【分布式计算框架】hadoop全分布式及高可用搭建
【分布式计算框架】hadoop全分布式及高可用搭建
🕺作者: 主页
我的专栏 C语言从0到1 探秘C++ 数据结构从0到1 探秘Linux 😘欢迎 ❤️关注 👍点赞 🙌收藏 ✍️留言
文章目录
hadoop全分布式及高可用搭建
一、实验目的
- hadoop完全分布式搭建
- hadoop高可用搭建
二、实验环境
- ubuntu 6.5
- VMware Workstation
三、实验内容
hadoop全分布式搭建
一、准备工作:(前提:已配置好node01为伪分布式服务器)
(1)安装java

同理在2、3…号机安装java


…
(2)同步所有服务器时间
date
 date -s “2024-03-17 19:33:00” //所有会话
date -s “2024-03-17 19:33:00” //所有会话



…
(3)cat /etc/sysconfig/network //查看机器IP映射



…
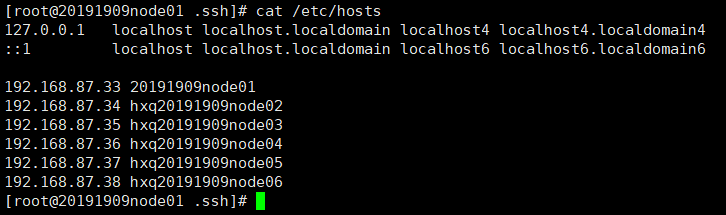
(4)cat /etc/hosts //所有所有机器别名
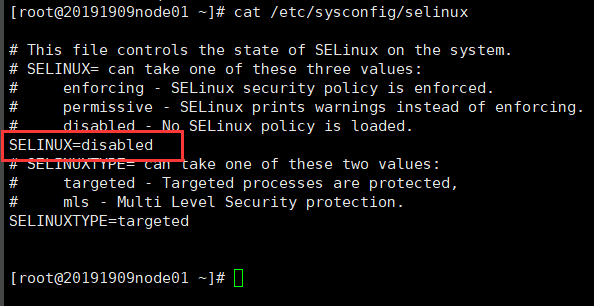
(5)cat /etc/sysconfig/selinux //selinux 关闭
(6)关闭防火墙
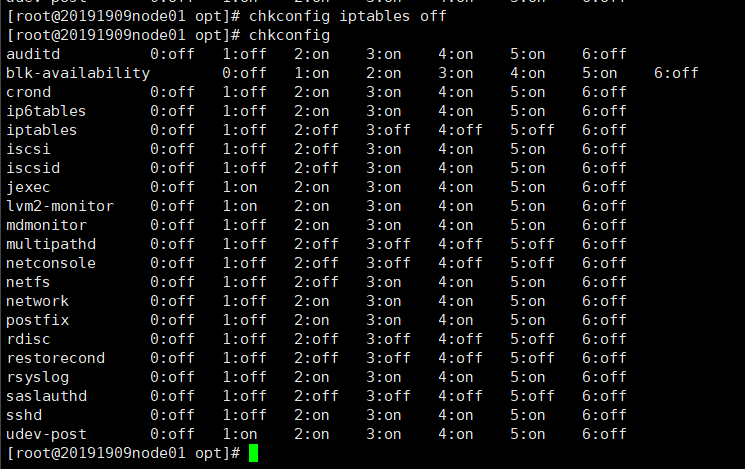
(7)ssh 免密钥 //管理节点分发密钥文件给其他节点
分发给node02:
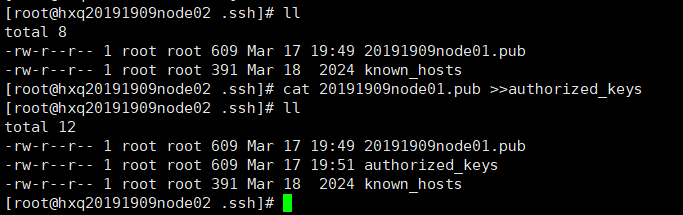
在node1上输入:scp id_dsa.pub hxq20191909node02:pwd/20191909node01.pub

在node02的.ssh目录下输入
cat 20191909node01.pub >>authorized_keys
以此类推
二、修改配置文件
在/opt/20191909/hadoop-2.6.5/etc/hadoop 目录下
备份hadoop
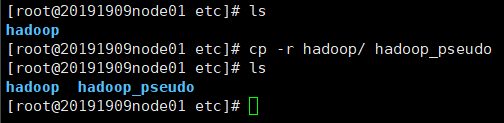
node02:
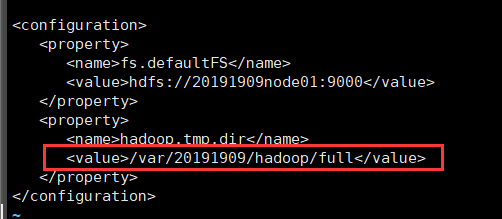
(1)core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node02:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/20191909/hadoop/full</value>
</property>
</configuration>
(2)hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hxq20191909node02:50090</value>
</property>
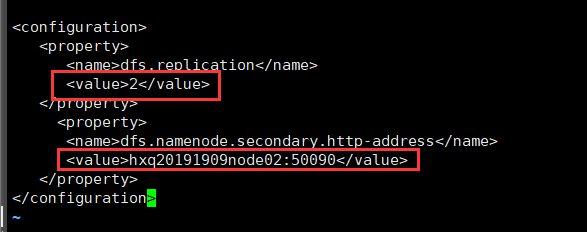
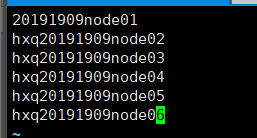
(3)slaves
node02
node03
node04
node05
node06
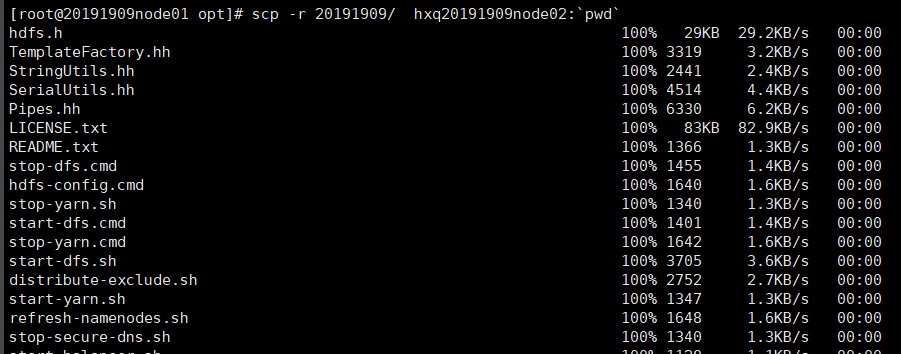
三、分发hadoop-2.6.5给其他节点
scp -r 20191909/ hxq20191909node02:`pwd`
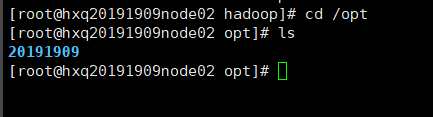
以此类推
四、分发环境变量给其他节点
scp /etc/profile hxq20191909node02:/etc/ #node1会话下
. /etc/profile #全部会话下
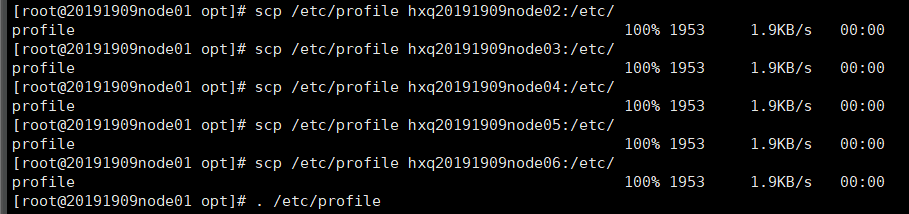
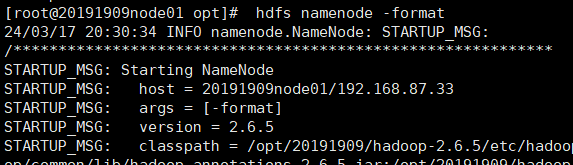
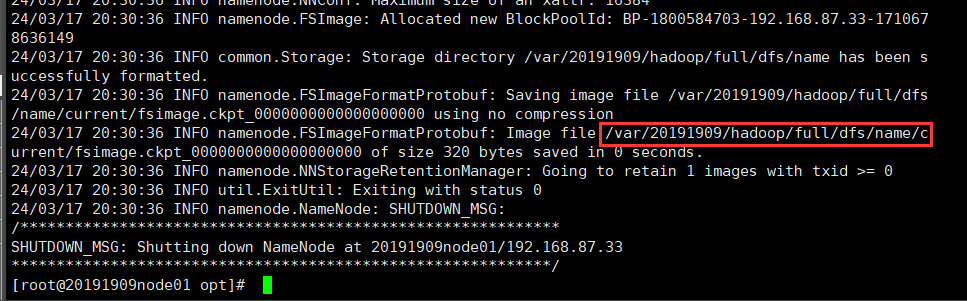
五、格式化
hdfs namenode -format
//ls /var/20191909/hadoop/full

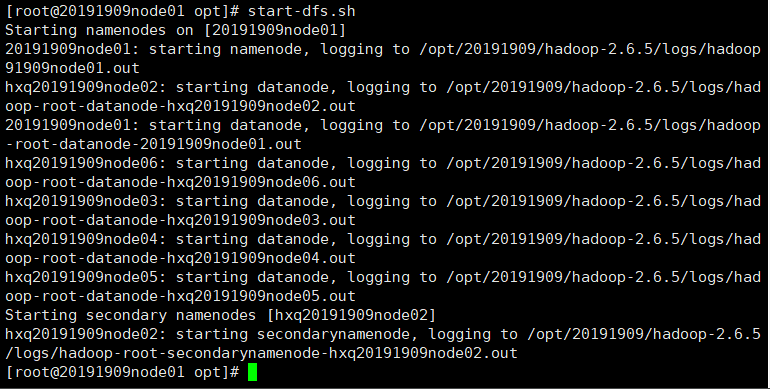
六、启动
start-dfs.sh
七、出现问题,看日志
ll /opt/20191909/hadoop-2.6.5/logs
tail -100 hadoop-root-datanode-20191909node01.log
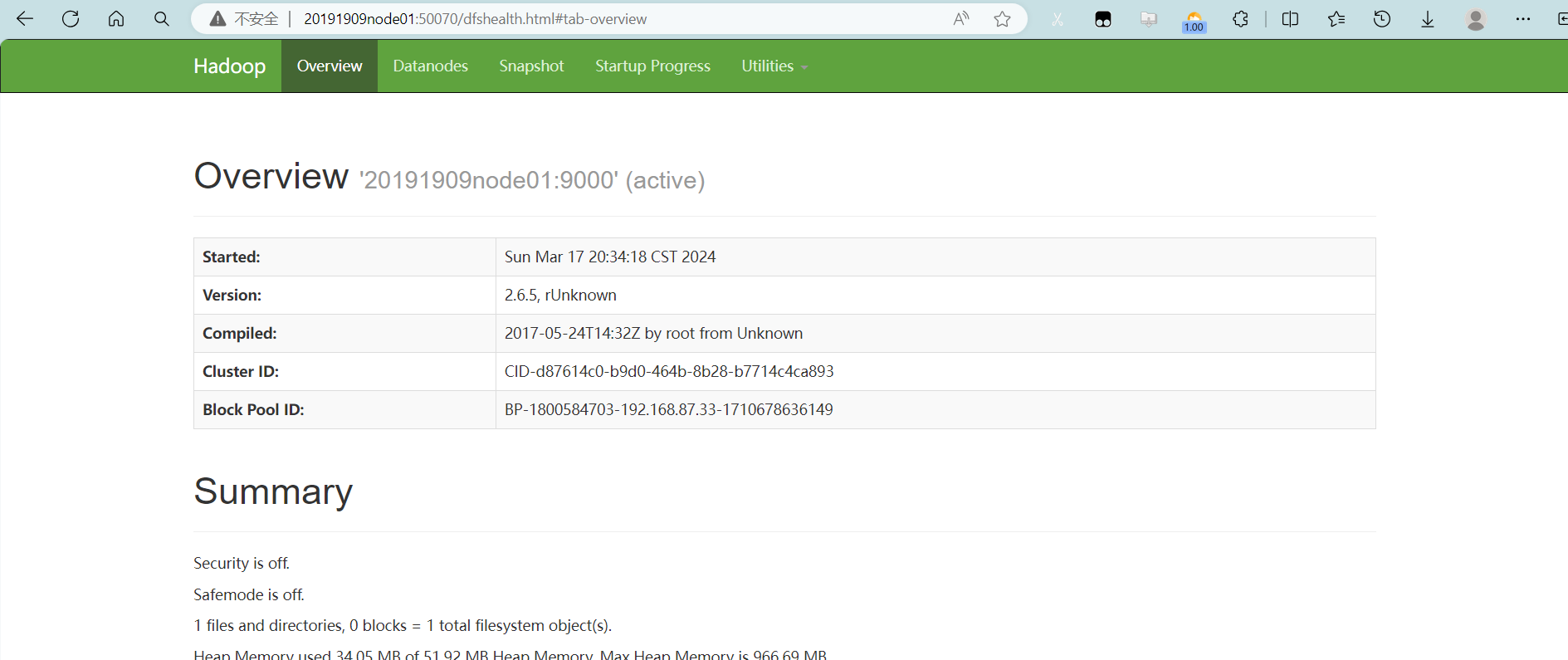
八、浏览器查看信息
20191909node01:50070
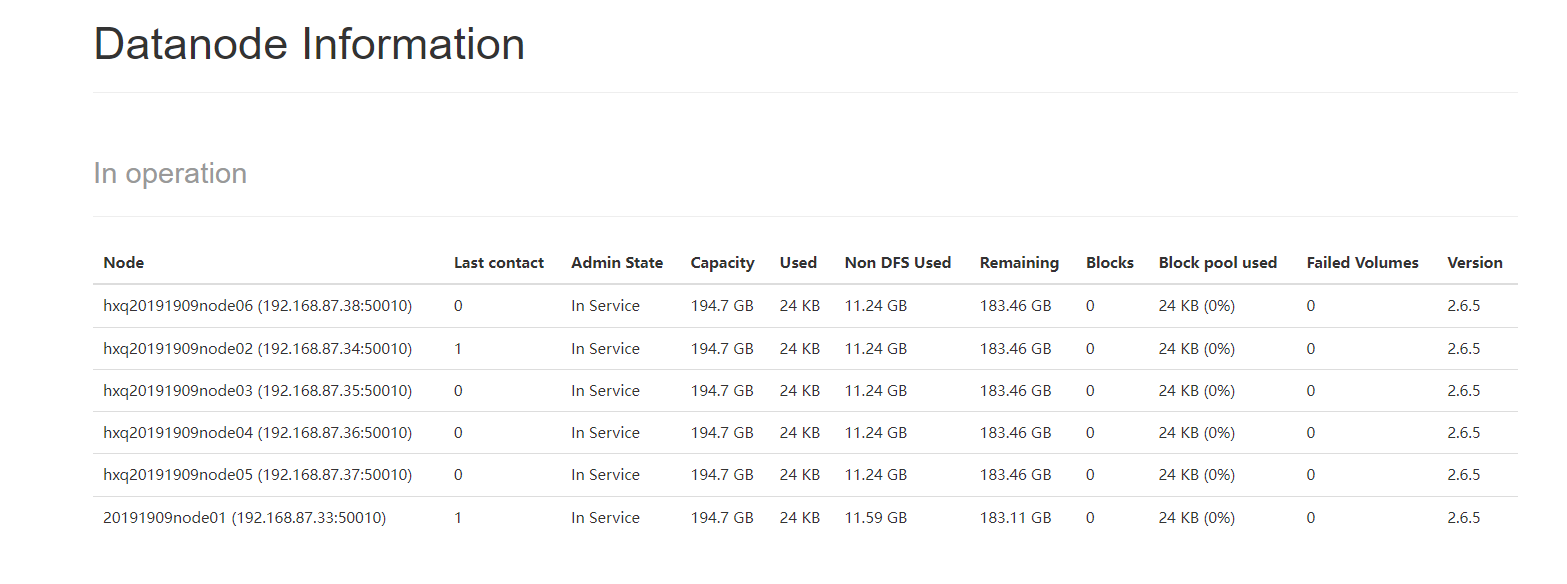
创建目录

浏览器上查看
九、练习上传文件
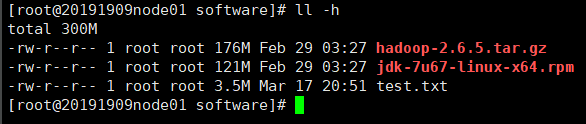
在~/software目录里创建一个新文件
for i in
seq 100000;do echo “hello 20191909$i” >> test.txt;done

查看新文件大小
ll -h //test.txt文件大小约为3.5M
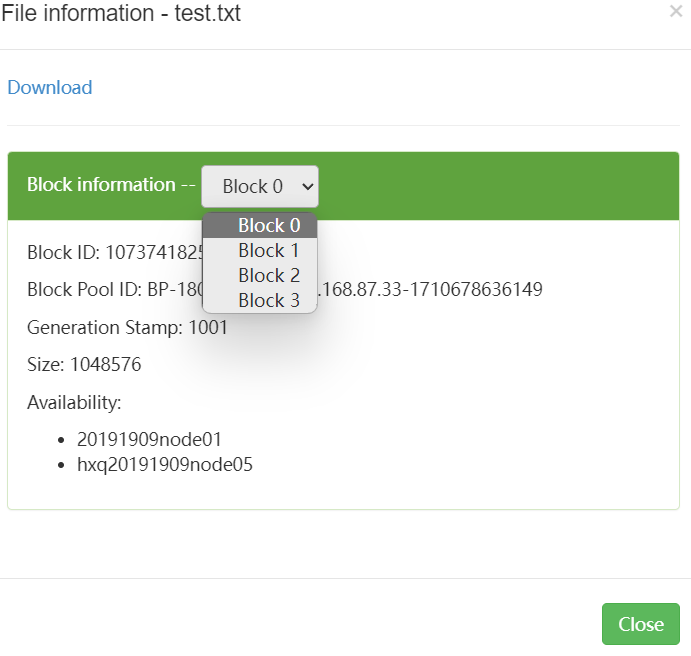
设置块大小上传文件
hdfs dfs -D dfs.blocksize=1048576 -put test.txt

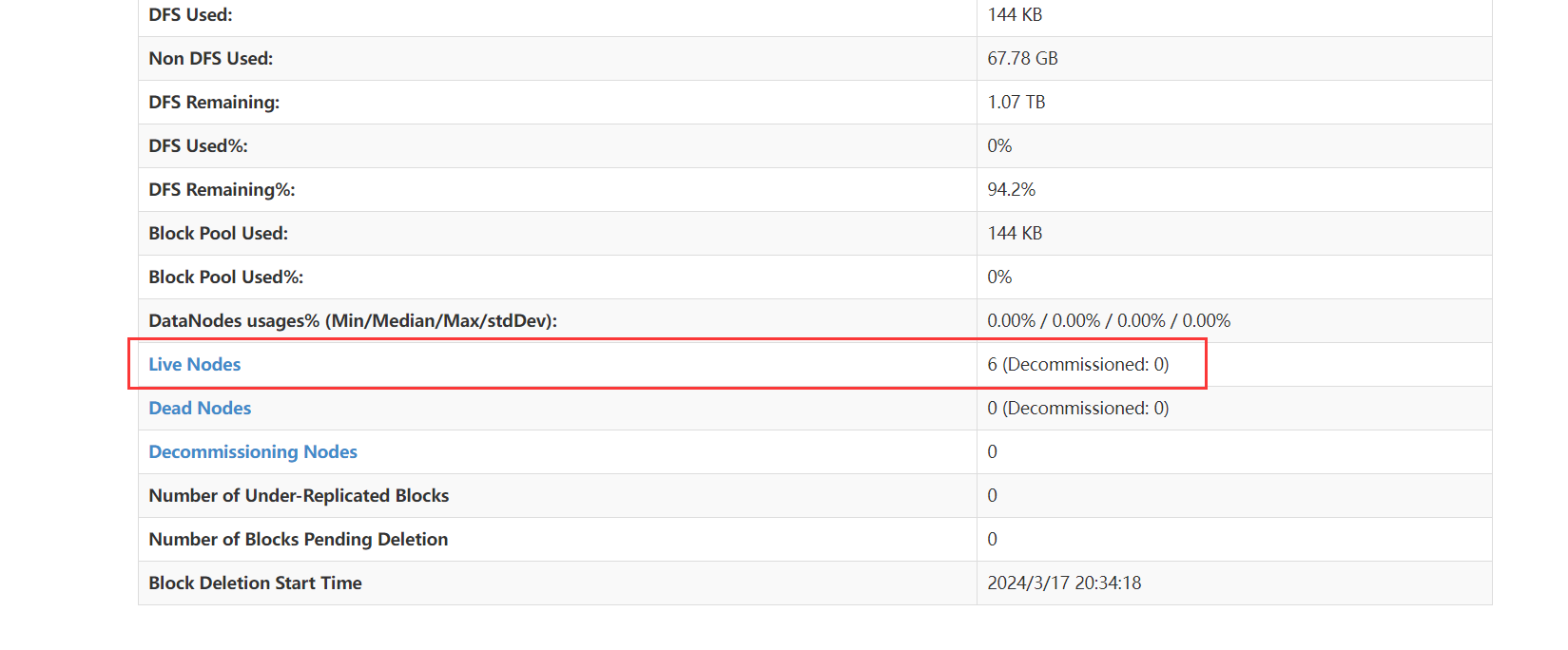
浏览器查看文件块
高可用搭建
先关闭服务
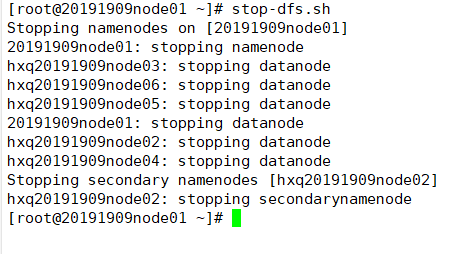
(1)文档:/opt/20191909/hadoop-2.6.5/share/doc/hadoop 官方文档

(2)两个namenode节点互相免密钥
(本例中node01,node02互相免密钥,node02生成密钥文件,分发自己和node01)
在node02的.ssh目录下输入
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat id_dsa.pub >> authorized_keys //将id_dsa.pub公钥文件追加到验证文件
scp id_dsa.pub 20191909node01:`pwd`/hxq20191909node02.pub//分发密钥给node01
cat hxq20191909node02.pub>>authorized_keys //在node01的.ssh目录下
在node02下来登录node01

(3)配置文件:
在/opt/20191909/hadoop-2.6.5/etc/hadoop目录下
- dfs.nameservices //逻辑名称
hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
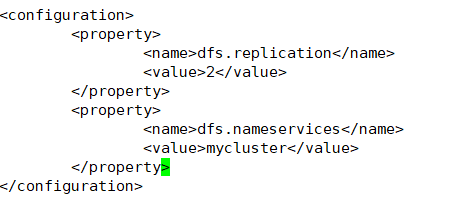
-
dfs.ha.namenodes.[nameservice ID] //只能1主1从两个
<property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property>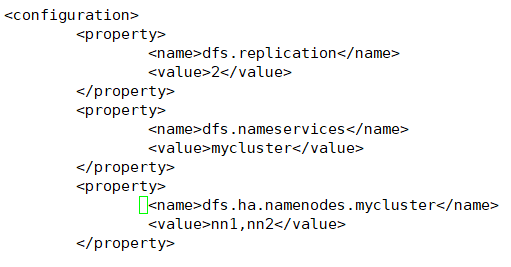
-
dfs.namenode.rpc-address.[nameservice ID].[name node ID]
<property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>20191909node01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hxq20191909node02:8020</value> </property>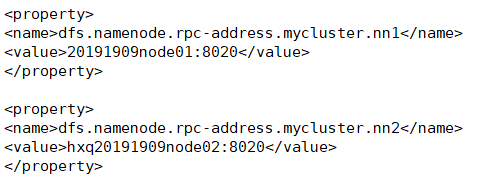
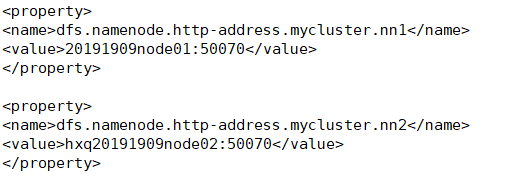
4.dfs.namenode.http-address.[nameservice ID].[name node ID]
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>20191909node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hxq20191909node02:50070</value>
</property>
5.dfs.namenode.shared.edits.dir // URI which identifies the group of JNs
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://20191909node01:8485;hxq20191909node02:8485;hxq20191909node03:8485/mycluster</value>
</property>

6.dfs.client.failover.proxy.provider.[nameservice ID] //java class that HDFS clients use to contact the Active Namenode
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>

-
dfs.ha.fencing.methods //a list of scripts or java classes which will be used to fence the Active Namenodes during a failover
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property>
8.fs.defaultFS //the default path prefix used by the Hadoop FS client when none is given
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
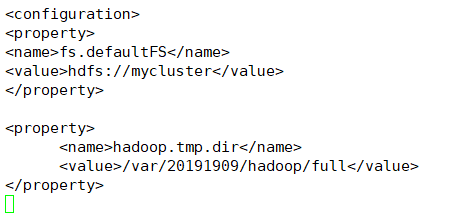
-
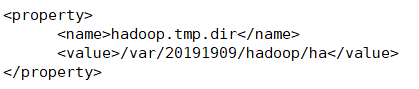
<property> <name>hadoop.tmp.dir</name> <value>/var/20191909/hadoop/ha</value> </property> )
)core-site暂时修改完成
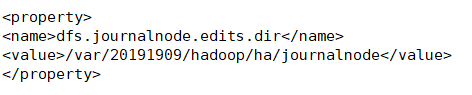
-
dfs.journalnode.edits.dir //the path where the journalnode daemon will store its local state
在hdfs-site中修改
<property> <name>dfs.journalnode.edits.dir</name> <value>/var/20191909/hadoop/ha/journalnode</value>
(4)zookeeper配置(自动故障转移)
ZooKeeper quorum and ZKFailoverController process
ZooKeeper 功能:Failure detection; Active Namenode election
ZKFC 功能:health monitoring;Zookeeper session management;zookeeper-based election)
hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
core-site.xml
<property>
<name>ha.zookeeper.quorum</name>
<value>hxq20191909node02:2181,hxq20191909node03:2181,hxq20191909node04:2181,hxq20191909node05:2181,hxq20191909node06:2181</value>
</property>

(5) 分发配置文件给其他节点
scp core-site.xml hdfs-site.xml hxq20191909node02:`pwd`
scp core-site.xml hdfs-site.xml hxq20191909node03:`pwd`
...
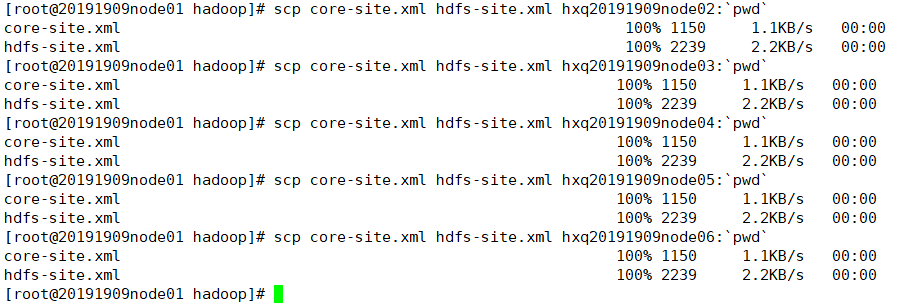
(6) 搭建zookeeper
-
在相关节点安装zookeeper
上传zookeeper-3.4.6.tar.gz压缩包

解压缩文件到/opt/20191909/目录下
tar xf zookeeper-3.4.6.tar.gz -C /opt/20191909/


-
配置zookeeper
进入zookeeper目录的conf目录

mv zoo_sample.cfg zoo.cfg
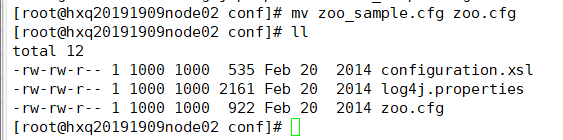
修改zoo.cfg,
dataDir=/var/20191909/zk (创建该目录)
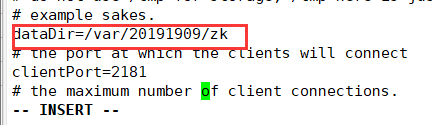
增加:
server.1=hxq20191909node02:2888:3888
server.2=hxq20191909node03:2888:3888
server.3=hxq20191909node04:2888:3888
server.4=hxq20191909node05:2888:3888
server.5=hxq20191909node06:2888:3888
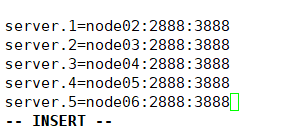
//1是ID,2888是主从节点通信端口,3888是选举机制端口,zookeeper也是主从架构,也有选举机制
- 分发zookeeper给其他节点
scp -r zookeeper-3.4.6/ hxq20191909node03:`pwd` //node3~6

-
mkdir -p /var/20191909/zk //都要创建 echo 1 > /var/20191909/zk/myid //node02 echo 2 > /var/20191909/zk/myid //node03 echo 3 > /var/20191909/zk/myid //node04 echo 4 > /var/20191909/zk/myid //node05 echo 5 > /var/20191909/zk/myid //node06
5.设置环境变量(/etc/profile)
export ZOOKEEPER_HOME=/opt/20191909/zookeeper-3.4.6
PATH=$PATH:$ZOOKEEPER_HOME/bin

6.分发:
scp /etc/profile hxq20191909node03:/etc/ //3~6都要发 然后. /etc/profile #2给3
(7) 启动zookeeper
zkServer.sh start
jps //查看进程: QuorumPeerMain
或者:
zkServer.sh status // Mode:leader or Mode:foolwer
zkServer.sh stop //关闭zookeeper
注意:至少启动两台服务器
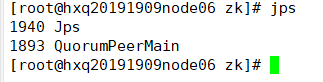

(8) 启动journalnode(3个节点)
hadoop-daemon.sh start journalnode


(9) 格式化node01(或 node02)
hdfs namenode -format
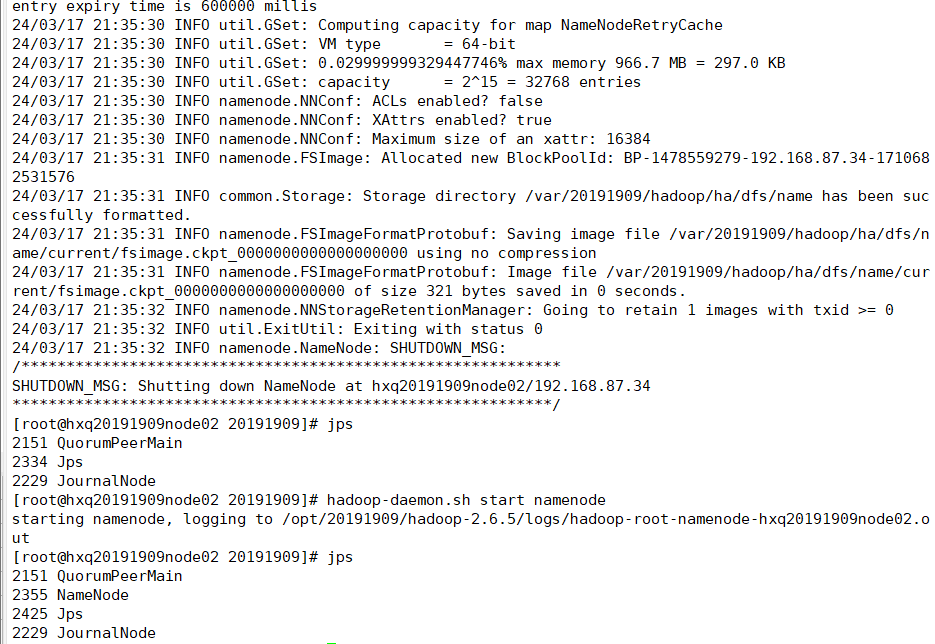
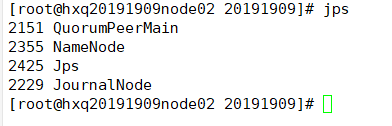
(10)启动node02
hadoop-daemon.sh start namenode

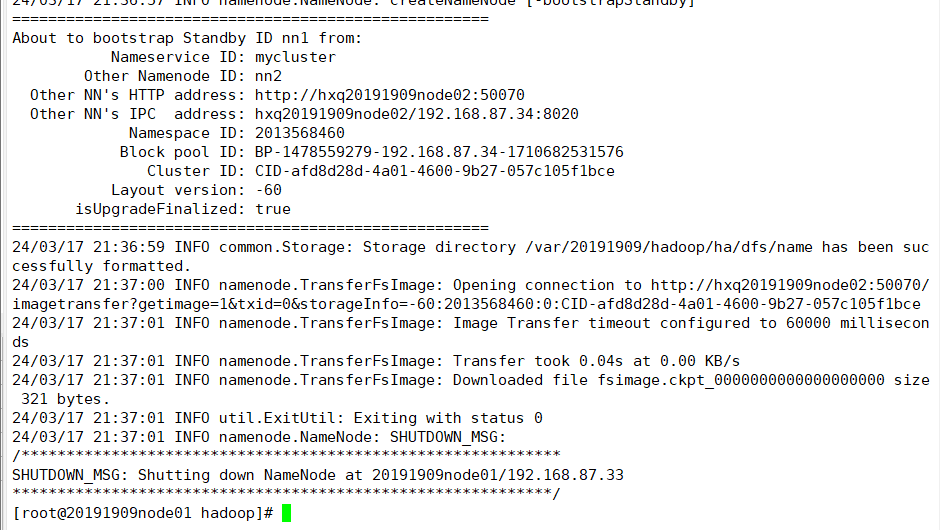
(11)复制node02元数据信息给node01
hdfs namenode -bootstrapStandby (在node01中执行)
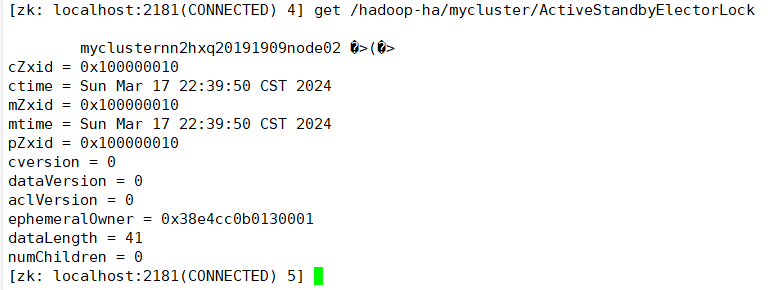
(12)两个namenode在zookeeper上注册
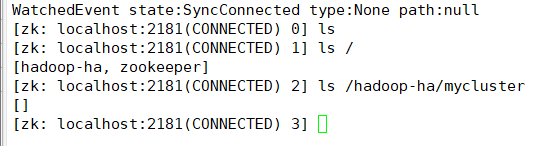
1.zkCli.sh //客户端查看
ls / 只有[zookeeper]
2. hdfs zkfc -formatZK //initializing HA state in zookeeper
再查看: [hadoop-ha,zookeeper]
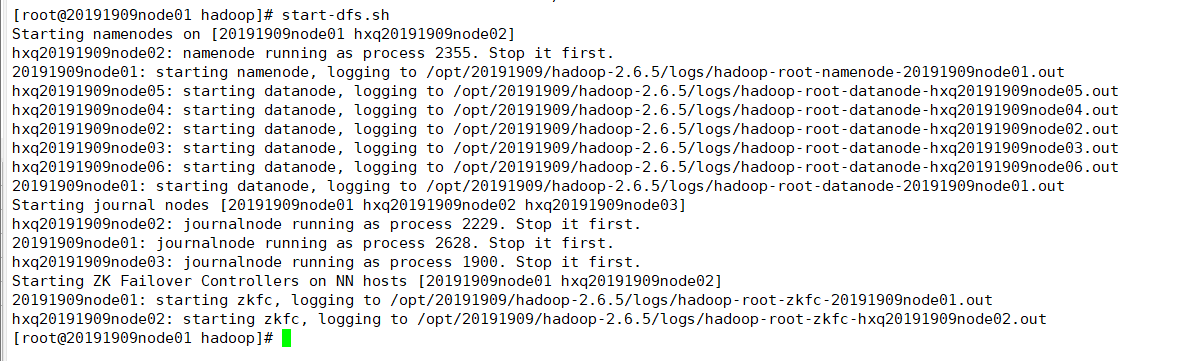
(13)在node01上启动(因为有免密钥登录)
start-dfs.sh
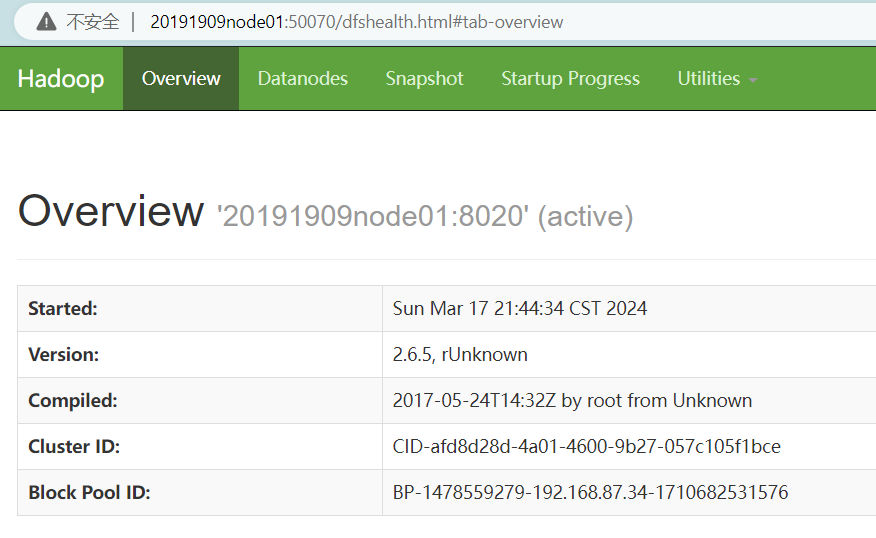
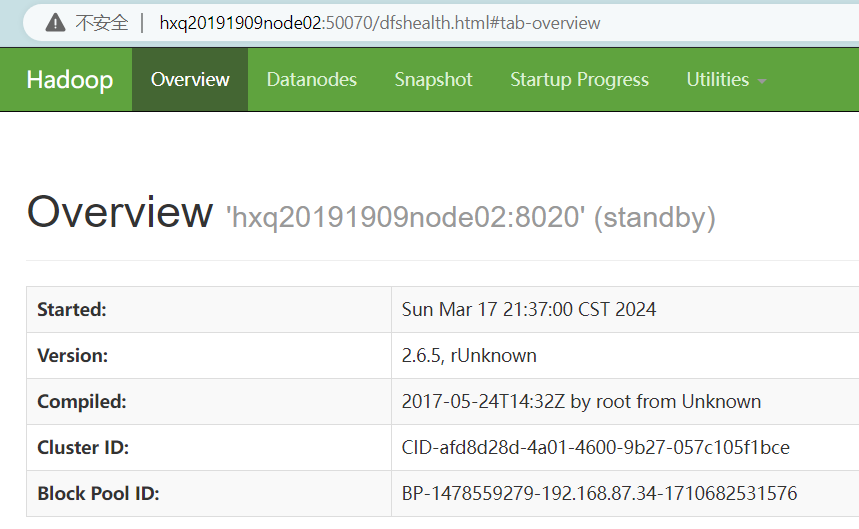
(14)浏览器访问
20191909node01:50070 //active
hxq20191909node02:50070 //standby
(15)实验:关闭node01(active namenode)
hadoop-daemon.sh stop namenode
hxq20191909node02:50070 //显示为active

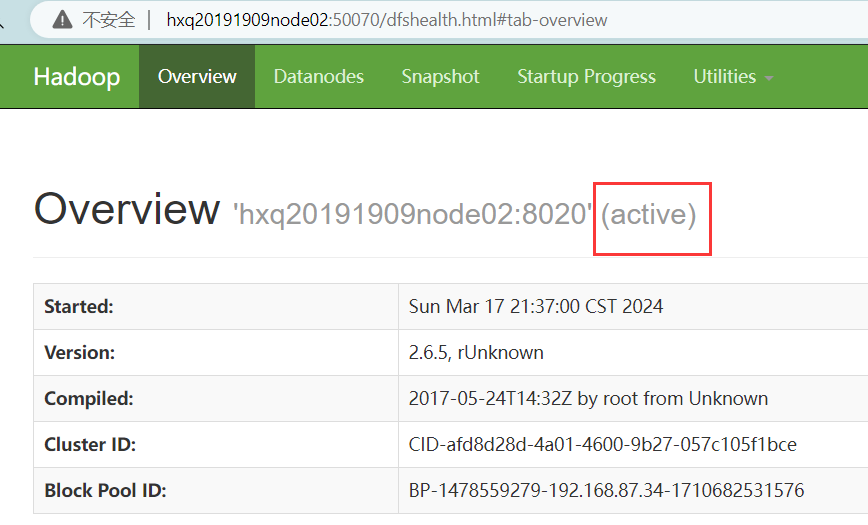
关闭node01的namenode再打开
此时node01的状态变成standby
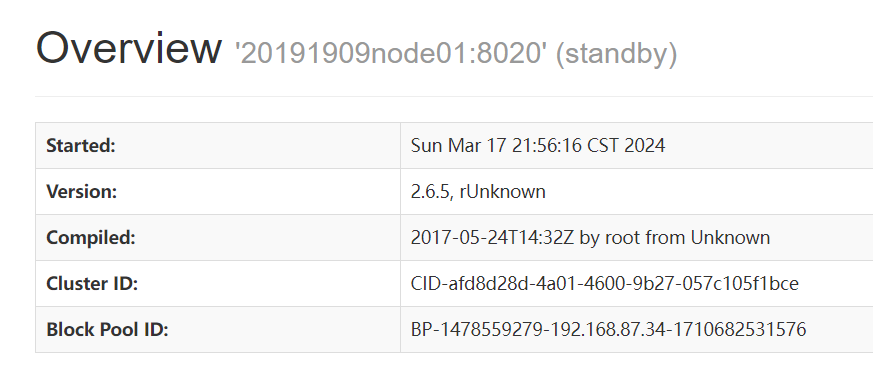
四、出现的问题及解决方案
-
报错
[root@hxq20191909node02 20191909]# zkServer.sh status JMX enabled by default Using config: /opt/20191909/zookeeper-3.4.6/bin/…/conf/zoo.cfg Error contacting service. It is probably not running.
解决方案
恢复快照,重新配置文件,细心一点
五、实验结果
实验成功搭建全分布式及高可用架构
现在在浏览器查看状态为
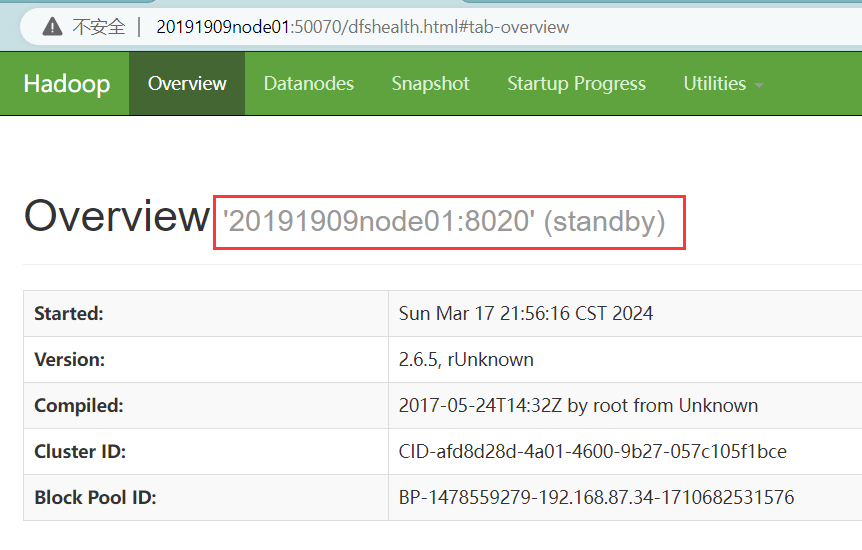
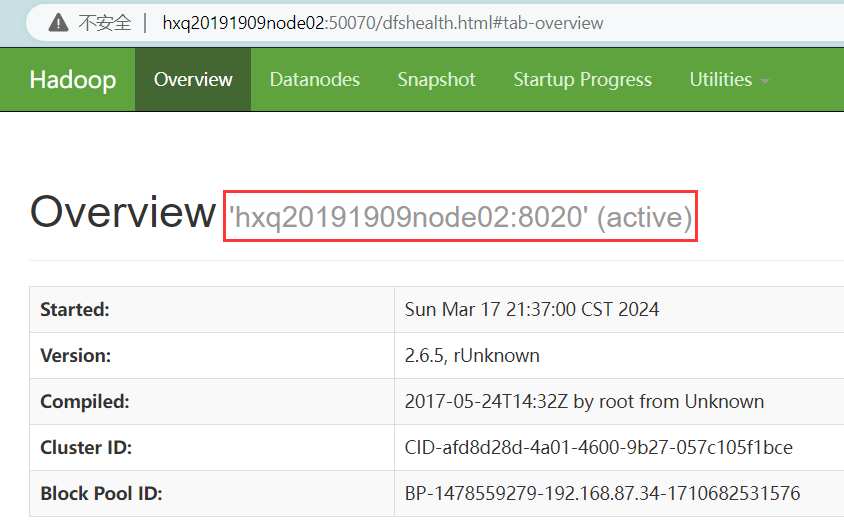
e
[外链图片转存中…(img-7DISxQuh-1711692961927)]
[外链图片转存中…(img-7O6QIYN8-1711692961927)]
关闭node01的namenode再打开
此时node01的状态变成standby
[外链图片转存中…(img-pd7VFpa9-1711692961927)]
[外链图片转存中…(img-NUYGW4gv-1711692961928)]
四、出现的问题及解决方案
-
报错
[root@hxq20191909node02 20191909]# zkServer.sh status JMX enabled by default Using config: /opt/20191909/zookeeper-3.4.6/bin/…/conf/zoo.cfg Error contacting service. It is probably not running.
解决方案
恢复快照,重新配置文件,细心一点
五、实验结果
实验成功搭建全分布式及高可用架构
现在在浏览器查看状态为
[外链图片转存中…(img-GDga6CX5-1711692961928)]
[外链图片转存中…(img-jVi3Fmxa-1711692961928)]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)