编译原理 语法分析程序
编译原理 语法分析程序
工程链接:https://pan.baidu.com/s/1HS_b8xn34GFzh7g0CNfnsw
提取码:w0au(仅供参考!)
建议配合源码观看
第一部分、 学习经典的语法分析器
一、实验目的
学习已有编译器的经典语法分析源程序。
二、实验任务
阅读已有编译器的经典语法分析源程序,并测试语法分析器的输出。
三、实验内容
1.选择一个编译器,掌握它的语法分析程序。
编译器选择:TINY
2.阅读语法分析源程序。尤其要求对相关函数与重要变量的作用与功能进行稍微详细的描述。
TINY有两种基本的结构类型:
语句和表达式。语句共有5类:(if语句、repeat语句、assign语句、read语句和read语句),表达式共有3类(算符标的是、常量表达式和标识符表达式)。因此,语法树节点首先安装它是语句还是表达式来进行分类,接着根据语句或表达式的种类进行再次分类。
树节点最大可有3个孩子的结构(仅在带有else部分的if语句才用到)。语句通过同属域而不是子域来排序,即由父亲到他的孩子的唯一物理连接是到最左孩子的。孩子则在一个标准连接表中自左向右连接到一起,这种连接称作同属连接,用于区别父子连接。
五种语句对应的语法树: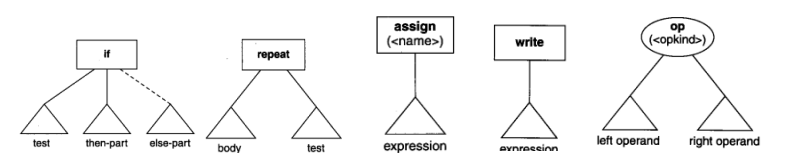
树结构设计流程:
①创建一个树节点的结构体
②使用递归下降算法,将每一个文法产生式转变成递归函数中的一个子句
③用前看符号指导产生式规则的选择
④创建一个match函数,对前看符号进行匹配,如果不匹配,调用syntaxError函数对错误语法进行报错。
⑤创键一个printTree函数,将一个语法树打印出来。
3.测试语法分析器。对TINY语言要求输出测试程序的字符形式的抽象语法树。(手工或编程)画出图形形式的抽象语法树。
3.1.TINY语言测试用例:
sample.tny
3.2.TINY语言的输出测试程序的字符形式抽象语法树: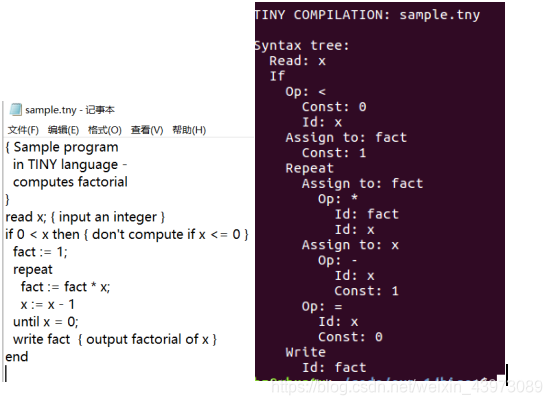
3.3.手绘抽象语法树的图形形式: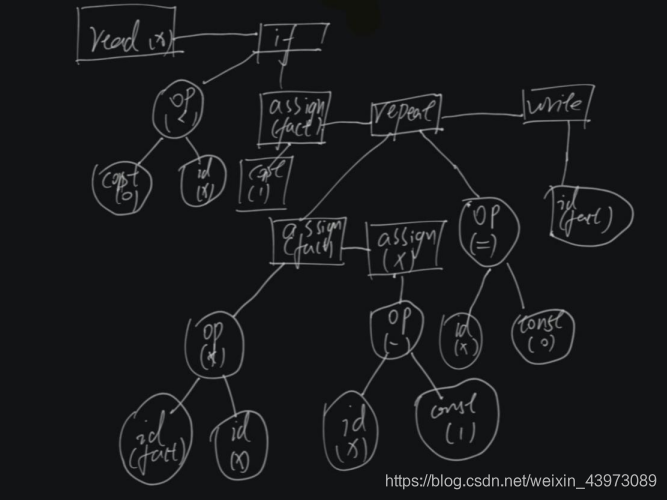
第二部分——实现一门语言的语法分析器(3学时)
一、实验目的
通过本次实验,加深对语法分析的理解,学会编制语法分析器。
二、实验任务
用C或C++语言编写一门语言的语法分析器。
三、系统设计
1.语言确定
C-语言,其定义在《编译原理及实践》附录A中。
2.完成C-语言的BNF文法到EBNF文法的转换。
通过这一转换,消除左递归,提取左公因子,将文法改写为LL(1)文法,以适用于自顶向下的语法分析。规划需要将哪些非终结符写成递归下降函数。
因为C-语言的BNF文法存在左递归,因此,这里首先手工消除左递归与公因子转化为EBNF;
语法分析采用递归下降的算法,转换后的EBNF文法规则如下:({ }表示可有可无)
program → declaration-list
declaration-list → declaration { declaration }
declaration → var-declaration | fun-declaration
var-declaration → type-specifier ID | type-specifier ID [ NUM ] ;
type-specifier → int | void
fun-declaration → type-specifier ID ( params ) | compound-stmt
params → params-list | void
param-list → param { , param }
param → type-specifier ID { [ ] }
compound-stmt → { local-declarations statement-list }
local-declarations → empty { var-declaration }
statement-list → { statement }
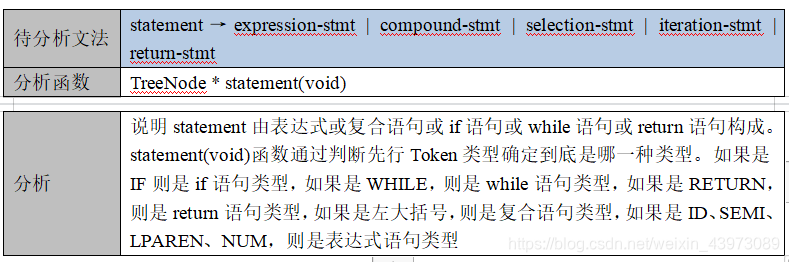
statement → expression-stmt | compound-stmt | selection-stmt | iteration-stmt | return-stmt
expression-stmt → [ expression ];
selection-stmt → if ( expression ) statement [ else statement ]
iteration-stmt → while ( expression ) statement
return-stmt → return [ expression ] ;
expression → var = expression | simple-expression
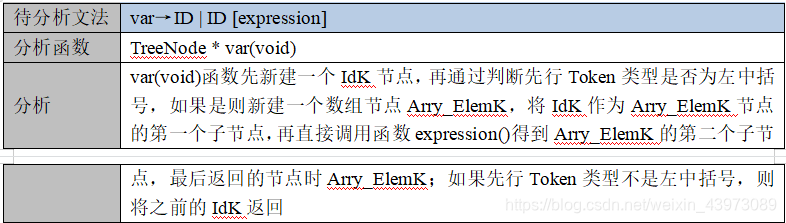
var → ID | ID [ expression ]
simple-expression → additive-expression { relop additive-expression}
relop → <= | < | > | >= | == | !=
additive-expression → term { addop term }
addop → + | -
term → factor {mulop factor }
mulop → * | /
factor → ( expression ) | var | call | NUM
call → ID ( args )
args → arg-list | empty
arg-list → expression { , expression }
3.为每一个将要写成递归下降函数的非终结符,定义其抽象语法子树的形式结构,然后定义C-语言的语法树的数据结构。
3.1.因为非终结符较多,所以这里简单的画出几个语句、表达式、声明的语法子树的形式结构: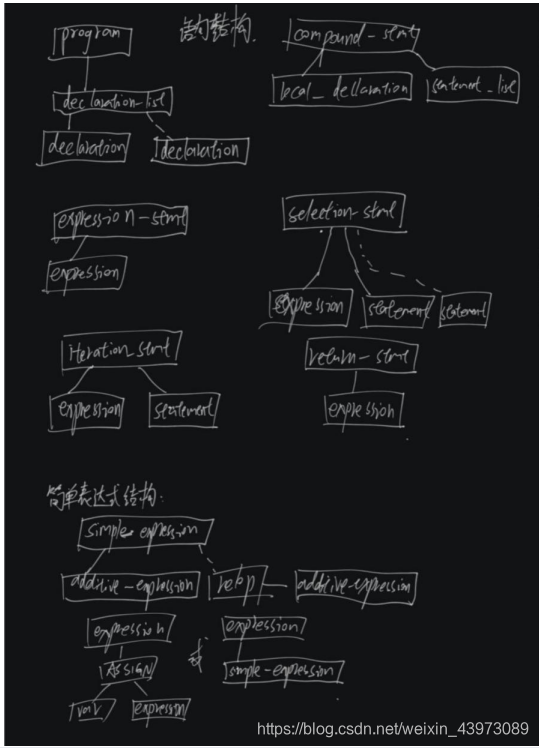
3.2.c-语言的语法树数据结构:
树结点定义: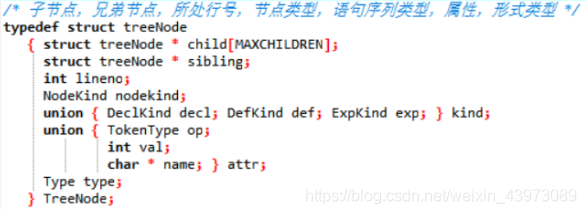
包含子结点、兄弟节点、行号、序列类型(声明、定义、表达式中的一种)、属性、形式类型信息;
序列类型:定义decl、声明def、表达式exp三种;
树结点的构建:
以声明结点创建为例: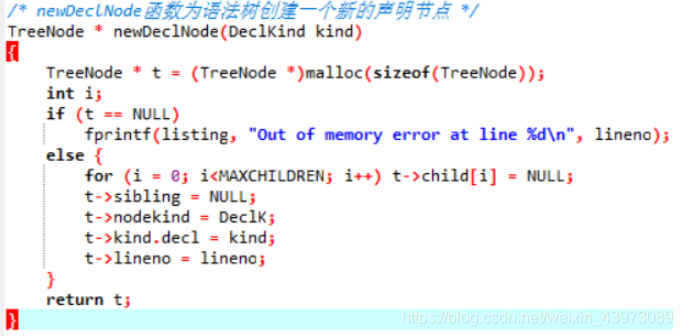
开辟空间、给子节点和兄弟节点赋初值NULL、给结点结点类型赋初值Declk表示声明、行号赋初值;
4.仿照前面学习的语法分析器,编写选定语言的语法分析器。
4.1.选择使用递归下降的任意方法实现;
注:本实验需要用到实验1当中的词法分析器,因此,采用增量编程的方法,直接在原来的实验1的工程基础上,加上语法分析的相关文件myparse.h、myparse.c、util.c、util.h;
文件结构如下: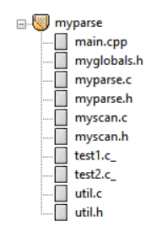
语法分析添加文件:
parser.h:与语法分析相关的声明
parser.cpp:语法分析阶段的实现
util.h:语法树的结点生成与打印相关函数的声明
util.c:语法树的结点生成与打印相关函数的实现
词法分析部分与实验一完全相同,语法分析程序需要用到词法分析的getToken函数来进行Token词素的获取。
语法分析的过程主要是:在语法分析之的过程中通过词法分析程序获得Token,然后通过递归向下分析法根据C-语言的文法进行语法分析,并生成语法树,最后打印语法树。程序构建树大致流程: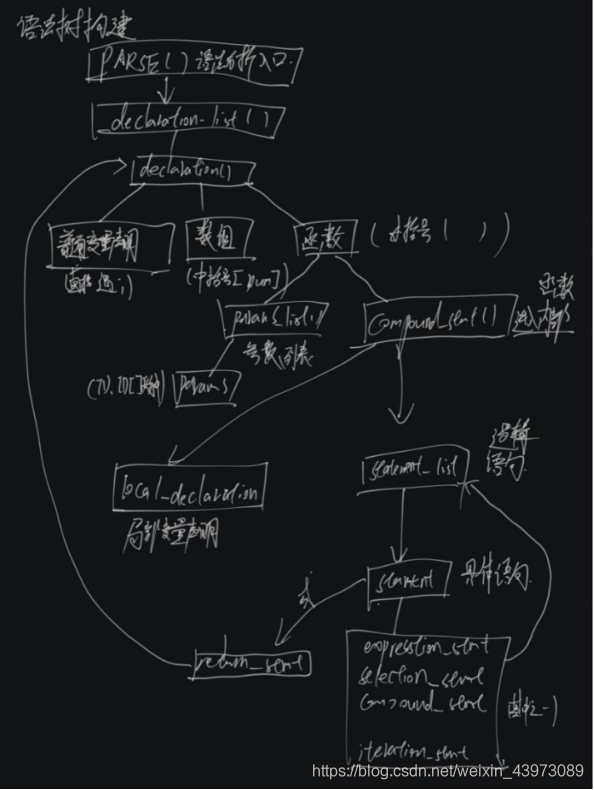
递归下降构建语法树时,对于每条产生式设计函数,调用词法分析的函数,返回当前Token并准备下次读取。 分解产生式进行Match判断下一个产生式的入口,在Match的同时函数会判断当前Token 的合法性同时读取下一个Token。对于左因子与间接递归的情况,在本条产生式函数内进行多次Match,直至匹配到出现差异的地方进行递归函数的调用,这个过程中,根据产生式构建带有节点性质的语法树。由于手动消除了间接递归,部分情况需要将父节点的属性向下传递,帮助确定子节点的性质。
4.2.节点类型:
在程序处理过程中,主要对语法树定义了19种节点,节点性质与相对关系如下:
| 节点类型 | 描述 | 子节点组成 |
|---|---|---|
| IntK | 变量或返回值类型(int) | 无 |
| VoidK | 变量或返回值类型(void) | 无 |
| IdK | 标示符(id) | 无 |
| ConstK | 数值 | 无 |
| Var_DeclK | 变量声明 | 变量类型+变量名 |
| Var_DeclK | 数组声明 | 数组名+数组大小 |
| FunK | 函数声明 | 返回类型+函数名+参数列表+函数体 |
| ParamsK | FunK的参数列表 | 参数(如果有多个参数,则之间为兄弟节点) |
| ParamK | FunK的参数 | 参数类型+参数名 |
| CompK | 复合语句体 | 变量声明列表+语句列表 |
| Selection_StmtK | if | 条件表达式+IF体+[ELSE体] |
| Iteration_StmtK | while | 条件表达式+循环体 |
| Return_StmtK | return | [表达式] |
| AssignK | 赋值 | 被赋值变量+赋值变量 |
| OpK | 运算 | 运算符左值+运算符右值 |
| Arry_ElemK | 数组元素 | 数组名+下标 |
| CallK | 函数调用 | 函数名+参数列表 |
| ArgsK | CallK的参数列表 | [表达式](如果有多个表达式,则之间为兄弟节点) |
| UnkownK | 未知节点 | 无 |
4.3.成员函数和变量的作用和含义:
Token getToken():获取保存在scanner中TokenList数组中的Token,每次获取完之后数组下标指向下一个 void
printSpace(int n):打印n个空格 void syntaxError(string
s):报错的函数,报告出错位置(行号)、出错位置附近的Token void match(TokenType
ex):与目标Token类型ex匹配,如果匹配成功则获取下一个Token(为currentToken赋值),否则报错 void
printTree(TreeNode * t):打印生成的语法树 TreeNode * newNode(Nodekind
k):根据节点类型新建节点
以下为递归向下分析文法过程中各阶段的分析函数:
TreeNode * declaration_list(void);
TreeNode * declaration(void);
TreeNode * params(void);
TreeNode * param_list(TreeNode * k);
TreeNode * param(TreeNode * k);
TreeNode * compound_stmt(void);
TreeNode * local_declaration(void);
TreeNode * statement_list(void);
TreeNode * statement(void);
TreeNode * expression_stmt(void);
TreeNode * selection_stmt(void);
TreeNode * iteration_stmt(void);
TreeNode * return_stmt(void);
TreeNode * expression(void);
TreeNode * var(void);
TreeNode * simple_expression(TreeNode * k);
TreeNode * additive_expression(TreeNode * k);
TreeNode * term(TreeNode * k);
TreeNode * factor(TreeNode * k);
TreeNode * call(TreeNode * k);
TreeNode * args(void);
以下表格列出了根据上文中的C-文法使用递归向下分析方法分析程序的过程,待分析文法中列出的是将要分析的若干文法,分析函数是程序针对该文法编写的分析函数,用以分析该文法,分析是对该文法的分析过程以及分析函数的编写思想,代码是分析函数用C语言的实现;
4.4.各文法分析过程如下(具体代码实现见源码):
| 待分析文法 | program→declaration-list |
|---|---|
| 分析函数 | TreeNode * parse(void) |
| 分析 | 说明C-语言编写的程序由一组声名序列组成。parse(void)函数使用递归向下分析方法直接调用declaration_list()函数,并返回树节点 |
| 待分析文法 | declaration_list → declaration{ declaration } |
|---|---|
| 分析函数 | TreeNode * declaration_list(void) |
| 分析 | 说明C-语言编写的程序由一组声名序列组成。declaration_list(void)函数使用递归向下分析方法直接调用declaration()函数,并返回树节点 |
![待分析文法 declaration→var-declaration|fun-declaration
var_declaration →type-specifier ID; | type-specifier ID [NUM];
fun-declatation→type-specifier ID (params) | compound-stmt
type - specifier → int | void
分析函数 TreeNode * declaration(void)
分析 说明C-语言的声明分为变量声明和函数声明。declaration(void)函数并不是直接调用var-declaration或fun-declaration文法所对应的函数,令其返回节点,实际上程序并没有为var-declaration和fun-declaration文法定义函数,而是在declaration(void)函数中,通过求First集合的方式先确定是变量定义还是函数定义,然后分别根据探测的结果生成变量声明节点(Var_DeclK)或函数声明节点(FunK)。所以var-declaration和fun-declaration文法在declaration→var-declaration|fun-declaration文法中就都已经分析了](https://i-blog.csdnimg.cn/blog_migrate/67f7fe64f5e863360c78ecb3a33e75a6.png)

| 待分析文法 | param_list→param{, param} |
|---|---|
| 分析函数 | TreeNode * param_list(TreeNode * k) |
| 分析 | 说明参数列表由param序列组成,并由逗号隔开。param_list(TreeNode * k)函数使用递归向下分析方法直接调用param(TreeNode * k)函数,并返回树节点 |
待分析文法 param→ type-specifier ID{[ ]}
分析函数 TreeNode * param(TreeNode * k)
分析 说明参数由int或void、标示符组成,最后可能有中括号表示数组。param(TreeNode * k)函数根据探测先行Token是int还是void而新建IntK或VoidK节点作为其第一个子节点,然后新建IdK节点作为其第二个子节点,最后探测Follow集合,是否是中括号,而确定是否再新建第三个子节点表示数组类型
| 待分析文法 | compound-stmt→{ local-declaration statement-list} |
|---|---|
| 分析函数 | TreeNode * compound_stmt(void) |
| 分析 | 说明复合语句由用花括号围起来的一组声明和语句组成。compound_stmt(void) 函数使用递归向下分析方法直接调用local_declaration()函数和statement_list()函数,并根据返回的树节点作为其第一个子节点和第二个子节点 |
| 待分析文法 | local-declarations → empty {var- declaration} |
|---|---|
| 分析函数 | TreeNode * local_declaration(void) |
| 分析 | 说明局部变量声明要么是空,要么由许多变量声明序列组成。local_declaration(void)函数通过判断先行的Token是否是int或void便可知道局部变量声明是否为空,如果不为空,则新建一个变量定义节点(Var_DeclK) |
待分析文法 statement-list→{statement}
分析函数 TreeNode * statement_list(void)
分析 说明由语句列表由0到多个statement组成。statement_list(void)函数通过判断先行Token类型是否为statement的First集合确定后面是否是一个statement,如果是,则使用递归向下分析方法直接调用statement()函数
| 待分析文法 | expression-stmt→ [expression]; |
|---|---|
| 分析函数 | TreeNode * expression_stmt(void) |
| 分析 | 说明表达式语句有一个可选的且后面跟着分号的表达式。expression_stmt(void)函数通过判断先行Token类型是否为分号,如果不是则直接调用函数expression() |
![待分析文法 selection-stmt→if (expression) statement [else statement]
分析函数 TreeNode * selection_stmt(void)
分析 selection_stmt(void)函数直接调用expression()函数和statement()函数分别得到其第一个和第二个子节点,然后通过判断先行Token类型是否为ELSE,如果是则直接调用statement()函数得到其第三个子节点](https://i-blog.csdnimg.cn/blog_migrate/9f6deaf0df798054338ff7095f45db0c.png)
| 待分析文法 | iteration-stmt→while (expression)statement |
|---|---|
| 分析函数 | TreeNode * iteration_stmt(void) |
| 分析 | iteration_stmt(void)函数直接调用expression()函数和statement()函数分别得到其第一个和第二个子节点 |
| 待分析文法 | return-stmt→return [expression]; |
|---|---|
| 分析函数 | TreeNode * return_stmt(void) |
| 分析 | return_stmt(void)函数通过判断先行Token类型是否为分号,如果不是则直接调用函数expression()得到其子节点 |

5.准备2~3个测试用例,测试并解释程序的运行结果。
5.1.测试样例1(正例):
代码:
测试结果:
手工画出语法树为(因为篇幅原因只画出了第一个函数,其实还有一个函数的树未画):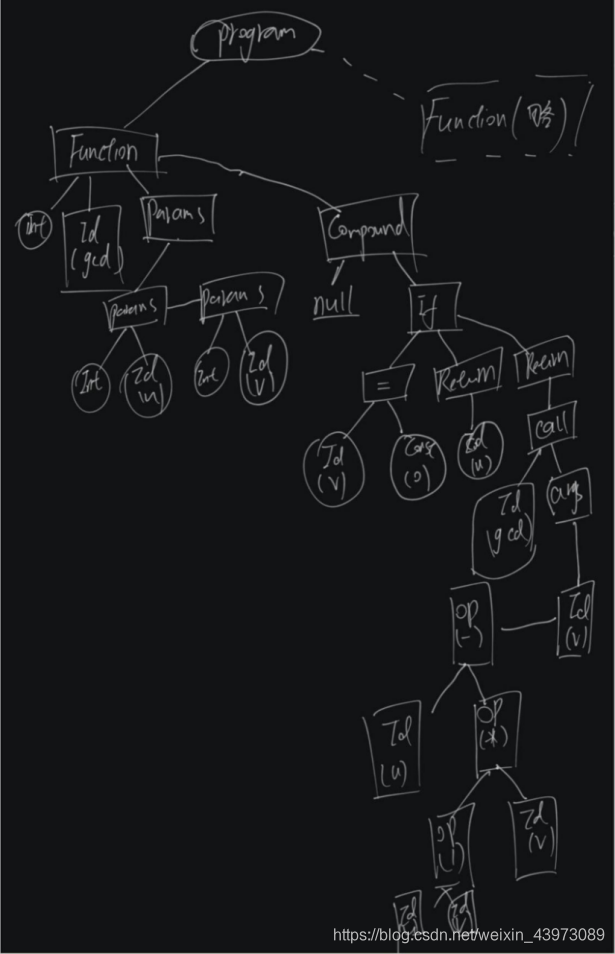
5.2.测试样例2(反例):
代码:
测试结果: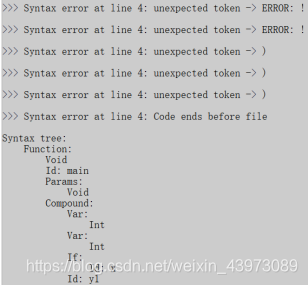
可以看到这里遇到!会报出错误;
四、总结
对于编译原理的这次课程设计,自己经历了从刚开始的不懂明白任务的要求和内容理论知识的了解开始着手写代码完成基本功能根据DFA及自顶向下等理论修改完善代码等这些过程。
在写语法分析的时候,已经对编译器的语法分析的内容有了一定的了解,所以直接进行了理论的学习。首先自己对递归向下分析法进行了学习,将书上的几个递归向下分析的伪代码看过之后,自己对递归向下的分析方法的原理有了初步的认识,大概知道了根据文法怎么分析,但是对于如何编写代码却还是难以下手,于是就对照TINY语言的文法看了几遍书后面的TINY语言的递归向下分析的语法分析程序,这样就基本知道了C-语言的语法分析程序怎么写。由于C-语言给出的文法有左递归存在,于是自己将存在左递归的文法改写成EBNF的形式,并据此进行代码编写。由于在编写代码的过程中需要确定分析是否正确或选择多个文法中的某一个文法进行分析,有时必须探测需要的或下一个Token的类型,在这种情况下需要求First集合,在推导中若存在empty,又需要求Follow集合,所以这样又需要我了解First集合和Follow集合,自己在程序中也根据求出的First集合和Follow集合进行判断,以确定程序的走向。在编写过程中,还有一类问题,就是存在公共左因子,如文法expression→ var = expression | simple-expression,左因子为ID,在分析过程中,由于已经取出了一个ID的Token,且生成了一个IdK的节点,但是在当前状态无法确定是哪一个推导,然而IdK节点已经生成,又无法回退,并且是使用自顶向下的分析方法,已经生成的IdK在程序上方无法使用,自己通过查阅资料等途径的学习确定了在这种情形下的处理方式:将已经生成的IdK节点传到下方的处理程序,所以TreeNode * simple_expression(TreeNode * k)、TreeNode * additive_expression(TreeNode * k)等函数都被设计成有节点类型参数的函数,目的就是将已经生成的节点传到下面的分析函数中去。
通过这次的编译原理课程的学习和实践,自己获益良多。首先最基本的成果是完成了课程设计的任务,实现了编译器的词法分析和语法分析阶段的功能,词法分析主要能过滤注释、分析出语法分析阶段需要的Token并满足语法阶段的所有要求,能够判别词法分析阶段是否出错和出错类型和位置。语法分析主要能根据递归向下的分析思想和C-文法对词法分析获取的Token进行语法分析,能够构造出语法树,能够判别语法分析过程中是否出错以及出错位置和错误类型。
总之,通过这次课程实验,自己获益匪浅,达到了自己预期的效果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)