【ComfyUI】通用 静态图像转视频
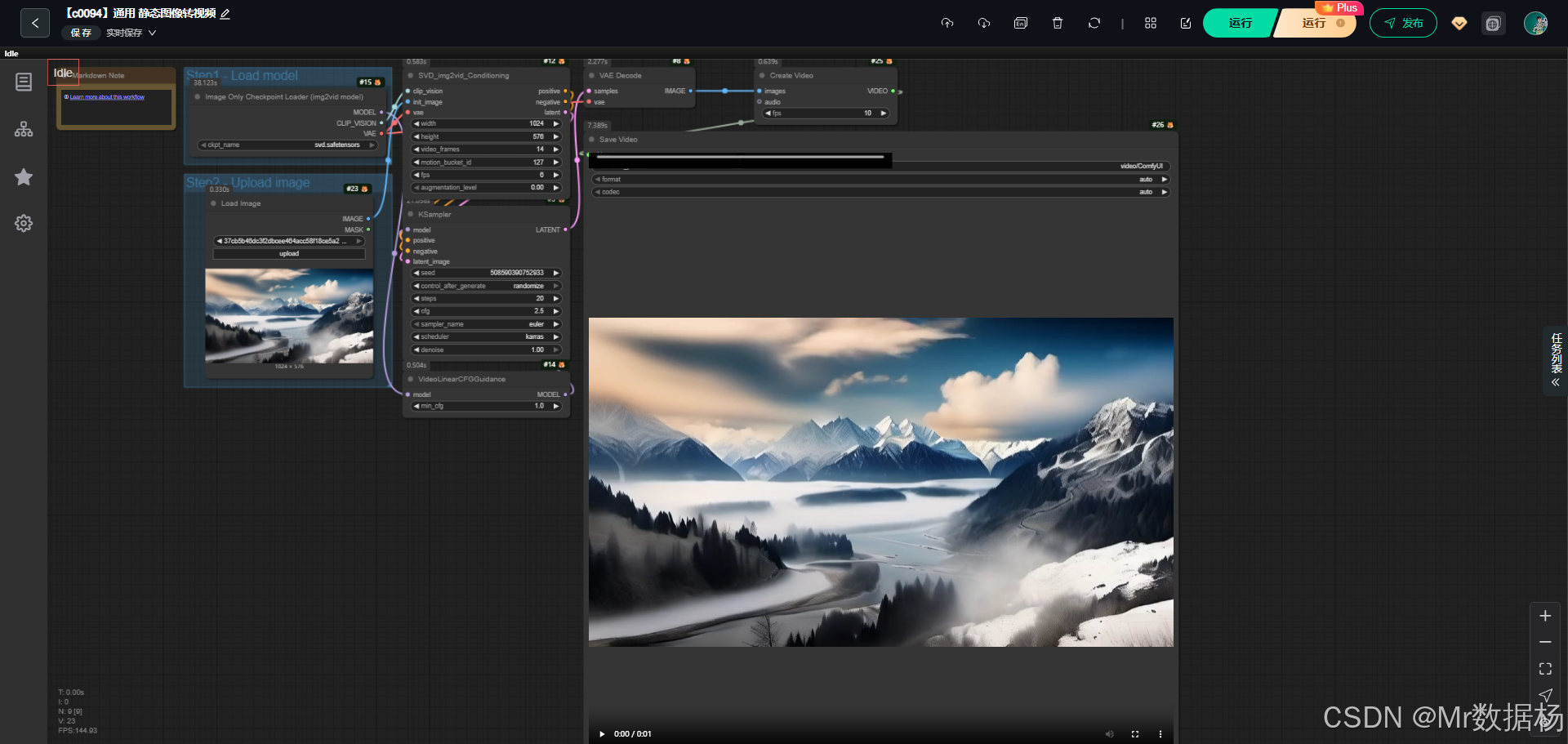
本文介绍了一种基于Stable Video Diffusion(SVD)模型的ComfyUI图生视频工作流,能够将静态图片转换为动态视频。工作流包含模型加载、图像导入、条件生成、视频采样、解码合成等8个核心步骤,通过SVD_img2vid_Conditioning节点实现视觉语义转换。该方案适用于创意视频制作、产品演示等场景,支持设计师和AI爱好者快速实现"以图生动"效果。文中
今天给大家演示一个 ComfyUI 图生视频工作流。该流程基于 Stable Video Diffusion (SVD) 模型,通过输入一张静态图片,结合条件控制与采样器配置,最终生成动态视频效果。
整个过程不仅能展现模型对图像运动的理解,还能让用户快速体验从“图”到“视频”的一键生成效果。
工作流介绍
这个工作流以 SVD 图像转视频模型 为核心,首先加载检查点模型及相关 VAE/CLIP 组件,随后导入静态图像并生成对应的潜变量,通过条件控制与采样器进行视频帧的生成,再经过解码与视频合成节点输出最终视频文件。整体逻辑清晰:从 模型加载 → 图片输入 → 条件生成 → 采样与解码 → 视频输出,实现了图像到视频的完整转化流程。
核心模型
在本工作流中使用的核心模型是 svd.safetensors,它是 Stable Video Diffusion img2vid 的权重文件,能够将单张图片扩展为时间维度上的连续视频帧。模型依赖 VAE 进行潜空间与图像空间的互转,并结合 CLIP Vision 进行特征条件化。
| 模型名称 | 说明 |
|---|---|
| svd.safetensors | Stable Video Diffusion 图生视频核心模型,用于从静态图像生成动态视频。 |
Node节点
该工作流包含多个关键节点。模型加载节点负责读取核心权重和相关组件,图像加载节点提供输入素材,条件生成节点利用 SVD 特性构建正/负向引导,采样器节点进行迭代生成,最后通过解码、合成与保存节点将潜变量还原为视频文件。整体节点互相衔接,完成从输入到输出的完整链路。
| 节点名称 | 说明 |
|---|---|
| ImageOnlyCheckpointLoader | 加载 SVD 模型及其相关组件(MODEL/CLIP_VISION/VAE)。 |
| LoadImage | 导入用户输入的静态图像。 |
| SVD_img2vid_Conditioning | 根据输入图像与 CLIP Vision 特征,生成正向/负向条件及潜变量。 |
| VideoLinearCFGGuidance | 为视频生成过程提供 CFG 引导控制。 |
| KSampler | 基于模型与条件进行迭代采样,生成潜变量帧。 |
| VAEDecode | 将潜变量解码为可视图像帧。 |
| CreateVideo | 将解码后的图像帧合成为视频。 |
| SaveVideo | 输出最终的视频文件。 |
工作流程
整个工作流的执行顺序由 模型加载 → 图像导入 → 条件构建 → 视频生成与引导 → 潜变量采样 → 图像解码 → 视频合成 → 文件保存 八个阶段组成。通过节点间的数据传递,保证了从输入图像到最终视频输出的完整链路。模型与图像在前端准备,随后通过条件和采样器生成视频帧,最后在解码与合成节点中输出可播放的视频文件。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 加载 Stable Video Diffusion 模型及其 CLIP、VAE 组件,作为后续生成的基础。 | ImageOnlyCheckpointLoader |
| 2 | 图像导入 | 读取用户输入的静态图像,作为视频生成的参考起点。 | LoadImage |
| 3 | 条件构建 | 使用输入图像与 CLIP Vision 特征生成正/负条件及潜变量。 | SVD_img2vid_Conditioning |
| 4 | 引导控制 | 通过 CFG 指导视频生成过程,提高一致性和控制性。 | VideoLinearCFGGuidance |
| 5 | 潜变量采样 | 依据条件和模型进行迭代采样,生成潜变量帧。 | KSampler |
| 6 | 图像解码 | 将潜变量解码为具体图像帧。 | VAEDecode |
| 7 | 视频合成 | 将生成的图像帧合成为连续的视频序列。 | CreateVideo |
| 8 | 文件保存 | 将最终生成的视频以文件形式输出保存。 | SaveVideo |
大模型应用
SVD_img2vid_Conditioning 视觉语义与潜变量核心生成器
该节点是整个工作流中唯一承担「大模型语义处理」的关键节点。它将加载的视觉编码模型、用户提供的初始图像以及 VAE 编码结果结合,生成视频生成所需的两类核心语义信息:positive conditioning 与 negative conditioning,同时构建用于采样的视频初始潜变量。
由于本工作流是一个纯图像转视频流程,不再依赖文本 Prompt,而是完全由视觉特征主导生成,因此该节点的职责是将图像内容、风格、构图、色彩统一转化为模型可理解的语义表达。最终生成的视频风格、结构和动态一致性,都由这里的视觉条件决定。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| SVD_img2vid_Conditioning | (无文本 Prompt,基于输入图像自动生成视觉语义) | 将 CLIP Vision、初始图像与 VAE 编码结果融合,生成 positive 与 negative 条件 embedding,并构建视频潜变量,是整个 SVD 视频生成的核心语义节点。 |
使用方法
该图像转视频工作流通过加载 SVD(Stable Video Diffusion)模型,读取用户输入的图片,并利用视觉条件生成连续帧,最终合成完整视频。用户只需更换输入图片,系统就能自动重新编码图像语义、生成潜变量并进行视频采样。
初始图像决定视频内容主题与画面风格;视觉模型负责解析图像特征;潜变量则引导动作与帧间变化;用户无需提供文字 Prompt 就能生成与原图一致性极强的视频。
| 注意点 | 说明 |
|---|---|
| 输入图要清晰 | 影响视觉语义提取与最终视频质量 |
| 建议使用较高分辨率 | SVD 动态生成效果与分辨率相关 |
| 视频长度由帧率参数决定 | 在 CreateVideo 节点中调整 |
| 图像主体应明确 | 有利于模型提取重点特征进行动态生成 |
| CFG 调整平稳即可 | VideoLinearCFGGuidance 过高会导致画面不自然 |
应用场景
该工作流主要用于 图像到视频的快速生成,尤其适合创意视频、故事板扩展、产品演示与视觉动效场景。用户只需准备一张静态图像,即可自动生成带有动态变化的视频。典型用户包括 设计师、视频创作者、AI 爱好者 等,他们能够通过该流程将静态素材转化为动态内容,从而扩展创作维度。生成的视频可以用于 社交媒体展示、概念验证、艺术创作 等,帮助实现“以图生动”的效果。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 图像转视频 | 将静态图像转化为动态视频 | 设计师 / 创作者 / AI 爱好者 | 输入单张图片 | 输出连贯的视频画面 |
| 创意内容制作 | 用于视觉动效或短片生成 | 视频博主 / 营销团队 | 产品图像 / 场景图像 | 自动生成动画效果 |
| 概念演示 | 展示项目或艺术创意 | 项目展示者 / 艺术家 | 草图 / 插画 | 转化为动态视觉演示 |
| AI 研究与实验 | 验证图生视频模型效果 | 开发者 / 学者 | 不同测试图片 | 比较生成结果与模型性能 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)