大模型“赛博算命”大考:DeepSeek、GPT-5、Gemini 谁才是真正的玄学宗师?(附 BaziQA 完整榜单)
我们推出的 “生命 K 线(Life K-line)” 和 “天赋地图(Talent Map)”,正是试图将这些复杂的概率数据,转化为用户可感知、可参考的人生工具。一个“庚金”在不同月令、不同坐支下的旺衰完全不同,这种极度的非线性、强约束网络对 Transformer 的空间表达能力提出了极大挑战。虽然在总榜表现一般,但它在处理事业、财富等世俗化、商业化的逻辑上,依然保留了极强的优势。我们发布 B
导读: 当我们在谈论大模型的推理能力(Reasoning)时,通常在聊数学题或写代码。但如果把这股算力投向拥有千年历史、逻辑极度非线性的“中国传统命理学”,AI 的表现会如何?是胡言乱语的概率游戏,还是已经摸到了五行逻辑的门槛?
最近,AuraMate 研究团队发布了 BaziQA Live Benchmark(2021–2025)实时评测结果。这份榜单基于 200 道真实八字比赛真题、1000 轮实验数据,并引入了 400 位专业命理爱好者的投票验证。
结果不仅颠覆了认知,还暴露出了一些主流模型在处理“东方逻辑”时的底层缺陷。
一、 实验设计:我们是如何“调教”AI 考公职命理题的?
为了保证评测的严肃性,我们没有采用简单的“随便问问”,而是构建了一个严谨的评测框架:
数据集 (BaziQA): 筛选自 2021–2025 年间真实的八字竞赛题目。
题型: 四选一客观题(减少了主观判分的偏差)。
评测方法: Multi-turn Conversation(多轮对话诱导推理),每款模型运行 1000 次取宏平均准确率。
随机基线: 25%(即完全瞎蒙的得分)。
二、 成绩单揭晓:谁是“硅基半仙”?
在参与测试的 10 款顶尖模型中,排位赛异常激烈。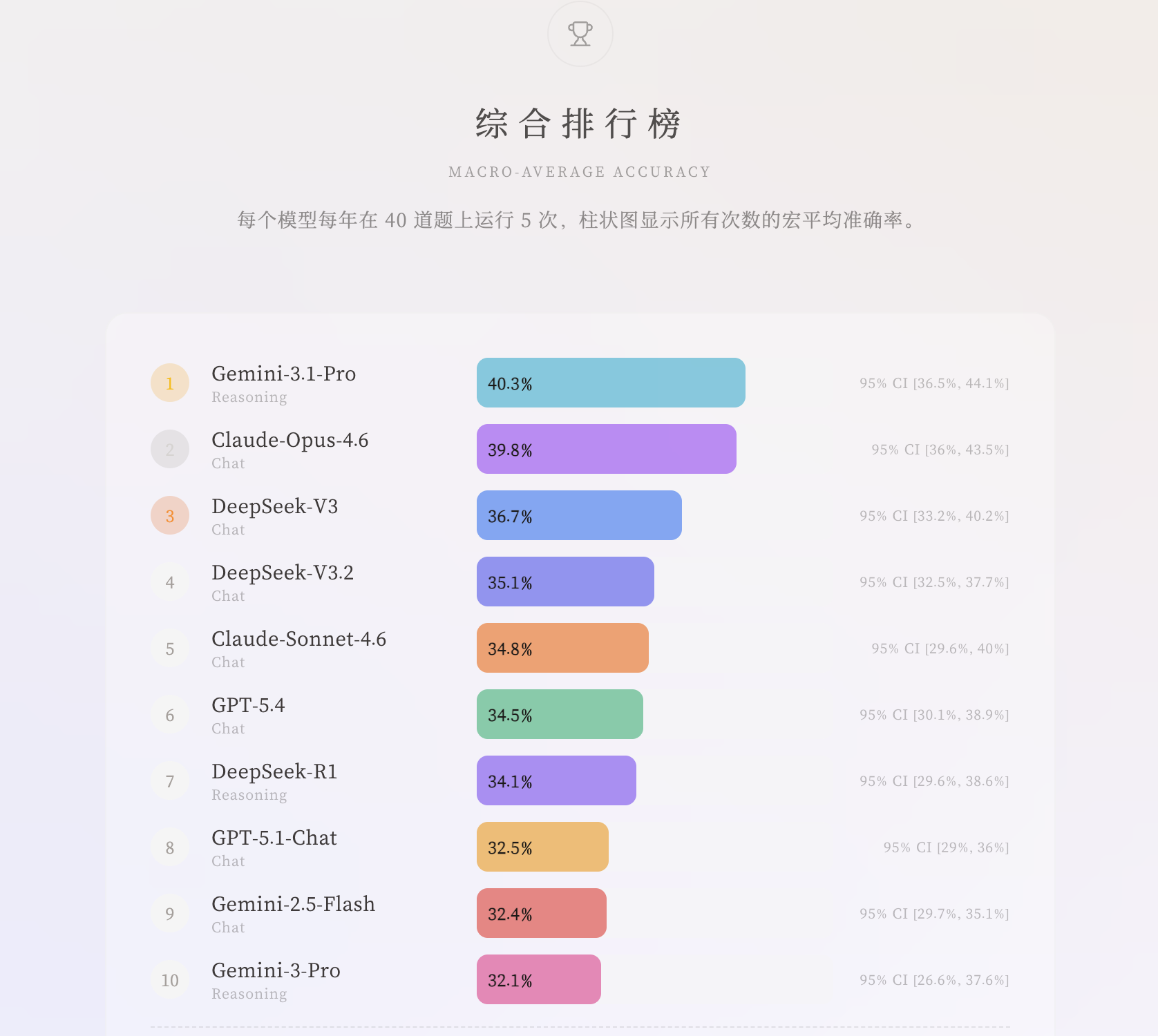
核心观察:
- 显著性: 几乎所有主流模型的准确率均稳定在 32%~40% 之间,统计学上显著优于 25% 的随机猜测。这意味着,AI 确实在某种程度上“理解”了干支与五行之间的逻辑关联。
- 推理模型的“滑铁卢”: 一个非常反直觉的现象是,主打逻辑推理的模型(如DeepSeek-R1)在八字测试中的表现反而略逊于对话版(V3)。这或许说明,命理推理不完全等同于数学逻辑,它更依赖于对语境和传统语义的深层建模。
三、 领域拆解:AI 也有“擅长”和“短板”
通过对 9 个细分维度的分析,我们发现 AI 们展现出了有趣的“性格差异”: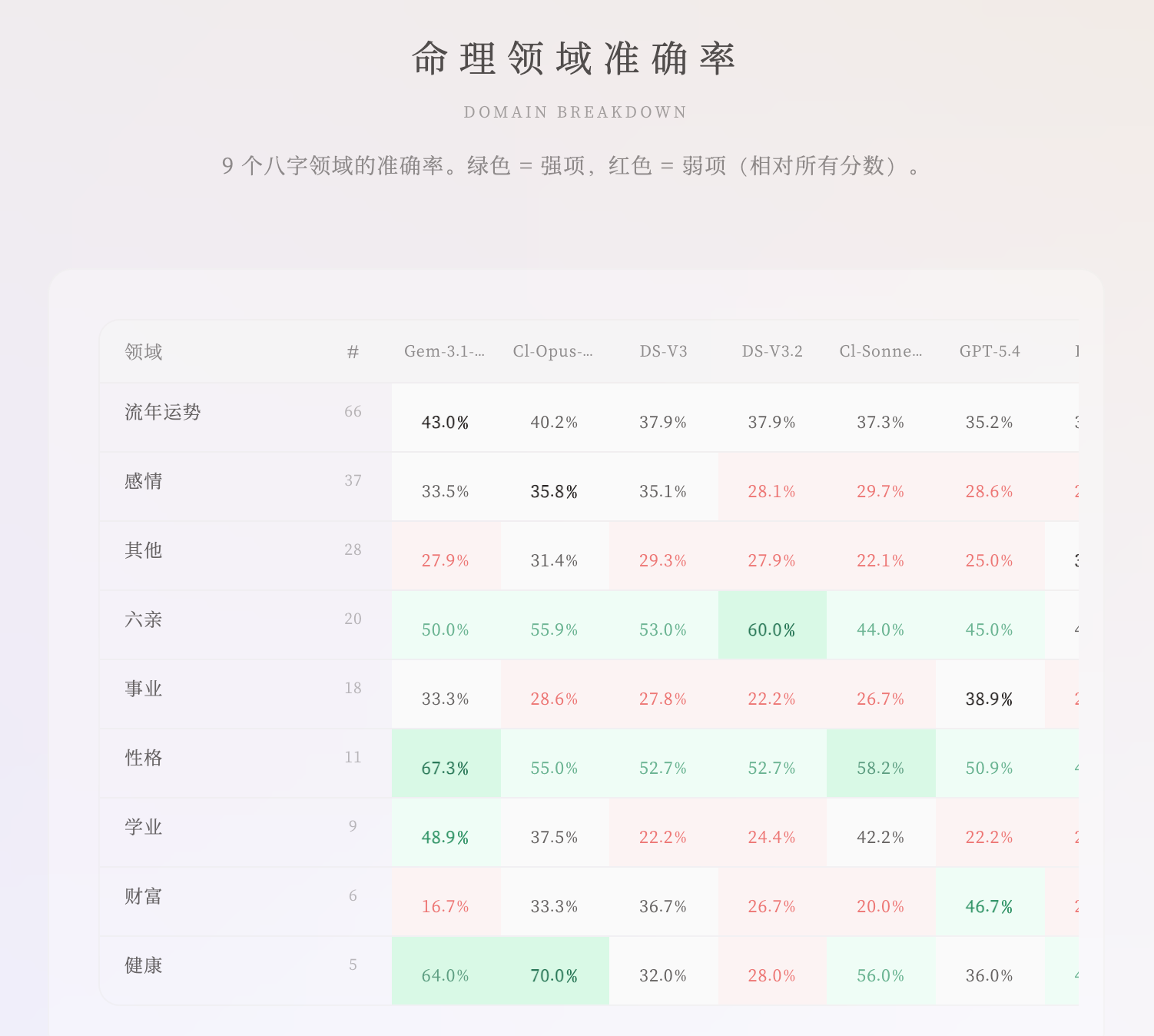
-
谁是真正的“健康大师”?
在【健康】领域,Claude-Opus (70%) 和 Gemini-3.1 (64%) 拿到了超高分。这可能得益于它们在训练阶段接触了大量的跨学科数据,能够将五行平衡与生物医学逻辑进行有效映射。 -
谁最懂“家长里短”?
【六亲】(父母、兄弟、子女关系)是八字中最难的推断之一。DeepSeek-V3.2 以 60% 的准确率冠绝群雄。作为国产模型,它对中式家族结构、传统伦理逻辑的理解,显然比西方模型更具“根源优势”。 -
谁更懂“发财之道”?
在【财富】维度,GPT-5.4 跑出了 46.7% 的好成绩。虽然在总榜表现一般,但它在处理事业、财富等世俗化、商业化的逻辑上,依然保留了极强的优势。
四、 技术深思:40% 的准确率意味着什么?
在知乎,我们要聊点深层的:为什么 AI 算命还没到 80%?
非线性逻辑的悖论: 八字命理不是 1+1=2。一个“庚金”在不同月令、不同坐支下的旺衰完全不同,这种极度的非线性、强约束网络对 Transformer 的空间表达能力提出了极大挑战。
语料的纯度问题: 互联网上充斥着大量的“劣质”命理文案,AI 在预训练阶段吸收了太多噪音。
认知断层: AI 目前更多是在“模式匹配”,而非真正的“天人合一”。但 40% 的成绩已经足以证明,AI 可以成为命理师的强力辅助工具。
五、 结语:AuraMate 的探索
我们发布 Bazi-Benchmark 并不是为了造神,而是想在大模型的能力地图上,标记出一个属于“中式传统智慧”的坐标。
目前,AuraMate V1.0.1 已经整合了这些顶尖模型的能力。我们推出的 “生命 K 线(Life K-line)” 和 “天赋地图(Talent Map)”,正是试图将这些复杂的概率数据,转化为用户可感知、可参考的人生工具。
命运不是写好的代码,而是可以被优化的算法。
完整榜单及详细数据分析,欢迎访问我们的实时页面: BaZi-Benchmark 实时评测: AI 八字推理能力排行榜
也推荐一下我们研发的目前达到全球命理师大赛季军水平的产品:AuraMate灵伴

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)