原理就是LinkedHashMap.
底层数据结构依然是基于哈希表实现的,只是每个简直对元素额外多了一个双链表的机制记录元素顺序(保证有序)
Map综合案例-统计投票信息

分析:以终为始思考。假设B=40 A=23 C=7 D=10想去B的人最多,此时发现这几个不就是一个map集合,所以将技术定为map集合
将80个学生选择的数据存到程序中,【A,A,B,C,D……】
准备一个Map集合用于存储统计结果,Map<String,Interger>,键是景点,值代表投票数量
遍历80个学生选择的景点,每遍历一个经典,就看map集合中是否存在该景点,不存在“景点=1”(说明是第一次统计),存在则对应值加1
public class test {
public static void main(String[] args) {
//完成map集合案例,投票统计功能
calc();
}
public static void calc(){
//1.把80个学生选择的景点数据拿到程序中来,用一个集合试试
List<String> locations = new ArrayList<>();
String[] names ={"aaa","bbb","ccc","ddd"};
Random r = new Random();
for (int i=1;i<=80;i++){
int index = r.nextInt(names.length);//数组长度为4,返回的索引整数为0~3,不同的nextInt有不同的功能,这里随机生成数
locations.add(names[index]);//以上代码是每次随机一个索引然后加到集合中去
}
System.out.println( locations);
//2.统计的最终结构是一个键值对的形式,所以考虑一个map集合来统计
Map<String,Integer> map = new HashMap<>();
System.out.println( map);//这里一定是空的
//3.遍历集合,询问每一个景点,没有就写上去,有就加一
for (String location : locations) {
// //4.判断当前遍历的景点是否在map集合存在,如果不存在说明第一次出现,如果存在说明之前统计过。
// if(map.containsKey( location)){//这个代码是问当前map集合是否包含当前遍历的景点键
//map.put(location,map.get(location)+1);//这里是遍历到存在的,值加一,原理是因为因为键不可以重复。一旦重复值就会被覆盖,所以这里用get方法获取值,然后加一
// }else {
// map.put(location,1);//这里是遍历到不存在的,值写1
// }
//简化写法!!
map.put(location,map.containsValue( location)?map.get(location)+1:1)
}
//5.打印统计结果
map.forEach((k,v)-> System.out.println(k+"被选择了"+v+"次"));
}
}
三.Stream流
1.认识stream流
1.1认识
是jdk8开始新增的一套api(Java.util.stream*),可用于操作集合或者数组的数据。
其优势:Stream流大量结合了Lambda的语法风格来编程,功能强大,性能高效,代码简洁,可读性好。
1.2.体验Stream流

public class streamdemo1 {
public static void main(String[] args) {
//认识stream流,掌握其基本使用,体会优势
List<String> list =new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.add("张小四");
//1.先用传统方案找出姓张的人,名字为3字存到一个新集合
List<String> list2 = new ArrayList<>();
for (String name : list) {
if ((name.startsWith("张"))){// if ((name.startsWith("张")&&name.length()==3)一样的
if (name.length()==3){
list2.add(name);
}
}//startsWith()判断字符串开头是否满足条件
}
System.out.println(list2);
//2.用stream流实现
List<String> list3 = list.stream().filter(name -> name.startsWith("张")).filter(name->name.length()==3).collect(Collectors.toList());//理解为这是一个传送带,可以把这些集合中的数据全部扔进这个传送带,然后可以用传送带自带的功能对数据进行加工
//filter代表过滤,name -> name.startsWith("张")第一个name写参数叫什么都行,name.startsWith("张")这个是条件,collect(Collectors.toList())这个是收集到一个集合
System.out.println( list3);
}
}
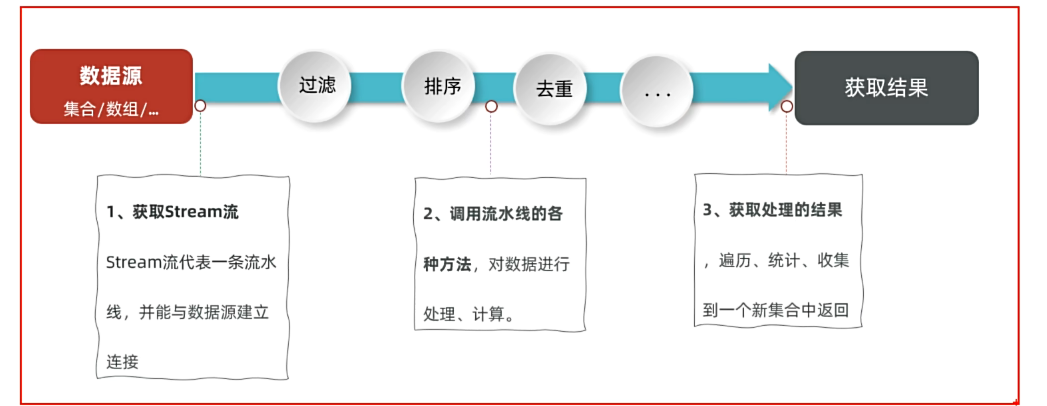
1.3Stream流的使用步骤
准备数据源(集合,数组……)
1.获取stream流
2.调用流水线各种方法t
3.获取出来结结果
2.获取Stream流
获取Stream流才能够用流操作数据。
2.1获取集合的Stream流
public interface Stream<T>…{ }
发现是接口不能直接构建对象,意味着会提供一些实现类对象而不是拿本身的对象。
而集合也不需要我们找它的实现类,而是集合已经封装了一个方法叫做stream方法,只需调用该方法,底层可以直接得到一个stream流的实现类对象。
public class streamdemo2 {
public static void main(String[] args) {
//获取 stream流的方式
//1.获取集合的Stream流。调用集合提供的stream方法
Collection<String> list = new ArrayList<>();
Stream<String> s1 = list.stream();//所有单列集合调用stream流都是用的这个方法,记得写collection
//如果是map集合呢
Map<String, Integer> map = new HashMap<>();
// map.stream();//报错,因为map集合不属于collection集合,是单独的一个体系
//还是有方法拿的,只需要拆开,获取键流
map.keySet();//这个方法是拿map集合的所有的键
Stream<String> s2 = map.keySet().stream();
//获取值流
Stream<Integer> s3 = map.values().stream();
//获取键值对流
Stream<Map.Entry<String, Integer>> s4 = map.entrySet().stream();// map.entrySet()将map集合转换成set集合
}
}
2.2获取数组的Stream流
Arrays提供的方法:public static <T> Stream(T[] array)
Stream提供的方法:public static<T> Stream<T>of(T…values)
其中T代表类型,是个泛型,…代表是个可变参数,是方法独有的参数,大概就是参数值可以不给,可以给多个,可以给一批,给数组也能接

//3.获取数组的Stream流
String[] name = {"张三","李四","张五","王六"};
Stream<String> s5 = Arrays.stream( name);
System.out.println(s5.count());//拿这个流中元素的个数
Stream<String> s6 = Stream.of(name);//数组的另一种写法
Stream<String> s7 = Stream.of("张三","李四","张五","王六");//of的另一种写法
3.Stream流提供的常用方法
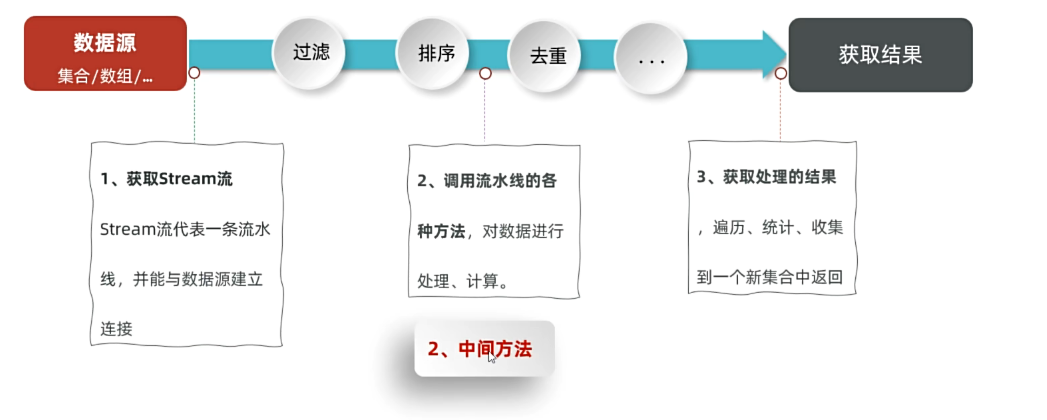
中间方法:当我们拿到这个stream流,可以理解为相当于拿到了流水线,它会把集合或者数组中的数据拷贝到这个流水线中让我们进行操作,所以我们要看流水线上有哪些方法对数据进行处理,这就叫做中间方法。过滤排序去重等都是。
以下是常用方法:
中间方法指的是调用完后会返回新的Stream流,可以继续使用


过滤方法: 用于从流中筛选出满足特定条件的元素,形成一个新的流。它的核心作用是「根据条件保留符合要求的元素,排除不符合的元素。
public class streamdemo3 {
public static void main(String[] args) {
//目标:掌握stream流常用的中间方法,对流上的数据进行处理(返回新流,支持链式编程)
List<String> list =new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.add("张小四");
//1.过滤方法
System.out.println("过滤方法");
list.stream().filter(name -> name.startsWith("张")&&name.length()==3).forEach(name -> System.out.println(name));
//2.排序方法
List<Double> scores = new ArrayList<>();
scores.add(99.9);
scores.add(66.6);
scores.add(77.7);
scores.add(77.7);
scores.add(88.8);
scores.add(88.8);
System.out.println("排序方法默认升序");
scores.stream().sorted().forEach(System.out::println);//默认升序
System.out.println( "==========");
//3.使用重载的方式降序
System.out.println("重载降序");
scores.stream().sorted((s1,s2) -> Double.compare(s2,s1)).forEach(System.out::println);
//4.降序完之后只要前两名:limit()获取前几个元素
System.out.println("降序完之后只要前两名");
scores.stream().sorted((s1,s2) -> Double.compare(s2,s1)).limit(2).forEach(System.out::println);
//5.跳过元素
System.out.println("跳过元素");
scores.stream().sorted((s1,s2) -> Double.compare(s2,s1)).skip(2).forEach(System.out::println);
//6.去重
System.out.println("去重");
scores.stream().sorted((s1,s2) -> Double.compare(s2,s1)).distinct().forEach(System.out::println);
//如果希望自定义对象能去重复,重写对象的equals()和hashCode()方法
//加工方法/映射方法:把流上原来的数据拿出来变成新数据又放入流上。
System.out.println("映射方法");
scores.stream().map(score->"加10分后"+(score+10)).forEach(System.out::println);
//合并流
System.out.println("合并流");
Stream<String> s1 = Stream.of("张三","张三","张三");
Stream<Integer> s2 = Stream.of(1,2,3,4,5);
Stream< Object> concat = Stream.concat(s1, s2);//一定是object,因为源码
System.out.println(concat.count());
}
}


4.终结方法、收集Stream流
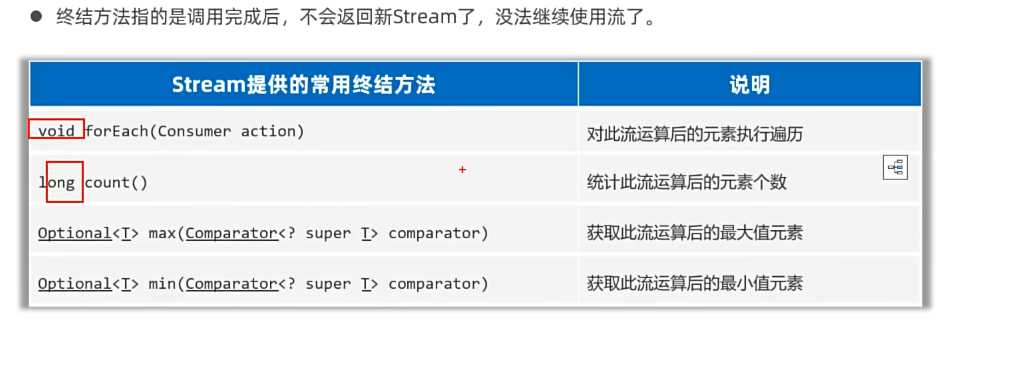
4.1终结方法
获取处理的结果,遍历,统计,收集到一个新集合中返回。
中介方法一旦调用完成后,不会返回新Stream了,没法继续使用流。
4.2收集Stream流
就是把stream流操作后的结果转回到集合或数组中去返回。

收集map流简化代码的过程:

public static void main(String[] args) {
//掌握stream流的收集操作(终结方法)
List<teacher> list = new ArrayList<>();
list.add(new teacher("张三", 18, 5000));
list.add(new teacher("lisi", 19, 6000));
list.add(new teacher("wangwu", 20, 7000));
list.add(new teacher("zhaoliu", 21, 8000));
list.add(new teacher("zhangqi", 22, 9000));
list.add(new teacher("zhangsan", 23, 10000));
//遍历stream流
//foreach就是一个终结方法,因为无法再调流
System.out.println("=====遍历stream流=====");
list.stream().filter(t->t.getSalary()>7000).forEach(System.out::println);
//统计个数,也是终结方法,因为统计出的是count而不是返回流
System.out.println("=====统计个数=====");
long count = list.stream().filter(t -> t.getSalary() > 7000).count();
System.out.println(count);
//max,min取最大最小。会把最值放在一个Optional对象中然后再提取
System.out.println("=====max取最大=====");
Optional<teacher> max = list.stream().max((t1, t2) -> Double.compare(t1.getSalary(), t2.getSalary()));
teacher maxteacher = max.get();//获取Optional对象中的值
System.out.println(maxteacher);
System.out.println("=====min取最小=====");
Optional<teacher> min = list.stream().min((t1, t2) -> Double.compare(t1.getSalary(), t2.getSalary()));
teacher mintacher = min.get();
System.out.println(mintacher);
System.out.println("--------------------------------------");
List<String> list2 =new ArrayList<>();
list2.add("张无忌");
list2.add("周芷若");
list2.add("赵敏");
list2.add("张强");
list2.add("张三丰");
list2.add("张小四");
System.out.println("=====将流中的数据收集到集合中=====");
//1.将流中的数据收集到集合中
Stream<String> s1 = list2.stream().filter(s -> s.startsWith("张"));
//2.收集到list集合
List<String> collect1 = s1.collect(Collectors.toList());
System.out.println(collect1);
//3.收集到set集合
System.out.println("=====将流中的数据收集到set集合正确做法=====");
Stream<String> s2 = list2.stream().filter(s -> s.startsWith("张"));//必须重新创建一个流
Set<String> collect2 = s2.collect(Collectors.toSet());
System.out.println(collect2);
// Set<String> collect2 = s1.collect(Collectors.toSet());
// System.out.println(collect2);//这里会报错
// Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
// at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)
// at java.base/java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:682)
// at com.itheima.demo3Stream.streamdemo4.main(streamdemo4.java:53)
//因为流只能收集一次,c1收集完了c2即无法收集,只能重新创建一个新流
//4.收集到数组
System.out.println("=====将流中的数据收集到数组中=====");
Stream<String> s3 = list2.stream().filter(s -> s.startsWith("张"));
Object[] array = s3.toArray();
System.out.println(Arrays.toString( array));
//5.收集到map集合
System.out.println("=====将流中的数据收集到map集合中=====");
Stream<teacher> sorted = list.stream().sorted((t1, t2) -> Double.compare(t1.getSalary(), t2.getSalary()));
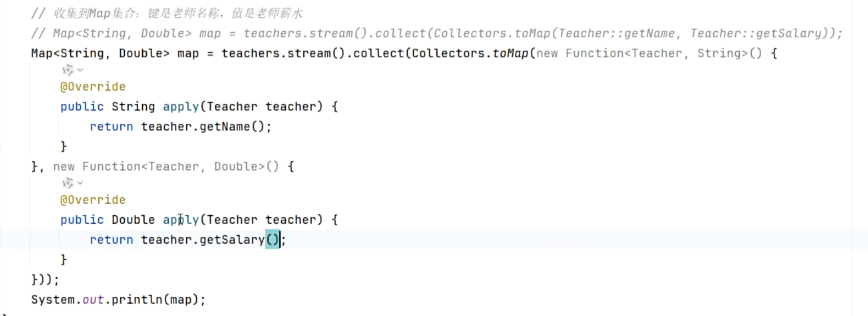
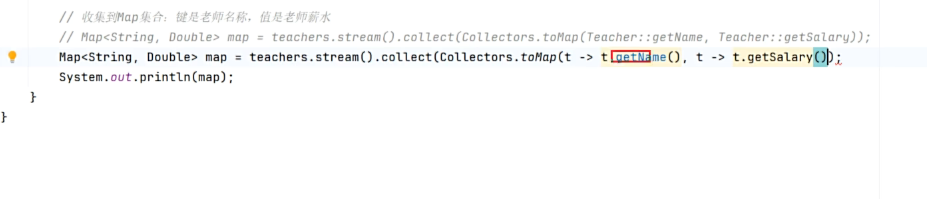
//收集到map集合,要求键是老师名称,值是薪水
Map<String,Double> map = list.stream().collect(Collectors.toMap(teacher::getName, teacher::getSalary));
System.out.println( map);
// Map<String,Double> map = list.stream().collect(Collectors.toMap(teacher::getName, teacher::getSalary));解释这代码
//list.stream().collect(Collectors.toMap这个代码中,调用了一个tomap的api,代表收集到map集合,但要注意不能直接写成toMap(),因为不知道()中要收集什么,因此括号内必须写要求
//toMap()方法中,第一个参数是键,第二个参数是值
}
}

综合案例
前置知识
1.方法中可变参数
就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:数据类型…参数名称
特点和好处
特点:可以不传数据给它;可以传一个或者同时传多个数据给它,也可以传一个数组给它。
好处:常用来灵活的接收数据。
对内来说,可变参数其实就是一个数组
public class paramdemo1 {
public static void main(String[] args) {
//认识可变参数
sum();//不传参数
sum(1);//传一个参数
sum(1,2,3,4,5,6,7,8,9,10);//传多个参数
sum(new int[]{11,22,33});//传一个数组
//优势:接收参数很灵活,可以代替数组传参
}
public static void sum(int...nums){
//内部怎么拿数据
//可变参数对内实际上就是一个数组
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("----------------");
}
}

注意:可变参数再形参列表中只能有一个,可变参数必须放在形参列表的最后面。
2.collections工具类
1.认识
collections是一个用来操作集合的工具类
2.常用静态方法

public class pramdemo2 {
public static void main(String[] args) {
//认识comllerctions工具类
List<String> list =new ArrayList<>();
// list.add("张无忌");
// list.add("周芷若");
// list.add("赵敏");
// list.add("张强");
// list.add("张三丰");
// list.add("张小四");
//collections的方法批量添加
Collections.addAll(list,"张小五","张小六","张小七");//pi批量添加,相当于简化上面代码
System.out.println( list);
//打乱顺序
Collections.shuffle(list);
System.out.println( list);
//排序
Collections.sort(list);
System.out.println( list);
}
}
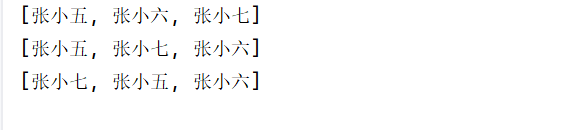
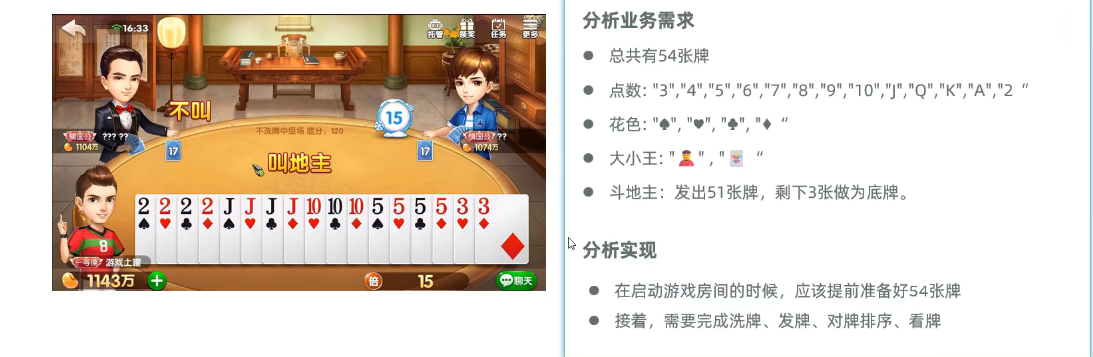
3.综合项目

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)