Pytorch手势识别
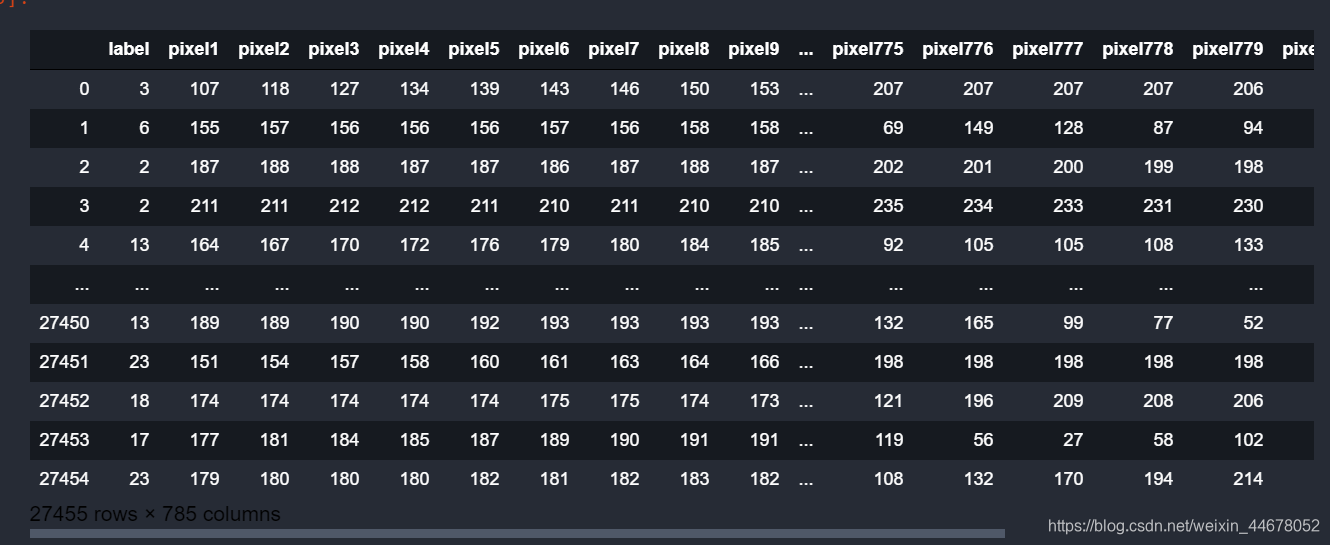
一. 数据集介绍数据集可以在kaggle上面下载地址.识别的手势是26个英文字母,如下所示,图片中好像缺少了一个Z。数据是csv格式的,第一列是label,其余的像素,也就是我们的图片数据,28*28大小的。二.构造DataLoader由于数据是csv格式,和之前图片的有所不同,之前直接重写Dataset类就可以加载我们的数据,这次其实可以重写Dataset类,但是我这样做的...
·
一. 数据集介绍
- 数据集可以在kaggle上面下载地址.
- 识别的手势是26个英文字母,如下所示,图片中好像缺少了一个Z。

- 数据是csv格式的,第一列是label,其余的像素,也就是我们的图片数据,28*28大小的。
二. 构造DataLoader
-
由于数据是csv格式,和之前图片的有所不同,之前直接重写Dataset类就可以加载我们的数据,这次其实可以重写Dataset类,但是我这样做的时候,训练的时候准确率一直只有0.07左右,这次我们需要使用另外一种比较简单的方法,来构造数据集
-
利用TensorDataset函数将tensor数据变成TensorDataset数据,也就是将数据变成pytorch可以分批次加载的数据。
train = pd.read_csv('../input/sign-language-mnist/sign_mnist_train.csv',dtype=np.float32) #读取csv
y = train.label.values #label
x = train.loc[:,train.columns!= 'label'].values / 255 #图片数据
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.2,random_state=42) #分成数据集,测试集
print(test_x.shape)
train_x = torch.from_numpy(train_x) #转换成tensor
train_y = torch.from_numpy(train_y).type(torch.LongTensor) #转换成Longtensor,交叉熵损失函数的label需要long类型的数据
test_x = torch.from_numpy(test_x)
test_y = torch.from_numpy(test_y).type(torch.LongTensor)
train = TensorDataset(train_x,train_y) #转换成Dataset,类似于TensorFlow的from_tensor_slices
test = TensorDataset(test_x,test_y)
train_loader = DataLoader(train,batch_size=100,shuffle=False,drop_last=True) # 构造DataLoader
test_loader = DataLoader(test,batch_size=100,shuffle=False,drop_last=True)
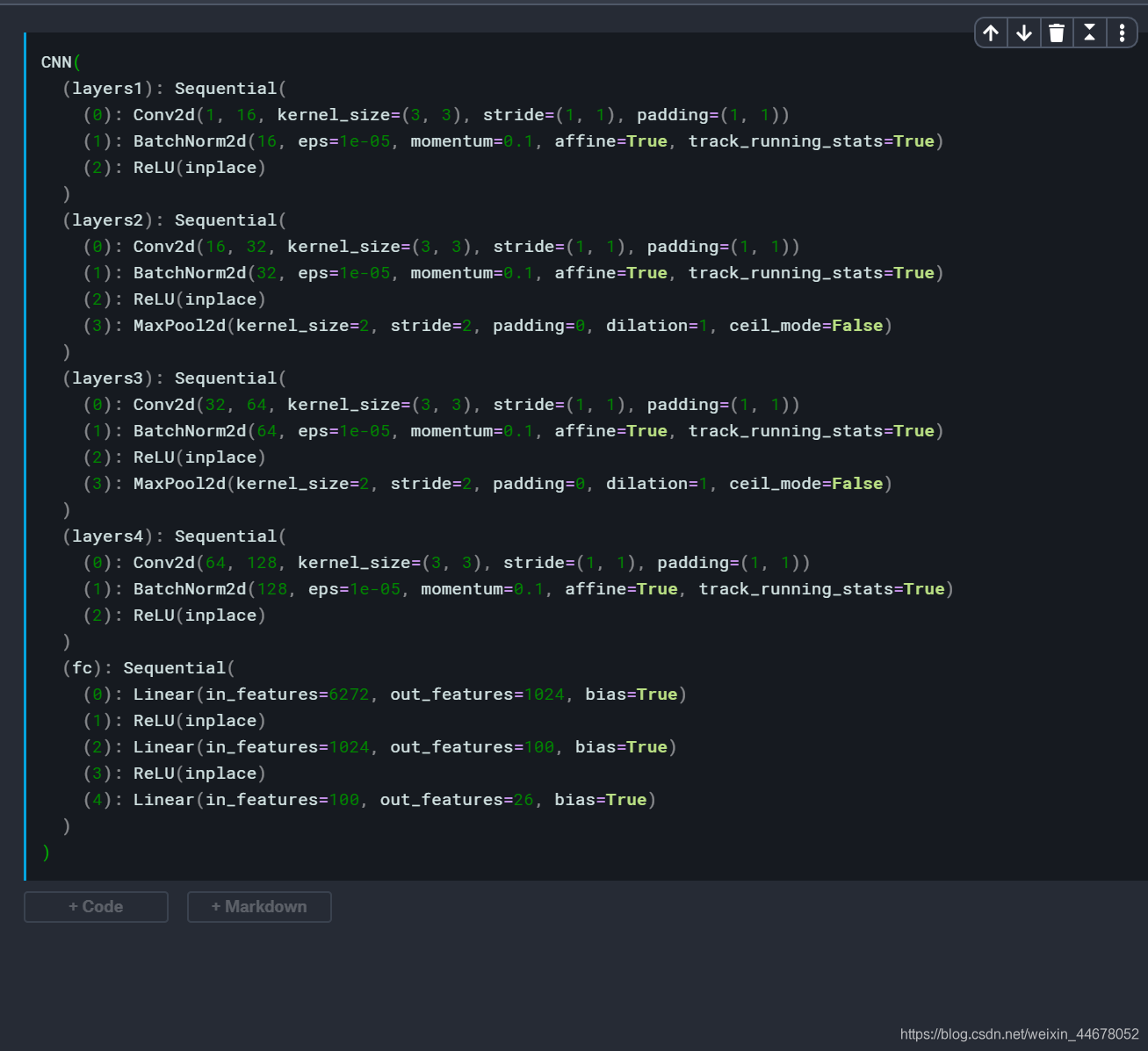
三. 构造网络
- 构造网络这比较简单,由于没有合适的GPU,只能使用一些比较简单的网络。
- 这里也可以使用残差网络,随便学一下什么是残差网络,残差网络在很深的网络中经常用到,非常重要的一个网络结构。
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layers1 = nn.Sequential(
nn.Conv2d(1,16,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True)
)
self.layers2 = nn.Sequential(
nn.Conv2d(16,32,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.layers3 = nn.Sequential(
nn.Conv2d(32,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layers4 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
)
self.fc = nn.Sequential(
nn.Linear(7*7*128,1024),
nn.ReLU(inplace=True),
nn.Linear(1024,100),
nn.ReLU(inplace=True),
nn.Linear(100,26)
)
def forward(self, x):
x = self.layers1(x)
x = self.layers2(x)
x = self.layers3(x)
x = self.layers4(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return x
四. 训练网络
- 在训练网络的时候,这次我们分成了训练集合测试集,和之前写有些不一样,但也都差不多,
- 每训练50个epoch,就在测试集上测试一下准确率,这样可以明确模型的好与坏,精度如何。
- 最后如果准确率大于0.983后,就退出训练,训练太久而准确率没有太多的提升,还不如提前结束训练。
error = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(cnn.parameters(),lr=0.1)
for epochs in range(100):
for i ,(img,label) in enumerate(train_loader):
img = img.view(100,1,28,28)
img = Variable(img)
label = Variable(label)
optimizer.zero_grad()
output = cnn(img)
loss = error(output,label)
loss.backward()
optimizer.step()
if i %50 == 0: #测试模型
accuracy = 0
for x,y in test_loader:
x = x.view(100,1,28,28)
x = Variable(x)
out = cnn(x)
pre = torch.max(out.data,1)[1]
accuracy += (pre == y).sum()
print('accuracy:',accuracy.item()/(5491))
if(accuracy.item()/(5491)>0.975):
torch.save(cnn.state_dict(),'model.pth')
if(accuracy.item()/5491 > 0.983):
break
最后打印一下训练的log,训练到最后准确率基本上没有变化了。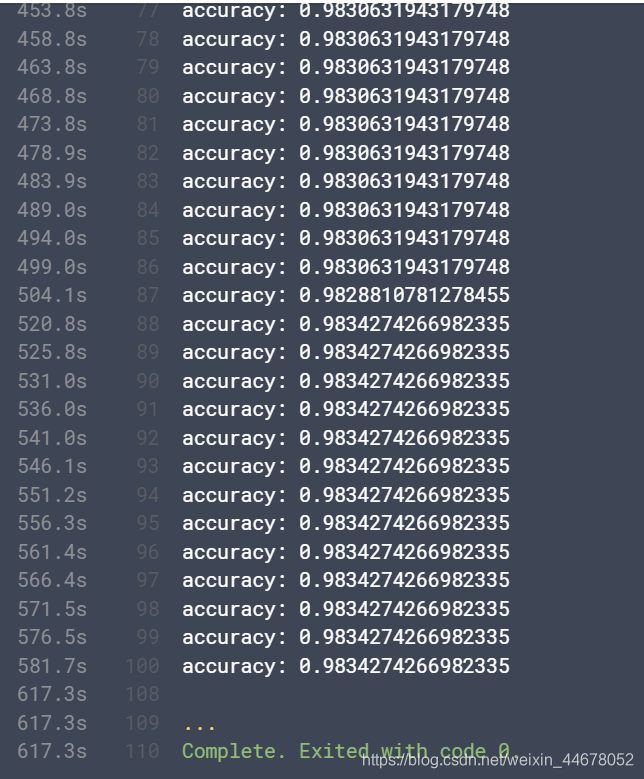
完整代码可在GitHub上面下载地址.
Thank for your reading !!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)