使用Java实现哈夫曼编码(Huffman Coding)
源码之后会上传到CSDN下载平台和github...
文章目录
(一)需求分析
(二)构建哈夫曼树
(三)构建哈夫曼编码
(四)哈夫曼编码的解码
(五)哈夫曼编码压缩的原理
(六)总结
(七)Java代码实现哈夫曼树:构建节点类&二叉树类
(八)Java代码实现哈夫曼树:计算字符出现的次数
(九)Java代码实现哈夫曼树:构建哈夫曼树
(十)Java代码实现哈夫曼树:进行哈夫曼编码
(十一)Java代码实现哈夫曼树:打印哈夫曼编码
(十二)Java代码实现哈夫曼树:打印编码压缩效率
(十三)Java代码实现哈夫曼树:树状打印哈夫曼树&编码前后的信息
(十四)Java代码实现哈夫曼树:main.java汇总
(一)需求分析
- 哈夫曼编码,又称为霍夫曼编码,它是现代压缩算法的基础
在介绍哈夫曼编码之前,先做一个需求分析:
假设要把字符串【ABBB】转成二进制编码进行传输
可以使用ASCII编码(65~66,1000001~100101),如下:
编码:1000001 100101 100101 100101(这里空格是为了阅读方便)
解码: A B B B (每次取7个位即可)
使用ASCII编码有点冗长,怎么样才能使编码更短呢?
我们可以约定一些字母对应的二进制,如下:
A -> 0
B -> 1
C -> 10
D -> 11
E -> 100
我们尝试一下可不可行,依然传输【ABBB】
编码:0111
解码:A***(只能解析出A,其他的有歧义)
所有的解码情况:ADB、ABD和ABBB(因为协议不定长,所以解码有歧义)
出现歧义的根本原因:其中一个字母的编码是另外一个字母编码的前缀
我们可以规定这些字母都是3位,即等长,如下:
A -> 000
B -> 001
C -> 010
D -> 011
E -> 100
我们再来尝试一下可不可行,依然传输【ABBB】
编码:000 001 001 001(这里空格是为了方便阅读)
解码: A B B B
这种方案是可行的,相对于普通的ASCII编码确实更短了,但是哈夫曼编码可以做得更短
下面介绍哈夫曼编码
(二)构建哈夫曼树
-
先计算出每个字母的出现频率(权值,这里直接用出现次数)
我们传输【ABBBCCCCCCCCDDDDDDEE】
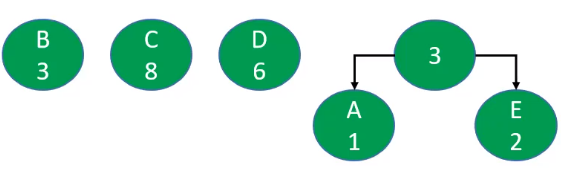
我们可以用出现次数的比例来作为权重衡量,也可以直接用出现次数来作为权重衡量A:1/20 --> 1 B:3/20 --> 3 C:8/20 --> 8 D:6/20 --> 6 E:2/20 --> 2 -
利用这些权值,构建一颗哈夫曼树(又称为霍夫曼树、最优二叉树)
-
如何构建一颗哈夫曼树?(假设有n个权值)
- 以权值作为根节点构建n棵二叉树,组成森林
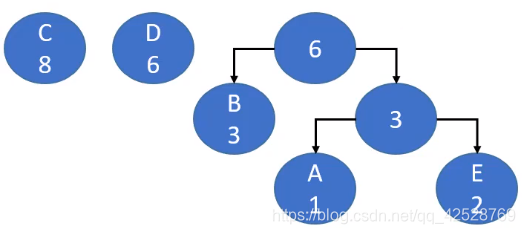
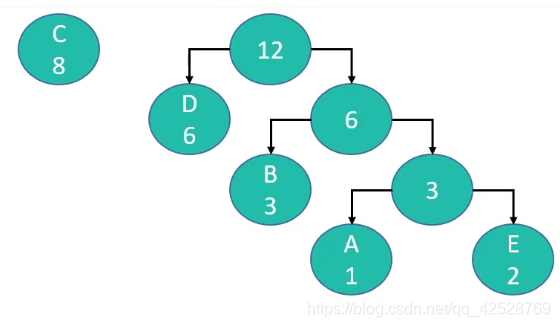
- 在森林中选出2棵根节点最小的树进行合并,作为一棵新树的左右子树,且新树的根节点为其左右子树根节点之和
- 从森林中删除刚才选取的2棵树,并将新树加入森林
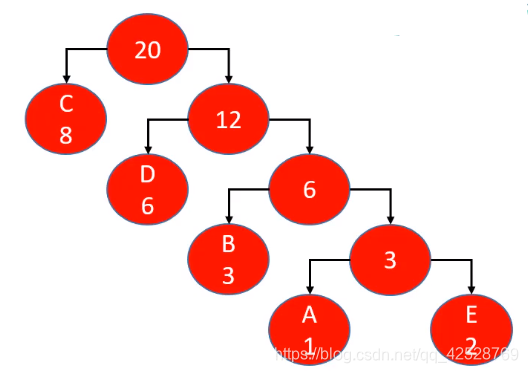
- 重复2、3步骤,直到森林只剩一棵树为止,该树即为哈夫曼树
- 构建哈夫曼树

(三)构建哈夫曼编码
- left为0,right为1,可以得出5个字母对应的哈夫曼编码
| A | B | C | D | E |
|---|---|---|---|---|
| 1110 | 110 | 0 | 10 | 1111 |
【ABBBCCCCCCCCDDDDDDEE】的哈夫曼编码是:
1110 110 110 110 0 0 0 0 0 0 0 0 10 10 10 10 10 10 1111 1111(一共41个二进制位,空格是为了阅读方便)
- 对比我们先前约定的5个字母对应的二进制
| A | B | C | D | E |
|---|---|---|---|---|
| 000 | 001 | 010 | 011 | 100 |
编码为:000001001001010010010010010010010010011011011011011011100100(一共60个二进制位)
- 总结:使用哈夫曼编码,可以压缩至41个二进制位,约为原来长度的68.3%
(四)哈夫曼编码的解码
虽然哈夫曼编码不等长,但是每一个字母的编码都不是另外一个字母编码的前缀,所以是可以解码的
(五)哈夫曼编码压缩的原理
出现次数最多(权值最高的字母)编码最短,出现次数最少(权值最低的字母)编码最长
(六)总结
- n个权值构建出来的哈夫曼树拥有n个叶子节点
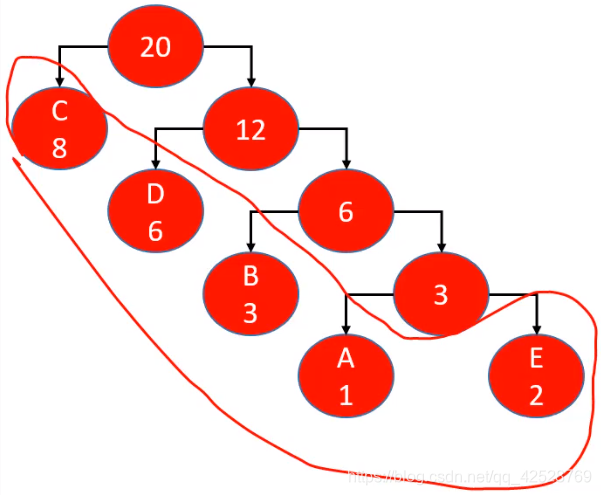
- 每个哈夫曼编码都不是另一个哈夫曼编码的前缀
原因:
- 其实每一个叶子的编码就是根节点到它的路径,路径的长度就是编码的长度
- 一个叶子节点的路径不可能是另一个叶子节点的路径的前缀
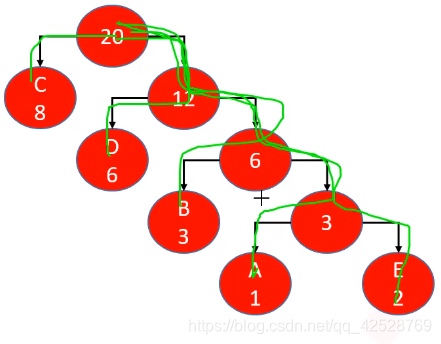
- 哈夫曼树是带权路径长度最短的树,权值较大的节点离根较近
带权路径长度:树中所有的叶子节点的权值乘上其到根节点的路径长度,与最终的哈夫曼编码总长度成正比关系(其实带权路径长度就是等于编码长度)
(七)Java代码实现哈夫曼树:构建节点类&二叉树类
Node.java:
public class Node {
private Character ch;//存储的字母
private Integer value;//对应的权值
private Node leftChild;//左子节点
private Node rightChild;//右子节点
private String code = "";//对应的哈夫曼编码
public Node(Character ch, Integer value) {
this.ch = ch;
this.value = value;
}
public Node(Integer value, Node leftChild, Node rightChild) {
this.value = value;
this.leftChild = leftChild;
this.rightChild = rightChild;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public Character getCh() {
return ch;
}
public void setCh(Character ch) {
this.ch = ch;
}
public Integer getValue() {
return value;
}
public void setValue(Integer value) {
this.value = value;
}
public Node getLeftChild() {
return leftChild;
}
public void setLeftChild(Node leftChild) {
this.leftChild = leftChild;
}
public Node getRightChild() {
return rightChild;
}
public void setRightChild(Node rightChild) {
this.rightChild = rightChild;
}
@Override
public String toString() {
return "Node{" +
"ch=" + ch +
", value=" + value +
", leftChild=" + leftChild +
", rightChild=" + rightChild +
'}';
}
}
BinaryTree.java:
/**
* 二叉树类
*/
public class BinaryTree implements Comparable<BinaryTree>, BinaryTreeInfo {
private Node root;//根节点
public BinaryTree(Node root) {
this.root = root;
}
public Node getRoot() {
return root;
}
public void setRoot(Node root) {
this.root = root;
}
@Override
public String toString() {
return "Tree{" +
"root=" + root +
'}';
}
@Override
public int compareTo(BinaryTree binaryTree) {
int result = (int) (this.root.getValue() - binaryTree.root.getValue());
return result;
}
@Override
public Object root() {
return (Node) root;
}
@Override
public Object left(Object node) {
return ((Node) node).getLeftChild();
}
@Override
public Object right(Object node) {
return ((Node) node).getRightChild();
}
@Override
public Object string(Object node) {
Node mynode = ((Node) node);
StringBuilder sb = new StringBuilder();
if (mynode.getCh() == null) {
sb.append(mynode.getValue());
} else {
sb.append(mynode.getCh()).append("_").append(mynode.getValue());
}
return sb.toString();
}
}
(八)Java代码实现哈夫曼树:计算字符出现的次数
/**
* 统计输入字符串里每一个字符出现的次数,并存入map集合中
*/
public static void statisticsTimes() {
char[] ch = str.toCharArray();
for (char c : ch) { //遍历ch数组
for (int i = 'A'; i <= 'Z'; i++) { //遍历大写字母
if (c == (char) i) {
if (map_times.containsKey(c)) { //map集合中已经存在该字母
num++;
Integer value = map_times.get(c);
map_times.put(c, ++value);
} else { //map集合中还没有该字母
num++;
map_times.put(c, 1);
}
}
}
for (int i = 'a'; i <= 'z'; i++) { //遍历小写字母
if (c == (char) i) {
if (map_times.containsKey(c)) { //map集合中已经存在该字母
num++;
Integer value = map_times.get(c);
map_times.put(c, ++value);
} else { //map集合中还没有该字母
num++;
map_times.put(c, 1);
}
}
}
}
}
(九)Java代码实现哈夫曼树:构建哈夫曼树
/**
* 利用map集合构建哈夫曼树
*/
public static void buildHuffmanTree() {
Node leftChild;
Node rightChild;
Set<Character> set = map_times.keySet(); //遍历map集合
for (Character key : set) {
Integer value = map_times.get(key);
list.add(new BinaryTree(new Node(key, value))); //以权值作为根节点构建n棵二叉树(目前只有一个根节点),组成森林
}
while (list.size() != 1) {
Collections.sort(list); //让节点的权值从小到大排序
leftChild = list.remove(0).getRoot();
leftChild.setCode("0");
rightChild = list.remove(0).getRoot();
rightChild.setCode("1");
Node node = new Node(leftChild.getValue() + rightChild.getValue(), leftChild, rightChild);
list.add(new BinaryTree(node));
}
}
(十)Java代码实现哈夫曼树:进行哈夫曼编码
/**
* 遍历哈夫曼树,并且进行编码
*
* @param root
*/
public static void buildHuffmanCode(Node root) {
if (root.getLeftChild() != null) {
//root.getLeftChild().getCode()是现在正在遍历节点的编码,root.getCode()是之前的编码,两者要相加
root.getLeftChild().setCode(root.getCode() + root.getLeftChild().getCode());
buildHuffmanCode(root.getLeftChild());
}
if (root.getRightChild() != null) {
root.getRightChild().setCode(root.getCode() + root.getRightChild().getCode());
buildHuffmanCode(root.getRightChild());
}
}
(十一)Java代码实现哈夫曼树:打印哈夫曼编码
/**
* 打印哈夫曼编码(前序遍历)
*
* @param root
*/
public static void printHuffmanCode(Node root) {
if (root == null) return;
if (root.getLeftChild() == null & root.getRightChild() == null) { //只打印叶子节点
if (root.getValue() >= 0 && root.getValue() <= 9) {
System.out.print(root.getCh() + "的出现次数是: " + root.getValue());
} else {
System.out.print(root.getCh() + "的出现次数是:" + root.getValue());
}
System.out.println(" 对应的编码是: " + root.getCode());
map_code.put(root.getCh(), root.getCode()); //把叶子节点对应的编码和出现的次数,存入map集合,用于后面打印压缩效率
}
printHuffmanCode(root.getLeftChild());
printHuffmanCode(root.getRightChild());
}
(十二)Java代码实现哈夫曼树:打印编码压缩效率
/**
* 打印编码压缩效率
*/
public static void printCompressionRate() {
double num_befor = 0; //编码之前的大小(单位是bit)
double num_after = 0; //编码之后的大小(单位是bit)
double times; //字符出现的次数
String code; //字符对应的编码
for (Character key : map_times.keySet()) {
times = map_times.get(key);
code = map_code.get(key);
num_after += times * (code.length());
}
num_befor = 8 * num;
System.out.println();
System.out.println("编码压缩效率: " + num_befor / num_after);
System.out.println();
}
(十三)Java代码实现哈夫曼树:树状打印哈夫曼树&编码前后的信息
注意:此处用到了打印器工具类
/**
* 树状打印二叉树、打印编码前后的信息
*/
public static void printOtherInfo() {
BinaryTree tree = list.get(0);
BinaryTrees.println(tree);
System.out.println();
System.out.println("编码之前: " + str);
String str_after = "";
for (char c : str.toCharArray()) {
str_after += map_code.get(c);
}
System.out.println("编码之后: " + str_after);
System.out.println();
BinaryTrees.println(new BinaryTreeInfo() {
@Override
public Object root() {
return tree.getRoot();
}
@Override
public Object left(Object node) {
return ((Node) node).getLeftChild();
}
@Override
public Object right(Object node) {
return ((Node) node).getRightChild();
}
@Override
public Object string(Object node) {
Node mynode = ((Node) node);
StringBuilder sb = new StringBuilder();
if (mynode.getCh() == null) {
sb.append(mynode.getValue() / Double.valueOf(list.get(0).getRoot().getValue()));
} else {
sb.append(mynode.getCh()).append("_").append(mynode.getValue() / Double.valueOf(list.get(0).getRoot().getValue()));
}
return sb.toString();
}
}, BinaryTrees.PrintStyle.INORDER);
}
(十四)Java代码实现哈夫曼树:main.java汇总
main.java:
/**
* 哈夫曼树编码测试类
*/
public class main {
// private static String str = "dcbaddcdddcddcab";
// private static String str = "ABBBCCCCCCCCDDDDDDEE";
// private static String str = "abcdaabbccaaabbbcfaaaabbbccdffeeeaaabbbcccdefabcde";
private static String str = "i am a student i study iot subject in guangzhou university i like the subject and will work hard and do my best to achieve a high score in final examination";
private static HashMap<Character, Integer> map_times = new HashMap<>(); //用来存储不同字符对应的权重(出现次数)
private static HashMap<Character, String> map_code = new HashMap<>(); //用来存储不同字符对应的编码
private static ArrayList<BinaryTree> list = new ArrayList<>(); //定义一个森林,用来存储二叉树
private static double num = 0; //记录字母的数量,用于计算编码压缩效率
/**
* 统计输入字符串里每一个字符出现的次数,并存入map集合中
*/
public static void statisticsTimes() {
char[] ch = str.toCharArray();
for (char c : ch) { //遍历ch数组
for (int i = 'A'; i <= 'Z'; i++) { //遍历大写字母
if (c == (char) i) {
if (map_times.containsKey(c)) { //map集合中已经存在该字母
num++;
Integer value = map_times.get(c);
map_times.put(c, ++value);
} else { //map集合中还没有该字母
num++;
map_times.put(c, 1);
}
}
}
for (int i = 'a'; i <= 'z'; i++) { //遍历小写字母
if (c == (char) i) {
if (map_times.containsKey(c)) { //map集合中已经存在该字母
num++;
Integer value = map_times.get(c);
map_times.put(c, ++value);
} else { //map集合中还没有该字母
num++;
map_times.put(c, 1);
}
}
}
}
}
/**
* 利用map集合构建哈夫曼树
*/
public static void buildHuffmanTree() {
Node leftChild;
Node rightChild;
Set<Character> set = map_times.keySet(); //遍历map集合
for (Character key : set) {
Integer value = map_times.get(key);
list.add(new BinaryTree(new Node(key, value))); //以权值作为根节点构建n棵二叉树(目前只有一个根节点),组成森林
}
while (list.size() != 1) {
Collections.sort(list); //让节点的权值从小到大排序
leftChild = list.remove(0).getRoot();
leftChild.setCode("0");
rightChild = list.remove(0).getRoot();
rightChild.setCode("1");
Node node = new Node(leftChild.getValue() + rightChild.getValue(), leftChild, rightChild);
list.add(new BinaryTree(node));
}
}
/**
* 遍历哈夫曼树,并且进行编码
*
* @param root
*/
public static void buildHuffmanCode(Node root) {
if (root.getLeftChild() != null) {
//root.getLeftChild().getCode()是现在正在遍历节点的编码,root.getCode()是之前的编码,两者要相加
root.getLeftChild().setCode(root.getCode() + root.getLeftChild().getCode());
buildHuffmanCode(root.getLeftChild());
}
if (root.getRightChild() != null) {
root.getRightChild().setCode(root.getCode() + root.getRightChild().getCode());
buildHuffmanCode(root.getRightChild());
}
}
/**
* 打印哈夫曼编码(前序遍历)
*
* @param root
*/
public static void printHuffmanCode(Node root) {
if (root == null) return;
if (root.getLeftChild() == null & root.getRightChild() == null) { //只打印叶子节点
if (root.getValue() >= 0 && root.getValue() <= 9) {
System.out.print(root.getCh() + "的出现次数是: " + root.getValue());
} else {
System.out.print(root.getCh() + "的出现次数是:" + root.getValue());
}
System.out.println(" 对应的编码是: " + root.getCode());
map_code.put(root.getCh(), root.getCode()); //把叶子节点对应的编码和出现的次数,存入map集合,用于后面打印压缩效率
}
printHuffmanCode(root.getLeftChild());
printHuffmanCode(root.getRightChild());
}
/**
* 打印编码压缩效率
*/
public static void printCompressionRate() {
double num_befor = 0; //编码之前的大小(单位是bit)
double num_after = 0; //编码之后的大小(单位是bit)
double times; //字符出现的次数
String code; //字符对应的编码
for (Character key : map_times.keySet()) {
times = map_times.get(key);
code = map_code.get(key);
num_after += times * (code.length());
}
num_befor = 8 * num;
System.out.println();
System.out.println("编码压缩效率: " + num_befor / num_after);
System.out.println();
}
/**
* 树状打印二叉树、打印编码前后的信息
*/
public static void printOtherInfo() {
BinaryTree tree = list.get(0);
BinaryTrees.println(tree);
System.out.println();
System.out.println("编码之前: " + str);
String str_after = "";
for (char c : str.toCharArray()) {
str_after += map_code.get(c);
}
System.out.println("编码之后: " + str_after);
System.out.println();
BinaryTrees.println(new BinaryTreeInfo() {
@Override
public Object root() {
return tree.getRoot();
}
@Override
public Object left(Object node) {
return ((Node) node).getLeftChild();
}
@Override
public Object right(Object node) {
return ((Node) node).getRightChild();
}
@Override
public Object string(Object node) {
Node mynode = ((Node) node);
StringBuilder sb = new StringBuilder();
if (mynode.getCh() == null) {
sb.append(mynode.getValue() / Double.valueOf(list.get(0).getRoot().getValue()));
} else {
sb.append(mynode.getCh()).append("_").append(mynode.getValue() / Double.valueOf(list.get(0).getRoot().getValue()));
}
return sb.toString();
}
}, BinaryTrees.PrintStyle.INORDER);
}
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args) {
statisticsTimes(); //统计每个字符出现的次数
buildHuffmanTree(); //构建哈夫曼树
buildHuffmanCode(list.get(0).getRoot()); //遍历哈夫曼树并且进行编码
printHuffmanCode(list.get(0).getRoot()); //打印哈夫曼编码
printCompressionRate(); //打印编码压缩效率
printOtherInfo(); //树状打印二叉树、打印编码前后的信息
}
}
效果如下: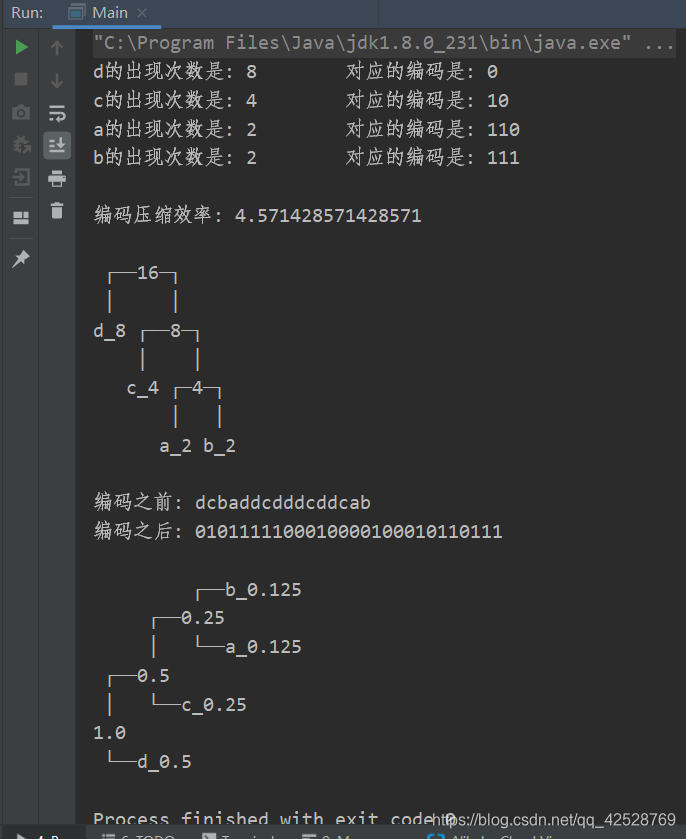

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)