VMware Ubuntu18 虚拟机安装 -《大数据原理与应用》 第3版 林子雨 - 实验
书本教材链接:
(建议自行在浏览器收藏夹栏创建一个目录,并将该网址以及本文引用的所有网址收录并整理)教材配套大数据软件安装和编程实践指南![]() https://dblab.xmu.edu.cn/post/13741/
https://dblab.xmu.edu.cn/post/13741/
(第2版)机房上机实验指南-林子雨编著《大数据技术原理与应用》![]() https://dblab.xmu.edu.cn/post/6131/(第2版)林子雨编著《大数据技术原理与应用》教材配套上机练习题目
https://dblab.xmu.edu.cn/post/6131/(第2版)林子雨编著《大数据技术原理与应用》教材配套上机练习题目![]() https://dblab.xmu.edu.cn/post/5645/(第2版)林子雨编著-大数据基础编程、实验和案例教程(jysh)
https://dblab.xmu.edu.cn/post/5645/(第2版)林子雨编著-大数据基础编程、实验和案例教程(jysh)
iso 文件下载:
虚拟机 iso 文件下载:(官方建议 Ubuntu 18)NEXT, ITELLYOUNEXT, ITELLYOU![]() https://next.itellyou.cn/
https://next.itellyou.cn/
Ubuntu Releases![]() https://releases.ubuntu.com/
https://releases.ubuntu.com/
VMware 下载:
参考下方 2023 版教程,或 B 站自行搜索
Ubuntu 18 安装:
Ubuntu 安装流程:(参考)
- 2015版教程,Ubuntu 18在Windows中使用VirtualBox安装Ubuntu
 https://dblab.xmu.edu.cn/blog/337-2/
https://dblab.xmu.edu.cn/blog/337-2/ - 2020版教程在Windows中使用VirtualBox安装Ubuntu虚拟机(2020年7月版本)https://dblab.xmu.edu.cn/blog/2760/
- 2023版教程,Ubuntu 20在Windows操作系统下使用虚拟机VMware Workstation安装Ubuntu 20.04https://dblab.xmu.edu.cn/blog/4124/
本教程 VMware 设置参考2023版教程,Ubuntu 18 安装过程参考2015年版教程。
为避免一些麻烦,降低学习成本,磁盘大小建议调大一点,比如 64 GB、128 GB。但不要立即分配!不要立即分配!不要立即分配!除非你的实体机有 1 TB 以上。
安装过程中,界面可能会显示不全,这是由于计算机的分辨率问题导致的,遇到这种情形时,可以按住键盘的“win”键,再把鼠标移动到安装界面上,点住鼠标左键不放,拖动界面,就可以看到其他被遮住的部分了。
Ubuntu 18 设置:
为降低学习成本,建议初始用户(跟随官方教程设置)为 dblab,密码为 1
系统安装完成之后,根据教程创建 hadoop 用户,建议密码也跟随教程设置为 hadoop:
右键桌面,打开终端,(右键终端图标,添加到收藏夹)
Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)![]() https://dblab.xmu.edu.cn/blog/2441/登录 hadoop 后,进行如下设置
https://dblab.xmu.edu.cn/blog/2441/登录 hadoop 后,进行如下设置
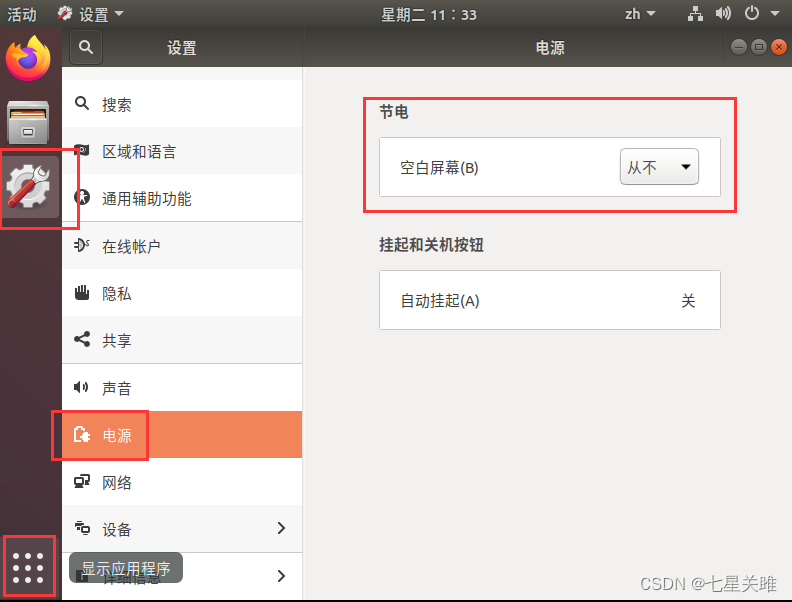
可自行选择将软件更新源改为阿里云。
为提高学习效率,建议自行安装 VMware tools,并开启文件共享功能,可在本站自行搜索教程,
在 VMware 里面点击安装 VMware tools,稍后 Ubuntu 桌面会弹出安装文件
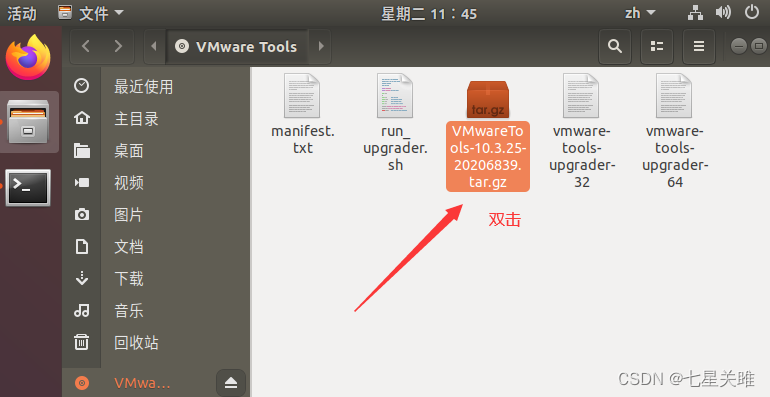
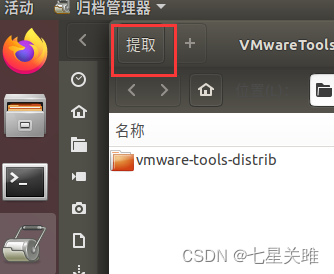 →
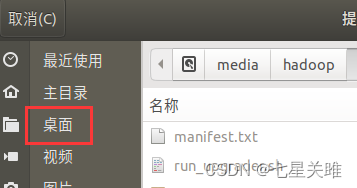
→ 
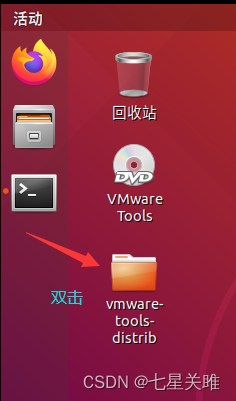 →右键→
→右键→ 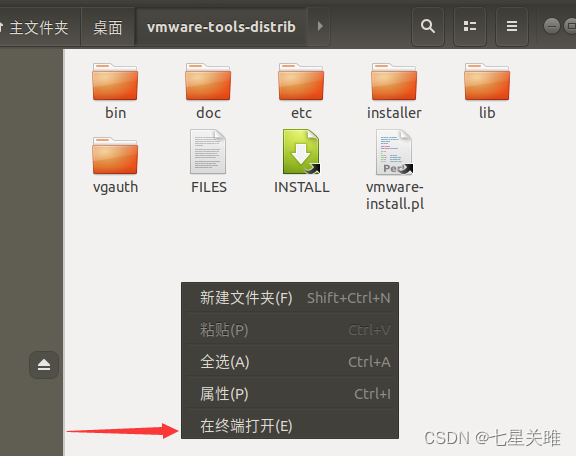
输入:sudo ./vm,之后 tab 键补全,回车,第一个提示输入 yes,其他回车默认,
开启剪切板共享、文件夹共享。建议把林子雨老师的百度网盘的文件一次性下载保存到实体机的一个目录,在 VMware 中共享此目录,可以通过此目录来共享、上传、下载文件,如此可大幅度地降低学习成本,降低硬盘占用
终端访问共享目录:
输入cd /mnt,然后 tab,tab,再 tab,回车,ls,回车。tab 能否补全,取决于目录下是否只有一个子目录。效果如下,
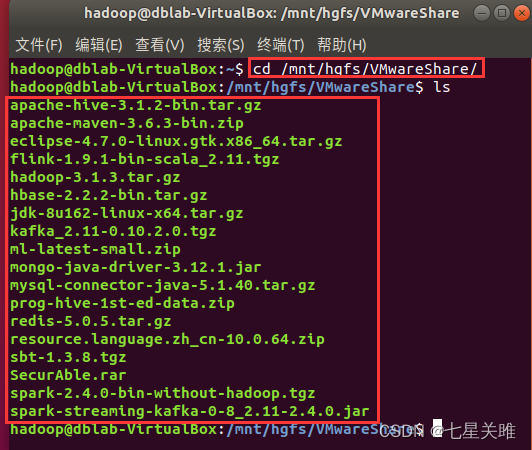
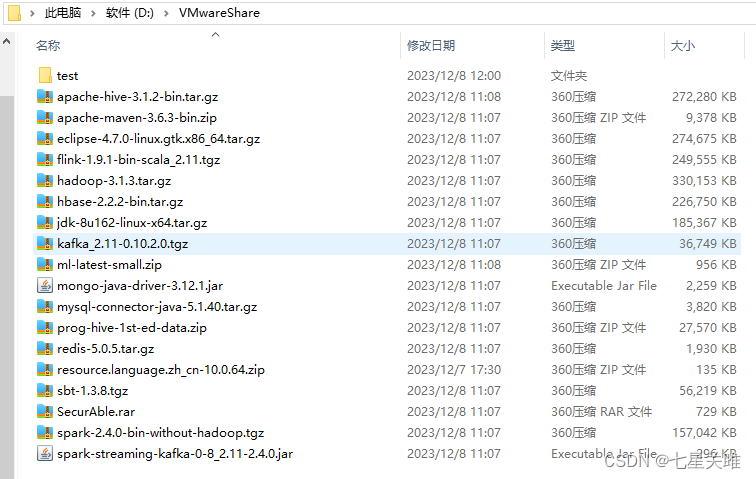
之后可以根据自己实体物理机器的硬盘空间考虑是否创建快照。
建议:在以后的作业和教程学习的过程中,都要使用 hadoop 用户来登录完成,后续教程涉及的软件版本尽量保证与教程一致,如使用 VMware 文件共享功能,则教程中提到的“下载”目录更换为你自己设置的共享目录即可,如果硬盘空间足够可一次性将文件复制到“下载”目录
常用启动 / 关闭命令:
建议自行在桌面创建一个 txt 文本保存以下命令
启动 hadoop
# 启动 Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh关闭 hadoop
# 关闭 hadoop
cd /usr/local/hadoop
./sbin/stop-dfs.sh # 关闭启动 HBase
# 启动 HBase
cd /usr/local/hbase
bin/start-hbase.sh
打开 HBase 命令行
# 打开 Hbase 命令行
cd /usr/local/hbase
bin/hbase shell关闭 HBase
# 关闭HBase
cd /usr/local/hbase
bin/stop-hbase.sh启动 eclipse
# 启动 eclipse
cd /usr/local/eclipse
./eclipse
启动 MongoDB
# 启动 MongoDB
sudo service mongodb start
关闭 MongoDB
# 关闭 MongoDB
sudo service mongodb stop
启动并登陆mysql shell
# 启动并登陆 mysql shell
service mysql start
mysql -u root -p
service mysql stop
启动 hive
# 启动 hive
cd /usr/local/hadoop #进入Hadoop安装目录
./sbin/start-dfs.sh
cd /usr/local/hive
./bin/hive启动 spark shell
#启动 Spark shell
cd /usr/local/spark
bin/spark-shell
启动 flink
# 启动 Flink:
cd /usr/local/flink
./bin/start-cluster.sh
启动 idea
(下方有创建快捷方式教程)
# 启动 idea
cd /usr/local/idea
./bin/idea.sh
附:
Ubuntu 虚拟机文件:
ubuntu 18 献上(“毛坯房”,已完成hadoop创建、VMware tools 安装,可进行剪切板、文件夹共享)
大数据Linux实验环境虚拟机镜像文件_厦大数据库实验室博客![]() https://dblab.xmu.edu.cn/blog/1645/
https://dblab.xmu.edu.cn/blog/1645/
软件链接:
(友情提示:鼠标中健(滚轮)单击下方蓝色链接可在新标签页打开链接,更多中键功能、鼠标手势可自行百度)
Index of /dist![]() https://archive.apache.org/dist/https://downloads.apache.org/
https://archive.apache.org/dist/https://downloads.apache.org/![]() https://downloads.apache.org/Index of /hive
https://downloads.apache.org/Index of /hive![]() https://dlcdn.apache.org/hive/Index of /maven
https://dlcdn.apache.org/hive/Index of /maven![]() https://downloads.apache.org/maven/Index of /flink
https://downloads.apache.org/maven/Index of /flink![]() https://downloads.apache.org/flink/Index of /dist/hadoop/common
https://downloads.apache.org/flink/Index of /dist/hadoop/common![]() http://archive.apache.org/dist/hadoop/common/Index of /hadoop/common
http://archive.apache.org/dist/hadoop/common/Index of /hadoop/common![]() https://dlcdn.apache.org/hadoop/common/https://downloads.apache.org/hbase/
https://dlcdn.apache.org/hadoop/common/https://downloads.apache.org/hbase/![]() https://downloads.apache.org/hbase/Index of /kafka
https://downloads.apache.org/hbase/Index of /kafka![]() https://downloads.apache.org/kafka/Index of /spark
https://downloads.apache.org/kafka/Index of /spark![]() https://downloads.apache.org/spark/Index of /dist/spark
https://downloads.apache.org/spark/Index of /dist/spark![]() https://archive.apache.org/dist/spark/
https://archive.apache.org/dist/spark/
大佬巨作:

你连“抄袭”都没学会,谈何创新??? 大数据 | 实验一:大数据系统基本实验 | 常用的 Linux 操作和 Hadoop 操作_熟悉常用的linux操作和hadoop操作-CSDN博客文章浏览阅读3.4k次,点赞10次,收藏44次。Hadoop 运行在 Linux 系统上,因此需要学习实践一些常用的 Linux 命令。_熟悉常用的linux操作和hadoop操作![]() https://blog.csdn.net/m0_63398413/article/details/129482997
https://blog.csdn.net/m0_63398413/article/details/129482997
实验二:熟悉常用的HDFS操作_实验2 熟悉常用的hdfs操作-CSDN博客文章浏览阅读960次。⑤给定HDFS中某个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路 径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息。(1)操作系统:Linux(建议 Ubuntu 16.04 或 Ubuntu 18.04)。(1)编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务。(2)Hadoop 版本:3.1.3。(3)JDK 版本:1.8。_实验2 熟悉常用的hdfs操作![]() https://blog.csdn.net/m0_52014276/article/details/130874420
https://blog.csdn.net/m0_52014276/article/details/130874420
实验6 熟悉Hive的基本操作_hive环境搭建实验报告-CSDN博客文章浏览阅读1.8w次,点赞49次,收藏250次。一、实验目的(1)理解Hive作为数据仓库在Hadoop体系结构中的角色。(2)熟练使用常用的HiveQL。二、实验平台操作系统:Ubuntu18.04(或Ubuntu16.04)。Hadoop版本:3.1.3。Hive版本:3.1.2。JDK版本:1.8。三、数据集由《Hive编程指南》(O’Reilly系列,人民邮电出版社)提供,下载地址:https://raw.githubusercontent.com/oreillymedia/programming_hive/master/_hive环境搭建实验报告![]() https://blog.csdn.net/weixin_46584887/article/details/121550084
https://blog.csdn.net/weixin_46584887/article/details/121550084
实验7 Spark初级编程实践_sparkjic实验-CSDN博客文章浏览阅读4.5k次,点赞13次,收藏63次。每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;下面是输入文件和输出文件的一个样例,供参考。对于两个输入文件 A 和 B,编写 Spark 独立应用程序(推荐使用 Scala),对两个文件进行。1、输入/usr/local/sbt/sbt package打包时,显示找不到sbt。_sparkjic实验![]() https://blog.csdn.net/weixin_51293984/article/details/128076728
https://blog.csdn.net/weixin_51293984/article/details/128076728
[idea] ubuntu创建idea快捷方式 好用!-CSDN博客文章浏览阅读1.1k次,点赞3次,收藏7次。ubuntu创建idea快捷方式_ubuntu创建idea快捷方式![]() https://blog.csdn.net/weixin_43931635/article/details/126686212?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170176185516800186581172%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=170176185516800186581172&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-6-126686212-null-null.142%5Ev96%5Epc_search_result_base6&utm_term=idea%E5%BF%AB%E6%8D%B7%E6%96%B9%E5%BC%8F&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_43931635/article/details/126686212?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170176185516800186581172%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=170176185516800186581172&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-6-126686212-null-null.142%5Ev96%5Epc_search_result_base6&utm_term=idea%E5%BF%AB%E6%8D%B7%E6%96%B9%E5%BC%8F&spm=1018.2226.3001.4187
Flink初级编程实践(使用macOS上的IDEA远程调试服务器)——大数据基础编程实验之八_flink idea mac-CSDN博客文章浏览阅读4.8k次,点赞12次,收藏74次。Flink初级编程实践——大数据基础编程实验之八一、实验目的(1)通过实验掌握基本的Flink编程方法。(2)掌握用IntelliJ IDEA工具编写Flink程序的方法。二、实验平台(1)服务器 Ubuntu 16.04。(2)个人电脑 macOS 10.15.6。(3)IntelliJ IDEA 2021.2.2。(4)Flink 1.9.1。三、实验步骤1.使用IntelliJ IDEA工具开发WordCount程序在个人电脑macOS系统中安装IntelliJ IDEA,然后使_flink idea mac![]() https://blog.csdn.net/weixin_44616879/article/details/120689033
https://blog.csdn.net/weixin_44616879/article/details/120689033
————

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)